머리말
매일매일 AI 관련 뉴스를 많이 찾아봐야 하는데 정보량이 폭발적으로 늘어나고 실효성 있는 정보가 적다고 느끼시나요?
수많은 신제품과 새로운 도구 중에서 어떤 것이 정말 가치가 있고 어떤 것이 단지 성급한 핫스팟일까요?
AI 제품 및 도구 개발에 참여하고 싶다면 어디에서 많은 영감과 아이디어를 얻을 수 있습니까?
정보 노이즈를 제거하고 AI의 최전선 개발을보다 효율적으로 이해할 수 있도록 새로운 AI 관련 트렌드, 새로운 아이디어, 새로운 아이디어, 성숙한 AI 제품, 도구, 모델 등을 여기에 정리하겠습니다.
주로 주변:
- AI 산업 동향, 아이디어, 아이디어
- AI 제품
- AI 개발자 도구
- AI 모델
이 저널의 두 번째 호로 2023년 5-6월에 발표된 관련 정보에 중점을 둡니다. 시청자 및 친구 여러분, 적시성에 주목하십시오.
아이디어
대형 모델 교육용 자료가 소진됩니까?
다음은 Ruan Yifeng의 Science and Technology Weekly에 실린 Mr. Ruan의 개인적인 생각에서 발췌한 것입니다.
현재 뉴스 보도에는 매일 AI 뉴스가 있으며 많은 모델이 언급될 것입니다.
모델의 강도를 구별하기 위해 얼마나 많은 매개변수가 있는지를 보는 핵심 지표가 있습니다. 일반적으로 매개변수의 수가 많을수록 모델이 강해집니다.
GPT-2는 15억 개의 매개변수, GPT-3 및 ChatGPT는 1750억 개의 매개변수를 가지고 있으며 GPT-4는 이 지표를 발표하지 않았으며 이는 이전 세대보다 5배 이상 크다고 합니다.

그렇다면 매개 변수는 무엇입니까? 대략적인 이해에 따르면 매개 변수는 모델 예측을 기반으로 한 신경망의 노드 수와 같습니다. 매개변수가 많을수록 모델이 고려하는 가능성이 많아지고 계산량이 많아지고 효과도 좋아집니다.
매개변수가 많을수록 좋기 때문에 매개변수가 무한대로 늘어나나요?
대답은 '아니요'입니다. 매개변수가 교육 자료에 의해 제한되기 때문입니다. 이러한 매개변수를 계산할 수 있는 충분한 교육 자료가 있어야 하며, 매개변수가 무한대로 증가하면 교육 자료도 무한히 증가해야 합니다.
내가 본 한 가지 주장은 교육 자료가 매개 변수의 10배 이상이어야 한다는 것입니다. 예를 들어 고양이 사진과 개 사진을 구별하는 모델은 1,000개의 매개변수를 가정하고 최소 10,000개의 이미지에 대해 학습해야 합니다.
ChatGPT에는 1,750억 개의 매개변수가 있으므로 교육 자료는 17억 5천만 개 이상의 토큰이 바람직합니다. "어휘 요소"는 다양한 단어와 기호로, 소설 "붉은 저택의 꿈"을 예로 들면 788,451자, 즉 100만 개의 어휘 요소를 의미합니다. 그러면 ChatGPT의 교육 자료는 "붉은 저택의 꿈" 175만 부에 해당합니다.
보고서에 따르면 ChatGPT는 실제로 Wikipedia, 인터넷 라이브러리, Reddit 포럼, Twitter 등에서 570GB의 교육 자료를 사용했습니다.
여러분 생각해보세요. 더 강력한 모델은 더 많은 교육 자료가 필요합니다. 문제는 우리가 그렇게 많은 자료를 찾을 수 있고 언젠가는 자료가 충분하지 않을까요?
이 문제에 대해 논문을 쓰고 연구한 학자들이 실제로 있음을 말씀드립니다.
지난 10년 동안 AI 교육 데이터 세트는 전 세계 데이터 스톡보다 훨씬 빠르게 성장했습니다. 이 추세가 계속되면 데이터 재고의 고갈이 불가피합니다.
이 논문은 세 가지 시점을 제시합니다.
- 2026년: 일반 언어 데이터의 고갈
- 2030-2050: 모든 언어 데이터 사용
- 2030-2060: 모든 시각적 데이터를 사용
즉, 그들의 예측에 따르면 약 3~4년 후에는 새로운 교육 자료를 찾기 어려울 것입니다. 늦어도 30년이 지나면 세상의 모든 자료가 AI 교육에 충분하지 않습니다.
