Autor: Tarun Gupta
deephub tradução Grupo: Meng Xiangjie
Neste artigo, vamos olhar para usar NumPy como um programa escrito em Python3 biblioteca de processamento de dados para aprender a implementar (lote) de regressão linear usando o método do gradiente de descida.
Vou explicar gradualmente o princípio de funcionamento e com o princípio de cada parte do código do código.
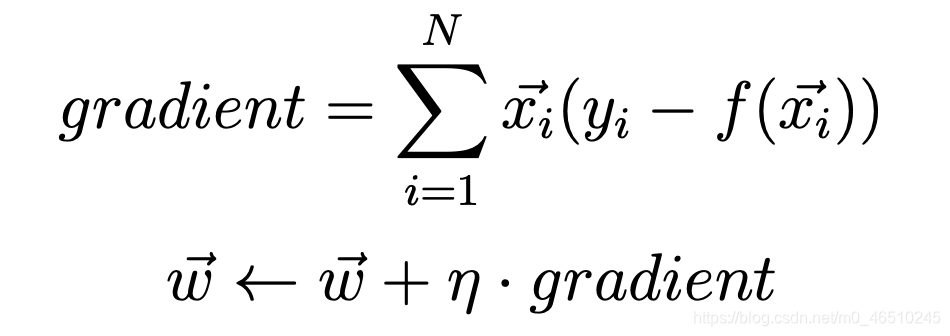
Vamos utilizar esta fórmula para calcular o gradiente.
Aqui, x (i) é um vector de um ponto, em que N é o tamanho do conjunto de dados. n (eta) é a nossa taxa de aprendizagem. y (i) é um vector de saída de destino. f (x) é definido como o vector f (x) = Soma (w * x) de uma função de regressão linear, onde sigma é a função de soma. Além disso, vamos considerar a diferença inicial w0 = 0 e tal que x0 = 1. Todos os pesos são inicializados a 0.
Neste método, foi utilizada a soma da função perda erro quadrado.
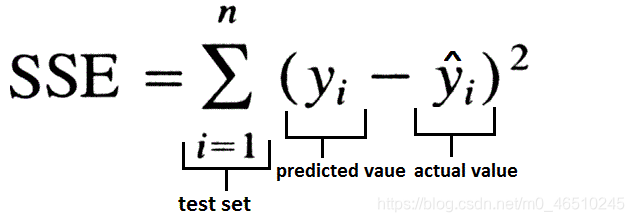
Só que SSE é inicializado para zero, vamos gravar as mudanças em cada iteração do SSE, e comparados com um valor limite previsto antes da execução do programa. Se SSE está abaixo do limite, o programa sai.
Neste programa, nós fornecemos três entradas a partir da linha de comando. São eles:
limite - o valor limite, antes dos termina algoritmo, a perda deve ser abaixo deste limiar.
Dados - Posição conjunto de dados.
learningRate - taxa de aprendizagem método de gradiente de descida.
Portanto, o início do programa deve ficar assim:
python3linearregr.py — datarandom.csv — learningRate 0.0001 — threshold 0.0001
Antes de mergulhar no código identificamos última coisa, a saída do programa seria a seguinte:
iteration_number,weight0,weight1,weight2,...,weightN,sum_of_squared_errors
O programa inclui seis partes, uma por uma, vemos.
módulo de importação
import argparse # to read inputs from command lineimport csv # to read the input data set fileimport numpy as np # to work with the data set
inicialização parte
# initialise argument parser and read argumentsfrom command line with the respective flags and then call the main() functionif __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("-d", "--data", help="Data File")
parser.add_argument("-l", "--learningRate", help="Learning Rate")
parser.add_argument("-t", "--threshold", help="Threshold")
main()
parte principal função
defmain():
args = parser.parse_args()
file, learningRate, threshold = args.data, float(
args.learningRate), float(args.threshold) # save respective command line inputs into variables# read csv file and the last column is the target output and is separated from the input (X) as Ywith open(file) as csvFile:
reader = csv.reader(csvFile, delimiter=',')
X = []
Y = []
for row in reader:
X.append([1.0] + row[:-1])
Y.append([row[-1]])
