


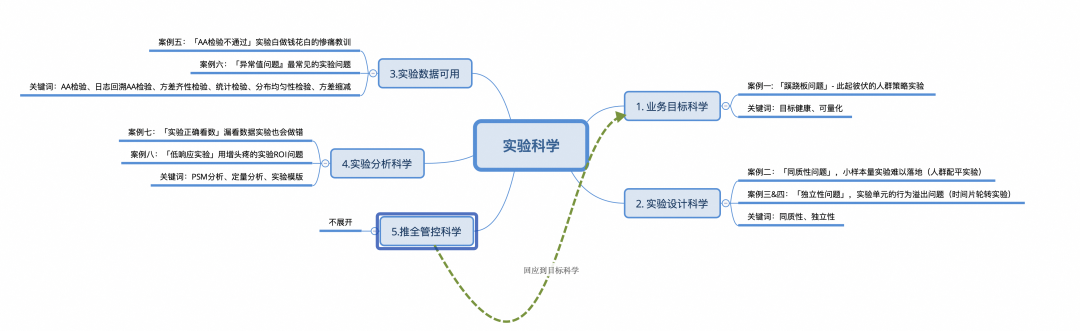

비즈니스 목표의 과학: 성장 목표는 장기적이고 건전하며 정량화 가능해야 합니다.
▐사례 1: "스카이소 문제" - 연속적인 작동 실험

사례 분석
실험 결론 에서 볼 수 있듯이 실험은 1인당 GMV를 크게 증가시키는 반면 사용자 경험을 크게 줄 였습니다 . 1인당 시청 시간을 늘리는 등 1인당 거래 금액 등을 줄이지는 않지만, 서로 다른 소규모 팀에 헤징 지표(조직 구조의 일반적인 문제)가 할당되는 경우 대규모 팀은 합리적으로 목표를 설정하고 특별한 주의를 기울여야 합니다. 헤징 지표에 적용됩니다.
현재 솔루션
-
대규모 팀에서는 일반적으로 비즈니스 리더, 재무 및 BI의 결정이 필요한 핵심 지표와 울타리 지표를 유지 관리합니다.
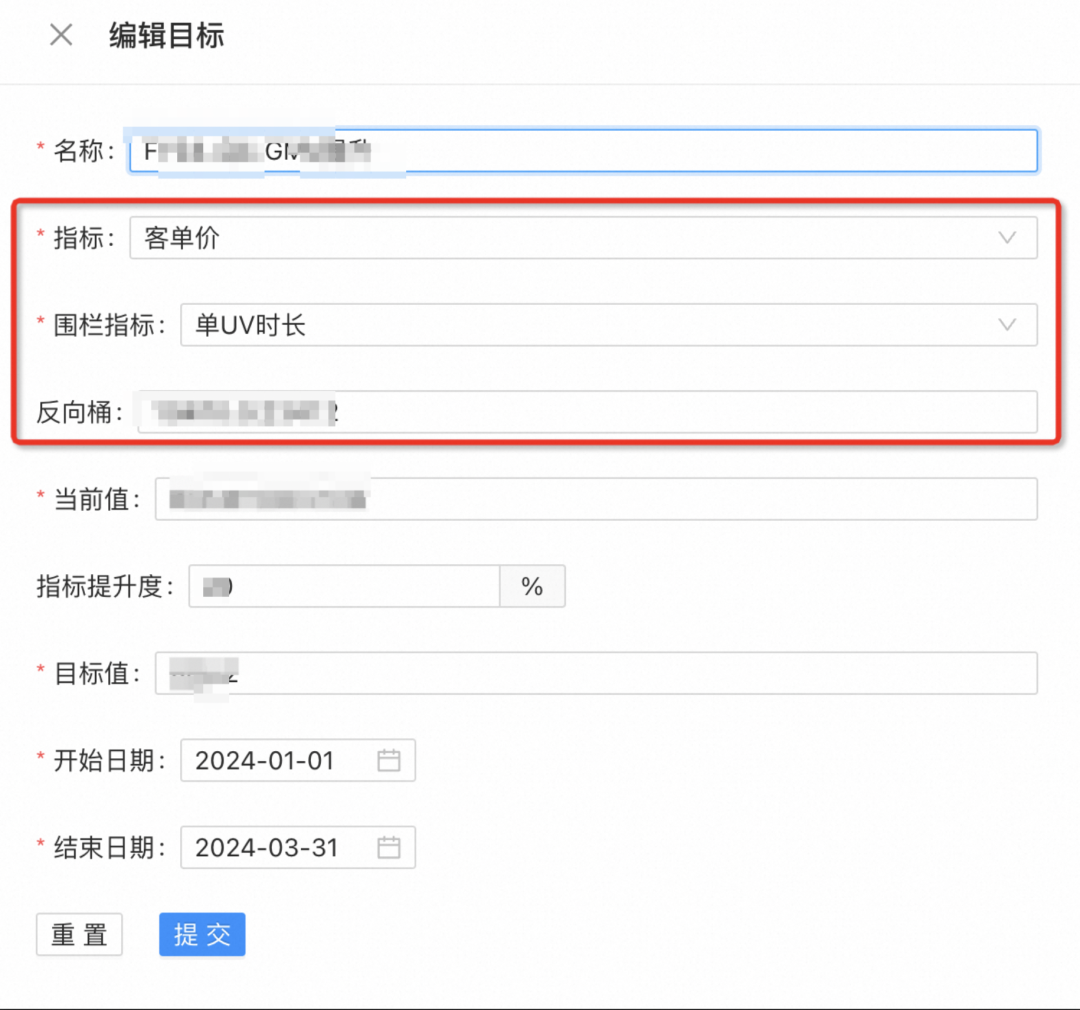
코어 지표와 펜스 지표의 렌더링 추세를 정규화하고 모든 노드의 실험적 푸시로 인한 직관적인 변화를 관찰합니다.