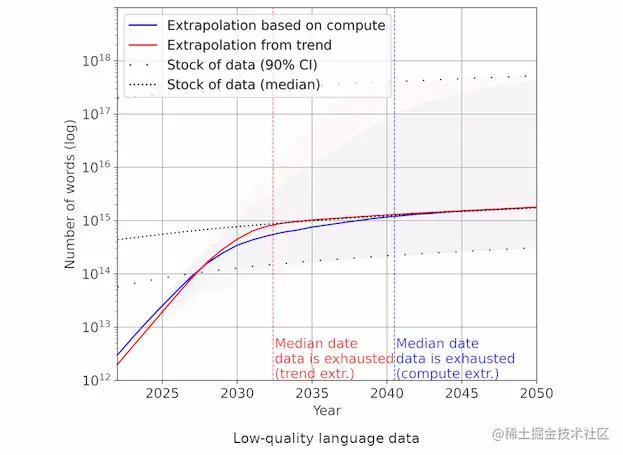
위의 그림은 저자가 제시한 추세 차트이며, 점선은 학습 자료의 성장 속도, 빨간색 선과 파란색 선은 모델 성장 속도에 대한 서로 다른 예측입니다. 2035년 이후에는 이 세 개의 선이 합쳐져 곡선이 점점 더 평평해질 것입니다. 그 시점에서 저자는 AI 모델 개발이 불충분한 교육 자료로 인해 크게 느려질 수 있다고 주장합니다. 그의 예측이 맞다면 대중의 믿음과 달리 AI의 급속한 발전은 오래가지 못할 것이라는 뜻이다. 지금은 가장 빠른 발전의 단계일 수 있으며, 그런 다음 속도가 느려지기 시작할 것이며, 양자 물리학의 현상 유지와 유사한 정체에 접근하면서 금세기 중반까지 크게 느려질 것입니다.
이 문제는 여기에서 발췌한 아래 뉴스에서도 논의됩니다.
https://m.thepaper.cn/newsDetail_forward_23467960
모델 축소란 무엇입니까?
기본적으로 "모델 축소"는 AI 대형 모델에서 생성된 데이터가 후속 모델의 교육 세트를 오염시킬 때 발생합니다.
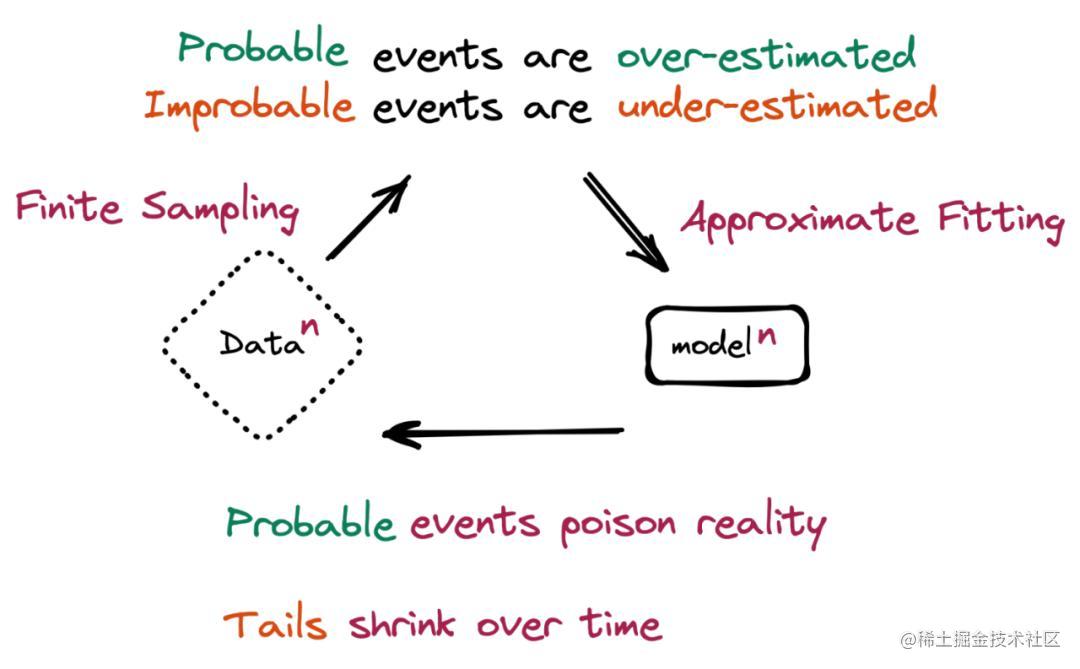
"모델 붕괴는 시간이 지남에 따라 모델이 자신의 현실 투영에 의해 오염되기 때문에 모델이 불가능한 사건을 잊기 시작하는 퇴행적 학습 과정을 말합니다."라고 논문은 말합니다.