# Convert data points into float and initialise weight vector with 0s.
n = len(X)
X = np.array(X).astype(float)
Y = np.array(Y).astype(float)
W = np.zeros(X.shape[1]).astype(float)
# this matrix is transposed to match the necessary matrix dimensions for calculating dot product
W = W.reshape(X.shape[1], 1).round(4)
# Calculate the predicted output value
f_x = calculatePredicatedValue(X, W)
# Calculate the initial SSE
sse_old = calculateSSE(Y, f_x)
outputFile = 'solution_' + \
'learningRate_' + str(learningRate) + '_threshold_' \
+ str(threshold) + '.csv''''
Output file is opened in writing mode and the data is written in the format mentioned in the post. After the
first values are written, the gradient and updated weights are calculated using the calculateGradient function.
An iteration variable is maintained to keep track on the number of times the batch linear regression is executed
before it falls below the threshold value. In the infinite while loop, the predicted output value is calculated
again and new SSE value is calculated. If the absolute difference between the older(SSE from previous iteration)
and newer(SSE from current iteration) SSE is greater than the threshold value, then above process is repeated.
The iteration is incremented by 1 and the current SSE is stored into previous SSE. If the absolute difference
between the older(SSE from previous iteration) and newer(SSE from current iteration) SSE falls below the
threshold value, the loop breaks and the last output values are written to the file.
'''with open(outputFile, 'w', newline='') as csvFile:
writer = csv.writer(csvFile, delimiter=',', quoting=csv.QUOTE_NONE, escapechar='')
writer.writerow([*[0], *["{0:.4f}".format(val) for val in W.T[0]], *["{0:.4f}".format(sse_old)]])
gradient, W = calculateGradient(W, X, Y, f_x, learningRate)
iteration = 1whileTrue:
f_x = calculatePredicatedValue(X, W)
sse_new = calculateSSE(Y, f_x)
if abs(sse_new - sse_old) > threshold:
writer.writerow([*[iteration], *["{0:.4f}".format(val) for val in W.T[0]], *["{0:.4f}".format(sse_new)]])
gradient, W = calculateGradient(W, X, Y, f_x, learningRate)
iteration += 1
sse_old = sse_new
else:
break
writer.writerow([*[iteration], *["{0:.4f}".format(val) for val in W.T[0]], *["{0:.4f}".format(sse_new)]])
print("Output File Name: " + outputFile
função principal do processo é como se segue:
- A linha de comando correspondente na entrada para uma variável
- Lendo o arquivo CSV, o último é uma saída de destino, e a entrada (armazenados como X) e armazenado como Y separado
- Converter o ponto de dados de ponto flutuante de inicialização vector de pesos para os 0s
- Use calculatePredicatedValue funcionar para calcular o valor previsto da saída
- função SSE usadas para calcular o calculateSSE inicial
- O arquivo de saída é aberto no modo de gravação, os dados são gravados no formato mencionado no artigo. Depois de escrever o primeiro valor, e usando a função gradiente de cálculo calculateGradient peso atualizado. número variável de repetições realizado para determinar a regressão linear realizado em modo descontínuo antes valores da função perda abaixo de um limiar. Enquanto num ciclo infinito, mais uma vez calculado o valor de saída previsto, e o cálculo de um novo valor de SSE. Se o velho (iteração anterior de SSE) ea mais recente a diferença absoluta entre (SSE da iteração atual) é maior que o valor limite, em seguida, repita o processo. Aumentar o número de iterações 1, SSE está armazenado em SSE anterior. Se o mais velho (iteração anterior de SSE) ea mais recente a diferença absoluta entre o (iteração atual do SSE) está abaixo do limite, o ciclo é interrompido, e o valor da produção final escrito para o arquivo.
calculatePredicatedValuefunção
Aqui, o produto é calculada através da realização da matriz de saída e de entrada previsto X W representa os pontos de matriz de peso.
