papel Original: https://arxiv.org/pdf/1608.03981.pdf
I. Introdução
Honestamente, não vale a pena ler atentamente a última parte deste trabalho, um monte de conteúdo são discutidos experimentos, comparando a escrever prolixo. Menos conteúdo esclarecedor, depois de ler só conhecem o seu efeito modelo bom, mas não sabe muito bem porquê.
Foco do artigo :
-
Enfatizou a aprendizagem residual (resíduos de aprendizagem) e normalização lote (padronização lote) papel complementar na restauração da imagem, lata sob as condições de uma rede de profundidade, ainda pode trazer convergência rápida e bom desempenho.
-
Este artigo propõe DnCNN, remoção de ruído Gaussian em questão, com um único modelo para lidar com diferentes níveis de Gaussian ruído, você pode até utilizar um modelo único para lidar com remoção de ruído Gaussian, super-resolução, JPEG para bloquear problemas em três áreas.
Dois, modelo de rede DnCNN

arquitetura de rede:
Primeira parte: Conv (3 * 3 * C * 64) + Relu (c imagem representativa do número de canais)
Segunda parte: Conv (3 * 3 * 64 * 64) + BN (normalização em lotes) + Relu
Parte III: Conv (3 * 3 * 64)
Cada camada de preenchimento a zero, de tal modo que cada camada do tamanho de entrada e de saída permanece constante. A fim de evitar os limites (artifícios limítrofes) artificiais. Cada camada entre a segunda porção e a convolução são adicionados Relu lote padronização (normalização em lotes, BN).
Profundidade Arquitectura: profundidade DnCNN D dada por os três tipos de camadas, mostrando três cores diferentes na FIG. (I) CONV + Relu: Para a primeira camada, um tamanho de 64 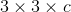
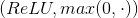
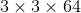
Em conclusão, o nosso modelo DnCNN tem duas características principais: o uso da fórmula resíduos para aprender a aprender R (y), e combinada com a massa normalizada para acelerar o treinamento e melhorar o desempenho de-noising. Por convolução e ligação Relu, DnCNN camada escondida por separar gradualmente a estrutura de imagem ruído observado. Este mecanismo é semelhante ruído iterativo EPLL e WNNM outros métodos utilizados na estratégia de eliminação, mas a nossa abordagem a ponta DnCNN à formação.
2.1. Residual aprender aprendizagem residual
DnCNN combina a aprendizagem residual ResNet, resumo conhecimento do ResNet, veja meu outro artigo: https://www.jianshu.com/p/11f1a979b384
DnCNN diferença não é uma ligação atalho é incrementado a cada duas camadas, mas a saída da rede directamente em imagem residual (imagem residual) fornecido imagem puro é x, com a imagem de ruído para y, assumindo y = x + v , então v é um imagens residuais. Isso não é uma verdadeira imagem do MSE entre a saída de rede e metas de otimização DnCNN de (erro médio quadrático), mas MSE entre os verdadeiros resíduos de imagem e saída da rede.
O ResNet em teoria, quando o residual é 0, equivalente à camada depositada entre o mapa de identidade, eo mapa de identidade é fácil de otimização de trem. Os autores observaram que no campo da restauração da imagem (especialmente no caso dos níveis de ruído pequenos), ruídos e imagens de retrato puras de resíduos é muito pequena, por isso, em teoria, a aprendizagem residual é muito adequado para usar a restauração da imagem.
Popular falando, um design tão rede que está na camada escondida de imagens reais do ruído original cancelamento x y na Fig. Os autores observam: no campo da super-sub, uma imagem de baixa resolução é formada sobre a operação de amostragem dupla de três imagens de alta-resolução, de modo que o super-sub na área de imagens residuais e Gaussian ruído para a área de imagens residuais são equivalentes, com há fotos em JPEG processamento de resíduos para desbloquear o campo. É também um resultado, a resposta às três modelos terão um problema com a possibilidade de eventualmente provou realmente eficaz.
2.2. Batch padronizado normalização lote
SGD (gradiente estocástico método descida) é amplamente utilizado o método de formação com a CNN, mas o desempenho da formação foi em grande medida por co-variáveis deslocamento interno afectados por este problema. BN é adicionada a cada uma das camadas antes de a normalização de processamento não-linear, de zoom, as operações de deslocamento para aliviar covariáveis mudança interna. O treinamento pode trazer mais velocidade, melhor desempenho, o impacto sobre a variável de inicialização de rede não tão grande.
mudança covariáveis interno (Shift interno covariável) : rede neural profundo como valores de entrada para a transformação não linear antes da activação, como os aprofunda profundidade, ou a rede durante o treino, a distribuição ou mudanças de deslocamento ocorrer gradualmente, a razão para a formação de convergência lento geralmente distribuídos para progressivamente a totalidade do intervalo de valor de função não linear, perto das extremidades do limite inferior (por função sigmóide, a entrada de activação valor médio WU + B é grande negativo ou valor positivo), isto resulta em reversa gradiente de propagação menor rede neural desaparecer, o que é a razão essencial para a formação de DNN convergem cada vez mais lento.
