기사 디렉토리

인터뷰 질문 "Redis는 싱글 스레드인가요?"에서 촉발된 생각
저자: Li Le
출처: IT Reading Ranking
많은 사람들이 다음과 같은 인터뷰 질문을 접했습니다. Redis는 단일 스레드입니까 아니면 다중 스레드입니까? 이 질문은 간단하면서도 복잡합니다. 대부분의 사람들이 Redis가 단일 스레드라는 것을 알고 있기 때문에 간단하다고 하고, 실제로는 답이 정확하지 않기 때문에 복잡하다고 합니다.
Redis는 단일 스레드가 아닌가요? Redis 인스턴스를 시작하고 확인합니다. Redis 설치 및 배포 방법은 다음과 같습니다.
// 下载
wget https://download.redis.io/redis-stable.tar.gz
tar -xzvf redis-stable.tar.gz
// 编译安装
cd redis-stable
make
// 验证是否安装成功
./src/redis-server -v
Redis server v=7.2.4
다음으로 Redis 인스턴스를 시작하고 아래와 같이 ps 명령을 사용하여 모든 스레드를 확인합니다.
// 启动Redis实例
./src/redis-server ./redis.conf
// 查看实例进程ID
ps aux | grep redis
root 385806 0.0 0.0 245472 11200 pts/2 Sl+ 17:32 0:00 ./src/redis-server 127.0.0.1:6379
// 查看所有线程
ps -L -p 385806
PID LWP TTY TIME CMD
385806 385806 pts/2 00:00:00 redis-server
385806 385809 pts/2 00:00:00 bio_close_file
385806 385810 pts/2 00:00:00 bio_aof
385806 385811 pts/2 00:00:00 bio_lazy_free
385806 385812 pts/2 00:00:00 jemalloc_bg_thd
385806 385813 pts/2 00:00:00 jemalloc_bg_thd
실제로 스레드는 6개입니다! Redis는 싱글쓰레드라고 하지 않나요? 스레드가 왜 이렇게 많아?
이 6개 스레드의 의미를 이해하지 못할 수도 있지만 이 예에서는 최소한 Redis가 단일 스레드가 아니라는 점을 보여줍니다.
01 Redis의 멀티스레딩
다음으로 위 6개 스레드의 기능을 하나씩 소개합니다.
1) redis 서버 :
메인 스레드는 클라이언트 요청을 수신하고 처리하는 데 사용됩니다.
2)jemalloc_bg_thd
jemalloc은 Redis의 하위 계층에서 메모리를 관리하는 데 사용되는 차세대 메모리 할당자입니다.
3)바이오_xxx:
bio 접두사로 시작하는 스레드는 모두 비동기 스레드이며, 시간이 많이 걸리는 일부 작업을 비동기적으로 수행하는 데 사용됩니다. 그중 bio_close_file 스레드는 파일을 비동기적으로 삭제하는 데 사용되고, bio_aof 스레드는 AOF 파일을 디스크에 비동기적으로 플러시하는 데 사용되며, bio_lazy_free 스레드는 데이터를 비동기적으로 삭제(지연 삭제)하는 데 사용됩니다.
메인 스레드는 대기열을 통해 작업을 비동기 스레드에 배포하며 이 작업에는 잠금이 필요하다는 점에 유의해야 합니다. 메인 스레드와 비동기 스레드의 관계는 아래 그림과 같습니다.
