>> PaddlePaddleは公式サイト、訪問より関連性の高いコンテンツを。
人生の加速ペースで、「待機」は、より多くの人々が離れて物事をしたいとなっています。しかし、本研究の被写界深度、モデルパラメータのサイズ、データセット、およびSO毎ターンでそれ以上に背景音楽が本当にあるとして、鉄道模型の成功は、「あなたが最後になるまで」ジェーン・デビューを入れたときに、ユニットとして数十億ですあまりにも機会。
アーティファクトは今あなたに、あなたは二重のトレーニングの速度を達成できることをお勧めされている場合は、メモリアクセス効率が2倍になる、あなたは心、それを?(チャネルを変更する心配しないで、これは直接テレビではない)、と私は一緒にこのアーティファクトを見ている、それを手に入れた - 自動ブレンド精度(自動混合プレシジョン)技術、フライパドルパドルは、AMP技術がコアフレームワークに基づいて飛ぶと呼ばれます。
簡単かつ迅速にのみ単精度トレーニングモデルは自動的にコードの行によって精度の訓練をブレンドに変更しますヘルプユーザーにパドルAMP技術をフライング。安定性を確保し、INFまたはNANの問題を回避するために、黒と白のリストと動的損失スケーリング研修を通じて同時に。AMPは、Transformerが他のモデルと比較して、テンソルコアトレーニング速度と単精度トレーニングResNet50に性能上の利点を計算パドル完全世代のNVIDIA GPUを飛ぶことができる1.5 2.9倍に上昇させることができます。
そして、それを実現する方法ですか?自動的に混合精密技術の話であるものにしましょうスタート。
自動ミキシング技術の精度は何ですか
名前が示唆するように、モデルトレーニング技術を促進するために混合精度の自動、半自動および単精度混合物です。前記単精度(フロートPrecision32、FP32)は、データ・タイプ、一般的に使用されるコンピュータであり、理解しやすいです。だから、半分の精度は何ですか?示されるように、半精度1の浮動小数点の比較的新しいタイプである(Precision16、FP16はフロート)、binary16呼ばれるIEEE 754-2008、コンピュータに格納された2バイト(16ビット)を使用し。従来の計算単精度と倍精度型と比較して、Float16低い精度は、シーンでの使用に適しています。
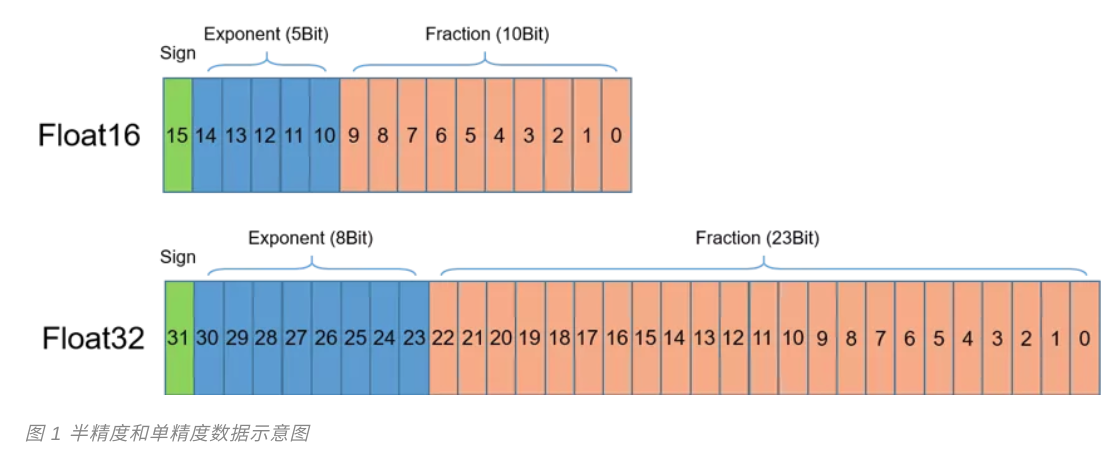
開発者は、より大きなバッチサイズを使用し、より大きく、より複雑なモデルを訓練することができますので、それは、もし代わりに、データの格納にFloat16のfloat32を使用するのでは、研究の被写界深度で、言うまでもないです。だから、GPU、各トランジスタの可能性を最大限に活用することを切望これらの科学者のために、それをどのように欠場することができますか?そして、NVIDIAは、ボルタGPUアーキテクチャを導入し、チューリングテンソルコア技術、満期半分の計算の精度が含まれているため。同じGPUハードウェア上で、単精度の8倍の精度スループットテンソルコア半計算。
確かにFloat16の使用も、精度の損失をもたらすことは明らかです。しかし、学習やトレーニングの深さの点で、すべての計算は、高い精度を必要としない、最終のトレーニング効果に精度の影響のいくつかの部分的な損失のfloat32を算出することができる精度を維持するだけいくつかの特別な手順を必要とする非常に弱いです。このように算出したブレンド精度の需要が浮上しました。我々は、プロセスをトレーニングすることができ、精度のいくつかの損失に敏感ではなく、加速度の半精度演算処理、最大増加計算効率とメモリアクセスを使用して、テンソルコアを使用することができます。
しかし、それぞれの特定のモデルのために、我々は緊急に効率的にブレンド精度の研修を実施し、より簡潔な方法を必要とする、非常に複雑で精度を混合する人工的な方法を設計してみてください。AMPは、名前が示唆するように、それは重要な機能だと使用に混合精度の自動化トレーニング、とても簡単にできるようにすることです。具体的にあなたがたの使用は、ダウンしています!
AMPの使用
