오픈 소스 LLaMA의 신화가 다시 나타납니다! 최초의 오픈 소스 650억 매개변수 대형 모델 고성능 사전 훈련 솔루션으로 훈련 속도가 38% 빨라지고 맞춤형 대형 모델이 저렴한 비용으로 생성됩니다.
"백 모델 전쟁"이 격렬해지고 AIGC 관련 회사의 자금 조달 및 인수 합병이 반복적으로 최고치를 기록하고 글로벌 기술 회사가 게임에 참가하기 위해 경쟁하고 있습니다.
그러나 AI 대형 모델의 뛰어난 아름다움 뒤에는 매우 높은 비용이 있으며 단일 사전 훈련 비용은 수천만 위안에 달할 수 있습니다. LLaMA와 같은 기존 오픈소스 대형 모델의 미세 조정을 기반으로 핵심 경쟁력을 구축하고 상업적 용도를 다양화하려는 기업의 요구를 충족시키기도 어렵습니다.
따라서 저렴한 비용으로 사전 학습된 기본 대형 모델을 만드는 방법은 AI 대형 모델의 물결에서 핵심 병목 현상이 되었습니다.
Colossal-AI는 세계에서 가장 크고 가장 활동적인 대규모 모델 개발 도구 및 커뮤니티입니다.현재 가장 널리 사용되는 LLaMA를 예로 들면, 즉시 사용 가능한 650억 매개변수 사전 훈련 솔루션을 제공하여 훈련 속도를 38% 높일 수 있고 대규모 모델 기업에 많은 비용을 절감할 수 있습니다.

오픈 소스 주소: https://github.com/hpcaitech/ColossalAI
LLaMA, 오픈 소스에 대한 열정에 불을 붙이다
Meta의 오픈소스 7B~65B LLaMA 대형 모델은 ChatGPT와 같은 모델을 만드는 열정을 더욱 자극했고, Alpaca, Vicuna, ColossalChat과 같은 미세 조정 프로젝트를 도출했습니다.
그러나 LLaMA는 모델 가중치만 오픈소스로 공개하고 상업적 이용을 제한하며, 미세조정으로 개선하고 주입할 수 있는 지식과 역량은 상대적으로 제한적이다. 대형 모델의 물결에 진정으로 동참하는 기업의 경우 여전히 자체 핵심 대형 모델을 사전 교육해야 합니다.
이를 위해 오픈 소스 커뮤니티에서도 많은 노력을 기울였습니다.
-
RedPajama: 상업적으로 사용 가능한 오픈 소스 LLaMA 데이터 세트, 교육 코드 및 모델 없음
-
OpenLLaMA: JAX 및 TPU 교육을 기반으로 하는 EasyLM을 사용하는 상용 오픈 소스 LLaMA 7B, 13B 모델
-
Falcon: 오픈 소스 상용 LLaMA 7B, 40B 모델, 교육 코드 없음
그러나 가장 주류인 PyTorch + GPU 생태계의 경우 여전히 효율적이고 안정적이며 사용하기 쉬운 LLaMA와 같은 기본 대규모 모델 사전 훈련 솔루션이 부족합니다.
최고의 대형 모델 사전 훈련 솔루션으로 38% 속도 향상
위의 격차와 요구에 부응하여 Colossal-AI는 650억 매개변수 LLaMA 저비용 사전 훈련 솔루션을 최초로 오픈 소스화했습니다.
업계의 다른 주류 옵션과 비교하여 이 솔루션은 사전 교육 속도를 38%까지 높일 수 있고 32개의 A100/A800만 사용하면 되며 상업적 사용을 제한하지 않습니다.