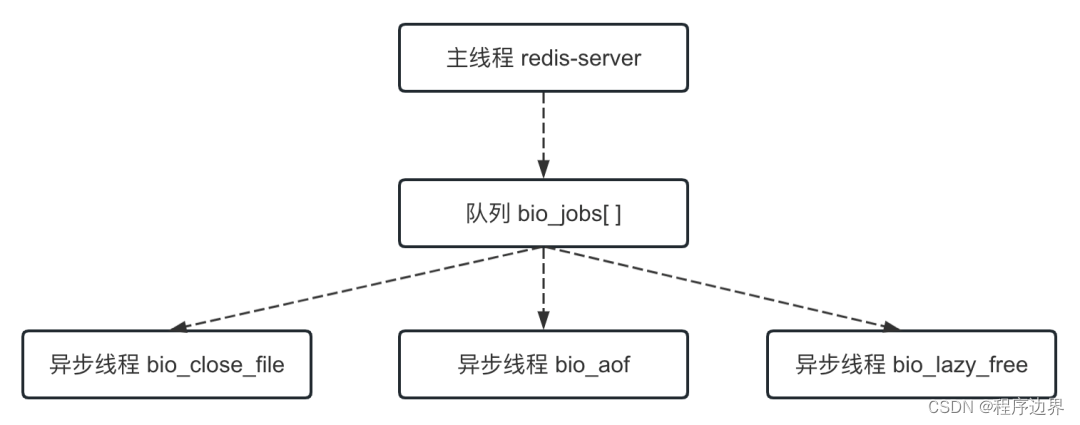
메인 스레드와 비동기 스레드 메인 스레드와 비동기 스레드메인 스레드와 비동기 스레드
여기서는 지연 삭제를 예로 들어 비동기 스레드를 사용해야 하는 이유를 설명합니다. Redis는 문자열, 목록, 해시 테이블, 집합 등을 포함한 다양한 데이터 유형을 지원하는 인메모리 데이터베이스입니다. 생각해 보세요. 목록형 데이터를 삭제(DEL)하는 과정은 어떻게 되나요? 첫 번째 단계는 데이터베이스 사전에서 키-값 쌍을 삭제하는 것이고, 두 번째 단계는 목록의 모든 요소를 순회하고 삭제하는 것입니다(메모리 해제). 목록의 요소 수가 매우 많으면 어떻게 될까요? 이 단계는 시간이 많이 소요됩니다. 이러한 삭제 방법을 동기 삭제라고 하며, 그 과정은 아래 그림과 같습니다.
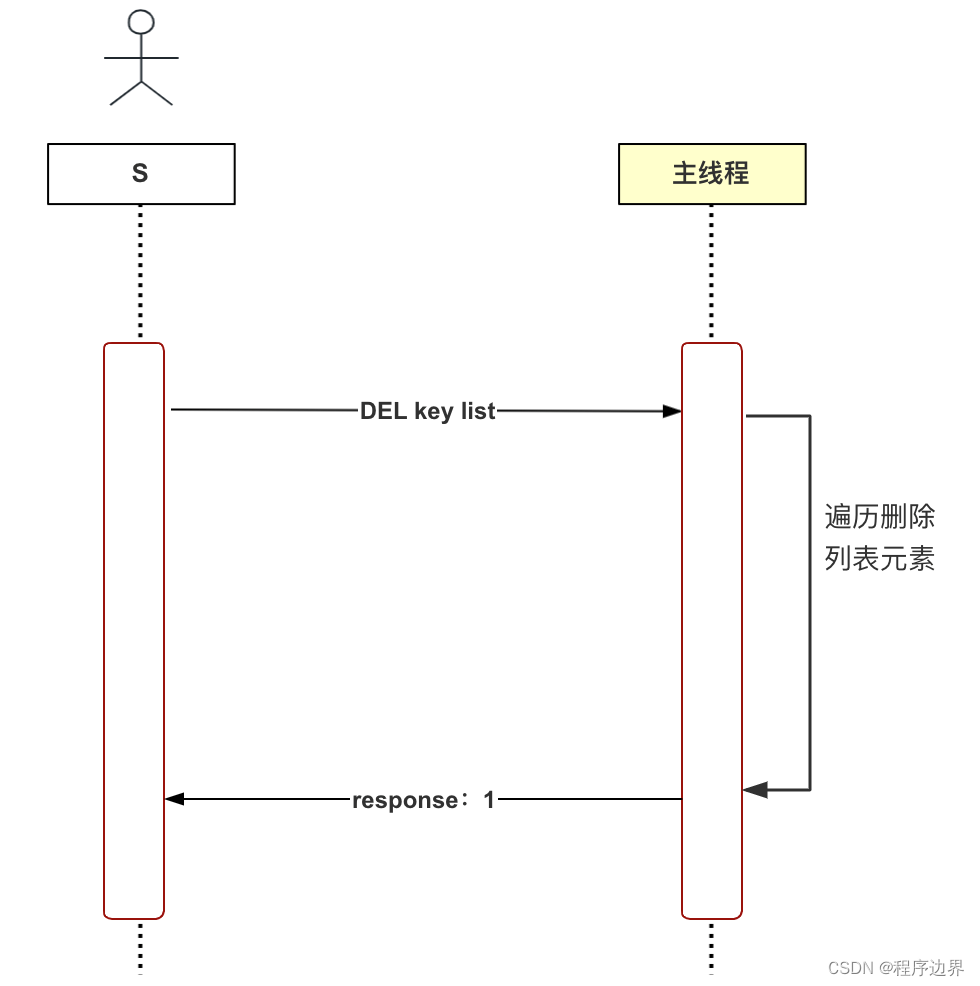
동기 삭제 흐름도 동기 삭제 흐름도동기 삭제 흐름도
위의 문제에 대응하여 Redis에서는 지연 삭제(비동기 삭제)를 제안했는데, 메인 스레드가 삭제 명령(UNLINK)을 수신하면 먼저 데이터베이스 사전에서 키-값 쌍을 삭제한 후 삭제 내용을 분산시킵니다. 비동기 스레드에 대한 작업 bio_lazy_free, 시간이 많이 걸리는 논리의 두 번째 단계는 비동기 스레드에 의해 실행됩니다. 이때의 과정은 아래와 같습니다.
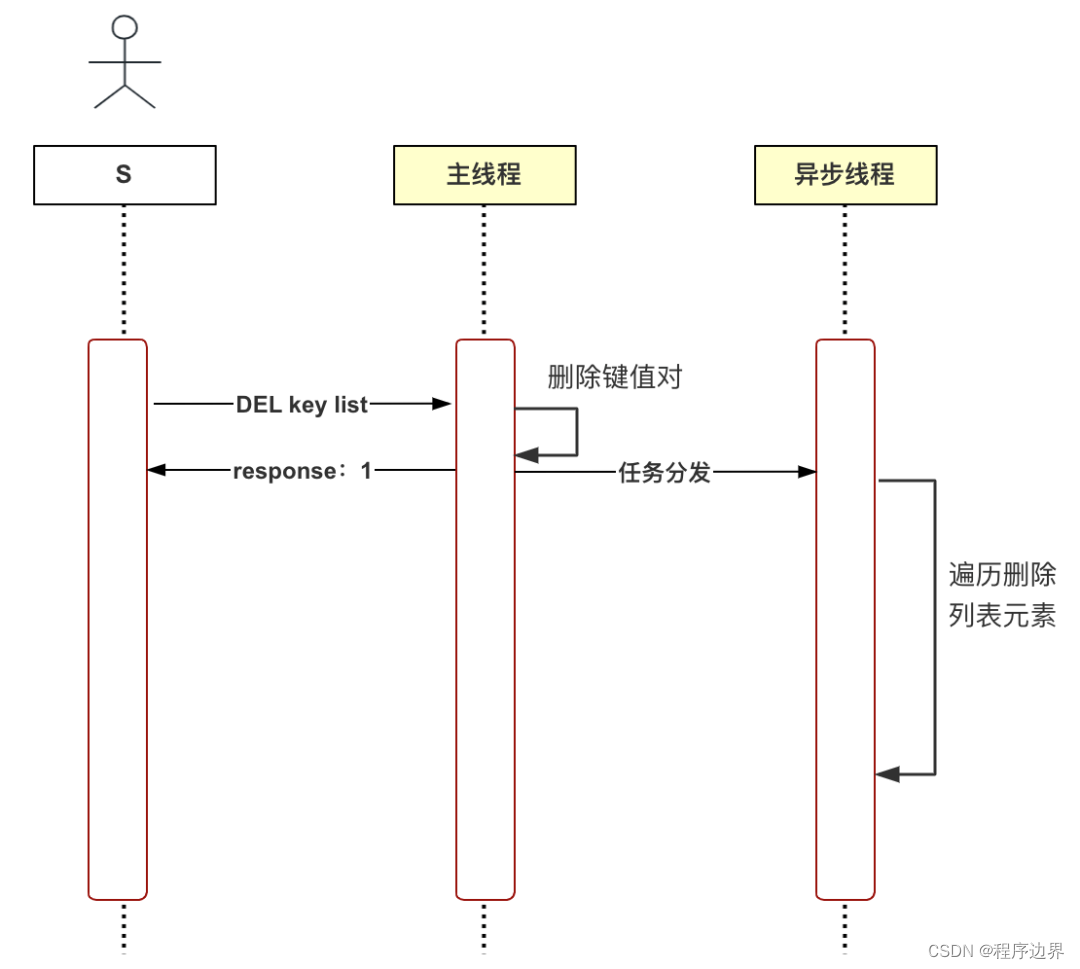