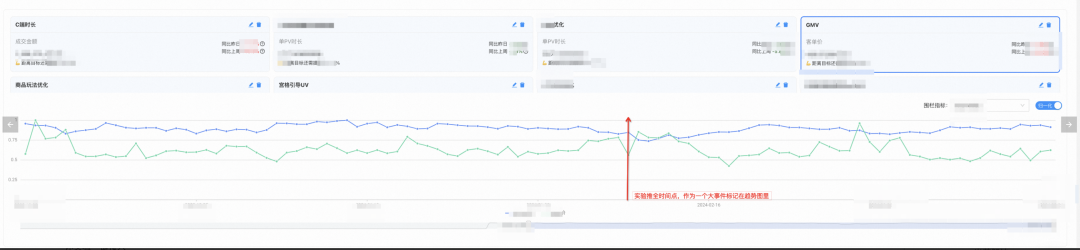
-
장기 리버스 버킷과 결합하여 실험의 증분 가치를 검증합니다. (그림에는 표시되지 않음)
생각하기: 실험 관리의 관점에서 비즈니스 OKR 지표는 어떻게 결정되어야 합니까?
-
OKR은 실험적으로 입증할 수 있는 지표(예: 1인당 GMV)로 설정되어 있으며, 이 지표는 실험의 가치를 정량적으로 평가하는 데 사용됩니다. -
엄격한 역방향 버킷 관리 및 제어 프로세스를 수행하고 역방향 버킷을 통해 GMV 기여도를 추정합니다.

▐사례 2: "균질성 문제", 작은 표본 크기의 실험이 어렵습니다: 새로운 앵커 실험
사례 분석
비즈니스 가설: 우리는 일반적으로 Taobao에서 새로운 앵커의 경험을 향상시키기 위해 많은 전략적 실험을 수행합니다. 특정 전략을 예로 들어 이 전략이 새로운 앵커의 열정을 효과적으로 향상시킬 수 있다고 가정합니다.
실제 상황: 신규 앵커는 기업 심사 후 테스트할 수 있는 샘플 수가 적고, 앵커 간 개인차가 크기 때문에 무작위로 선정된 두 샘플 그룹 간의 지표 변동이 커서 실험을 수행할 수 없습니다. .
현재 솔루션 아이디어
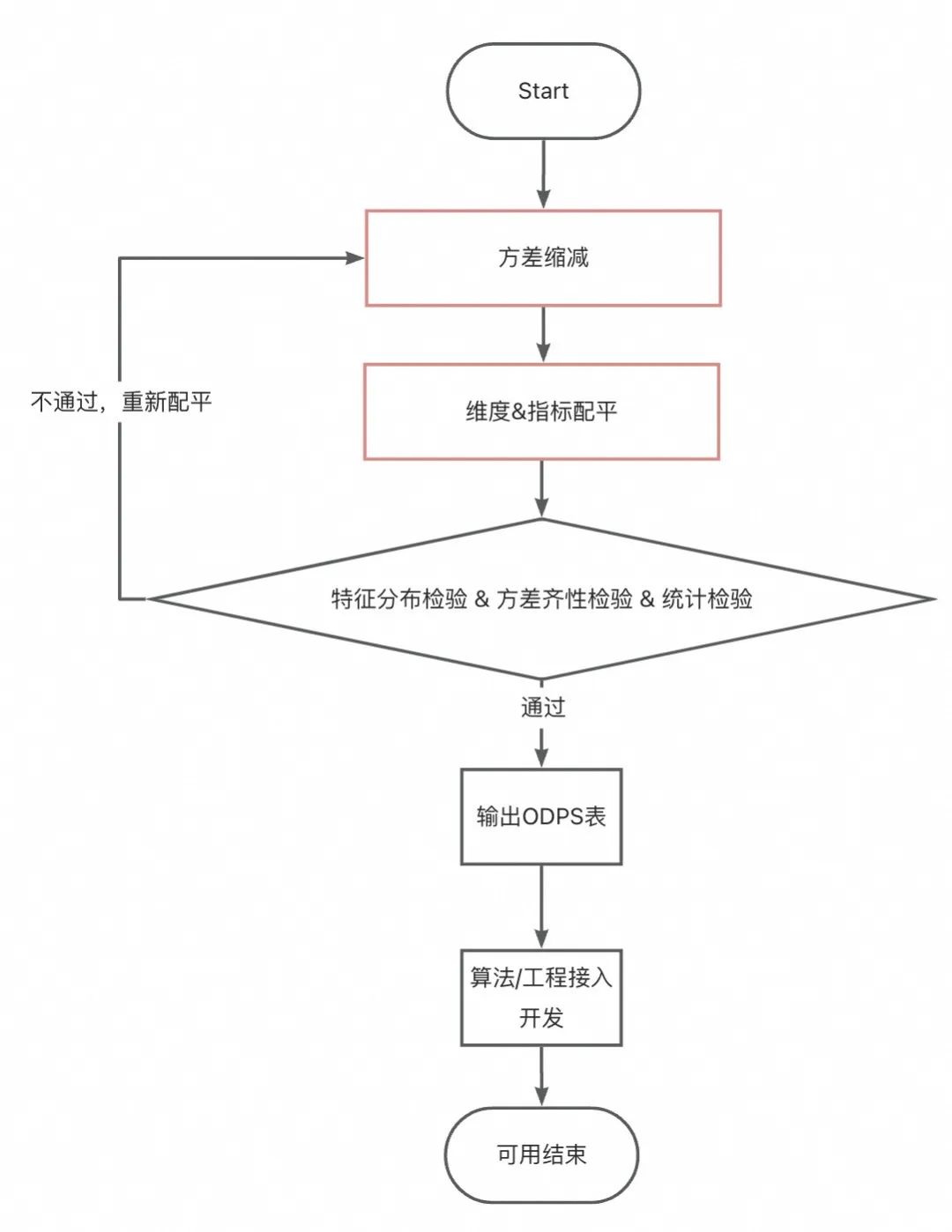
-
분산 감소: 실험에서 검증할 지표 주변에서 이상값을 적당량 제거합니다. (참고: 너무 많이 제거하면 실험 효과가 작아지고, 너무 적게 제거하면 변동이 과도해집니다. 경험적으로는 최소한 99번째 백분위수) 여전히 편차가 너무 큰 경우에는 크기가 커서 장기 지표로 적절하게 처리 할 수 있습니다 . 