AMP技術を飛ぶためにパドルを使用する方法を紹介するMNIST例以下に。次のコードに示すようMNISTネットワークを定義しました。conv2d、batch_norm(BN)とpool2dデータニーズがレイアウト「NHWC」に予め設定される請求、これはトレーニングのブレンド精度を加速するために役立つ、出力チャネルの数は、テンソルコア加速技術を使用するために、4の倍数に設定する必要がconv2d。
import paddle.fluid as fluiddef MNIST(data, class_dim):conv1 = fluid.layers.conv2d(data, 16, 5, 1, act=None, data_format='NHWC')bn1 = fluid.layers.batch_norm(conv1, act='relu', data_layout='NHWC')pool1 = fluid.layers.pool2d(bn1, 2, 'max', 2, data_format='NHWC')conv2 = fluid.layers.conv2d(pool1, 64, 5, 1, act=None, data_format='NHWC')bn2 = fluid.layers.batch_norm(conv2, act='relu', data_layout='NHWC')pool2 = fluid.layers.pool2d(bn2, 2, 'max', 2, data_format='NHWC')fc1 = fluid.layers.fc(pool2, size=50, act='relu')fc2 = fluid.layers.fc(fc1, size=class_dim, act='softmax')return fc2
MNISTネットワークを訓練するだけでなく、ここで使用される損失関数を最適化するために、重みパラメータを更新するために、損失関数を定義する必要がありますするにはSGDOptimizerです。説明を簡単にするためだけの損失関数の定義および関連コンテンツの最適化を反映するためにここに関連するコードの反復訓練を省略しています。
import paddle.fluid as fluidimport numpy as npdata = fluid.layers.data(name='image', shape=[None, 28, 28, 1], dtype='float32')label = fluid.layers.data(name='label', shape=[None, 1], dtype='int64')out = MNIST(data, class_dim=10)loss = fluid.layers.cross_entropy(input=out, label=label)avg_loss = fluid.layers.mean(loss)sgd = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)sgd.minimize(avg_loss)
したがって、上記の例になります、それを訓練AMPを使用する方法にどのように変換?次のようにのみ使用フライパドルに必要ユーザーは、更新、コードを元のAMP機能fluid.contrib.mixed_precision.decorateオプティマイザSGDOptimizerカプセル化を提供し、そしてオプティマイザ(mp_sgd)を使用してカプセル化勾配パラメータ:
sgd = fluid.optimizer.SGDOptimizer(learning_rate=1e-3)mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd)mp_sgd.minimize(avg_loss)
パドルAMP機能を飛ぶ使用するのが最も簡単です。
しかし、我々はそれが変換されるように感知する方法をオペレータ(OP)のものをモデルに、いくつかの質問を持っていること?あなたはそれを手動で指定する必要はありませんか?演算子そんなに、どのように私はそれに変換することができるオペレータを知っていますか?心配は、あなたが助けにパドルカスタムまあフライ持っている、これは、この技術は「自動」の理由の一つとして知られており、上読んでくださいしないでください!