지연 삭제 흐름도 지연 삭제 흐름도지연 삭제 흐름도
02 I/O 멀티스레딩
Redis는 멀티스레드인가요? 그렇다면 Redis가 단일 스레드라고 말하는 이유는 무엇입니까? 클라이언트 명령 요청 읽기, 명령 실행, 클라이언트로 결과 반환이 모두 메인 스레드에서 완료되기 때문입니다. 그렇지 않고, 여러 스레드가 동시에 인메모리 데이터베이스를 운영한다면 동시성 문제를 어떻게 해결할 수 있을까요? 각 작업 전에 잠금이 잠긴 경우 잠금과 단일 스레드의 차이점은 무엇입니까?
물론 이 프로세스도 Redis 6.0 버전에서 변경되었습니다. Redis 관계자는 Redis가 메모리 기반의 키-값 데이터베이스이기 때문에 명령 실행 프로세스가 매우 빠르며 클라이언트 명령 요청을 읽고 결과를 반환합니다. 클라이언트(즉, 네트워크 I/O)는 일반적으로 Redis의 성능 병목 현상이 됩니다.
따라서 Redis 6.0 버전에서는 작성자가 다중 스레드 I/O 기능을 추가했습니다. 즉, 여러 I/O 스레드를 열 수 있고 클라이언트 명령 요청을 병렬로 읽을 수 있으며 결과를 클라이언트에 반환할 수 있습니다. 병행하여. I/O 멀티스레딩 기능은 Redis 성능을 최소한 두 배로 늘립니다.
다중 스레드 I/O 기능을 활성화하려면 먼저 redis.conf 구성 파일을 수정해야 합니다.
io-threads-do-reads yes
io-threads 4
이 두 구성의 의미는 다음과 같습니다.
-
