Prefácio
O conjunto de dados da cabeça é usado no projeto, e a maioria das cabeças no conjunto de dados de imagem aberta no artigo anterior não possui imagens aéreas, o que não é adequado para o meu cenário de aplicativo. Por acaso, o conjunto de dados de lavagem cerebral foi encontrado no guthub aditya-vora / FCHD-Full-Convolutional-Head-Detector . Seu formato de arquivo de anotação é muito diferente do formato de anotação yolo, este artigo visa obter a conversão dos dois.
Pronto
- python3
- cmd
- Link de disco da rede do conjunto de dados de lavagem cerebral : https://pan.baidu.com/s/1Vgr6jZByU41TPd2tkiPMwA código de extração: rnk3
lavagem cerebral
O conjunto de dados de lavagem cerebral é um conjunto de dados de detecção de cabeça densa, que é um conjunto de dados obtido pela marcação de um grupo de pessoas que aparecem em um café e depois rotulado esse grupo de pessoas. Ele contém três partes, o conjunto de treinamento: 10769 imagens com 81975 cabeças e o conjunto de validação: 500 imagens com 3318 cabeças. Conjunto de teste: 500 imagens com 5007 cabeças. Este artigo discute apenas seu conjunto de treinamento.

Seus arquivos de anotação estão em vários arquivos idl, como o treinamento definido em brainwash_train.idl, e seu formato de anotação é o seguinte: "caminho da imagem": anotação. Cada caixa é colocada entre parênteses, as coordenadas são separadas por vírgulas e as caixas são separadas por vírgulas, cada figura tem sua própria linha e o final é separado por um ponto e vírgula.
"brainwash_11_13_2014_images/04231500_640x480.png": (316.0, 132.0, 332.0, 150.0), (201.0, 163.0, 221.0, 185.0), (136.0, 167.0, 156.0, 186.0), (349.0, 144.0, 372.0, 166.0), (606.0, 249.0, 639.0, 290.0);
"brainwash_11_13_2014_images/04232000_640x480.png": (485.0, 233.0, 527.0, 273.0), (48+3.0, 198.0, 513.0, 230.0), (291.0, 199.0, 326.0, 239.0), (208.0, 168.0, 242.0, 202.0), (137.0, 168.0, 160.0, 189.0), (197.0, 165.0, 215.0, 186.0), (317.0, 131.0, 332.0, 149.0);
"brainwash_11_24_2014_images/00000500_640x480.jpg": (385.0, 132.0, 399.0, 143.0), (152.0, 162.0, 168.0, 181.0), (120.0, 171.0, 140.0, 196.0), (468.0, 171.0, 490.0, 190.0);
"brainwash_11_24_2014_images/00001000_640x480.jpg": (160.0, 156.0, 176.0, 175.0), (121.0, 175.0, 140.0, 196.0), (357.0, 159.0, 379.0, 184.0);A próxima coisa a fazer é remover cada linha de dados de acordo com este formato de dados e alterá-lo para o formato yolo:
<Categoria> <coordenada centralizada normalizada x> <coordenada centralizada normalizada y> <imagem normalizada w> <imagem normalizada h>
<Categoria> <coordenada centralizada normalizada x> <coordenada centralizada normalizada y> <imagem normalizada w> <imagem normalizada h>
........
<Categoria> <coordenada centralizada normalizada x> <coordenada centralizada normalizada y> <imagem normalizada w> <imagem normalizada h>
Em seguida, coloque-os em um arquivo txt com o nome da foto.
Conversão de formato
Split:
Após a observação, descobrimos que algumas coisas não são necessárias, e algumas devem ser usadas como nomes de arquivo e outras como conteúdo de arquivo; portanto, primeiro devemos dividi-lo e fazer tratamentos diferentes para cada parte. Eu primeiro dividi cada linha em duas partes, a saber, a parte do caminho da imagem e a parte da anotação da imagem. Note que as duas partes são divididas por ":", mas o final de cada linha é dividido por ";", podemos primeiro dividir ":" Substitua por ";" e depois divida de acordo com ";", você pode remover esses dois símbolos extras.