ブラックとホワイトリスト機能
開発者が簡単かつ迅速にブレンド精度を使用して計算、パドルがエンジニア多数の異なるアプリケーションシナリオを繰り返し検証のモデルを使用し、その後、効果を加速安定性および半精度データ型から計算飛ぶことができる可能にするために、カーディングの一連を変換します半精度算術演算子、およびオペレータがホワイトリストファイルを定義します。すなわち、半精度を使用して、不適切変換演算子であることが見出されている間、いくつかの検証のための数値計算は不正確なオペレータにブラックリストファイルに記録されますもたらします。また、いくつかは、グレーリストとして分類され、半精度計算のオペレーターに大きな影響を持っていません。AMPトレーニングプロセスを使用して、システムが自動的に半精度計算に変換するオペレータの知覚を必要とするものだから、ホワイトリストを読み込みます。
開発者は、カスタムのブラックリストとホワイトリストを使用したい場合は、いくつかの特別なシナリオでは、あなたはクラスのコード例を以下に示してAutoMixedPrecisionListsに使用することができます。
sgd = SGDOptimizer(learning_rate=1e-3)# 指定自定义的黑白名单,其中 list1 和 list2 为包含有算子名称的列表amp_list = AutoMixedPrecisionLists(custom_white_list=list1,custom_black_list=list2)mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd, amp_list)mp_sgd.minimize(avg_loss)
そして、自動混合精密技術は「自動」第二の理由として知られていますか?これは、自動調整損失スケーリング機能を下回っています。
