Diretório
Antecedentes
Muitas empresas de Internet geralmente têm um banco de dados que armazena suas informações de usuário, e os dados no banco de dados são basicamente limpos pelo departamento de engenharia (o uso da tecnologia de rastreador ou a análise de dados subjacente é principalmente o trabalho do departamento de desenvolvimento ou do departamento de engenharia de coleta de dados) Muitos analistas de dados corporativos podem usar ferramentas como HSQL para obter facilmente a grande quantidade de dados de que precisam.
No entanto, existem algumas empresas B2B de pequeno e médio porte no mercado, que não são como as empresas B2C e dependem de suas próprias informações de usuário para iteração de produtos ou crescimento de negócios. Eles dependem principalmente do departamento de engenharia para analisar os dados de terceiros e enviar os resultados ao departamento de desenvolvimento de produtos para construção e visualização da plataforma de negócios. O processo de obtenção de dados de terceiros requer o uso de interfaces de API de terceiros, e é por isso que essas empresas exigem que os candidatos que se candidataram a vários cargos tenham experiência em chamadas de API, porque, mesmo que a empresa tenha seu próprio banco de dados, é afinal um departamento de engenharia. Após os resultados do rastreamento e classificação seletivos, você pode enfrentar o dilema de que o banco de dados não possui os dados desejados.Neste momento, você precisa usar um método semelhante para coletar os dados por conta própria.

Introdução à API
O processo de chamar a API também é um tipo de rastreador. Nos rastreadores, geralmente há dois lugares onde as APIs são mencionadas, uma é a API da biblioteca e a outra é a API de dados.
API da biblioteca
A API da biblioteca geralmente se refere a desenvolvedores que desenvolveram uma biblioteca (como uma biblioteca python) e fornecem uma interface para os usuários chamarem essa biblioteca. Assim, se quisermos ir até o armário de encomendas para pegar nosso correio, precisamos inserir as informações corretas para obter nosso correio.Essas são uma interface de API para nos ajudar a localizar com precisão essa biblioteca e chamá-la.
API de dados
No desenvolvimento de produtos ou na Web, a API de dados é como uma linha de dados passada do back-end para o front-end. A equipe de back-end classificou os dados que deseja exibir e só precisa transmitir essa linha de dados ao desenvolvedor front-end, que pode visualizá-lo conforme necessário. E essa interface também pode ser usada pelo mundo exterior.
Ao contrário do rastreador da Web, o design da API de dados é mais simples e eficiente.Esta interface já armazena os dados de que todos precisam, e não precisamos gastar muita energia para analisar a página da Web. E o rastreamento de dados de páginas da Web geralmente causa pressão no servidor. Se o seu código não estiver configurado com uma frequência razoável de navegação em páginas humanas, haverá o risco de o IP ser bloqueado.
Mas a API de dados também tem algumas desvantagens. Embora existam muitos produtos API no mercado que podem ser usados pelo mundo exterior, muitas interfaces gratuitas têm grandes restrições quanto à quantidade de rastreamento.Se suas necessidades de rastreamento forem grandes, você precisará pagar.
Exemplo simples de rastreador de API
Abaixo, usarei a API do Facebook Graph para rastrear dados como um exemplo para registrar aproximadamente o processo de chamada da API de dados comum.
- Informações sobre a interface de chamada: forneça o endereço de chamada da API (geralmente no formato URL) .Este endereço é semelhante a ajudar a localizar qual linha e coluna do armário de armazenamento que queremos buscar.
- Solicitar para obter dados: use o protocolo HTTP para solicitar a transferência de dados, geralmente chame a função get no pacote de solicitação em python.
- Defina os parâmetros de solicitação: você precisa fornecer os parâmetros de solicitação, ou seja, precisa informar à interface da API que tipo de informação deseja obter. Por exemplo, neste exemplo, eu preciso de created_time (post time), post_id (post_id) e outras informações.
Documento de introdução da API do Facebook Graph
Embora uma função get possa nos ajudar a implementar solicitações de protocolo HTTP, muitas vezes solicitar esta URL requer autenticação de identidade. Por exemplo, o código a seguir relatará um erro:
import requests
r = requests.get('https://facebook.com/user_id')
r.json()
E retorne: é necessária permissão de identidade. Portanto, ao usar qualquer interface da API, é melhor ler a documentação de uso do site com antecedência para ver quais informações específicas são necessárias pelo protocolo de solicitação.
{'documentation_url': ''https://facebook.com/user_id/#get-the-access-token',
'message': 'Requires authentication'}
Você também pode ver no manual oficial do usuário da API do Facebook, se eu quiser obter as informações po de uma conta do Facebook, preciso obter o token dessa conta. Se você deseja obter outras informações da conta além de si mesmo, também precisa obter os tokens deles com antecedência. Haverá uma introdução correspondente para obter o token-> como obter o token de acesso da conta do Facebook .