이 경우 앵커의 일일 거래 금액 차이가 너무 크기 때문에 3개를 선택했습니다. -일 평균 거래금액입니다. 그러나 이로 인해 실험 데이터 복구 주기가 길어지고 실험 해석성이 나빠질 수 있으므로 구경 처리 전에 실험 목적을 명확히 할 필요가 있습니다. -
지표 및 차원 밸런싱 : 오프라인 처리를 통해 지표 데이터 분포와 차원 분포가 동일한 여러 샘플 그룹을 얻습니다.
-
표본 크기가 그다지 작지 않고 그룹 내 차이가 너무 명확하지 않은 경우 간단한 그룹 균형 조정을 시도해 볼 수 있습니다. 즉, 각 그룹의 동일한 비율의 앵커가 실험에 참여하게 됩니다. -
표본 크기가 너무 작거나 그룹 내 차이가 큰 경우 모델을 사용하여 지표와 차원의 균형을 맞출 수 있습니다. 이 경우 AA 테스트를 안정적으로 통과할 수 있는 공변량 적응형 무작위화 방법을 사용합니다.
-
AA 테스트: 그룹화 결과가 동일하고 실험 결론이 유용한지 확인합니다. 이 섹션에서는 아래에서 자세히 설명합니다.
생각하다
소규모 표본 크기의 실험은 더 넓은 시장에 미치는 영향이 적고 실행이 어렵기 때문에 쉽게 무시되는 경우가 많습니다. 그러나 정교한 작업을 통해 이러한 실험은 점차 심각하게 받아들여지기 시작했습니다. 실제 제품 가격 인하 사례에서 500개의 제품을 1,000번 무작위로 추출한 결과, 표본 크기가 작다는 점에도 주목할 필요가 있습니다. 10,000개의 제품을 무작위로 샘플링하도록 조정하면 평균은 명백한 정규 분포를 나타내기 시작하므로 이 맥락에서 실험에서 샘플링할 수 있는 샘플 수는 10,000개 이상이어야 합니다.