io-threads-do-reads: 다중 스레드 I/O 기능을 활성화할지 여부, 기본값은 "no"입니다.
-
io-threads: I/O 스레드 수, 기본값은 1입니다. 즉, 메인 스레드만 네트워크 I/O를 수행하는 데 사용되며 최대 스레드 수는 128입니다. 이 구성은 다음에 따라 설정되어야 합니다. CPU 코어 수 저자는 4코어 CPU I/O 스레드의 경우 2~3을 설정하고, 8코어 CPU는 6개의 I/O 스레드를 설정하는 것을 권장합니다.
멀티 스레드 I/O 기능을 켠 후 Redis 인스턴스를 다시 시작하고 모든 스레드를 확인합니다. 결과는 다음과 같습니다.
ps -L -p 104648
PID LWP TTY TIME CMD
104648 104648 pts/1 00:00:00 redis-server
104648 104654 pts/1 00:00:00 io_thd_1
104648 104655 pts/1 00:00:00 io_thd_2
104648 104656 pts/1 00:00:00 io_thd_3
……
io-thread를 4로 설정했기 때문에 I/O 작업을 수행하기 위해 4개의 스레드가 생성됩니다(메인 스레드 포함).위 결과는 예상과 일치합니다.
물론 I/O 단계만 멀티스레딩을 사용하고 명령 요청을 처리하는 것은 여전히 단일 스레드이므로 결국 메모리 데이터의 멀티스레드 작업에는 동시성 문제가 있습니다.
마지막으로 I/O 멀티스레딩이 활성화된 후 명령 실행 흐름은 아래와 같습니다.