import os
idl_file_dir = "brainwash_train.idl" #相对地址
txt_files_dir = "txt_files"
if not os.path.exists(txt_files_dir):
os.mkdir(txt_files_dir) #用于存生成的txt文件
f1=open(idl_file_dir,'r+')
lines=f1.readlines()
#print(range(len(lines)))
for i in range(len(lines)):
line = lines[i]
line = line.replace(":",";") #用;替换:
#print(line)Após executar a operação acima, todo o arquivo de etiqueta se torna duas partes, o caminho é armazenado em line.split (";") [0] e o rótulo é armazenado em line.split (";") [1]. Primeiro processe a parte do caminho, observe que há ponto-e-vírgula em ambos os lados do caminho e, em seguida, o símbolo redundante; exclua-o primeiro e depois divida por "/" para obter o nome da imagem e, finalmente, por "." Nome da imagem sem sufixo. Obviamente, esse nome também é o nome do arquivo sem o sufixo do arquivo marcado posteriormente.
img_dir = line.split(";")[0]
#print(img_dir)
img_boxs = line.split(";")[1]
img_dir = img_dir.replace('"',"") #删除分号
#print(img_dir)
img_name = img_dir.split("/")[1]
txt_name = img_name.split(".")[0] #得到后缀名与文件名
img_extension = img_name.split(".")[1]
#print(txt_name)
#print(img_extension)Depois de executar as operações acima, o nome do arquivo e o nome do sufixo estão disponíveis, o primeiro será o nome do arquivo marcado e o último se tornará uma condição de filtragem. Agora, vamos dividir a parte da etiqueta, a parte da etiqueta fica assim. Primeiro exclua todos os "," ( porque há um espaço antes de cada "," no arquivo de identificação original, se você substituir "," por um espaço, haverá mais espaços após a divisão final ). Em seguida, exclua os colchetes de "(" e, finalmente, use ")" para separar as caixas diferentes.
(316.0, 132.0, 332.0, 150.0), (201.0, 163.0, 221.0, 185.0), (136.0, 167.0, 156.0, 186.0), (349.0, 144.0, 372.0, 166.0), (606.0, 249.0, 639.0, 290.0);
(485.0, 233.0, 527.0, 273.0), (48+3.0, 198.0, 513.0, 230.0), (291.0, 199.0, 326.0, 239.0), (208.0, 168.0, 242.0, 202.0), (137.0, 168.0, 160.0, 189.0), (197.0, 165.0, 215.0, 186.0), (317.0, 131.0, 332.0, 149.0);
(385.0, 132.0, 399.0, 143.0), (152.0, 162.0, 168.0, 181.0), (120.0, 171.0, 140.0, 196.0), (468.0, 171.0, 490.0, 190.0);
(160.0, 156.0, 176.0, 175.0), (121.0, 175.0, 140.0, 196.0), (357.0, 159.0, 379.0, 184.0); img_boxs = img_boxs.replace(",","") #删除“,”
#print(img_boxs)
img_boxs = img_boxs.replace("(","") #删除“(”
img_boxs = img_boxs.split(")") #删除“)”
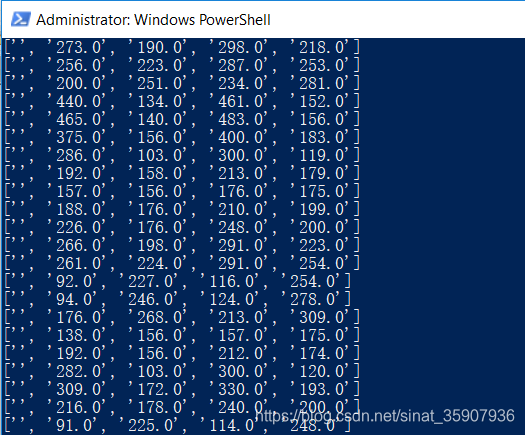
#print(img_boxs)Até agora, os dados foram basicamente divididos: uma imagem e uma img_boxs, cada caixa é uma dimensão de img_boxs e o número de caixas é a dimensão total de img_boxs. Observe que o último item de cada img_boxs é um item de espaço, e esse item é eliminado apenas passando para len (img_boxs) -1 menos um (não visite img_boxs [m], o índice da lista fora do intervalo aparecerá quando m> 0 Erro).