Depois de obter o token, teste o código acima para obter os seguintes resultados:
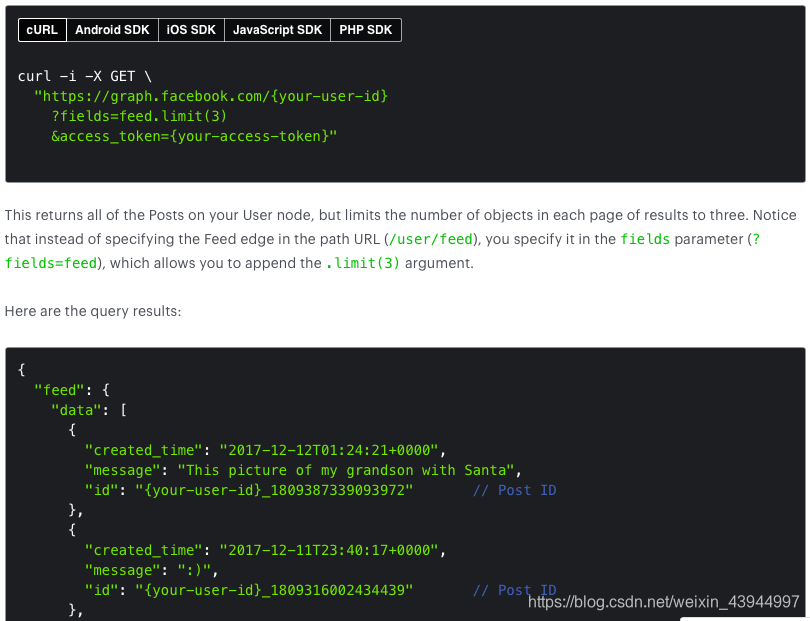
Exemplo de código
Objetivo: obter o número de visualizações de cada blog de vídeo de 2020.03.01 a 2020.03.07, o tempo de visualização de cada país, cada gênero e cada faixa etária e analisar o desempenho do conteúdo de vídeo deste blogueiro nesta semana.
1. 首先我需要拿到3.1至3.7之间每条博文的ID(post_id)
2. 筛选出仅为视频的博文ID
3. 需要获取每条视频博文的观看次数,各个国家的观看时长
4. 将json格式的数据整理成dataframe格式
5. 将观看时长可视化
1. 导入所需的包
import pandas as pd
import json, datetime, requests
from datetime import date, timedelta, datetime
import numpy as np
from pandas.core.frame import DataFrame
2.创建爬取数据的函数
def get_list_of_fb_post_ids(fb_page_id, fb_token, START, END):
'''
Function to get all the post_ids from a given facebook page during certain time range
'''
posts=[] #用来存储所有博文的post_id
graph_output = requests.get('https://graph.facebook.com/'+fb_page_id+'?fields=posts.limit(10){created_time}',params=fb_token).json()
posts+=graph_output['posts']['data']
graph_output = requests.get(graph_output['posts']['paging']['next']).json()
posts+=graph_output['data']
while True: #一直读取next_page,直到某次读取的记录的时间小于你设置的开始时间
try:
graph_output = requests.get(graph_output['paging']['next']).json()
posts+=graph_output['data']
if graph_output['data'][-1]['created_time']<=START:
break
except KeyError:
break
df_posts=pd.DataFrame(posts)
df_posts=df_posts[(df_posts.created_time>=START)&(df_posts.created_time<=(datetime.strptime(END, "%Y-%m-%d")+timedelta(days=1)).isoformat())]
df_posts.columns = ["timestamp", "post_id"]
return df_posts
3.给变量赋值,抓取post_id
fb='EAAIkwQUa1WoBAFWmq90xbMfLHecpRga****************'
fb_token = {'access_token': fb}
user_id='1404******'
output=get_list_of_fb_post_ids(user_id,fb_token,'2020-03-01','2020-03-07')
Os resultados são os seguintes:
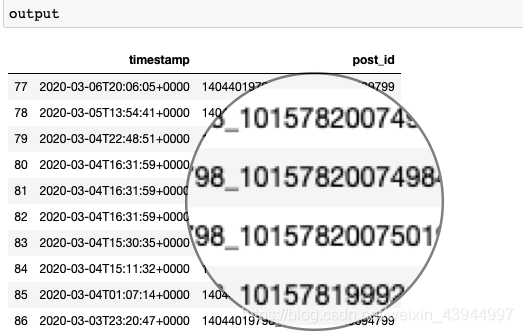
