
正と負のサンプルの不均衡の問題を解決するためのサンプリング(オーバー)の下で、道を作っ使用説明されてきた、この記事では、我々は正と負のサンプルの不均衡を解決するために第2の指標を導入 - 重量処罰する権利の正と負のサンプルをサンプルがバランスされていない解決。
現在、このようなAのデータセットが存在すると仮定する:0データセットは、100個のサンプル、10のサンプル1、110個のサンプルの合計を有します。試料の割合が0、10:1です。次の方法の導入の全てにおいて、我々は、例えば、このデータセットに対処する必要があります。
まず、シンプルかつ粗製の方法:
1、原則
例を見て:私はに参加したい場合は、言語テストと数学のテストを取るの両方が、あまり私は言語の問題を練習することができたので、私は、数学的な言語モニフアンモニファンの手と10セットを持っているので、私午前このボリュームは、言語のいくつかにもっと注意を払う必要があります。
同様に、より高い重量所与の小さなサンプルサイズのカテゴリに値の減量、軽量、シンプルで小型サンプルラベルの関数としての重量損失を増加させる粗に価値の損失に大きなサンプルサイズのカテゴリには、あなたが行うことができモデルは、より多くの試料中に含まれる以下の情報カテゴリが心配です。
当社は、損失関数の実施形態、詳細に具体的な実施プロセスを横断します。
以下のように、通常のクロスエントロピー損失関数が計算されます。
損失= -ylg(P) - (1-Y)、LG(1-P)
1のサンプルのために、モデルは私たちのサンプルを与えた場合、確率のサンプルは0.3であるが、その値の損失-LG(0.3)が0.52を=。
0サンプルについて、サンプルは我々のモデルに与えられた場合には、試料が0.7である確率(即ち、予測サンプルの確率も0 0.3である)、得られた損失-log(0.3)= 0.52です。
サンプルのモデル損失関数が同じで与えられ、同じ0,1偏差を持っていることがわかります。
データセットの最上部には、のみ1/10 1のサンプル0サンプル以来、私たちは体重減少はサンプル重量が10倍に増加させることができ、新たな損失関数は次のようになります。
Loss2 = -10 YLG(P) - 1(1-Y)、LG(1-P)
試料1について、確率モデル、我々は正のサンプルが0.3である与えるが、値はLoss2 -10lg(0.3)= 5.2に変更され、負のサンプルに関して、それはまだLoss2 0.52です。
すべての1-サンプル予測誤差を、私たちはモデルが完全な使用のみを確実にするために十分な注意を払って偽陽性のサンプルを予測するように、サンプルの値が0である10回の損失でモデルをあげることを、この手段陽性サンプル。
2、で実装されているscikit-学びます
このプロセスは、より多くの私たちのほとんどは、学ぶscikitに実装され、独自のアルゴリズムを持っていないとされるよりも、モデルとアルゴリズムの多くは、私たちは、実際のサンプルサイズの比率に応じて重量区分を調整するインタフェースを提供します。
SVMアルゴリズムには、例えば、設定することにより、class_weigh手動に値を正と負のサンプルを失う重量比に私たちが望むように体重などの異なる重量区分を、指定した10に設定されている:1、ちょうどこのパラメータを追加しますclass_weight= {1:10,0:1}。
もちろん、我々はまただけ、遅延することができる:class_weight = 'balanced'、SVMはパワーに重み付けし、あろうサンプルの異なる種類の数は、自動等化のための重量に反比例するように、重みは次のように計算される:サンプルのサンプル/(カテゴリの数*は、特定の種類の総数数)。
上側に示したデータセットの場合は、算出された、サンプル重量重量0:110 /(2 試料重量の100)0.55,1 =重量:110 /(2 10)5.5 =。図1に示すように、サンプル0の重量損失が比で計算した後:0.55:1:10 = 5.5、正確にサンプルの数に反比例するサンプルの数の比は、0、1、10、見ることができます。
SVM、決定木、ランダムフォレストアルゴリズムは、このように指定することができます。
1)まず、パッケージは、正および負のサンプルをインポートする必要があり、データ・セットを生成することはバランスされていません。
from sklearn.svm import SVC
from sklearn.model_selection import train_test_split
from sklearn.metrics import recall_score
import numpy as np
############################ 生成不均衡的分类数据集###########
from sklearn import datasets
X,Y = datasets.make_classification(n_samples = 1000,
n_features = 4,
n_classes = 2,
weights = [0.95,0.05])
train_x,test_x,train_y,test_y = train_test_split(X,Y,test_size=0.1,random_state=0)
サンプル0サンプル1とここで生成さの比が95:5です。
2)正及び負のサンプルは、列車をSVM分類器を処理していません
SVM_model = SVC(random_state = 66) #设定一个随机数种子,保证每次运行结果不变化
SVM_model.fit(train_x,train_y)
pred1 =SVM_model.predict(train_x)
accuracy1 = recall_score(train_y,pred1)
print('在训练集上的召回率:\n',accuracy1)
pred2 = SVM_model.predict(test_x)