自動調整損失スケーリング
AMP技術の副作用が明らかであると、メモリアクセスと計算効率を向上させながら。比較して、単精度とフロント半精度データ型変換の精度範囲を狭くするため、すなわち、INFとNANの問題を容易に製造をもたらすです。このような問題を回避するために、関数のスケーリング自動調整AMP損失、即ちAMPトレーニングプロセスを達成するための技術は、アンダーフロー精度、学習データの各バッチの一定量を避けるためには、損失増幅率を指定します。オーバーフローは、増幅過程で発生した場合損失が、さらに、特定の複数を減らす全体トレーニングプロセスは、勾配が適切に収束させることができることを保証することが可能です。
機能関連パラメータをスケーリング損失を運ぶfluid.contrib.mixed_precision.decorate自動調整機能、デフォルト値をこれらのパラメータは、以下のコードに示すように。これらのデフォルト値は定義された複数の検証エンジニアパドルを飛んでいます。一般的に、ユーザーが直接再設定せずに使用することができます。
sgd = SGDOptimizer(learning_rate=1e-3)mp_sgd = fluid.contrib.mixed_precision.decorator.decorate(sgd,init_loss_scaling=2**15,incr_every_n_steps=2000,use_dynamic_loss_scaling=True)mp_sgd.minimize(avg_loss)
マルチGPUカードの最適化訓練
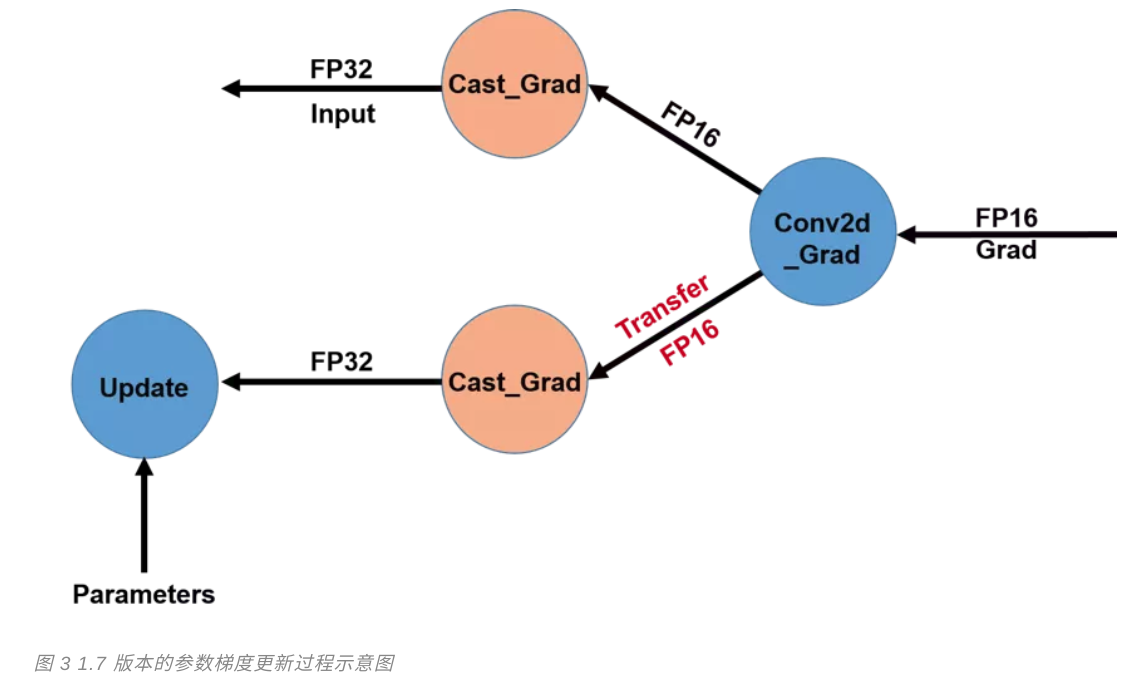
