Arquitectura de agendamento no segundo escalonamento de dois níveis é programado para completar a estrutura, normalmente, uma moldura é calculado, tal como Hadoop, faísca semelhantes;
programadores com base nestes cálculos quadro, pode completar o cálculo de diferentes tipos e tamanhos.
A natureza da computação distribuída está em um ambiente distribuído, a coordenação de vários processos para concluir um assunto complexo;
cada carry processo das suas funções, após a conclusão do seu trabalho, e depois para os outros processos para outro trabalho completo;
pois não há dependência trabalho, inter-processo pode ser executado em paralelo.
1 MapReduce
A idéia central: dividir para reinar, do JDK fork-join É neste quadro de pensamento
passos:
1 uma vista explodida problema original (Mapa): problema original é decomposto em um número de menor, independentes uns dos outros, e os mesmos problemas, sob a forma de sub-problemas originais;
2 subproblems: Se sub-problemas menores a ser resolvido directamente e facilmente resolvido, de outro modo de forma recursiva resolver cada sub-problema;
3 A solução combinada (Redução): A solução de problemas de vários sub-incorporada pela solução problema original
MapReduce inclui principalmente os seguintes três componentes:
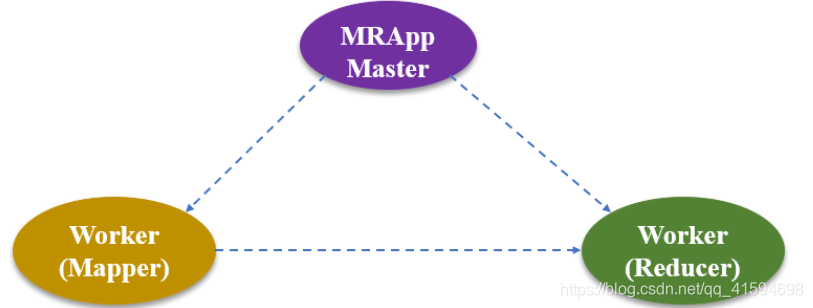
Master (MRAppMaster): responsável pela atribuição de tarefas, executando tarefas de coordenação e mapa de atribuição é função Mapper () para manipular, para atribuir Redutor reduzir operação function ();
trabalhador Mapper: função Mapa é responsável pela função, isto é, ; responsável pela execução sub-tarefa
resultados Reduzir função é responsável por função, que é responsável pela síntese de cada sub-tarefa: trabalhador Redutor
fluxograma de trabalho:
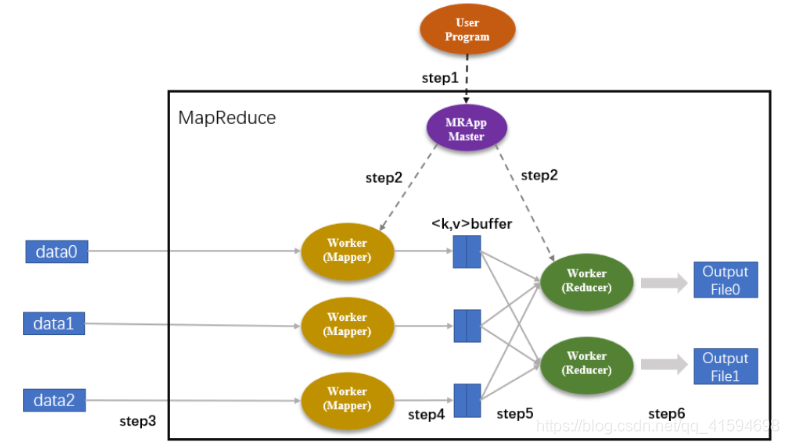
Depois de executar tarefas de MapReduce para completar todo o processo tarefa é longo, é um modo de missão curta;
iniciar e processo de tarefa parada é muito demorado, por isso MapReduce não é adequado para a tarefa processamento em tempo real: ele vai de dados primeiro coletar e seu cache, espera até que o cache é dados completos de processamento de início. Assim, uma desvantagem é que a massa calculada, a partir da aquisição de dados para o momento dos resultados do cálculo obtido por um longo tempo
2 Corrente
A principal tarefa é lidar com o tempo real para streaming de dados, requisitos de alto processamento de atraso, em geral, exige um processo de serviço permanente, esperando a chegada dos dados a qualquer momento, a qualquer momento, de modo a garantir baixa latência;
calcular o modo de tarefa de fluxo de dados, em campo distribuído chamado Stream.
