현재 추천 시스템에서 컴퓨터를 사용하는 학습의 많은 일부는 학습의 깊이를 사용했다. 그래서, 학습 알고리즘 기계는 그것의 더미에 해당?
대답은 : ≠ 기계 학습 알고리즘.
≠ 기계 학습 알고리즘
우리가 교과서 나 대학 강의를 열 때, 알고리즘의 무리는 일반적으로 볼 수 있습니다 나열합니다.
이것은 또한 당신이 그런 오해를 야기 할 수 있습니다 : 기계 학습 알고리즘의 일련의 것입니다. 사실, 기계 학습 알고리즘에서 멈추지 않는다, 우리는이 문제에 대한 포괄적 인 솔루션으로 볼 수 있습니다. 우리는 별도의 알고리즘을 볼 수 있지만 빙산의 문제, 도전의 나머지는 우리가 제대로 이러한 알고리즘을 사용합니까 방법이다.
왜 그렇게 마법의 기계 학습?
기계 학습, 데이터 분석은 컴퓨터를 가르치고 사람들이 연습이나 결정을 예측하는 법을 발견하는 것입니다.
진정한 의미의 학습 기계를 들어, 컴퓨터는 법의 해석으로 요구할 수없는 데이터를 프로그램 할 수있는 능력이 있어야합니다.
예 :
아이가 집에서 놀고 경우, 갑자기, 그는 촛불을 보았다! 그래서 그는 천천히 촛불을 향해 걸어 갔다.
호기심, 그는 촛불에 손가락을 가리키는되었다
! "와우"그는 소리 쳤다, 다시에 손;
! "흠 ...... 붉은 노을을 누르면 무언가는"
이틀 후, 그는 확인하기 위해 부엌으로 갔다 난로에. 또한, 그는 매우 궁금했다.
그는 매우, 매우 호기심, 그리고 내 마음은 터치하지 않으려는,
갑자기, 그는 빛나는이 일, 빨간색 발견!
"아 ......"그는 "나는 다시 한 번 고통을하지 않습니다!"자신에게 말했다
그는 빨간색과 빛나는 일 것이다 "고통을"기억, 그래서 그는 난로의 다른 부분으로 이동 떠났다. 
아이는 우리가 전화 결론 어떤 종류의에서 자신의 촛불 추론하기 때문에, 더 명확하게 넣어 "기계 학습."
"빨간색이되고"는 "고통"을 의미한다 : 결론은
멀리로에서, 부모가 그를 경고 때문에 아이는, 그것은보다는 기계 학습 "프로그램의 명확한 표시"인 경우.
중요한 용어
모델 - 데이터로부터 유도 패턴의 집합;
알고리즘 - 특정 ML 모델에 대한 훈련의 과정;
교육 자료 - 모델을 훈련하는 데 사용되는 데이터 수집 알고리즘;
테스트 데이터 - 모델의 성능의 객관적인 평가를위한 새로운 데이터 세트;
상기 식에서 - 모델 변수를 훈련하는 데 사용되는 데이터 세트;
목표 변수 - 예측 특정 변수;
예 :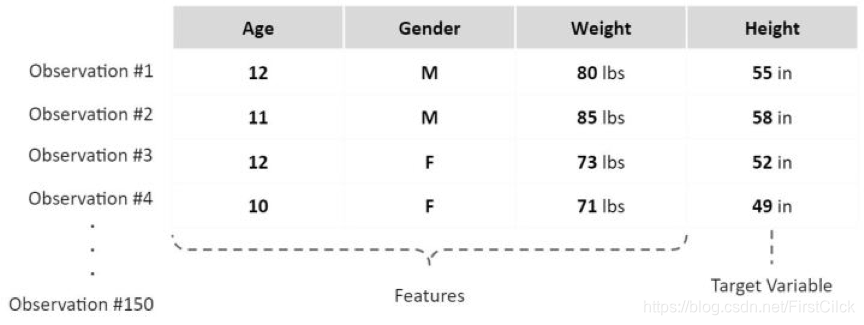