# dot product of X(input) and W(weights) as numpy matrices and returning the result which is the predicted outputdefcalculatePredicatedValue(X, W):
f_x = np.dot(X, W)
return f_x
calculateGradientfunção
Gradiente calculada utilizando uma fórmula primeiro mencionada no artigo e actualizar os pesos.
defcalculateGradient(W, X, Y, f_x, learningRate):
gradient = (Y - f_x) * X
gradient = np.sum(gradient, axis=0)
temp = np.array(learningRate * gradient).reshape(W.shape)
W = W + temp
return gradient, W
calculateSSEfunção
SSE é calculado utilizando a equação acima.
defcalculateSSE(Y, f_x):
sse = np.sum(np.square(f_x - Y))
return sse
Agora, leia o código completo. Vamos olhar os resultados da implementação do programa.

Isto é como a saída:
00.00000.00000.00007475.31491-0.0940-0.5376-0.25922111.51052-0.1789-0.7849-0.3766880.69803-0.2555-0.8988-0.4296538.86384-0.3245-0.9514-0.4533399.80925-0.3867-0.9758-0.4637316.16826-0.4426-0.9872- 0.4682254.51267-0.4930-0.9926-0.4699205.84798-0.5383-0.9952-0.4704166.69329-0.5791-0.9966-0.4704135.029310-0.6158-0.9973-0.4702109.389211-0.6489-0.9978-0.470088.619712-0.6786-0.9981-0.469771. 794113-0.7054-0.9983-0.469458.163114-0.7295-0.9985-0.469147.120115-0.7512-0.9987-0.468938.173816-0.7708-0.9988-0.468730.926117-0.7883-0.9989-0.468525.054418-0.8042-0.9990-0.468320.297519- 0.8184-0.9991-0.468116.443820-0.8312-0.9992-0.468013.321821-0.8427-0.9993-0.467810.792522-0.8531-0.9994-0.46778.743423-0.8625-0.9994-0.46767.083324-0.8709-0.9995-0.46755.738525-0.8785- 0.9995-0.46744.649026-0.8853-0.9996-0.46743.766327-0.8914-0.9996-0.46733.051228-0.8969-0.9997-0.46722.471929-0.9019-0.9997-0.46722.002630-0.9064-0.9997-0.46711.622431-0.9104-0.9998-0.46711.314432-0.9140-0.9998-0.46701.064833-0.9173-0.9998-0.46700.862634-0.9202-0.9998-0.46700.698935- 0.9229-0.9998-0.46690.566236-0.9252-0.9999-0.46690.458737-0.9274-0.9999-0.46690.371638-0.9293-0.9999-0.46690.301039-0.9310-0.9999-0.46680.243940-0.9326-0.9999-0.46680.197641-0.9340- 0.9999-0.46680.160142-0.9353-0.9999-0.46680.129743-0.9364-0.9999-0.46680.105144-0.9374-0.9999-0.46680.085145-0.9384-0.9999-0.46680.069046-0.9392-0.9999-0.46680.055947-0.9399-1.0000- 0.46670.045348-0.9406-1.0000-0.46670.036749-0.9412-1.0000-0.46670.029750-0.9418-1.0000-0.46670.024151-0.9423-1.0000-0.46670.019552-0.9427-1.0000-0.46670.015853-0.9431-1.0000-0.46670. 012854-0.9434-1.0000-0.46670.010455-0.9438-1.0000-0.46670.008456-0.9441-1.0000-0.46670.006857-0.9443-1.0000-0.46670.005558-0.9446-1.0000-0.46670.004559-0.9448-1.0000-0.46670.003660-0.9450-1.0000-0.46670.002961-0.9451-1.0000-0.46670.002462-0.9453-1.0000-0.46670.001963-0.9454-1.0000-0.46670.001664-0.9455-1.0000- 0.46670.001365-0.9457-1.0000-0.46670.001066-0.9458-1.0000-0.46670.000867-0.9458-1.0000-0.46670.000768-0.9459-1.0000-0.46670.000569-0.9460-1.0000-0.46670.000470-0.9461-1.0000-0.46670. 0004
O programa final
import argparse
import csv
import numpy as np
defmain():
args = parser.parse_args()
file, learningRate, threshold = args.data, float(
args.learningRate), float(args.threshold) # save respective command line inputs into variables# read csv file and the last column is the target output and is separated from the input (X) as Ywith open(file) as csvFile:
reader = csv.reader(csvFile, delimiter=',')
X = []
Y = []
for row in reader:
X.append([1.0] + row[:-1])
Y.append([row[-1]])