가상 시나리오는 문제를 이해하는 데 더 도움이 됩니다. 기계 학습(ML) 모델은 고양이 100마리(파란색 털을 가진 고양이 10마리와 노란 털을 가진 고양이 90마리)의 사진이 포함된 데이터 세트에서 훈련되었습니다. 이 모델은 노란 고양이가 더 흔하다는 것을 이해하지만 파란 고양이가 실제보다 약간 더 노랗다는 것을 나타내며 새 데이터를 생성하라는 요청을 받으면 "녹색 고양이"를 나타내는 일부 결과를 반환합니다. 시간이 지남에 따라 파란색 코트 색상의 초기 시그니처는 연속적인 훈련 기간에 걸쳐 희미해지고 점차 녹색에서 노란색으로 변경됩니다. 이러한 점진적인 왜곡과 몇 가지 데이터 기능의 궁극적인 손실을 "모델 붕괴"라고 합니다.
저자는 교육 자료의 고갈은 아직 멀었지만 교육에 필요한 자료가 기하급수적으로 늘어나고 기존 자료가 따라가지 못한다면 이러한 병목 현상을 미리 겪을 수 있다는 사실을 믿는다.
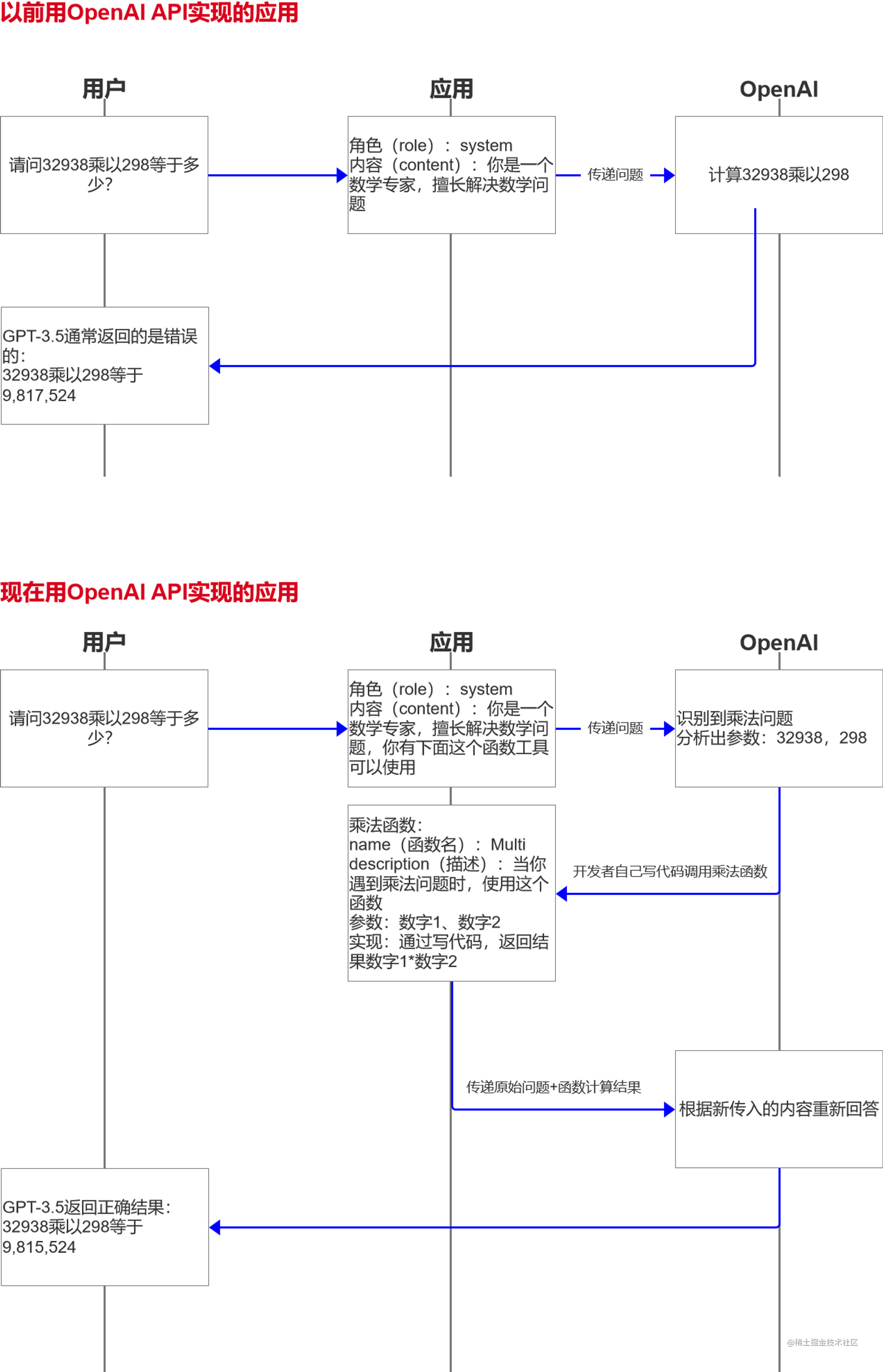
OpenAI는 함수 호출 기능을 지원합니다.
