디렉토리
응용 프로그램의 종료가 실행 될 때까지 3, 클라이언트 모드에서, 드라이버 프로세스가 현재 클라이언트에서 시작, 클라이언트 프로세스가 존재한다.
(1) 제 실의 모델도 소개
(1)도 1의 실 모델.

다음 (2)은, 실 프로세스는 :
YARN 차례로 다음 단계로 나눌 수 있습니다, 그 과정에서 신청서를 제출 :
(1) 클라이언트 RM에 의해 사용자에게 신청서를 제출
(2) RM 새 응용 프로그램을받은 후, 먼저 응용 프로그램 별 AM을 시작하기위한 컨테이너를 선택합니다
자원 (3) AM 시작 후, 필요성은 RM을 실행하는 응용 프로그램을 요청합니다
(4) RM은 AM 용기 자원 컨테이너 ID 및 컨테이너의 호스트 명으로 표현 가능한 할당 요청
지정된 컨테이너 ID 및 호스트 이름 (5)에 따라 AM은, 해당 리소스 요구가 특정 애플리케이션을 사용 NodeManager 이러한 작업을 시작한다.
(6) NodeManager는 작업 및 자원의 사용 상태를 모니터링하는 작업을 시작합니다.
구현 (7) 지속적인 모니터링 작업을하고있다.
작업 실행이 완료되면 (8), AM과 RM이 작업을 수행 할 컨테이너의 취소에보고, 자신을 로그 아웃합니다.
2, 클러스터 모델은 작업 흐름에 따라 제출
(1) 다음 흐름도
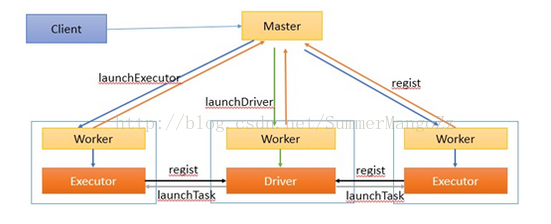
다음과 같이 (2), 작동 :
클러스터에 노드 후, 마스터 (ResourceManager에)를 시작 1. 근로자 (NodeManager ) 과정, 근로자 (NodeManager) 프로세스는 마스터 (ResourceManager에)에 등록됩니다 성공적으로 시작했다.
3. 고객을 제출 작업 후, 마스터는 작업자 노드가 드라이버 (응용 석사) 과정을 시작 알립니다. (일부 노동자는 한 노동자가 충분한 자원을 가지고로서, 임의)
드라이버가 성공의 프로세스를 시작한 후를 성공은 마스터 등록 정보로 돌아갑니다
집행자가 작업자 프로세스에 통지 시작 4.master
5. 시작 드라이버를 성공적으로 등록 후 집행 과정을
6.Driver 분할 작업의 단계와 단계는 더 분열이었다 작업, 집행 과정에서 파이프 라인으로 모든 작업을 캡슐화하고 자신의 작업 실행 스레드에 등록 된 전송
7. 모든 작업 실행 종료 후, 프로그램 종료
우리가 알고있는 위의 설명을 통해 : 이잖아요 (ResourceManager에) 전체 클러스터 자원 관리에 대한 책임과 노동자 (NodeManager), 현재 노드의 자원을 관리 할 책임이 노동자를 만들고, 현재의 CPU, 메모리 타이밍 마스터를 알리기 위해 다른 정보를 저장하고, 집행 인은 (이다, 가장 작은 자원 할당 단위) 과정, 드라이버 (applicationMaster) 전체 작업 응용 프로그램 작업 부서 및 작업 및 절단 및 최적화의 단계에 대한 책임 절단을 만들기위한 책임과 집행에 해당하는 작업자 노드에 배포하는 작업에 대 한 책임이있다 작업 실행 스레드의 처리, 그리고 작업의 결과를 얻을, SparkContext 개체와 스파크 클러스터 연락처에 대한 드라이버, 마스터 호스트 호스트를 얻을, 당신은 RPC를 통해 마스터로 자신을 등록 할 수 있습니다.
마스터 스파크 클러스터는 전체 클러스터 자원 관리에 대한 책임 ResourceManager에의 원사 및 근로자를 만드는 것입니다.
작업자 스파크 클러스터는 현재 노드의 자원 (CPU, 메모리) 관리를 담당 NodeManager의 원사입니다.
드라이버는 고유의 각 응용 프로그램의 작업입니다. 원 사는 applicationMaster입니다.
각 작업자는 작업을 수행해야합니다.
각 폭에 의존 단계가 있습니다.
실행기 * = 핵심 태스크의 수, 작업 공정은 격벽에 대응.
3에서 클라이언트 모드 에서, 드라이버 프로세스가 현재 클라이언트에서 시작됩니다 응용 프로그램이 끝날 때까지 클라이언트 프로세스의 존재가 실행 중입니다.
(1) 클라이언트 모드의 흐름도
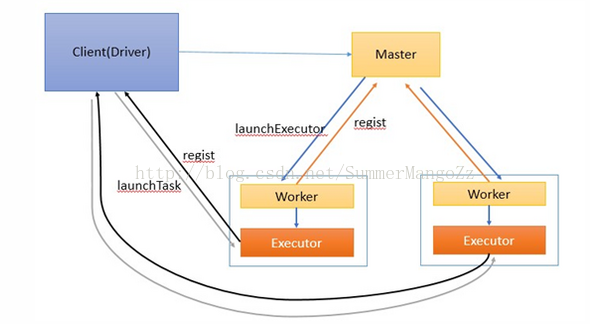
다음과 같이 (2), 작동 :
1. 마스터와 노동자. 전체 클러스터의 자원 관리, 마스터에 자신의 CPU, 메모리 정보를 정기적으로 보고서를 모니터링하기위한 책임을 노동자에 대한 책임을 노동자
클라이언트 프로세스에 2. 시작 드라이버, 등록 된 마스터
작업자 RPC에 의해 3.master 통신, 알림 노동자는 하나 개 이상의 실행 프로그램 프로세스 시작
, 드라이버 정보가 호스트와 다른 노드 곳을 포함, 자신을 알리기 위해 드라이버에 4.executor 등록 절차를
것, 작업의 5.Driver 분할 단계와 단계 더 분할했다 모든 작업은 작업, 집행자의 파이프 라인으로 캡슐화과 등록에 전송
작업 실행 스레드에서 처리
응용 프로그램의 실행이 완료 6. 드라이버 프로세스 종료
4, 스파크 작업 스케줄링
이러한 의존성의 각 의존성 사이 RDD는 비순환 그래프 DAG를 향하는 형성하는 이들 DAGScheduler가 DAG 스테이지 뒤에서 앞으로, 분할 매우 간단한 규칙을 분할되어 형성된 종속 좁은면 의존성 첨가 이 단계는 단계 폭에 의존 분할을 충족. 스테이지 부문의 완성. DAGScheduler는 당 단계 TaskSet 생성 및 TaskSet은 TaskScheduler에 제출했다. 특정 작업 스케줄링에 대한 책임 TaskScheduler, 그리고 마지막으로 작업자 노드에서 작업을 시작합니다.