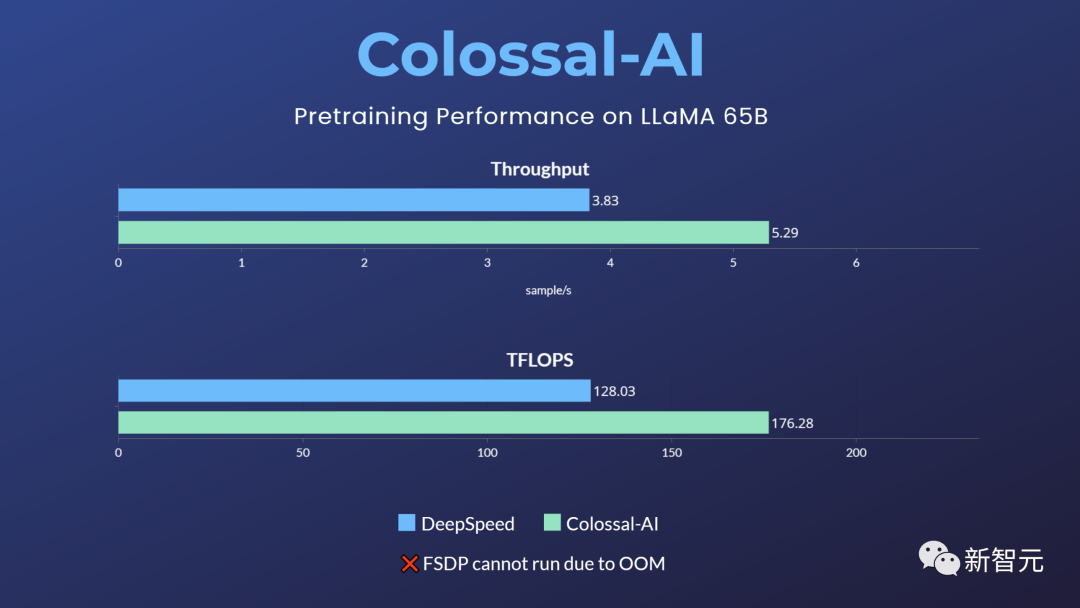
그러나 기본 PyTorch, FSDP 등은 메모리 오버플로로 인해 작업을 실행할 수 없습니다. Hugging Face 가속, DeepSpeed 및 Megatron-LM은 공식적으로 LLaMA 사전 교육을 지원하지 않습니다.
상자 밖으로
1. Colossal-AI 설치
git clone -b example/llama https://github.com/hpcaitech/ColossalAI.gitcd ColossalAI# install and enable CUDA kernel fusionCUDA_EXT=1 pip install .
2. 기타 종속성 설치
cd examples/language/llama# install other dependenciespip install -r requirements.txt# use flash attentionpip install xformers
3. 데이터세트
기본 데이터세트 togethercomputer/RedPajama-Data-1T-Sample은 처음 실행 시 자동으로 다운로드되며 사용자 지정 데이터세트는 -d 또는 --dataset를 통해 지정할 수도 있습니다.
4. 명령 실행
7B 및 65B 속도 테스트 스크립트가 제공되었으며 실제 하드웨어 환경에 따라 사용되는 다중 노드의 호스트 이름만 설정하면 성능 테스트를 실행할 수 있습니다.
cd benchmark_65B/gemini_autobash batch12_seq2048_flash_attn.sh
실제 사전 교육 작업의 경우 속도 테스트와 동일한 명령을 사용하고 4개의 노드 * 8개의 카드를 사용하여 65B 모델을 교육하는 것과 같이 해당 명령을 시작합니다.
colossalai run --nproc_per_node 8 --hostfile YOUR_HOST_FILE --master_addr YOUR_MASTER_ADDR pretrain.py -c '65b' --plugin "gemini" -l 2048 -g -b 8 -a예를 들어 Colossal-AI gemini_auto 병렬 전략을 사용하면 다중 머신 다중 카드 병렬 교육을 쉽게 구현하고 고속 교육을 유지하면서 메모리 소비를 줄일 수 있습니다. 하드웨어 환경 또는 실제 요구 사항에 따라 파이프라인 병렬 처리 + 텐서 병렬 처리 + ZeRO1과 같은 복잡한 병렬 전략 조합을 선택할 수 있습니다.
그 중 Colossal-AI의 Booster Plugins를 통해 사용자는 Low Level ZeRO, Gemini, DDP와 같은 병렬 전략을 선택하는 등 병렬 훈련을 쉽게 사용자 정의할 수 있습니다.
기울기 체크포인트는 역전파 동안 모델 활성화를 재계산하여 메모리 사용량을 줄입니다. 플래시 주의 메커니즘을 도입하여 계산을 가속화하고 비디오 메모리를 절약합니다.
사용자는 고성능을 유지하면서 맞춤형 개발을 위한 유연성을 유지하는 명령줄 매개변수를 통해 수십 개의 유사한 사용자 정의 매개변수를 편리하게 제어할 수 있습니다.