OpenAI의 함수 호출 기능과 관련하여 은유: OpenAI에 수학 질문에 답을 요청하기 전에 최면에만 의존할 수 있으며(수학 전문가임) 답변을 자주 틀리는 경우가 많습니다. 이제 OpenAI에 수학 질문에 답하고 동시에 그에게 계산기를 주면(그는 계산기를 사용해야 할 때를 알고 있지만 스스로 사용할 수는 없습니다) 그가 수학 문제임을 인식하면 그는 당신에게 숫자를 뱉어내고 당신은 계산기를 사용할 수 있습니다. 결과를 직접 계산한 다음 결과를 던지고 질문에 대답하십시오. 이것은 또한 모델 플러그인과 유사하게 다른 많은 새 모델과 함께 제공될 기능입니다.
장점: 정확하고 스마트합니다. 결과는 귀하의 기능으로 계산되며 잘못되어서는 안됩니다.
팟캐스트 노트를 빠르게 구성
Ali의 Tongyi Hewu는 오디오 콘텐츠를 빠르게 분류하여 텍스트로 변환할 수 있습니다.
먼저 팟캐스트 오디오를 다운로드하고 오디오를 Tongyi Tingwu 플랫폼으로 가져와야 합니다.오디오를 가져오고 처리하는 데 약 5분밖에 걸리지 않으며 1시간 분량의 오디오를 처리합니다.
일반적인 의미 듣기 및 이해 처리 후 자동으로 장 및 음성 전사 텍스트(다른 화자를 구별할 수 있음)를 생성하고 중국어로 텍스트 번역을 지원합니다.
그런 다음 자동으로 생성된 챕터 또는 키워드에 따라 관심 있는 콘텐츠로 빠르게 이동하고 관심 없는 콘텐츠는 모두 건너뛸 수 있습니다.
AI는 컴퓨터 알고리즘을 발명합니다.
https://www.ithome.com/0/698/425.htm
구글의 인공지능 사업부 딥마인드(DeepMind)는 AI를 활용해 정렬 속도를 70% 향상시킨 새로운 알고리즘 알파데브(AlphaDev)를 발견했다고 밝혔다.

모델
대형 모델의 순위를 매기는 방법은 무엇입니까?
대규모 모델 연구의 인기로 많은 모델이 시장에서 싸우고 있으며 모델 순위도 많습니다. 과학적으로 모델의 순위를 어떻게 매깁니까?
모델 하드 지표 측면에서 다음 측면을 비교해야 합니다.
- 모델 크기
- 훈련 데이터 세트
- 교육 및 추론 효율성
- 적용분야(싱글모달/멀티모달 등)
- …
하드 지표 외에도 인터넷에서 배웠습니다.현재 LLM에 대한 권위있는 순위 기관과 논문은 상대적으로 적습니다.더 잘 알려진 것은 LMSYS입니다.
LMSYS ORG(Large Model Systems Organization)는 UC 버클리의 학생과 교수진이 UCSD 및 CMU와 공동으로 설립한 개방형 연구 조직입니다. 우리의 목표는 개방형 데이터 세트, 모델, 시스템 및 평가 도구를 공동 개발하여 모든 사람이 대규모 모델에 액세스할 수 있도록 하는 것입니다. 우리의 작업에는 기계 학습 및 시스템에 대한 연구가 포함됩니다. 우리는 대규모 언어 모델을 훈련하고 널리 사용할 수 있도록 하는 동시에 훈련 및 추론을 가속화하기 위해 분산 시스템을 개발합니다.