if(img_extension == 'jpg'):
for n in range(len(img_boxs)-1): #消除空格项影响
box = img_boxs[n]
box = box.split(" ")
#print(box)
#print(box[4])

O último passo é converter o formato de lavagem cerebral [xmin, ymin, xmax, ymax] para <category> <coordenada central normalizada x> <coordenada central normalizada y> <imagem normalizada w> <normalizada Imagem h>, é necessário calcular as coordenadas normalizadas, a largura e a altura normalizadas e, em seguida, adicionar o arquivo de anotação de uma imagem ao arquivo txt nomeado após o nome da imagem, e a conversão do tipo de dados é concluída. O resultado é mostrado abaixo. Veja o apêndice para o código completo.
with open(txt_files_dir+"/"+txt_name+".txt",'a') as f:
f.write(' '.join(['0', str((float(box[1]) + float(box[3]))/(2*640)),str((float(box[2]) + float(box[4]))/(2*480)),str((float(box[3]) - float(box[1]))/640),str((float(box[4]) - float(box[2]))/480)])+'\n')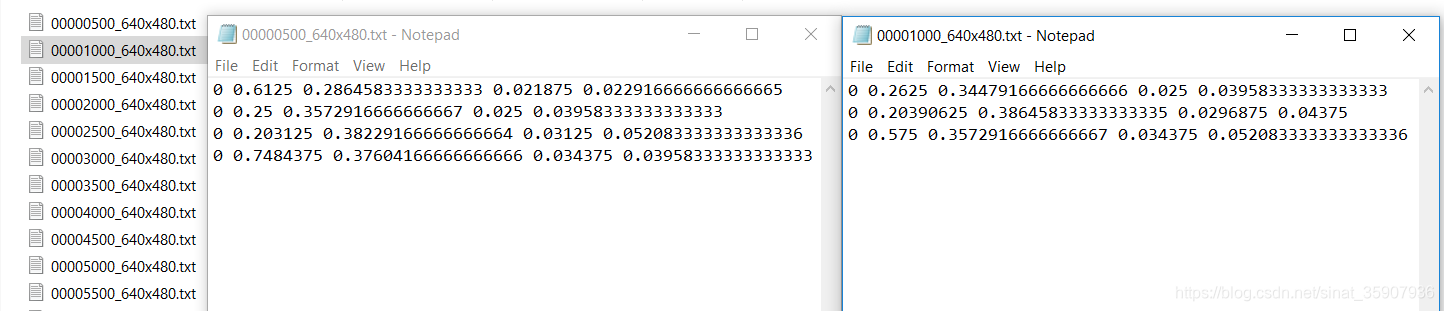
verificação yolo_mark
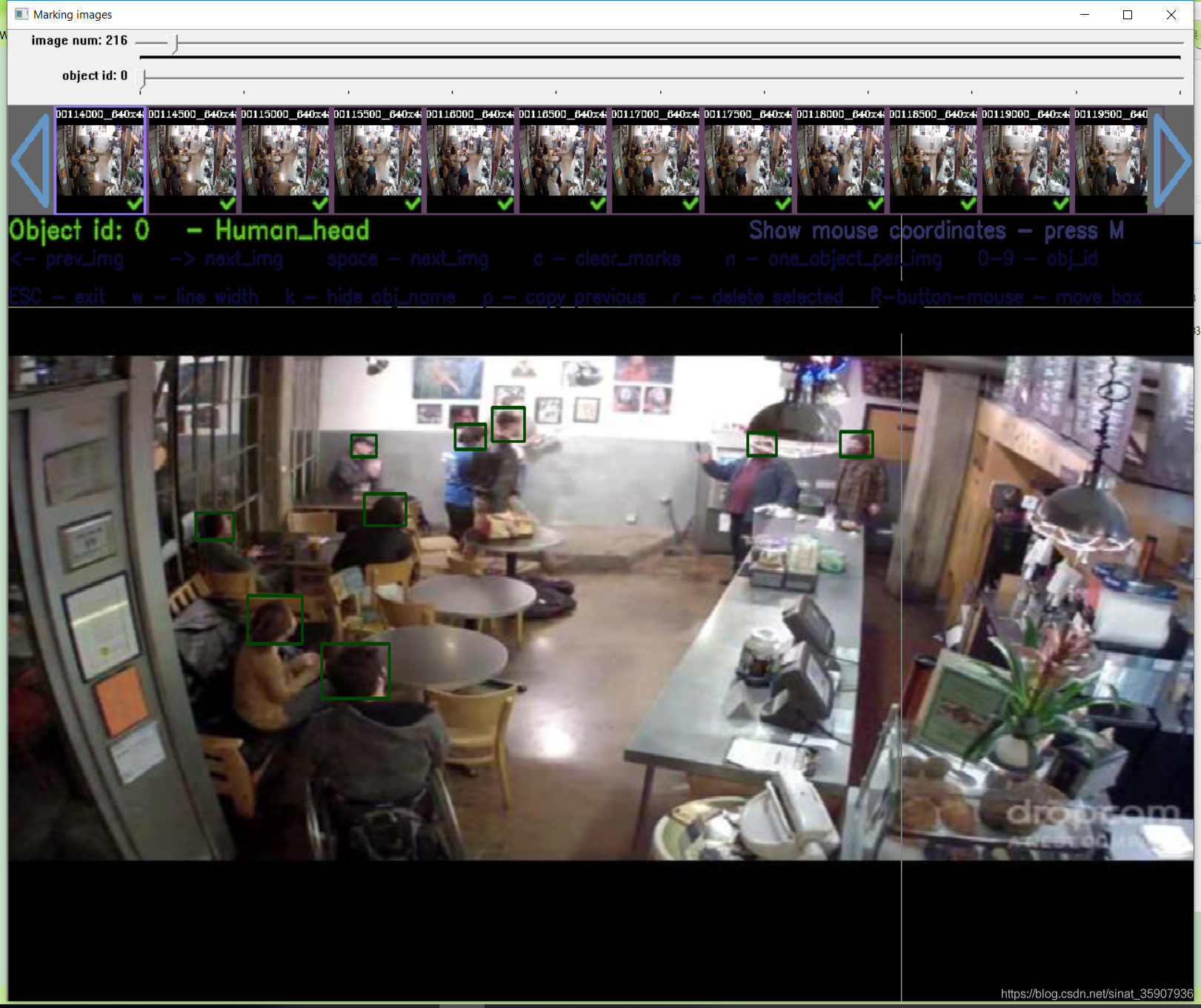
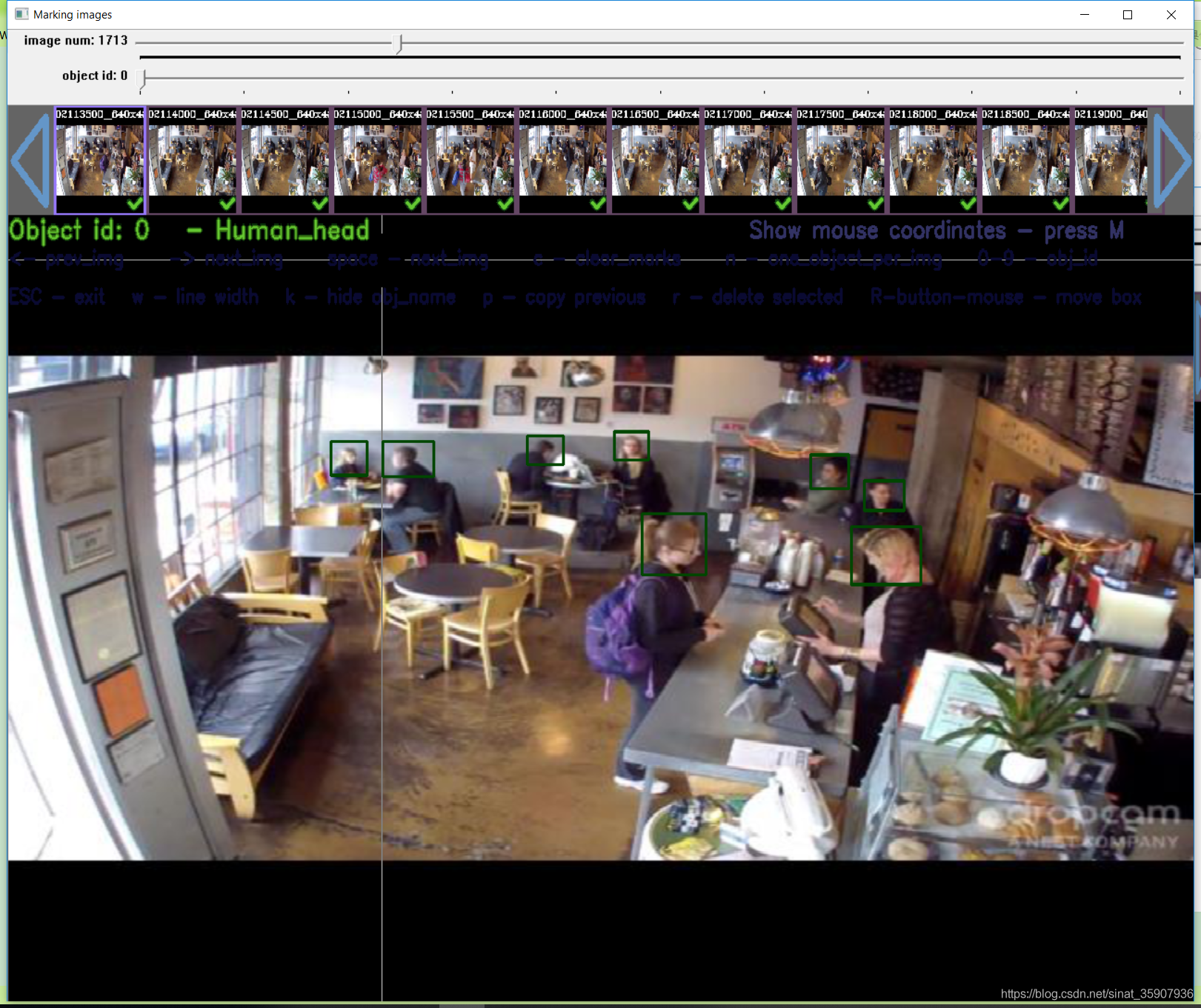