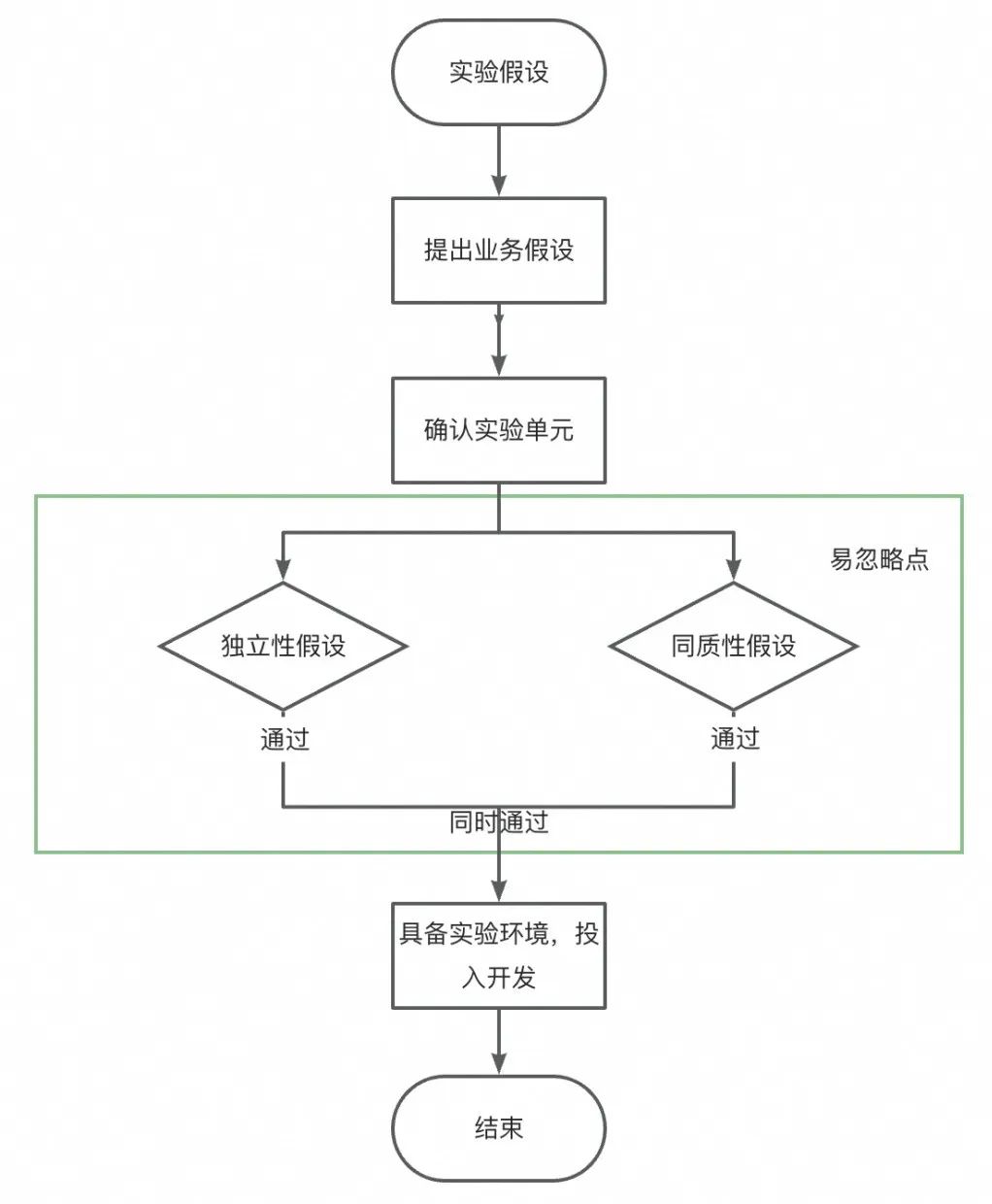
▐사례 3 & 4: "독립성 문제", 팬 간의 커뮤니티 관계로 인한 사용자 행동의 과잉, 앵커 간의 트래픽 경쟁 관계로 인한 앵커 행동의 과잉 이러한 실험은 어떻게 수행됩니까?
사례 분석
현재 솔루션
시간을 여러 시간 조각으로 나누고 각 시간 조각을 독립적인 실험 단위로 사용함으로써 동일한 시간 조각에 있는 모든 사용자가 동일한 전략을 경험하도록 보장할 수 있습니다. 이 디자인은 사용자 경험의 불일치 문제를 효과적으로 방지합니다. 마찬가지로 각 시간 조각에서 모든 트래픽은 정책에 균일하게 할당됩니다. 이러한 배열은 트래픽 경쟁과 사용자 경험의 불일치를 근본적으로 방지하여 실험의 공정성과 효율성을 보장합니다. 시간 분할 순환 실험을 통해 우리는 특정 순간에 모든 사용자에게 통합된 환경을 제공하여 일관성을 유지하고 실험 중에 잠재적인 중단을 방지할 수 있습니다.