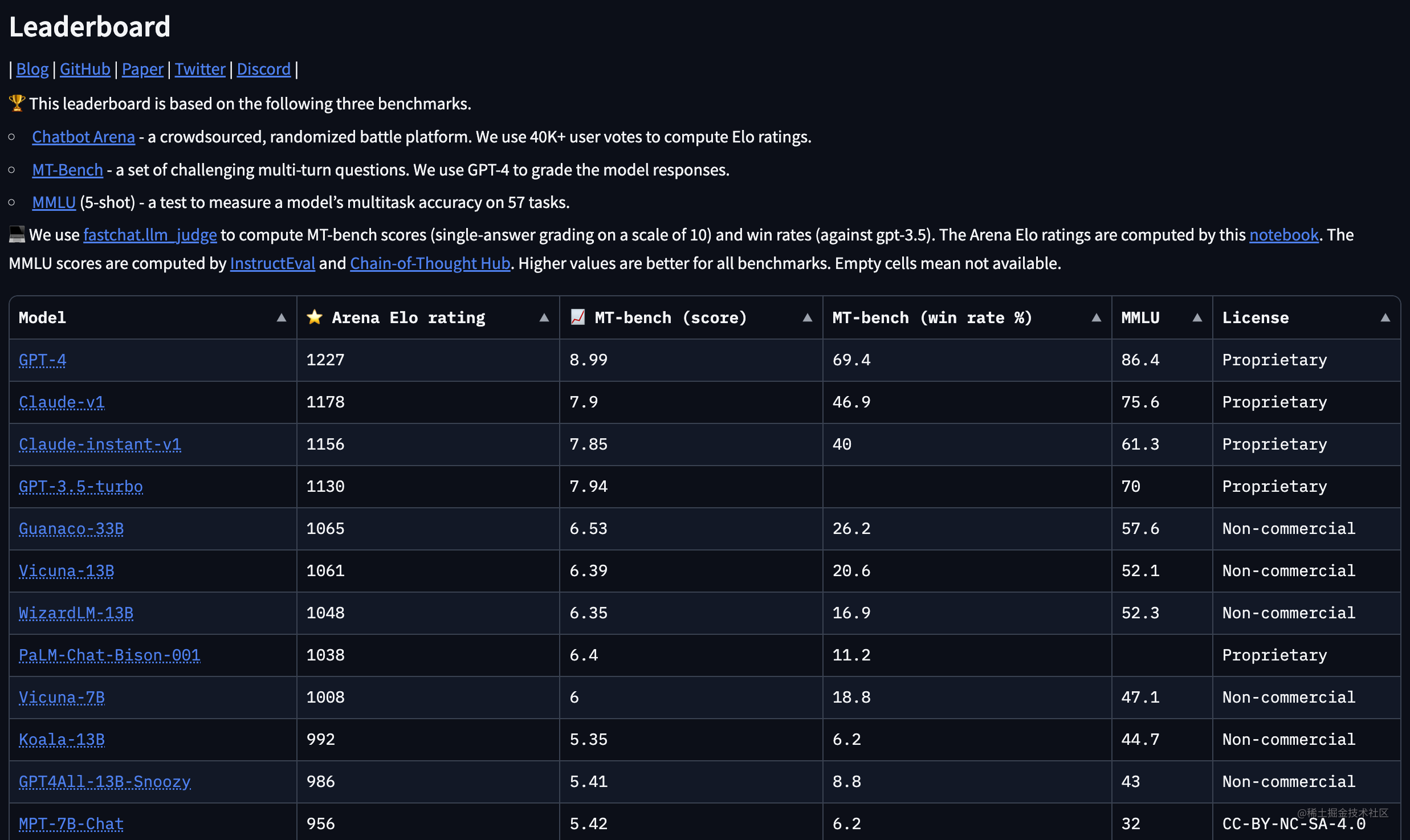
중국에 CLUE 순위표가 있는데 찾아보니 GLUE와 SuperGLUE의 외국 모델 평가를 약간 흉내 낸 느낌이 듭니다.
https://github.com/CLUEbenchmark/SuperCLUELYB

오디오 바크에 텍스트
https://github.com/suno-ai/bark
Bark는 Suno에서 만든 변환기 기반 텍스트-오디오 모델입니다. Bark는 매우 사실적인 다국어 음성은 물론 음악, 배경 소음 및 간단한 음향 효과를 포함한 기타 오디오를 생성할 수 있습니다. 이 모델은 웃음, 한숨, 울음과 같은 비언어적 의사소통도 생성할 수 있습니다. 6월 20일 현재 Github에는 20,000개의 별이 있습니다.
간단히 말해서 텍스트를 작성하고 어조를 선택한 다음 기계에서 읽도록 할 수 있습니다. 그러나 동시에 다음을 지원합니다.
