Minha coluna do blog da CSDN: https://blog.csdn.net/yty_7
Endereço do Github: https://github.com/yot777/
No processo de pré-processamento de dados no aprendizado de máquina e no aprendizado profundo, uma etapa muito importante é normalizar e padronizar os dados.
O conceito de normalização
O que é normalização? Simplificando, é para calcular e unificar todos os dados em um intervalo especificado por meio do cálculo.Em geral, esse intervalo é de 0 a 1.
Fórmula normalizada
Como normalizar? Pode ser realizada pelas duas seguintes fórmulas:
(1) Fórmula do coeficiente de transformação
![]()
item representa todos os elementos em cada coluna da matriz
max é o valor máximo de todos os dados nesta coluna , min é o valor mínimo de todos os dados nesta coluna
A matriz original é a seguinte:
>>> import numpy as np
>>> data = np.array([[36,46],[45,25],[6,79]])
>>> print(data)
[[36 46]
[45 25]
[ 6 79]]Etapa 1: encontre os valores mínimo e máximo para cada coluna
>>> n_max=np.max(data,axis=0)
>>> print(n_max)
[45 79]
>>> n_min=np.min(data,axis=0)
>>> print(n_min)
[ 6 25]Etapa 2: subtrair o valor mínimo n_min de cada elemento da coluna de cada elemento da matriz original para obter o numerador da fórmula
>>> fenzi = np.subtract(data,n_min)
>>> print(fenzi)
[[30 21]
[39 0]
[ 0 54]]Explique: n_min é uma matriz unidimensional (, 2) , os dados são uma matriz bidimensional (3,2)
Devido à subtração subtract () da matriz, n_min é transmitida automaticamente pelo Python no cálculo e se torna uma matriz bidimensional (3, 2)
[[6 25]
[6 25]
[6 25]]
Portanto, o processo de cálculo de np.subtract (data, n_min) é

Etapa 3: subtrair o valor mínimo n_min de cada coluna do valor máximo n_max de cada coluna da matriz original para obter o denominador da fórmula
>>> fenmu = np.subtract(n_max,n_min)
>>> print(fenmu)
[39 54]Explique:
O resultado de np.subtract (n_max, n_min) é
[45 79] - [6 25] = [39 54]
Etapa 4: Divida o numerador pelo denominador para obter o valor final do coeficiente de transformação
>>> x = np.divide(fenzi,fenmu)
>>> print(x)
[[0.76923077 0.38888889]
[1. 0. ]
[0. 1. ]]Explique: fenzi é uma matriz bidimensional (3, 2), fenmu é uma matriz bidimensional (, 2)
Devido à divisão divide () da matriz, o fenmu é transmitido automaticamente pelo Python no cálculo e se torna uma matriz bidimensional (3, 2)
[[39 54]
[39 54]
[39 54]]
Portanto, o processo de cálculo de np.divide (fenzi, fenmu) é
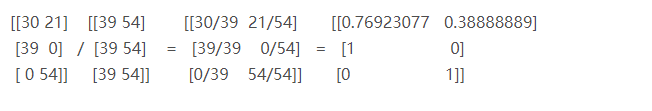
Após a proficiência, as 4 etapas acima podem ser concluídas com a seguinte linha, o código é o seguinte:
>>> x = np.divide(np.subtract(data,np.min(data,axis=0)),np.subtract(np.max(data,axis=0),np.min(data,axis=0)))
>>> print(x)
[[0.76923077 0.38888889]
[1. 0. ]
[0. 1. ]](2) Fórmula de conversão de intervalo
![]()
mx é o valor máximo do intervalo selecionado, mi é o valor mínimo do intervalo selecionado.
Em um caso especial, se o intervalo de valores a normalizar estiver entre 0 e 1, ou seja, mx = 1, quando mi = 0, não há necessidade de realizar a conversão do intervalo, pois:
![]()
Se precisarmos alterar a matriz x 'para -1 e 1, ou seja, quando mx = 1 e mi = -1:
>>> mx = 1
>>> mi = -1
>>> xx = x*(mx-mi)+mi
>>> print(xx)
[[ 0.53846154 -0.22222222]
[ 1. -1. ]
[-1. 1. ]]Explique: x é uma matriz bidimensional (3,2), mx-mi = 2, x * (mx-mi) é

O resultado final x * (mx-mi) + mi é

Conceito padronizado
Torne os dados em cada coluna o mais próximo possível da distribuição Gaussiana padrão (a média é 0, o desvio padrão é 1)
Fórmula padronizada
![]()
item representa todos os elementos em cada coluna da matriz, média é a média de todos os dados na coluna
σ é o desvio padrão de todos os dados na coluna
Nota: Média () função das numpy médios cálculos, [Sigma] pode ser uma função de numpy std () é calculado
Código:
>>> import numpy as np
>>> data = np.array([[36,46],[45,25],[6,79]])
>>> print(data)
[[36 46]
[45 25]
[ 6 79]]
#根据标准化的公式:X = (item - mean) / σ
#item代表数组每列中所有的元素,mean为该列所有数据的平均值,σ为该列所有数据的标准差
#mean可以由numpy的mean()函数计算
>>> n_mean = np.mean(data,axis=0)
>>> print(n_mean)
[29. 50.]
##σ可以由numpy的std()函数计算
>>> n_std = np.std(data,axis=0)
>>> print(n_std)
[16.673332 22.22611077]
#将mean和σ代入公式,得到最终结果
>>> xxx = np.divide(np.subtract(data,n_mean),n_std)
>>> print(xxx)
[[ 0.4198321 -0.17996851]
[ 0.95961623 -1.12480318]
[-1.37944833 1.30477168]]
Sumário
1. A fórmula normalizada é

item representa todos os elementos em cada coluna da matriz
max é o valor máximo de todos os dados nesta coluna , min é o valor mínimo de todos os dados nesta coluna
mx é o valor máximo do intervalo selecionado, mi é o valor mínimo do intervalo selecionado
Se o intervalo normalizado for 0 ~ 1 , não há necessidade de calcular a segunda fórmula
2. A fórmula padronizada é
![]()
item representa todos os elementos em cada coluna da matriz, média é a média de todos os dados na coluna
σ é o desvio padrão de todos os dados na coluna
função significativo () dos numpy médios cálculos, [Sigma] pode ser uma função de numpy std () é calculado
Minha coluna do blog da CSDN: https://blog.csdn.net/yty_7
Endereço do Github: https://github.com/yot777/
Se você acha que este capítulo é útil para você, seja bem-vindo a seguir, comentar e curtir! O Github recebe seu Follow e Star!