假设我们有一组包含150个小学生信息的数据集,现在希望通过他们的年龄、性别和体重预测他们的身高。
我们现在有150组数据点、1个目标变量(身高)、3个特征(年龄、性别、重量)。接下来会把所有数据分为两个子集:
其中,120组会被用来训练不同的模型(训练集),其余的30组用来选择最佳模型(测试集)。
机器学习任务
在学术界,机器学习始于并会一直专注于其中某个算法。但是,在工业界,我们首先得为工作所需选择正确的机器学习任务。
· 任务是算法的特定目标。
·只要选择正确的任务,算法就可以交换进出完成任务。
·实际上,我们会尝试多种不同算法,因为很可能我们一开始不知道哪种算法最适合数据集。
机器学习两种最常见的任务类别是监督学习和无监督学习。
监督学习
监督学习包括面向“标记”好的数据的任务(换言之,我们有一个目标变量)。
· 在实践中,它通常是用作建模预测的高级形式。
· 每一组数据点必须正确标记。
· 只有这样才能建立一个预测模型,因为我们必须在训练时告诉算法什么是“正确”的(也就是我们说的“监督”)。
· 回归是建模连续目标变量的任务。
·分类是对分类目标变量进行建模的任务。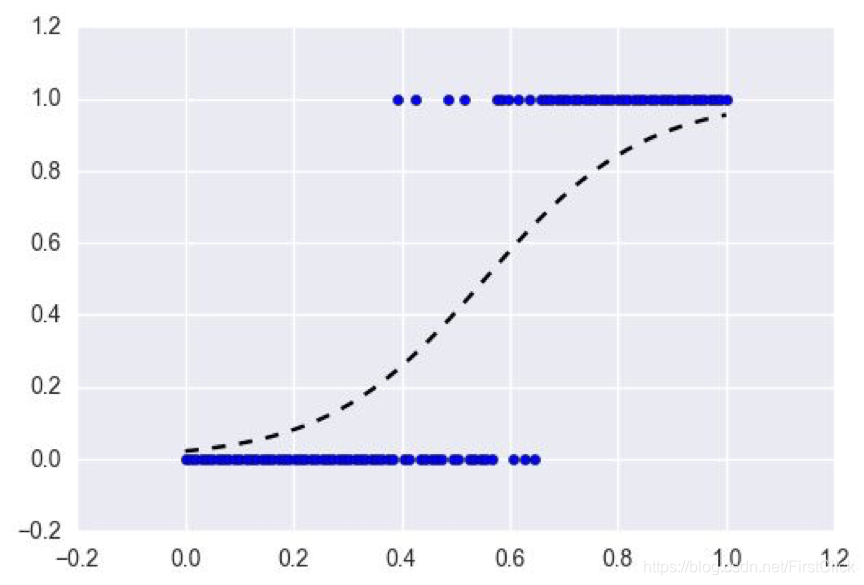
无监督学习
无监督学习包括面向“未标记”数据的任务(换言之,没有目标变量)。
· 在实践中,这种形式通常用作自动数据分析或自动信号提取。
· 未标记的数据没有预先确定的“正确答案”。
· 允许算法直接从数据中学习模式(即没有“监督”)。
· 聚类是最常见的无监督学习任务,用于查找数据中的组。
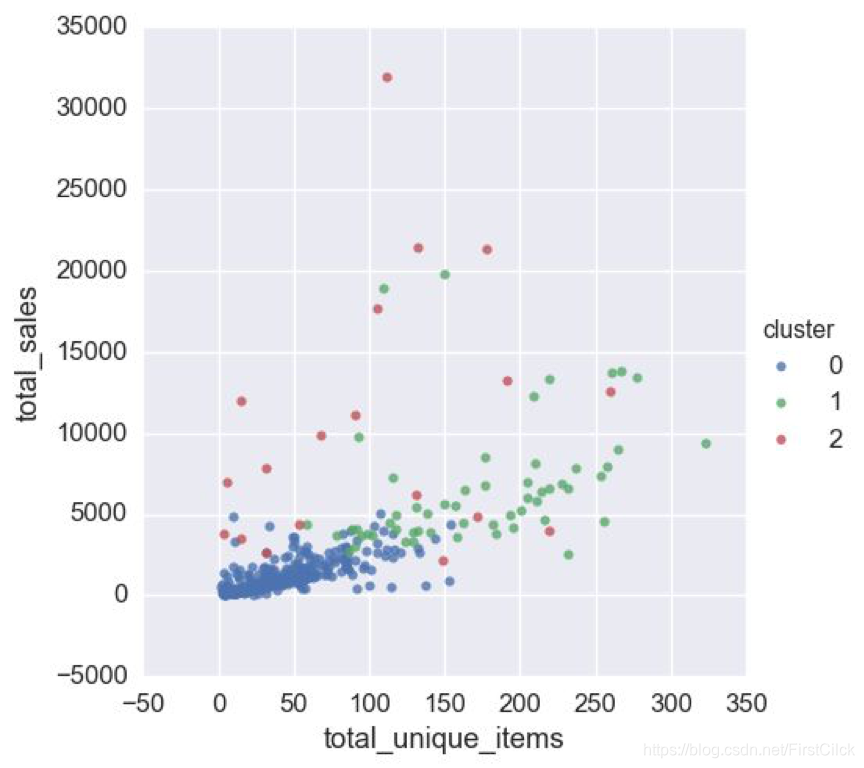
机器学习的三要素
如何始终如一地构建有效的模型以获得最佳效果。
#1:熟练的厨师(人类指导)
首先,即使我们是在“教电脑自学”,但在这个过程中,人的指导也起着很大的作用。
正如我们所看到的,您需要在此过程中做出无数项决策。
事实上,第一个重大决策就是该如何规划我们的项目,从而确保成功。
#2:新鲜食材(干净且相关的数据)
第二个基本要素是数据的质量。
无论我们使用哪种算法,垃圾输入=垃圾输出。
专业的数据科学家将大部分时间花在了解数据,清理数据和设计新功能上。
#3:不要过度烹饪(避免过度拟合)
기계 학습 중 하나는 오버 피팅의 가장 위험한 함정이다. 오버 피팅 아니라 실제 기본 모드를 배우는 것보다, 노이즈의 훈련 집합을 "기억"합니다 모델.
· 헤지 펀드의 overfitting은 수백만 달러의 비용을 수 있습니다.
· 병원에 Overfitting하는 수천명의 죽음으로 이어질 수 있습니다.
대부분의 응용 프로그램 overfitting는 실수를 방지하는 것입니다.