- 영어 외에 다른 언어도 지원
- 헛기침, 웃음, 허밍 등과 같은 텍스트가 아닌 소리를 지원합니다.
- 음악 기호 ♪를 추가하여 노래로 읽게 하세요.
- 당신은 그에게 오디오를 공급할 수 있고 그는 모방 톤을 출력합니다
- ... (그리고 많은 능력)
지원되는 언어:
| 언어 | 상태 |
|---|---|
| 영어(en) | ✅ |
| 독일어(드) | ✅ |
| 스페인어 | ✅ |
| 프랑스어(fr) | ✅ |
| 아니 (안녕) | ✅ |
| 이탈리아어(그것) | ✅ |
| 일본어(및) | ✅ |
| 한국인 | ✅ |
| 폴란드어(pl) | ✅ |
| 포르투갈어(pt) | ✅ |
| 러시아어(ru) | ✅ |
| 터키어(tr) | ✅ |
| 중국어 간체(zh) | ✅ |
HuggingFace에서 개인적으로 해봤는데 정말 좋은데 초반에 아무렇지도 않게 해봤더니 이상한 합성음이 나와서 꽤 무섭게 들렸습니다. Stable Diffusion을 사용하면서 사람이 아닌 머리를 그리는 것처럼...
바이오의약품 분야의 빅모델
LLaVA-Med: 생물의학 영역을 위한 대규모 언어 및 시각 모델
Microsoft는 LLaVA-Med를 의료 분야에서 GPT-4로 출시하여 다중 양식을 지원합니다. X선 필름의 정보를 식별할 수 있습니다.
Github: https://github.com/microsoft/LLaVA-Med

베이징 Zhiyuan 연구소 LLM Aquila-7B
Aquila-7B: Beijing Zhiyuan Research Institute에서 개설한 국내 및 상용 LLM
중국어와 영어로 이중 언어 지식을 지원하고 상용 라이선스 계약을 지원하며 국내 데이터 규정 준수 요구 사항을 충족합니다. 33B 모델은 추후 출시될 예정이다.
Github: https://github.com/FlagAI-Open/FlagAI/tree/master/examples/Aquila
Zhiyuan Research Institute와 Zhipu AI는 동일한 기원을 가지고 있으며 후자는 현재 GLM 시리즈를 마스터합니다. 현재 전자의 후속 조치는 주로 학술 연구를 위한 것이고 후자는 주로 상업화를 위한 것입니다.
Aquila의 대형 언어 모델은 기술적으로 GPT-3 및 LLaMA의 구조적 설계 장점을 계승 Aquila의 대형 언어 모델은 고품질의 중국어 및 영어 코퍼스를 기반으로 0부터 학습됩니다.데이터 품질 관리 및 다양한 교육의 최적화를 통해 이 방법은 더 작은 데이터 세트와 더 짧은 교육 시간으로 다른 오픈 소스 모델보다 더 나은 성능을 달성합니다. 또한 중국어-영어 이중 언어 지식을 지원하고 상용 라이센스 계약을 지원하며 국내 데이터 규정 준수 요구 사항을 충족하는 최초의 대규모 오픈 소스 언어 모델입니다.
Aquila-7B 및 Aquila-33B 오픈 소스 모델은 Zhiyuan의 Aquila 시리즈 모델 라이센스 계약을 사용하며 원본 코드는 Apache License 2.0을 기반으로 합니다.
왕 샤오촨 바이촨 LLM
Wang Xiaochuan이 설립한 "Baichuan Intelligence"는 공식적으로 70억 개의 매개변수가 있는 최초의 중국어 및 영어 LLM인 baichuan-7B를 출시했습니다. 국내, 오픈소스, 무료, 상용화.
Github: https://github.com/baichuan-inc/baichuan-7B
제품
금융 GPT: FinGPT
https://github.com/AI4Finance-Foundation/FinGPT
저자는 중국 금융시장 데이터와 미국 금융시장 데이터를 사용하고, 각각 ChatGLM과 LLaMA 모델을 사용하고, Lora 교육과 협력하여 FinGPT를 만든다.
다음 응용 프로그램을 실현할 수 있습니다.
- 로보어드바이저
- ChatGPT는 전문가처럼 투자 조언을 제공할 수 있습니다.
- 이 예에서 Apple의 주가는 뉴스를 분석한 ChatGPT의 예측에 따라 상승했습니다 .