Em que o fluxo de dados: como dados de áudio e vídeo live streaming gerado
Os dados contínuos chegar rapidamente;
dados de grande escala (TB, PB);
Altas exigências em tempo real, ao longo do tempo, irá reduzir significativamente o valor dos dados
Os dados não podem garantir a ordem, o que significa que o sistema não pode controlar a ordem de elementos de dados a serem processados.
Uma vez que os dados vão ser processadas imediatamente, quando os dados são processados, armazenados no cache são serializados, e, em seguida, transmitidas através da rede imediatamente para o próximo nó, continua a processar o próximo nó;
cálculo do fluxo, não serão armazenados quaisquer dados, teria sido em circulação
passos:

A fim de processamento em tempo útil do fluxo de dados, o fluxo deve ser calculada latência quadro, escalável, altamente fiável
3 Ator
modo de cálculo MapReduce e fluxo, enquanto os dados são tratados de forma diferente, mas eles são um tipo específico de dados (que correspondem aos dados estáticos e os dados dinâmicos) é calculado como uma dimensão
oleoduto Ator e o processo ou os processos são calculados como uma dimensão de
Ator representa um paralelo distribuído modelo de computação;
este modelo tem o seu próprio conjunto de regras que a lógica interna de computação um actor, e uma comunicação entre a pluralidade de regras Ator;
no modelo Ator, cada sistema corresponde Ator de um componente, que representa a unidade de computação de base;
modelo de cálculo com programação orientada para o objecto convencional (OOP) é semelhante a um objecto recebe um pedido de chamada de método (semelhante a uma mensagem), desse modo para executar o método;
no entanto, porque os dados são encapsulados num objecto OOP, não pode ser acedido do lado de fora quando, isto é, de uma maneira sincronizada acessível por uma pluralidade de chamada de método objecto exterior, haverá impasses, problemas de corrida, sistemas distribuídos podem não satisfazer a procura em alta simultaneidade;
o modelo de agente através de uma comunicação de mensagens usando o modo assíncrono (fila), supera as limitações da OOP, o sistema de distribuição adequado para altamente concorrente.
Ator modelo é de três elementos de estado, de comportamento e de mensagens: modelo Ator = (+ comportamento de estado) + mensagem
State (Estado): Informações componente Ator em si, o equivalente a objeto OOP atributos;
o Estado será afetada Ator Ator seu próprio comportamento, e só pode ser alterado a sua própriaComportamento (comportamento): cálculo Ator operações de processamento, correspondente ao objecto função OOP membro;
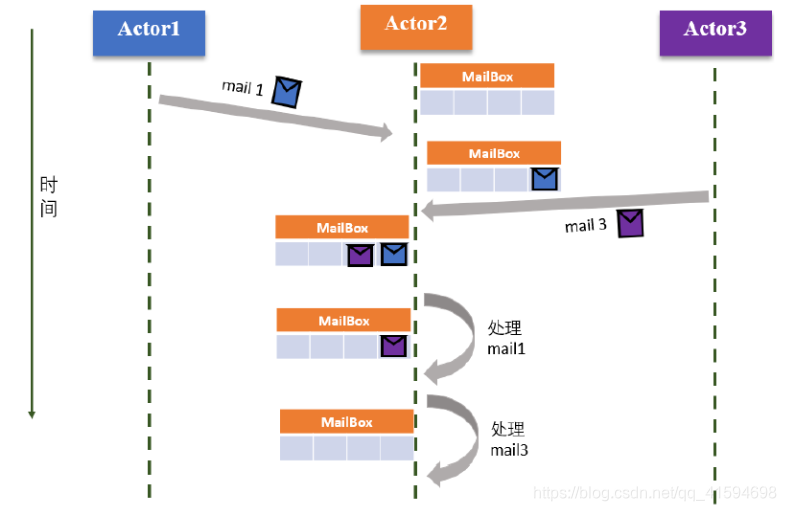
não é possível carregar a lógica de cálculo entre outros Ator Ator. Ator receber apenas mensagens irá acionar o seu comportamento de computaçãoMensagem (Mail): Ator entrega de mensagens por meio de comunicação de mensagens entre uma pluralidade de Ator, Ator cada um tem a sua própria caixa de correio (caixa de correio), para receber uma mensagem de outro Ator, portanto, mensagens Ator modelo, também conhecido como e-mail;
em geral, para o interior da mensagem a caixa de correio, ler o Agente é conseguido de acordo com a mensagem de pedido (FIFO) e processados