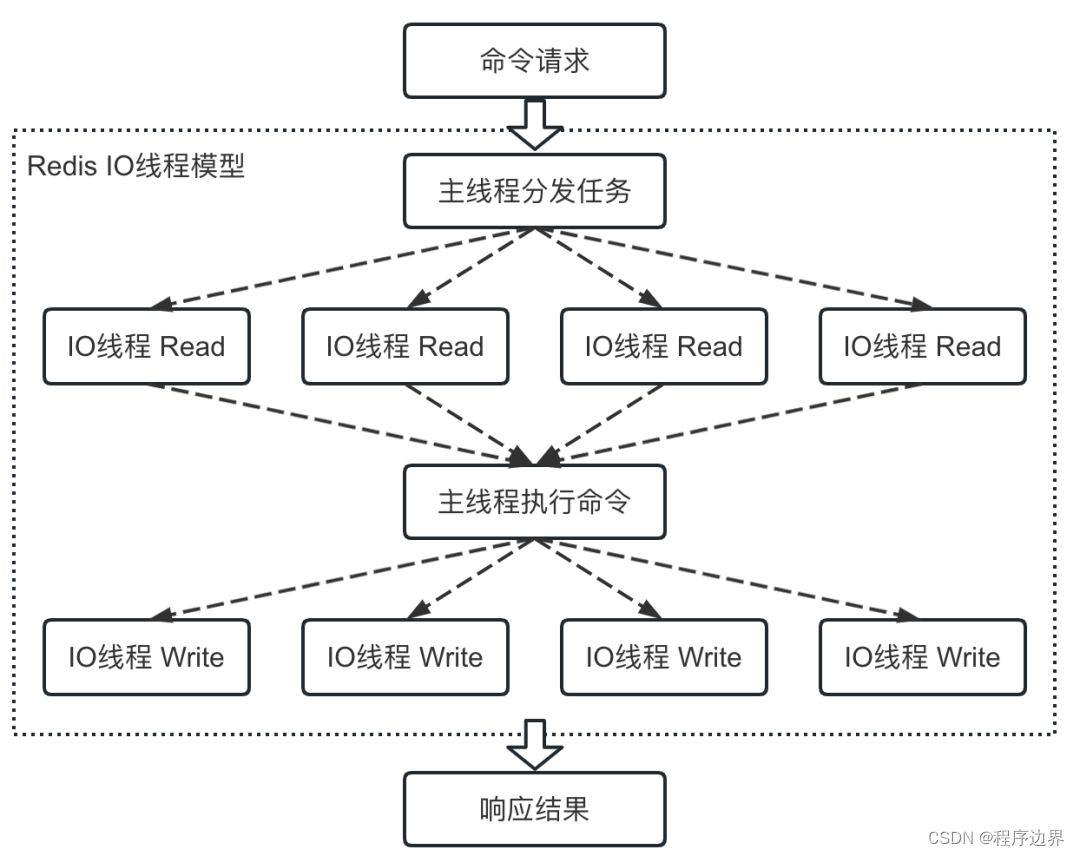
I/O 멀티스레드 흐름도 I/O 멀티스레드 흐름도I / O 멀티스레딩 흐름도
03 Redis의 다중 프로세스
Redis에는 여러 프로세스가 있나요? 예. 일부 시나리오에서는 Redis가 일부 작업을 수행하기 위해 여러 하위 프로세스도 생성합니다. 지속성을 예로 들면 Redis는 두 가지 유형의 지속성을 지원합니다.
-
AOF(Append Only File): 명령의 로그 파일로 간주할 수 있으며 Redis는 각 쓰기 명령을 AOF 파일에 추가합니다.
-
RDB(Redis Database): Redis 메모리에 스냅샷 형태로 데이터를 저장합니다. SAVE 명령은 RDB 지속성을 수동으로 트리거하는 데 사용됩니다. Redis의 데이터 양이 매우 많고 지속성 작업에 오랜 시간이 소요되며 Redis가 명령 요청을 단일 스레드에서 처리하므로 SAVE 명령의 실행 시간이 너무 길면 필연적으로 영향을 미칠 것입니다. 다른 명령의 실행.