- 양적 거래
- 우리는 또한 뉴스, 소셜 미디어 트윗 또는 회사 발표를 사용하여 감정적 요소를 구축 할 수 있습니다.오른쪽 부분은 Twitter 트윗 및 ChatGPT 신호로 생성된 거래 결과입니다.데이터는 stocknet-dataset 이라는 데이터 세트 에서 가져옵니다.
- 사진에서 볼 수 있듯이 ChatGPT에서 생성된 거래 신호는 훌륭합니다 . 우리는 Twitter 감정 요소에서 거래하는 것만으로도 좋은 결과를 얻을 수 있습니다 .
- 따라서 가격 요소를 결합하여 더 나은 결과를 얻을 수 있습니다.
- 로우 코드 개발
- LLM의 도움을 받아 코드를 작성할 수 있습니다.
- 오른쪽은 요소 및 기타 코드를 빠르고 효율적으로 개발한 방법을 보여줍니다.
Microsoft HuggingGPT
https://huggingface.co/spaces/microsoft/HuggingGPT
다양한 영역과 양식에서 AI 작업을 해결하는 것은 인공 지능을 향한 중요한 단계입니다. 다양한 영역과 양식의 문제를 해결하는 데 사용할 수 있는 AI 모델이 많이 있지만 복잡한 AI 문제는 해결할 수 없습니다. 대형 모델(LLM)은 언어 이해, 생성, 상호 작용 및 추론에 강력한 기능을 나타내므로 저자는 LLM이 복잡한 AI 작업을 해결하기 위해 기존 AI 모델을 관리하는 컨트롤러 역할을 할 수 있으며 언어가 공통 인터페이스가 될 수 있다고 생각합니다. AI가 이러한 작업을 처리할 수 있도록 합니다. 이 아이디어를 바탕으로 저자는 AI 작업을 해결하기 위해 서로 다른 AI 모델을 연결하는 프레임워크인 HuggingGPT를 제안합니다.
구체적인 단계는 다음과 같습니다.
- 작업 계획: ChatGPT를 사용하여 사용자 요청 받기
- 모델 선택: Hugging Face의 기능 설명에 따라 모델을 선택하고 선택한 모델을 사용하여 AI 작업 수행
- 작업 실행: 2단계에서 선택한 모델을 사용하여 수행한 작업을 답변으로 요약하여 ChatGPT로 반환
- 답변 생성: ChatGPT를 사용하여 모든 모델의 추론을 융합하고 답변을 생성하여 사용자에게 반환합니다.
ChatGPT의 강력한 언어 능력과 Hugging Face의 풍부한 모델 라이브러리를 통해 HuggingGPT는 가장 복잡한 AI 작업을 해결하여 진정한 인공 지능의 기반을 마련할 수 있습니다.

AI 지식 기반
나는 그것을 직접 시도하고 좋은 아이디어를 얻었습니다. 기사를 쓰거나 동영상을 제작할 영감이 없을 때 지금 마음속으로 주제를 생각하고 AIbus가 생각을 분산시키기 시작하도록 하고 간단한 브레인스토밍을 수행할 수 있습니다.
그에 대한 텍스트 톤을 설정할 수 있습니다.
카피라이팅의 읽기 대상을 설정하고 이해도에 해당하는 문장을 생성할 수 있습니다.

Java String 소개에 대한 블로그를 작성하고 Java String을 키워드로 사용한다고 가정하면 아래 그림은 그가 나를 위해 단계별로 생성한 사본이며 그림도 생성됩니다.