결점:
由于其实验单元为时间,所以可统计样本量较少,导致实验效果评估周期长,同时日期切片容易受热点事件影响,导致实验结论偏差。
由于需保证实验单元的独立性,且日期天然存在延续性,因此要减少日期之间的影响,例如1号的策略会影响到2号凌晨的主播(因为主播的场次容易跨天),所以日期切割需要结合业务特点,灵活选择时间切片大小和切割点。

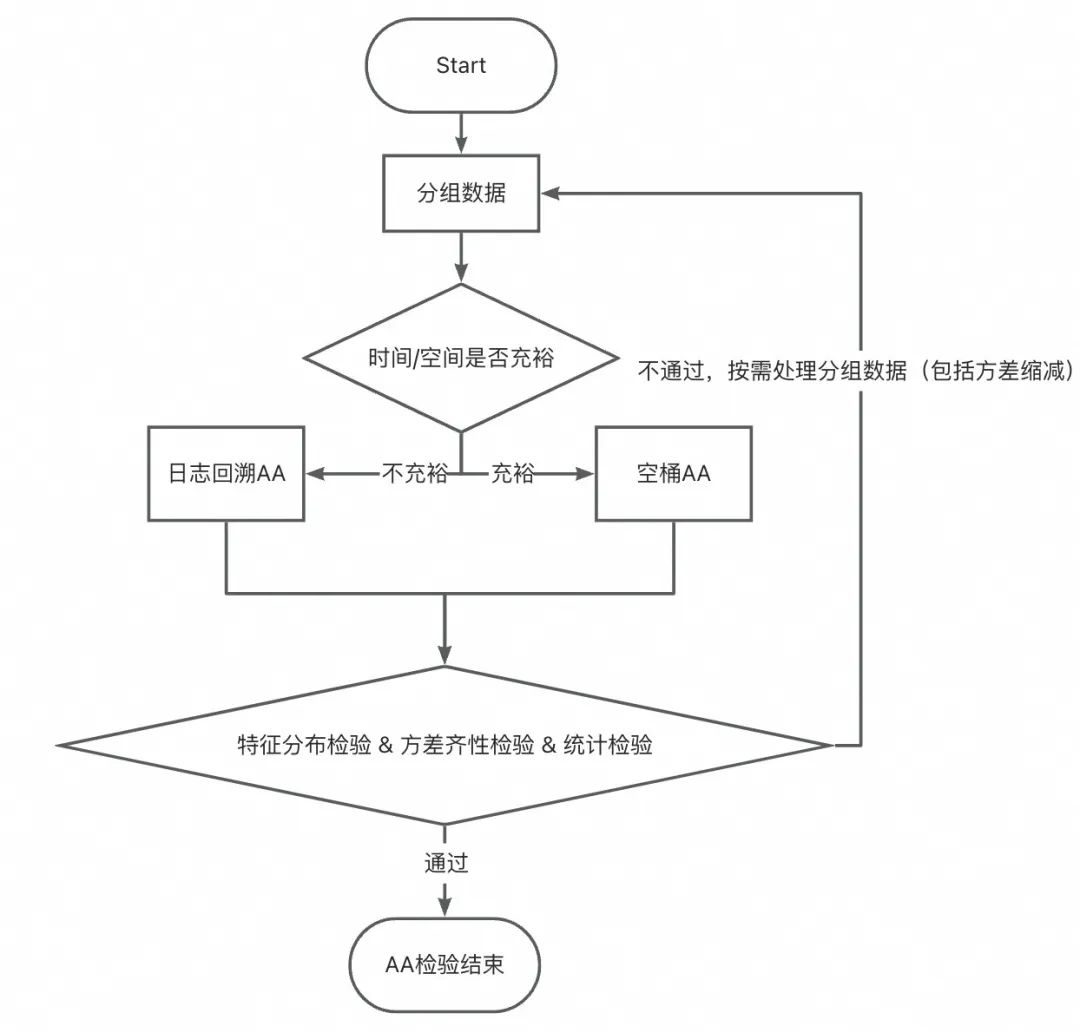
▐ 案例五:「AA检验不通过」在一次下单返红包的实验中,在分析实验数据时才发现用户分布不均匀,导致实验结论严重错误,甚至得出相反结论,浪费实验期间投入的预算等资源。
案例分析
当前解法
1、分布均匀性检验
在这次案例中,实验组和对照组在购买力分层上严重不均,从而导致其核心指标也显著不均,无法获得实验效果。注意:
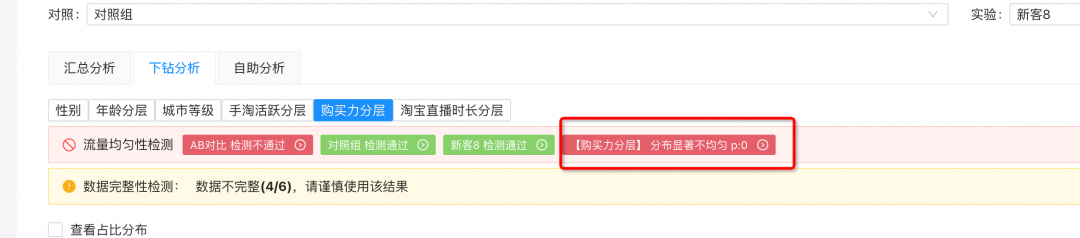
注意:分布不均匀并不一定表示实验数据不可用,本次案例是由于分布不均匀引起了核心指标不同质,导致了实验效果无法验证;
2、方差齐性检验 & 统计检验
在这次案例中,购买力的分布不均已经引起了指标不同质。从下图可以直观理解不同质现象,假设实验组和对照组本身同质,那么他们的数据分布应该都在绿色区域中,随后因为实验组施加了不同策略,导致实验组数据分布从绿色区域移动到了黄色区域。如果实验组未上策略就已经移动到了黄色区域,那么我们是无法证明策略对实验的影响。