マルチGPUカードを最適化するための新しいフライパドルリリースのコアフレームワークの1.7バージョンでは、AMPの深さ、技術研修。2、勾配パラメータ更新プロセス最適化の前に、場合半精度データ型を使用して勾配計算が、単精度GPUカード残るの異なるタイプ間でのデータの伝送の勾配ありません。
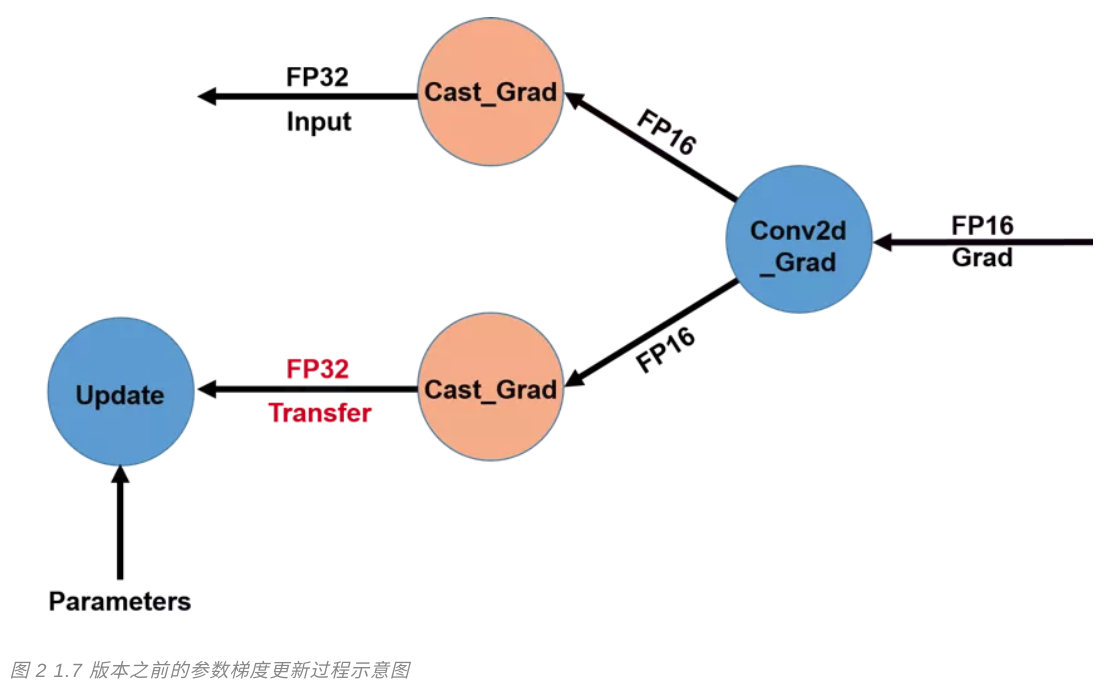
複数のGPUカードとの間で伝送帯域勾配を低減するために、我々は、単精度型に変換された対応する操作キャストを実行した後に得られた勾配で前述した勾配演算処理キャスト、各半精度GPUカードを送信します図3は、図2に示します。大規模なネットワークの複雑さを訓練で、この最適化モデルは、帯域幅は、このような訓練BERT-大型マルチカードモデルとして、減らすのに非常に有効です。
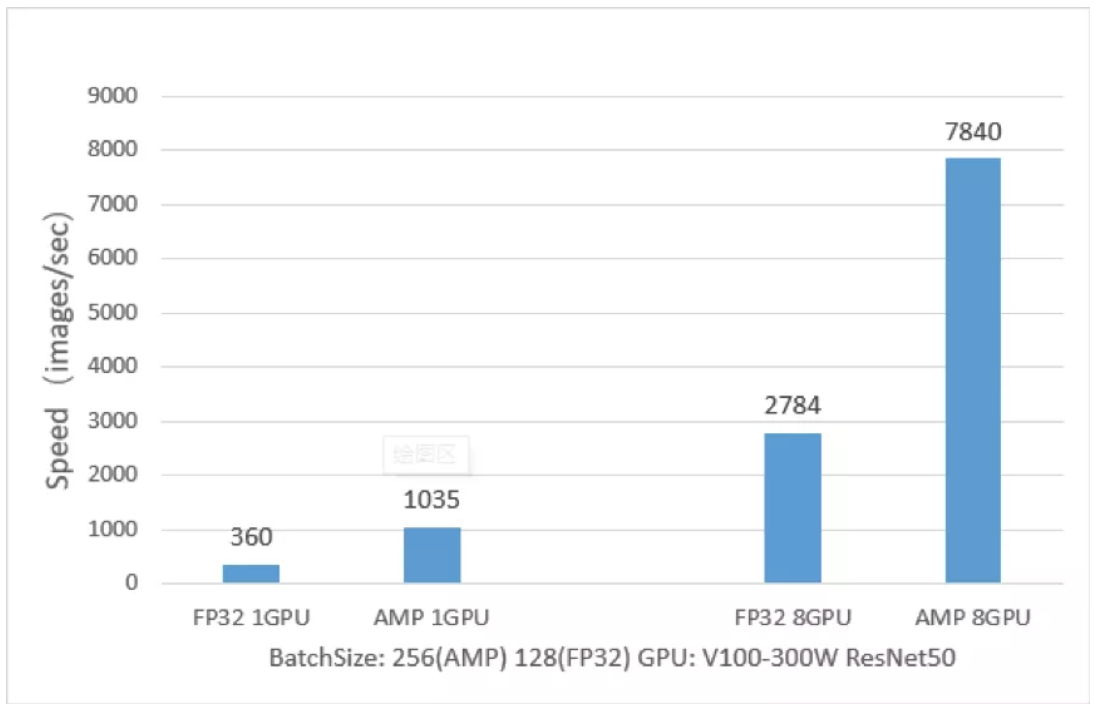
トレーニングパフォーマンスの比較(AMP VS FP32)
技術パドルAMP ResNet50にフライング、トランスピアモデルはResNet50モデルには、以下の例のように、非常に大きな利点に対する訓練速度FP32で訓練され、それは図から分かるように、反対のAMPトレーニングResNet50 FP32は、単一の訓練します2.9倍、2.8倍までの8つのカルガリー比までのカルガリー比。
関連情報
-
混合精度トレーニングします。https://arxiv.org/abs/1710.03740
-
自動混合精度加速度PaddlePaddleトレーニング:HTTPS :? //On-demand-gtc.gputechconf.com/gtcnew/sessionview.phpたsessionName = cn9312-自動混合精密加速度+ paddlepaddle +トレーニングを使用して
>> PaddlePaddleは公式サイト、訪問より関連性の高いコンテンツを。