SAVE 명령은 다른 요청을 차단할 수 있으므로 Redis는 BGSAVE 명령을 도입하여 지속성 작업을 수행하는 하위 프로세스를 생성하여 다른 요청을 실행해도 기본 프로세스에 영향을 미치지 않습니다.
BGSAVE 명령을 수동으로 실행하여 확인할 수 있습니다. 먼저 GDB를 사용하여 Redis 프로세스를 추적하고, 중단점을 추가하고, 지속성 논리에서 하위 프로세스가 차단되도록 합니다. 다음과 같이:
// 查询Redis进程ID
ps aux | grep redis
root 448144 0.1 0.0 270060 11520 pts/1 tl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
// GDB跟踪进程
gdb -p 448144
// 跟踪创建的子进程(默认GDB只跟踪主进程,需手动设置)
(gdb) set follow-fork-mode child
// 函数rdbSaveDb用于持久化数据快照
(gdb) b rdbSaveDb
Breakpoint 1 at 0x541a10: file rdb.c, line 1300.
(gdb) c
중단점을 설정한 후 Redis 클라이언트를 사용하여 BGSAVE 명령을 전송하면 결과는 다음과 같습니다.
// 请求立即返回
127.0.0.1:6379> bgsave
Background saving started
// GDB输出以下信息
[New process 452541]
Breakpoint 1, rdbSaveDb (...) at rdb.c:1300
보시다시피 GDB는 현재 자식 프로세스를 추적하고 있으며 프로세스 ID는 452541입니다. Linux 명령 ps를 통해서도 모든 프로세스를 볼 수 있으며 결과는 다음과 같습니다.
ps aux | grep redis
root 448144 0.0 0.0 270060 11520 pts/1 Sl+ 17:00 0:00 ./src/redis-server 127.0.0.1:6379
root 452541 0.0 0.0 270064 11412 pts/1 t+ 17:19 0:00 redis-rdb-bgsave 127.0.0.1:6379
하위 프로세스의 이름이 redis-rdb-bgsave임을 확인할 수 있습니다. 이는 이 프로세스가 RDB 파일에 있는 모든 데이터의 스냅샷을 유지한다는 의미입니다.
마지막으로 두 가지 질문을 고려해 보겠습니다.
- 질문 1: 하위 스레드 대신 하위 프로세스를 사용하는 이유는 무엇입니까?
RDB는 데이터 스냅샷을 지속적으로 저장하기 때문에 하위 스레드를 사용하면 메인 스레드와 하위 스레드가 메모리 데이터를 공유하게 되며, 메인 스레드도 지속되는 동안 메모리 데이터를 수정하므로 데이터 불일치가 발생할 수 있습니다. 메인 프로세스와 자식 프로세스의 메모리 데이터는 완전히 분리되어 있어 이러한 문제는 존재하지 않습니다.
- 질문 2: Redis 메모리에 10GB의 데이터가 저장되어 있다고 가정할 때 지속성 작업을 수행하기 위해 하위 프로세스를 생성한 후 이때 하위 프로세스에도 10GB의 메모리가 필요합니까? 10GB의 메모리 데이터를 복사하는 데 시간이 많이 걸리죠? 또한 시스템에 메모리가 15GB만 있는 경우에도 BGSAVE 명령을 실행할 수 있습니까?
여기에 copy on write라는 개념이 있는데, fork 시스템 호출을 이용해 자식 프로세스를 생성한 후 메인 프로세스와 자식 프로세스의 메모리 데이터를 일시적으로 공유하지만, 메인 프로세스가 메모리 데이터를 수정해야 하는 경우에는 시스템은 자동으로 이 메모리 블록의 복사본을 만들어 메모리 데이터를 격리합니다.
BGSAVE 명령의 실행 흐름은 아래 그림과 같습니다.