4.获取每条视频博文的相关数据
## 设定好想要获取的每条视频博文的信息
Fields = '?metric='+'post_video_views,post_video_view_time_by_region_id'
list_metrics=[ 'post_video_views','post_video_view_time_by_region_id']
def get_video_insights(output,fb_token):
final_output=pd.DataFrame()
for i in output.index.values:
post_id = output['post_id'][i]
Type = requests.get('https://graph.facebook.com/'+post_id+'?fields=type',params=fb_token).json()
if Type['type'] == 'video': #筛选出仅为视频的博文记录
try:
insights_output = requests.get('https://graph.facebook.com/'+post_id+'/insights{}&period=lifetime'.format(Fields),params=fb_token).json()
list1=list_metrics
metrics=[]
for j in range(0,len(list_metrics)):
metrics.append(insights_output['data'][j]['values'][0]['value'])
#print("metrics get")
metrics=DataFrame(metrics).T
metrics.columns=list1
col_name = metrics.columns.tolist()
col_name.insert(col_name.index('post_video_view_time_by_region_id'),'timestamp')
col_name.insert(col_name.index('timestamp'),'post_id')
metrics=metrics.reindex(columns=col_name).reset_index()
metrics['post_id']=output['post_id'][i]
metrics['timestamp']=output['timestamp'][i]
final_output=final_output.append(metrics)
except:
pass
return final_output
A saída é:
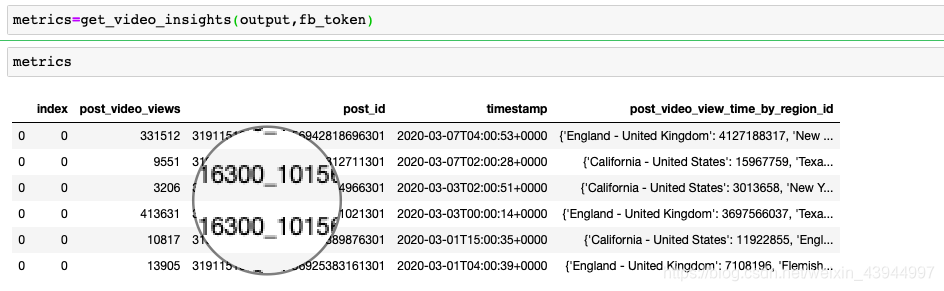
5.将json格式的数据整理成dataframe格式
A partir dos resultados acima, podemos ver que, nesta semana, o blogueiro publicou um total de 6 postagens em blog de vídeo, das quais a mais reproduzida é uma das 3,3, mais de 400.000 vezes. No entanto, o formato do indicador de tempo de exibição em várias regiões é o formato json, e precisamos lidar com isso separadamente.
Primeiro, observe a estrutura de dados da coluna da região:
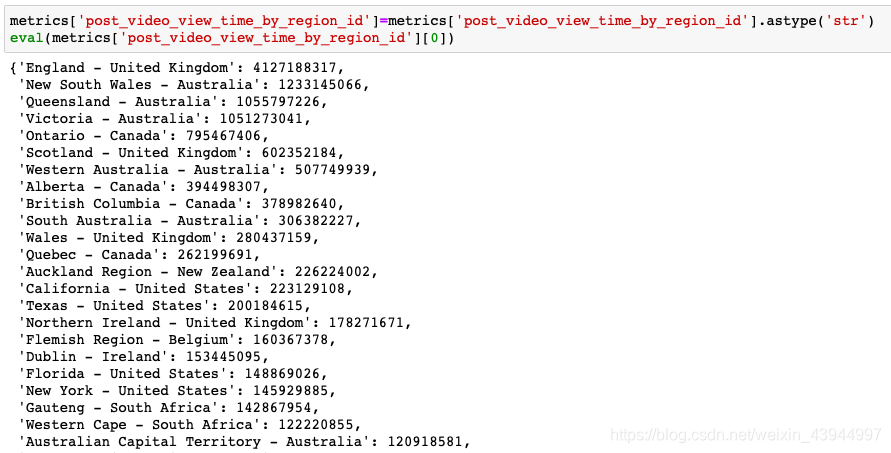
Como pode ser visto nos resultados acima, precisamos percorrer cada linha da coluna, gerar um novo da'ta'frame, usar cada país como uma coluna e armazenar os valores correspondentes um a um.