图为检验结果
-
统计检验:通过双样本T检验或者多样本ANOVA检验,比较两个独立样本或配对样本的均值差异,具体检验方法可以根据实验样本量大小、样本均衡性情况、样本组数量决定。 -
方差齐性检验:通过Levene's Test或Bartlett's Test来验证实验组和对照组的数据方差是否一致。如果p值大于常用的显著性水平(如0.05),则可以认为组间方差是同质的。
▐ 案例六:「异常值问题』在一次打赏实验中,发现实验效果波动较大,排查后发现榜一大哥竟能左右实验效果
案例分析
在这个案例中,由于实验的用户一致性,榜一大哥会持续进入同一个实验组,于是大哥上线的天数该实验组效果就很好,大哥不在的天数则表现平平。这种实验如果没有找到这个异常值,按照常规经验难以进行分析和迭代。
当前解法
方差缩减:因为异常值会影响到指标的均值、方差,因此异常值除了引起汇总结果的波动外,实验的AA检验、AB检验也都会受影响。目前根据参与实验的实际样本量,采用常用手段:四分位数间距法、标准差法、Z-Score、孤立森林等方式做动态处理。
思考
A/B实验是验证因果关系的黄金标准。错误的因,只会带来错误的果。做好数据可用性验证,保证因果关系的正确发现,是沉淀实验经验,建立实验文化的必要基础。

在获得可用的数据基础后,我们开始关注实验分析的问题,图示为一个简化的实验分析流程。