Lote normalização (Normalização LOTE) : é normalizada por alguns meios, a distribuição do valor de entrada de qualquer elemento deste redes neurais cada volta forçosamente puxados para variância zero unidade significativo é a distribuição normal padrão , isto é, quanto mais inclinado distribuição forçada de distribuição de volta mais padrão, de tal modo que o valor da entrada de activação cai função sensível não linear da região de entrada, apenas uma pequena mudança nos condutores de entrada para uma mudança maior na função de perda, de modo que meios que o gradiente se torna grande, problemas Evitar desaparecer gradiente e do gradiente se torna maiores meios de aprendizagem rápida convergência pode acelerar bastante o treinamento.
2.3 Rede de profundidade profundidade rede
Referência de "redes muito profundo convolucionais para reconhecimento de imagem em grande escala" padrão, o tamanho do kernel de convolução DnCNN está definido para 3 * 3, e remover todas as camadas celulares.
campo receptivo : o tamanho do diagrama característico de saída de uma região de rede para a camada de imagem de entrada mapeada rede neural convolucional.

Há vários casos do seguinte deve ser observado quando o cálculo campo receptivo:
- tamanho do campo receptivo da primeira camada da vista característica de saída convolução de uma camada de pixel é igual ao tamanho do filtro;
- Profundo convolução tamanho do campo receptivo antes de as camadas de filtro e seu tamanho e todas as etapas camadas relacionadas;
- Ao calcular o tamanho do campo receptivo, ignorando o impacto da borda da imagem, ou seja, sem levar em conta o tamanho do estofamento.
Além disso, em relação à descrição de cada camada de passos, caminha o passo é o produto de todas as camadas anteriores, isto é,
passos (i) = stride (1) * stride (2) * ... * passo (i-1)
Para redes individuais de convolução, que cada um mapa de características de ponto característica correspondente ao tamanho do campo receptivo é igual à convolução do tamanho original da camada de filtro de rede; convolucional de múltiplas camadas, em que camada de retorno de volta pela camada de, por iterativo obtenção da imagem de entrada original tamanho do campo receptivo, isto é, camada traseira convolução profundo tamanho do campo receptivo na camada de rede, e antes de tudo o tamanho do filtro e passo tem um relacionamento, no cálculo, o tamanho da imagem é ignorado no estofamento. Pode ser expresso como se segue, utilizando a fórmula:
r (i) = (r (i + 1) - 1) * passo (i) + C (i)
Em que, R (i) representa o i-ésimo tamanho camada campo receptivo, passo (i) representa o i-ésimo passo camada, c (i) representa o i-ésimo camada do tamanho do núcleo convolução.
Além disso, para a camada de função de activação da rede de convolução (Relu / sigmóide / ...) e semelhantes, como campos receptivos iteração fórmula:
r (i) = r (i + 1)
Para rede DnCNN, quando d é o número de camadas da rede, a rede é o campo receptivo (2d + 1) * (2d + 1). DnCNN campo receptivo associada com profundidade de rede d, e a rede neural de convolução pode ser comparado com o tamanho efectivo remendo algoritmo A suavização convencionais campo receptivo . Portanto, o mais corrente principal de vários algoritmo A suavização de referência, de acordo 2d + 1 = tamanho eficaz remendo, inverter lançamento DnCNN uma profundidade de rede adequado.
Finalmente, no caso em que o nível de ruído é de 25, os autores seleccionado EPLL 36 * 36 como um padrão de referência, porque EPLL comparação horizontal de mínima dimensão do adesivo eficaz (se DnCNN seleccionar o menor campo receptivo pode superar estes algoritmos tradicionais, que mostra DnCNN hardware muito rápido). Profundidade processo denoising DnCNN é Gaussian 17, um general profundidade DnCNN 20 tarefa denoising.
Em terceiro lugar, experiência
Os autores realizaram três experimentos:
-
Contraste afetam se o aprendizado residual e efeito normalização lote na recuperação, a velocidade de convergência, e, finalmente, provar que os dois são complementares, e utilizar todos os aspectos da rede para alcançar o melhor desempenho.
-
De acordo com um determinado grau de Gaussian ruído formação DnCNN-S, de acordo com o grau variável de Gaussian ruído formação DnCNN-B, dependendo do grau de ruído (ruído gaussiano de diferentes níveis, incluindo vários graus de resolução, os diferentes níveis de JPEG codificada) Formação DnCNN-3 para a frente com outros algoritmos para fazer experimentos comparativos. Conclusão: DnCNN-S tem a melhor performance, mas também o desempenho DnCNN-B melhor do que outros, provou DnCNN-B tem uma capacidade muito boa para cegar Gaussian ruído; DnCNN-3, em seguida, a prova de não ter DnCNN-3 generalização restaurado imagem do vulgar.
-
Comparação da velocidade experimental de DnCNN e outro algoritmo de remoção de ruído de ponta, a conclusão: a velocidade é boa, o próximo CPU \ ambiente GPU pertencem aos níveis médios e superiores.
Reimpressão artigo Fonte: https: //www.jianshu.com/p/3687ffed4aa8