#遍历 post_video_view_time_by_region_id 这一列的每一行
Region=pd.DataFrame()
metrics.index=range(len(metrics)) #重新定义index
metrics['post_video_view_time_by_region_id']=metrics['post_video_view_time_by_region_id'].astype('str')
for j in metrics.index.values:
e=eval(metrics['post_video_view_time_by_region_id'][j]) #返回字符串内的值,直接返回一个dict
single_graph = []
for i in e.keys():
single_graph.append(e[i])
single=pd.DataFrame(single_graph).T
single.columns=list(e.keys())
Region=Region.append(single)
Os resultados são os seguintes:
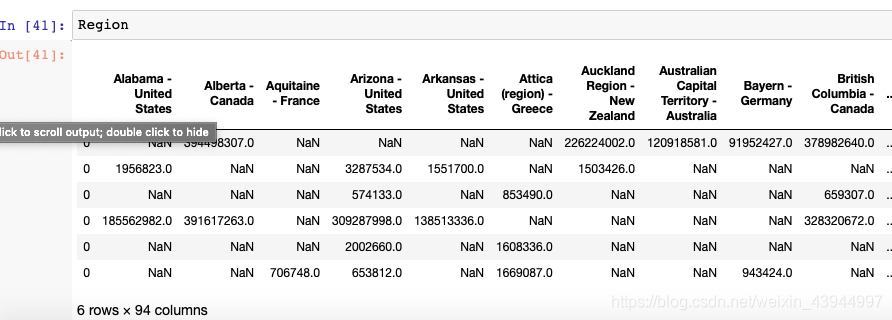
6. 将观看时长可视化
Primeiro, precisamos processar os dados na tabela Região. Precisamos dividir o nome de cada coluna em países e cidades. Isso é feito para mapear mais facilmente os dados acima para um mapa dos Estados Unidos e determinar visualmente quais usuários do estado preferem o conteúdo de vídeo do blogueiro.
o=Region.mean().to_dict() #算出每个城市的平均观看时长
dataset=pd.DataFrame(pd.Series(o),columns=['view time'])
dataset=dataset.reset_index().rename(columns={'index':'region'})
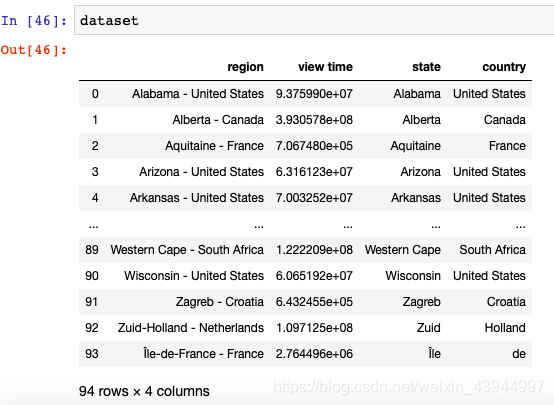
dataset['state']=dataset['region'].map(lambda x: x.split('-')[0]) #将列名分为国家和地区
dataset['country']=dataset['region'].map(lambda x: x.split('-')[1])#将列名分为国家和地区
O resultado processado é:
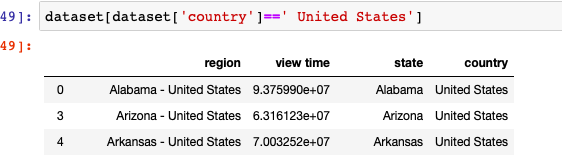
Finalmente, precisamos apenas filtrar as regiões dos Estados Unidos e converter os dados em um mapa dos Estados Unidos, e pronto.
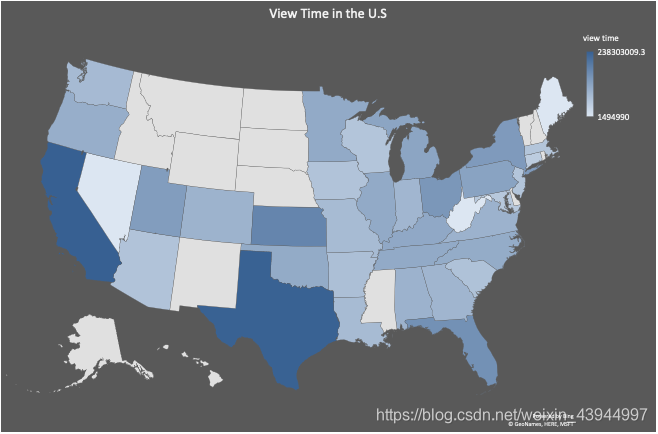
A partir do mapa, podemos analisar que o vídeo do blogueiro é amado pelo povo do Texas e da Califórnia, além de tentar constantemente atender às estratégias de vídeo dos usuários nesses dois estados, precisamos investigar mais por que outros estados Dos vídeos são muito mais curtos que eles. Com base nas informações acima, os blogueiros podem torná-lo mais geograficamente característico na produção posterior de vídeo e recomendar aos blogueiros que usem a função de distribuição regional do Facebook para distribuir diferentes características do conteúdo de vídeo para diferentes regiões, para atender com mais eficiência. Os gostos e hobbies dos usuários otimizam seu próprio trabalho de marketing de mídia.
A seguir, estão as etapas para rastrear dados usando a API do Facebook Graph. Se houver inadequações ou explicações incorretas, peça aos amigos para criticar e corrigir. :)