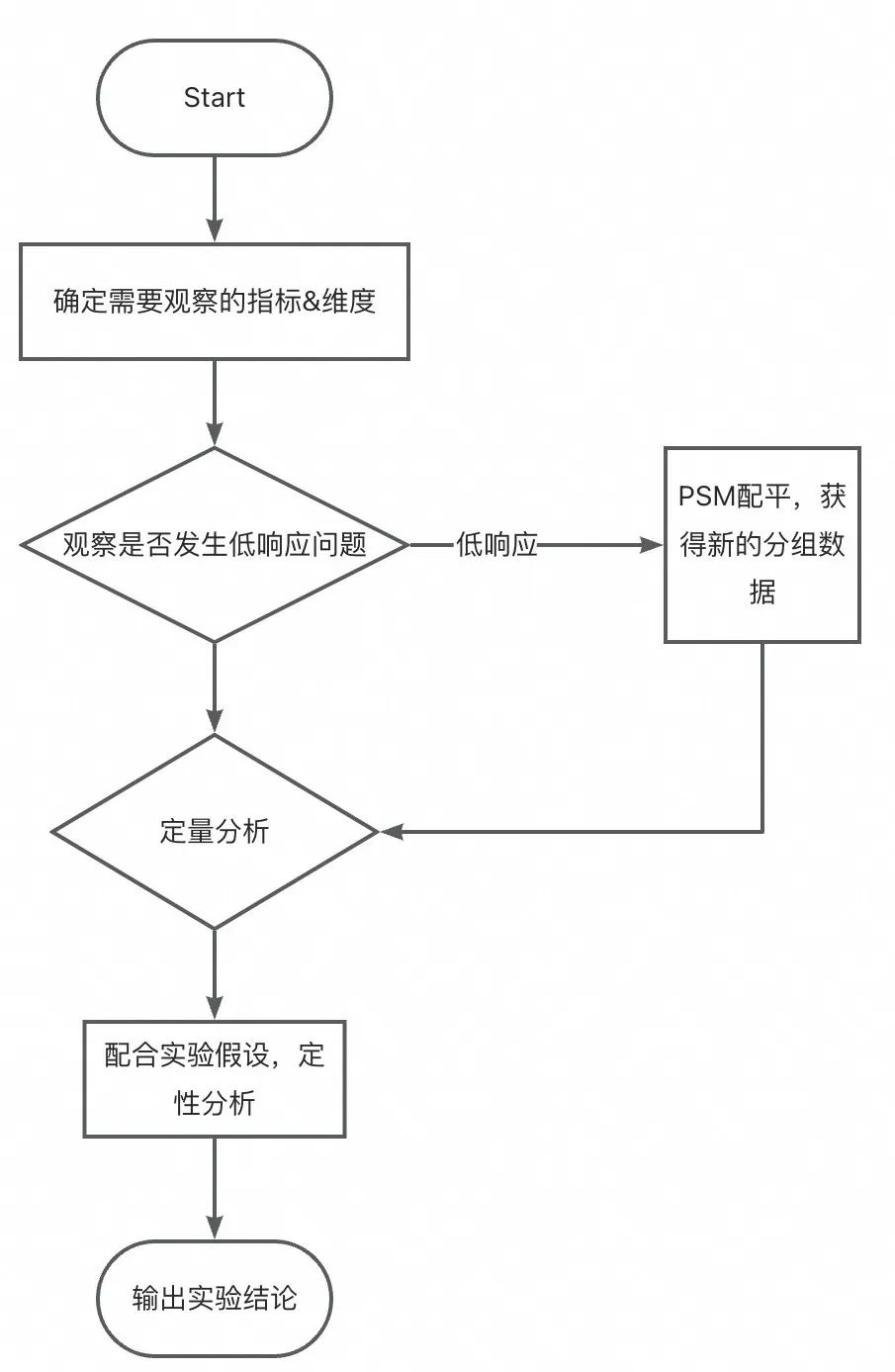
确定需要观察的指标&维度:
在上述案例中,可以发现漏看关键指标、关键维度都可能影响实验结论产出,且实际过程中实验往往需要下钻到关键维度,根据维度项里对实验的差异反应,寻找迭代方向。
▐ 案例七:「实验正确看数」在提单价的实验中,我们发现实验的GMV提升明显,但是观看时长显著降低
案例分析
由于提高了价格带,导致部分低购用户直接选择不看了,而这部分用户本身对GMV的贡献也不大,所以实验依然能够取得明显效果,然而低购群体里的较低年龄段用户他们贡献了较多的观看时长,因此该实验的观看时长也被显著降低。
因此得出一个业务经验:提单价的实验应避免波及(低GMV贡献但高观看时长贡献)的用户。
当前解法
针对不同业务背景,提前确定看数范围(指标+维度),避免经验不足引起的实验观察错误,通常这块由业务方+数据同学共同制定。
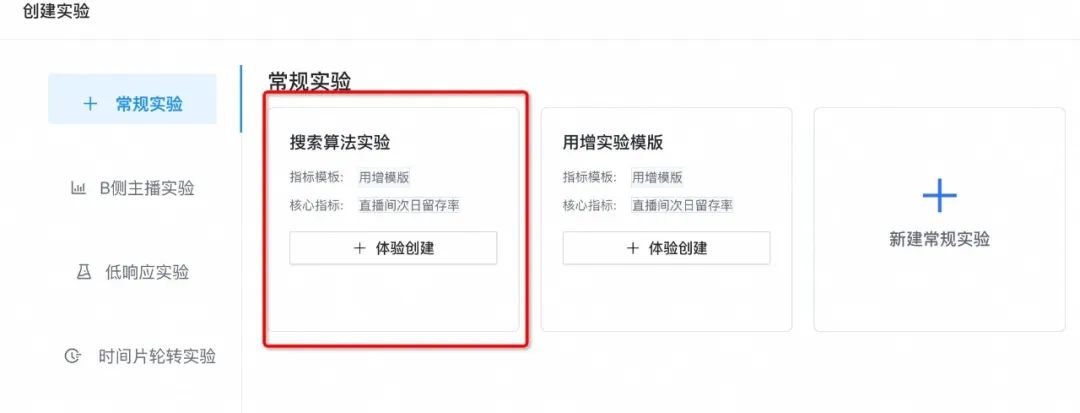
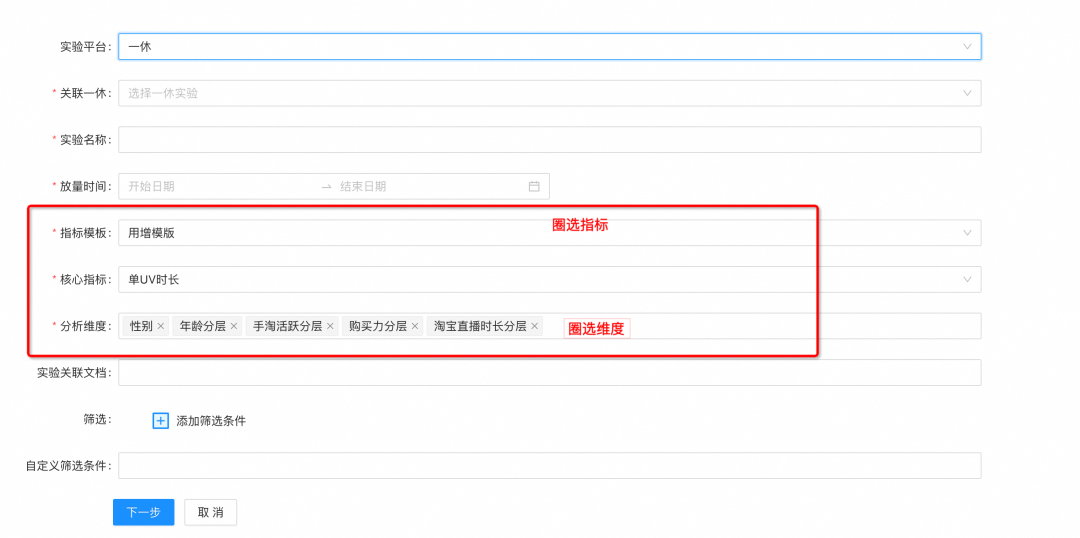
判断低响应实验
▐ 案例八:「低响应实验」活动入口做的AB实验,响应度太低无法分析实验数据。

案例分析
当前解法
▐ 定量分析
这块在第一篇文章中已经浓重介绍过,这里不再赘述。简单提及要点:没有置信度支撑的数据叫随机波动,不要当作实验结论。