accuracy2 = recall_score(test_y,pred2)
print('在测试集上的召回率:\n',accuracy2)
出力:
トレーニングセットのリコール:
0.56
テストセットの再現率:
0.2
サンプルは非常に不均一であるため、0,1、すべてのサンプルのモデルは0サンプルであると判断された場合でも、モデルは95%の正解率を取得しますが、実際の使用では、我々は、抗などの小さなサンプルを、フィルタリングできるようにモデルをしたいです疑わしい取引、マネーロンダリング、不良債権でクレジットカード。
そこでここでは、正のサンプル検出の効果を判断するためにリコールを使用し、あなたが見ることができ、通常の状況下では、テストセットの再現率はわずか0.2です。
3)正および負のサンプルに対して異なる値を設定する権利は、SVM分類器を再訓練を失っ
SVM_model2 = SVC(random_state = 66,class_weight = 'balanced') #设定一个随机数种子,保证每次运行结果不变化
SVM_model2.fit(train_x,train_y)
pred1 =SVM_model2.predict(train_x)
accuracy1 = recall_score(train_y,pred1)
print('在训练集上的召回率:\n',accuracy1)
pred2 = SVM_model2.predict(test_x)
accuracy2 = recall_score(test_y,pred2)
print('在测试集上的召回率:\n',accuracy2)
出力:
トレーニングセットのリコール:
0.8
リコールのテストセットに:
0.8
それは、十分なサンプル重量を与えられた後、リコールが大幅にそれが0.8になり、増加している見ることができます。
(これはサンプル1と0のサンプルの一部を誤解を識別するために、モデルです心配しないでくださいあなたはここで、精度を評価するために、ここでの精度を使用する場合は、あなたが悪いことを見つけるでしょう、これは正常です。)
また、いくつかのアルゴリズムは、インタフェースを提供することはできません、我々はまた、トレーニング機能に合うことができるsample_weightパラメータを指定しました。特定のリファレンスマニュアルを参照してscikit-学びます。
注:あなたが誤って2つのパラメータは使用されている場合は、サンプルの最終重量にして右がプラスまたはマイナス:class_weight * sample_weight
第二に、より洗練されたアプローチ:
第1の方法では、我々は、単に無礼重量損失を決定するために、このアプローチは効果がサンプルサイズの様々なタイプを介して非常に重要であろう有し反比例します。しかし、上記のサンプルを分類することはより困難のいくつかの処理を改善するために何かをしていない、我々だけでなく、サンプルのバランスをとるようにしたい、とあなたはサンプルの損失および提供容易な分類の割合を減らしたい、損失の割合が増加して分類サンプルに困難です。それはのようなものです:私たちは、この言語モニファンにもっと注意を払う必要がありますだけでなく、ボリュームヤード間違った質問のこのセットに集中します。焦点損失(動的調整重み)アイデアは、これらの二つの側面の間の完璧なバランスです。
フォーカル損失オリジナルのアイデアは、1つのより多くの事を言い、ここで、カテゴリ内の不均衡の画像検出問題を解決するために提唱された、画像検出エリアは、ほとんどの場合、理由は一つの画像では、正と負の不均一な領域の代表的なサンプルであります、目標は、画像の小さな部分を占める背景画像の大部分を占めるように常にあります。あなたは毎日のサンプル不均衡データの問題に対処する場合は、画像検出フィールドを見て、インスピレーションのために見てみましょう。
我々はまだ一例としてその2クラスのクロスエントロピー損失関数を考えます。に基づいて焦点losss損失関数
次のようになります。
この式を詳しく見は、右の重量損失関数は、2つの重みによって決定されます。
、言って第1の重み言うまでもなく、陽性および陰性試料の量は、第2の重みを表示することが焦点で減量のカスタムメソッドに基づいています。
( - 0.9 1)^ 2 = 0.01、モデルが予測した場合、確率サンプル1はサンプルである:いくつかのサンプル1について、モデルは、0.9の確率標本であると予測した場合、第2の重みであります0.6は、次いで、第2の重みは次のようになります(0.6から1)^ 2 = 0.16。サンプル予測精度の低い、重い重量損失の割合の値が大きくなります。
図オリジナル紙鮮やか示し、横軸は、予測の確率を表すと共に、縦軸は損失確率の値を示し,,赤い点線中間の予測が0.5である表し、破線の左半分の大きな偏差予測モデルを表す、代表の右半分モデルは、小さな偏差を予測します。ガンマ= 0における損失値は、重量が2番目のエントリが参加しないです。
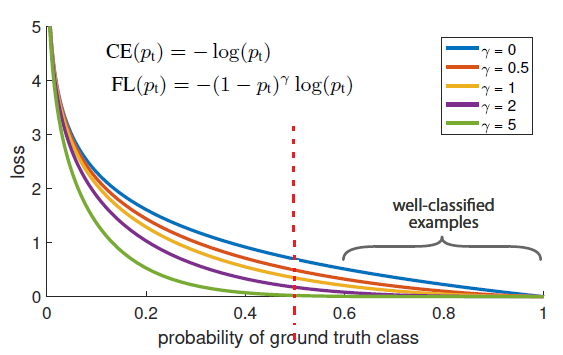
これは、ガンマ増加、赤線の左半分、いくつかの曲線損失値の差として、それに対して図青い曲線に見ることができますしかし、赤い線の値の損失の右半分は急速にゼロに近づいていません。
そして、もっと微妙に、一般的に、多くの言葉よりもサンプル0 1つのサンプル場合、モデルは確かに、(すべてのサンプルは、クラス0を宣告された、モデルの精度率が高いままで)0にサンプル予想のこのタイプに傾くことになりますモデルの上に第二の重重量は少数のサンプルに集中するより多くのエネルギーを費やすことを求めるメッセージが表示されます。
それを要約すると、焦点損失はさらにコントラストの分類であるサンプルの重量損失を増加させることは困難であるため、モデルのサンプル点が間違っているより多くの注意ので、迅速な収束モデルという、より良いパフォーマンスを得ます。
scikit-学ぶまだ実装されていない、自分の興味を達成することができ、を考えるの焦点喪失。