O rótulo e a imagem de yolo_mark estão na mesma pasta, e agora estamos em uma pasta e imagem diferentes, e o rótulo aqui é filtrado, de modo que o script que escrevi em outro artigo pode ser muito É fácil mesclar o conteúdo das duas pastas com base no rótulo. Em seguida, abra a verificação yolo_mark, método de uso yolo_mark, veja meu outro artigo . Consulte aleatoriamente dois, você pode ver que não há problema com o rótulo, indicando que a conversão foi bem-sucedida.
Sumário
A conversão entre os formatos de rotulagem de dados nada mais é do que dividir os dados de acordo com certas regras e, depois, calcular e reorganizar os dados para obter outro tipo de rotulagem. Acima, se um amigo está destinado a ler este artigo, é realmente uma honra. Se você tiver alguma dúvida, deixe uma mensagem para discutir abaixo. Responderei depois que a vir.
Referência
https://blog.csdn.net/sinat_35907936/article/details/88911770
https://blog.csdn.net/sinat_35907936/article/details/89605978
https://blog.csdn.net/sinat_35907936/article/details/89086081
http://arxiv.org/abs/1506.04878
Apêndice
import os
idl_file_dir = "brainwash_train.idl"
txt_files_dir = "txt_files"
if not os.path.exists(txt_files_dir):
os.mkdir(txt_files_dir)
f1=open(idl_file_dir,'r+')
lines=f1.readlines()
#print(range(len(lines)))
for i in range(len(lines)):
line = lines[i]
line = line.replace(":",";")
#print(line)
img_dir = line.split(";")[0]
#print(img_dir)
img_boxs = line.split(";")[1]
img_dir = img_dir.replace('"',"")
#print(img_dir)
img_name = img_dir.split("/")[1]
txt_name = img_name.split(".")[0]
img_extension = img_name.split(".")[1]
#print(txt_name)
#print(img_extension)
img_boxs = img_boxs.replace(",","")
#print(img_boxs)
img_boxs = img_boxs.replace("(","")
img_boxs = img_boxs.split(")")
#print(img_boxs)
if(img_extension == 'jpg'):
for n in range(len(img_boxs)-1):
box = img_boxs[n]
box = box.split(" ")
#print(box)
#print(box[4])
with open(txt_files_dir+"/"+txt_name+".txt",'a') as f:
f.write(' '.join(['0', str((float(box[1]) + float(box[3]))/(2*640)),str((float(box[2]) + float(box[4]))/(2*480)),str((float(box[3]) - float(box[1]))/640),str((float(box[4]) - float(box[2]))/480)])+'\n')