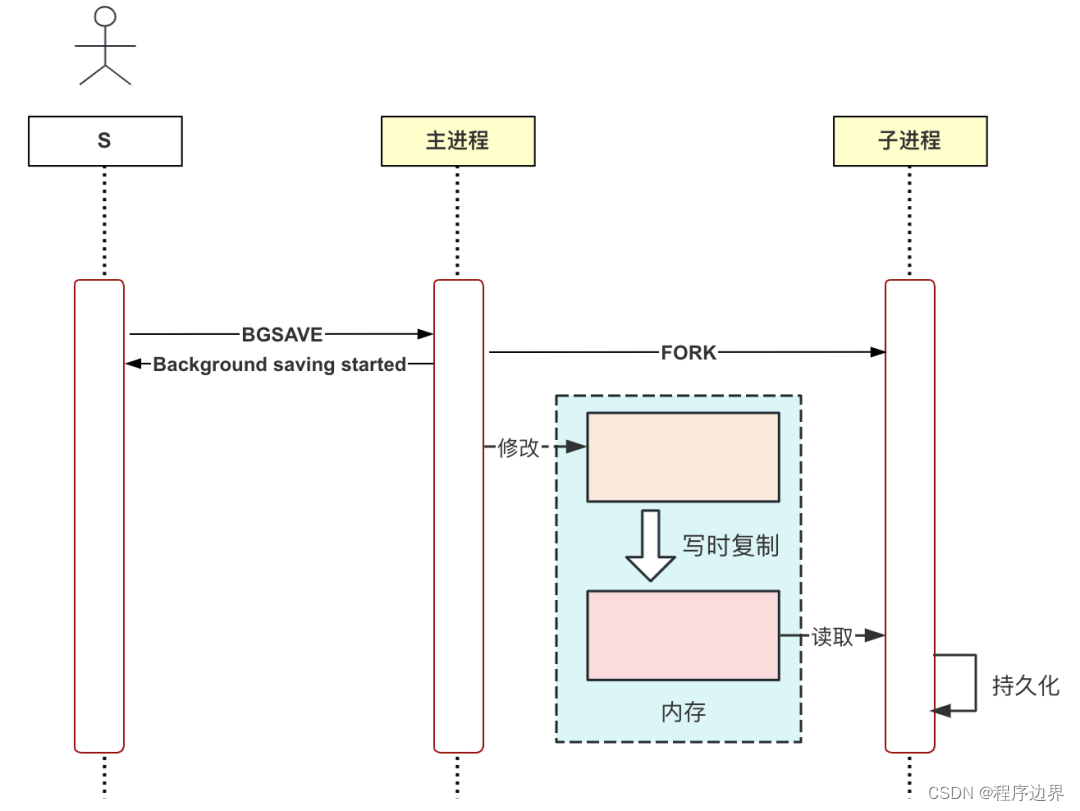
BGSAVE 실행 프로세스 BGSAVE 실행 프로세스BGS A VE 실행 프로세스
04 결론
Redis의 프로세스 모델/스레딩 모델은 여전히 상대적으로 복잡합니다. 여기서는 일부 시나리오의 멀티스레딩 및 멀티프로세싱을 간략하게 소개하고 다른 시나리오의 멀티스레딩 및 멀티프로세싱은 아직 독자 스스로 연구하지 않았습니다.
저자 소개
Li Le: TAL의 Golang 개발 전문가이자 시안 전자 과학 기술 대학의 석사 학위입니다. 그는 한때 Didi에서 근무했습니다. 그는 기술과 소스 코드를 깊이 탐구할 의향이 있습니다. 그는 다음의 공동 저자입니다. "Redis를 효율적으로 사용하기: 한 권의 책으로 데이터 스토리지 및 고가용성 클러스터 알아보기" 및 "Redis5" 설계 및 소스 코드 분석" "Nginx 기본 설계 및 소스 코드 분석".
▼확장 독서

"Redis 효율적으로 사용하기: 한 권의 책으로 데이터 스토리지 및 고가용성 클러스터 알아보기" "Redis 효율적으로 사용하기: 한 권의 책으로 데이터 스토리지 및 고가용성 클러스터 알아보기"" Redis를 효율적으로 사용하기: 데이터 스토리지와 고 가용성 클러스터를 한 권의 책 으로 배우기 "
추천 단어: Redis 데이터 구조 및 기본 구현에 대해 자세히 알아보고 Redis 데이터 스토리지 및 클러스터 관리 문제를 극복하세요.