Princípio de funcionamento: ver FIG fila para processamento utilizando Actor2
vantagens:
Para atingir um nível maior de abstração do que OOP: comunicação assíncrona entre Ator, múltiplos Ator pode ser executado de forma independente e não será perturbado, para resolver os problemas de concorrência em OOP
Sem bloqueio: modelo de agente através da introdução do mecanismo de passagem de mensagens, de modo a evitar o entupimento
Sem o uso de bloqueios: Ator só pode ler uma mensagem da caixa de correio, isto é, Actor interna só pode lidar com uma mensagem, ao mesmo tempo, é um mutex natural, de forma que nenhum bloqueio código adicional
alta concorrente: Cada Ator caixa de correio apenas processamento de mensagens local, e, portanto, uma pluralidade de trabalho Ator paralela, melhorando assim a todo distribuído sistema de processamento paralelo
Fácil expansão: cada ator pode criar vários Ator, reduzindo assim a carga de trabalho de um único ator,
quando o punho Ator local, no entanto, eles podem começar Ator no nó remoto em seguida, encaminha a mensagem no passado.
desvantagens:
falta Ator de herança e estratificação, código pequena reutilização
Ator criar dinamicamente múltipla ator, faz com que o comportamento de toda a mudança ator modelo, não é fácil de alcançar
aumento ator, ele também iria aumentar a sobrecarga do sistema
Não se aplica a sistemas de requisitos rigorosos para a seqüência de processamento de mensagens;
porque as mensagens são mensagens assíncronas, não pode determinar a ordem de execução de cada mensagem;
melhorias: Você pode pedir para resolver o problema, bloqueando Ator, mas irá afetar seriamente o modelo de tarefas de Ator eficiência
Cena: Akka
4 linhas
Um grande tarefa em várias etapas, processos diferentes podem ser utilizados em diferentes passos realizados, de modo que as diferentes tarefas podem ser realizadas em paralelo, melhorando assim a eficiência do sistema
Cena: processamento gasoduto aprendizagem de máquina
Modo MapReduce e o modo de pipeline, haverá uma grande tarefa em várias subtarefas, a diferença é que a relação entre o tamanho de partícula e subtarefas dividindo:
tarefa granularidade MapReduce, a tarefa é dividida em uma grande pluralidade de tarefas menores, cada tarefa tem de executar uma, a mesma etapa concluída, a mesma tarefa pode ser executada em paralelo, pode ser dito para ser um paralelo computação modelo de tarefas;
computação gasoduto modo de tamanho do passo, uma tarefa em várias etapas, cada uma realizada por uma tipos diferentes de lógica da pluralidade de tarefas, o mesmo passo de sobrepor a execução em paralelo de diferentes tarefas de computação, pode ser considerado um padrão de dados paralela .MapReduce respectiva sub-tarefa pode ser realizada de forma independente, sem perturbar o outro, uma pluralidade de subtarefas executada, os resultados combinados para dar os resultados globais da tarefa, e, portanto, não é necessária entre as dependências subtarefa;
o modo de canal está entre a pluralidade de subtarefas têm uma relação de dependência, a saída de uma subtarefa entrada anterior após uma subtarefa
MapReduce tarefa paralelismo para o cenário modo de cálculo, o modo de cálculo pipeline para a cena do mesmo tipo de tarefa de processamento de dados em paralelo.