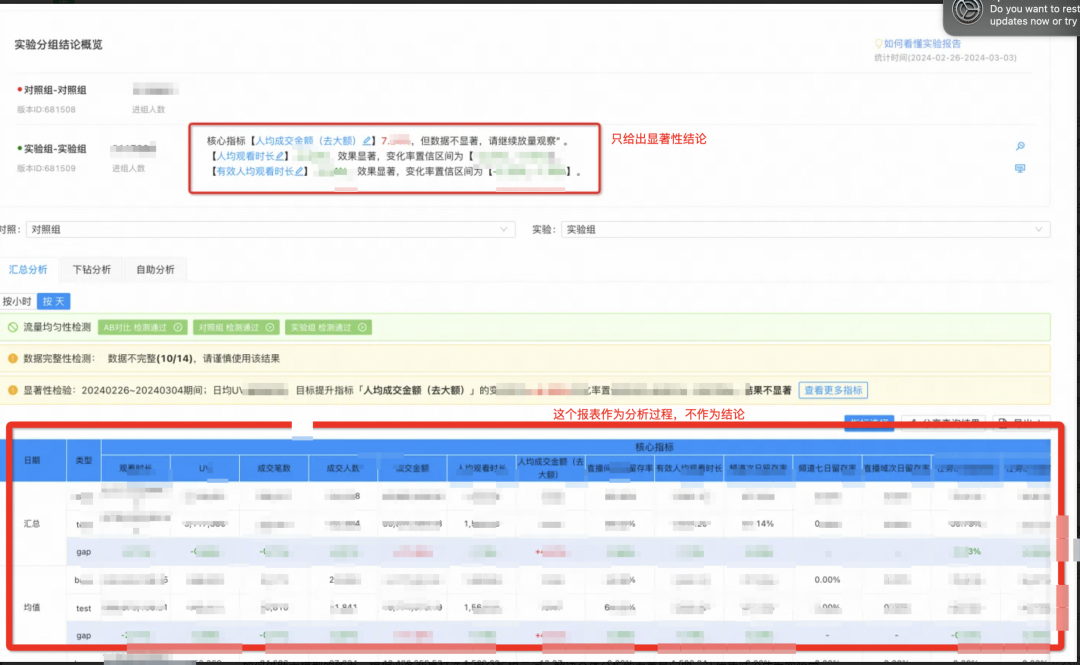
思考:

相关资料
实验推全最终会回应到业务目标达成,我在这块的推动经验较为薄弱,如何围绕业务目标建立可量化的推全标准,这需要多方的信任基础和强大的组织推力,以后补充。
感谢领导信任,让我有机会在直播业务中完善我对A/B实验的理解;感谢大佬的大力支持,感谢所有合作的产品老师、运营老师、算法老师、工程老师、数据研发老师、数据科学老师的大力支持。

技术线内容技术团队,是承接淘天内容电商最核心的技术力量,团队拥有非常全面的内容技术领域布局,不仅覆盖音视频编解码、流媒体传输、低延时直播等多媒体技术,也包含计算机视觉、自然语言处理、多模态內容理解、AIGC等人工智能领域。
在内容技术领域之外,团队拥有强大的算法、前端、客户端、服务端、测试开发、数据开发、数据科学团队、负责面向亿级消费者提供服务的淘宝直播、淘宝逛逛、点淘等核心业务场域;
面向千万级商家、品牌、机构、达人的内容创作工具、内容运营平台内容商业化解决方案;以及面向淘天集团电商板块各业务线的内容管理、内容总线等基石平台。
简历投递邮箱:[email protected]
本文分享自微信公众号 - 大淘宝技术(AlibabaMTT)。
如有侵权,请联系 [email protected] 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。