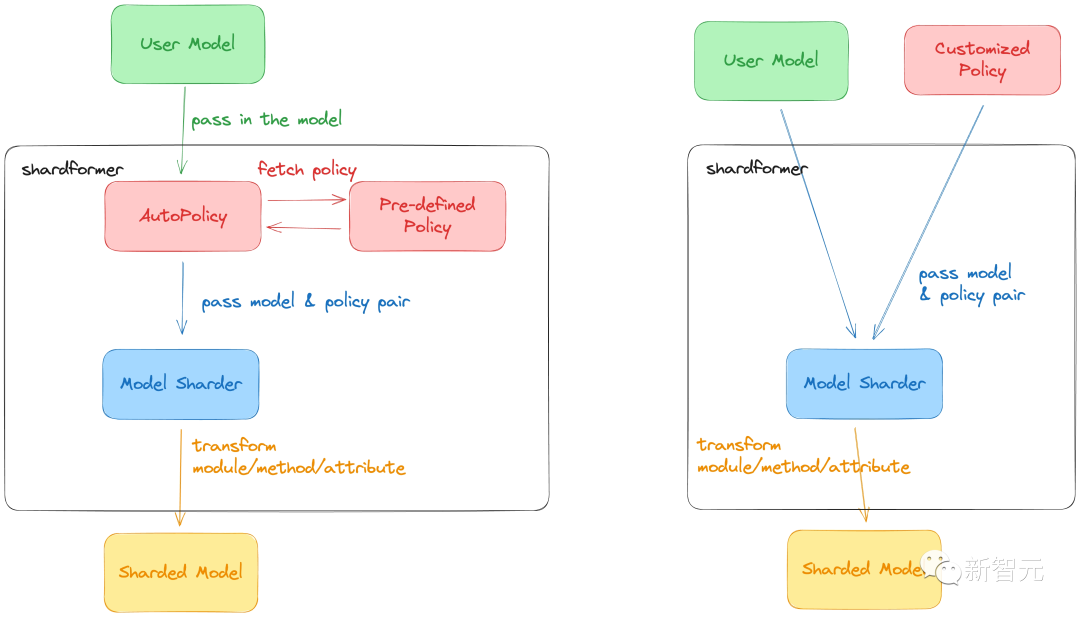
ColossalAI의 최신 ShardFormer는 다차원 병렬 교육 LLM 사용 비용을 크게 줄입니다.
이제 LLaMA를 포함한 다양한 주류 모델을 지원하고 기본적으로 Huggingface/transformers 모델 라이브러리를 지원합니다.
모델을 수정하지 않고 다차원 병렬성(파이프라인, 텐서, ZeRO, DDP 등)의 다양한 구성 조합을 지원할 수 있으며, 다양한 하드웨어 구성에서 뛰어난 성능을 발휘할 수 있습니다.
AI 대형 모델 시스템 인프라 Colossal-AI
Colossal-AI는 프로그램에 대한 핵심 시스템 최적화 및 가속 기능 지원을 제공하며, 버클리 캘리포니아 대학의 석좌 교수인 James Demmel과 싱가포르 국립 대학의 대통령 청소년 교수인 You Yang의 주도하에 개발되었습니다.
Colossal-AI는 PyTorch를 기반으로 AI 대형 모델 교육/미세 조정/추론의 개발 및 적용 비용을 줄이고 효율적인 다차원 병렬 처리 및 이기종 메모리를 통해 GPU 요구 사항을 줄일 수 있습니다.
위에서 언급한 Colossal-AI 솔루션은 Fortune 500대 기업에 적용되었으며, 킬로칼로리 클러스터에서 우수한 성능을 발휘하며, 수천억 개의 매개변수가 있는 개인 대규모 모델의 사전 교육을 완료하는 데 몇 주 밖에 걸리지 않습니다. Shanghai AI Lab, Shangtang 등 최근에 출시된 InternLM도 Colossal-AI를 기반으로 Kcal에서 효율적인 사전 교육을 구현합니다.
Colossal-AI는 오픈 소스 이후 GitHub Hot List에서 세계 1위를 수차례 달성했으며, GitHub Stars 30,000개 이상을 획득했으며, SC, AAAI, PPoPP, CVPR, ISC 등 세계 유수의 AI 및 HPC 컨퍼런스의 공식 튜토리얼로 성공적으로 선정되었으며, 수백 개의 기업이 Colossal-AI 생태계 구축에 참여했습니다.
그 배후인 루첸테크놀로지는 최근 시리즈A 펀딩에서 수억 위안을 받았고, 설립 18개월 만에 3차례의 펀딩을 빠르게 마쳤다.
오픈 소스 주소:
https://github.com/hpcaitech/ColossalAI
참조 링크:
https://www.hpc-ai.tech/blog/large-model-pretraining