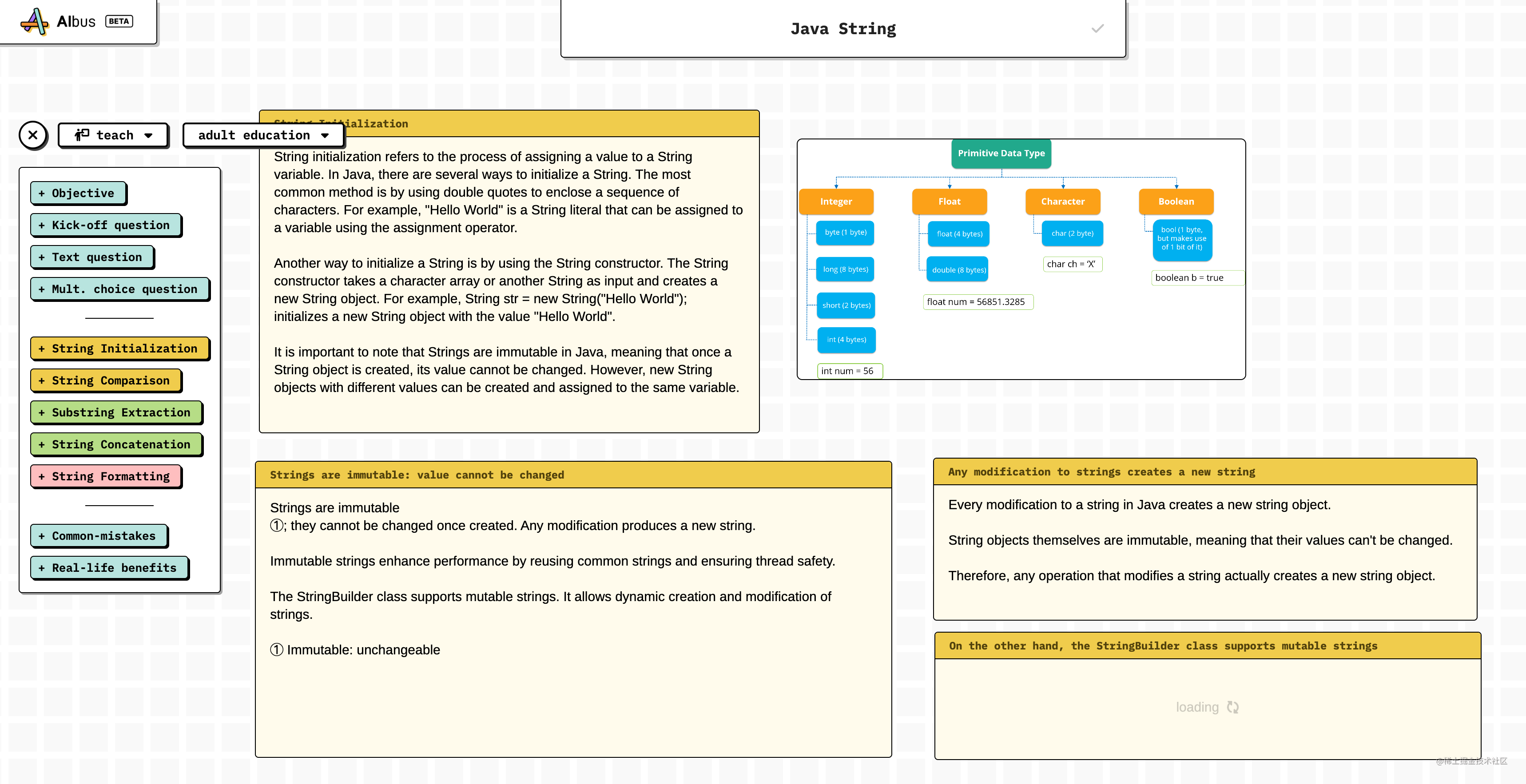
이제 나는 기술 블로그를 작성하는 것이 점점 더 잘못된 제안, 특히 기본 지식과 관련된 블로그를 작성하더라도 AI 모델을 먹일 것이라고 점점 더 느끼고 있습니다.
AI 비디오 변경 스타일
원본 비디오를 제공한 다음 원하는 스타일을 선택하면 AI가 자동으로 새로운 스타일 비디오를 생성합니다.
나는 또한 미세 조정 매개 변수, 프롬프트 단어 수정 및 생성된 비디오를 기반으로 반복을 지원할 수 있는 공식 데모 비디오로 시도했습니다. 내가 생성한 효과는 특별히 이상적이지 않으며 여전히 조정해야 합니다.

도구
Vercel, AI SDK 출시
Vercel은 잘 알려진 클라우드 개발 서비스 제공 업체입니다. 이번에 OpenAI, LangChain 및 Hugging Face Inference와의 협업 모듈이 내장되어 개발자가 인프라 구축보다 제품 개발에 집중할 수 있도록 하는 것이 목적입니다. 예측이 정확하지 않을 수 있습니다. Vercel과 OpenAI는 향후 웹 AI 제품을 만들기에 충분할 것입니다.
https://vercel.com/blog/introducing-the-vercel-ai-sdk
SD를 통해 QR 코드를 이미지로 변환
이 사이트는 Stable Diffusion을 사용하여 QR 코드를 이미지로 변환하는 방법을 알려줍니다.
정말 의미있는 일인거 같아요 여러곳에서 온갖 QR코드를 올리는게 정말 못생겼네요 음식, 상품, 인물사진 등 상인들의 홍보사진을 삽입할수 있다면 정말 유용하고 상품화.
https://stable-diffusion-art.com/qr-code/


참고
Meta360 혁신 아카데미 - AGI Eve
Github 트렌드