# Convert data points into float and initialise weight vector with 0s.
n = len(X)
X = np.array(X).astype(float)
Y = np.array(Y).astype(float)
W = np.zeros(X.shape[1]).astype(float)
# this matrix is transposed to match the necessary matrix dimensions for calculating dot product
W = W.reshape(X.shape[1], 1).round(4)
# Calculate the predicted output value
f_x = calculatePredicatedValue(X, W)
# Calculate the initial SSE
sse_old = calculateSSE(Y, f_x)
outputFile = 'solution_' + \
'learningRate_' + str(learningRate) + '_threshold_' \
+ str(threshold) + '.csv''''
Output file is opened in writing mode and the data is written in the format mentioned in the post. After the
first values are written, the gradient and updated weights are calculated using the calculateGradient function.
An iteration variable is maintained to keep track on the number of times the batch linear regression is executed
before it falls below the threshold value. In the infinite while loop, the predicted output value is calculated
again and new SSE value is calculated. If the absolute difference between the older(SSE from previous iteration)
and newer(SSE from current iteration) SSE is greater than the threshold value, then above process is repeated.
The iteration is incremented by 1 and the current SSE is stored into previous SSE. If the absolute difference
between the older(SSE from previous iteration) and newer(SSE from current iteration) SSE falls below the
threshold value, the loop breaks and the last output values are written to the file.
'''with open(outputFile, 'w', newline='') as csvFile:
writer = csv.writer(csvFile, delimiter=',', quoting=csv.QUOTE_NONE, escapechar='')
writer.writerow([*[0], *["{0:.4f}".format(val) for val in W.T[0]], *["{0:.4f}".format(sse_old)]])
gradient, W = calculateGradient(W, X, Y, f_x, learningRate)
iteration = 1whileTrue:
f_x = calculatePredicatedValue(X, W)
sse_new = calculateSSE(Y, f_x)
if abs(sse_new - sse_old) > threshold:
writer.writerow([*[iteration], *["{0:.4f}".format(val) for val in W.T[0]], *["{0:.4f}".format(sse_new)]])
gradient, W = calculateGradient(W, X, Y, f_x, learningRate)
iteration += 1
sse_old = sse_new
else:
break
writer.writerow([*[iteration], *["{0:.4f}".format(val) for val in W.T[0]], *["{0:.4f}".format(sse_new)]])
print("Output File Name: " + outputFile
defcalculateGradient(W, X, Y, f_x, learningRate):
gradient = (Y - f_x) * X
gradient = np.sum(gradient, axis=0)
# gradient = np.array([float("{0:.4f}".format(val)) for val in gradient])
temp = np.array(learningRate * gradient).reshape(W.shape)
W = W + temp
return gradient, W
defcalculateSSE(Y, f_x):
sse = np.sum(np.square(f_x - Y))
return sse
defcalculatePredicatedValue(X, W):
f_x = np.dot(X, W)
return f_x
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument("-d", "--data", help="Data File")
parser.add_argument("-l", "--learningRate", help="Learning Rate")
parser.add_argument("-t", "--threshold", help="Threshold")
main()
Este artigo descreve os conceitos matemáticos usando um método de gradiente de descida para a regressão linear lote. Aqui, considerando a função de perda (neste caso como a soma dos erros quadrados). Nós não vemos um método para minimizar o SSE, e isso não deve acontecer (para ajustar a taxa de aprendizagem), vimos como a convergência de regressão linear com a ajuda do limiar.
O programa utiliza dados de processo numpy pode ser usado sem utilizar os princípios de numpy pitão para completo, mas irá exigir nested loops, o tempo irá aumentar a complexidade de O (N * N). Em qualquer caso, maior a eficiência da memória matrizes numpy e matrizes fornecido. Além disso, se você preferir usar pandas módulo, recomendamos que você usá-lo, e tentar usá-lo para conseguir o mesmo procedimento.
Eu espero que você gostou deste artigo. Obrigado pela leitura.

