ZooKeeperの紹介
ZooKeeperのは、分散、高可用性、高性能なオープンソースの調整と一貫したサービスのために設計されたアプリケーションであり、Googleのチャビーのオープンソース実装です。
これは、機能を提供します。
- ネームサービス
- 構成管理
- クラスタ管理
- 分散ロック
- キュー管理
特長:
- シーケンシャル一貫性:同じクライアントから発信トランザクション要求は、最終的には、のZooKeeperに適用するための発売に合わせて厳密になります。
- 原子性:要求はすべてのマシン上のクラスタアプリケーションにつながるすべてのトランザクションが同じで、クラスタ全体を言っているか、すべてのクラスタがクラスタで正常に特定の取引に適用されているか、適用されない、機械の特定の部分は表示されません。例別の部分には、トランザクションの適用適用し、そしてません。
- シングルビュー:クライアント接続のZooKeeperサーバーは、サーバー側のデータが同じであるモデルを参照するに関係なく。
- 信頼性:別のトランザクションが存在しない限り成功した取引に適用され、サーバ、およびクライアントに完全対応したら、その後、事務所のサーバの状態が変化によって引き起こされているが、保持され、それが変更されました。
- リアルタイム:通常の人々がリアルタイムで最初の反応を見るには、トランザクションが正常に適用されると、クライアントは、直ちに変更後の事務の状態に最新のデータをサーバーから読み取ることができるということです。これは、ZooKeeperのが唯一の一定の期間を保証することに留意すべきで、クライアントは最終的には、最新のデータ状態にサーバーから読み取ることができるようになります。
飼育係の役割
- リーダー(リーダー):同時に世論調査や解像度を担当し、システムステータスを更新し、ZooKeeperのクラスタのみリーダー、フォロワーや他の人が存在しますオブザーバーです。
- 学習者(学習):フォロワー(フォロワ)と観察者(観察者)を含みます。
- クライアント要求の結果を受け入れるためのフォロワーは、予備選挙の過程で投票するために、クライアントに返されます。
- オブザーバーは、クライアント接続、リーダーに転送書き込み要求を受け入れることができますが、観察者が投票プロセスに参加していない、唯一の同期状態のリーダーは、観測者の目的は、システムを拡張し、読み出し速度を向上させることです。
- クライアント(クライアント)、要求イニシエータ。
注:ZooKeeperのデフォルトのみリーダーとフォロワー二つの役割ではなく、オブザーバーの役割。例えば、観察者、:サーバオブザーバーパターン列追加のサーバー構成に構成されているpeerType =観察者、およびすべてのサーバ構成ファイル:Observerパターンを使用するために、コンフィギュレーションファイルオブザーバーの任意のノードに追加したいです。 1:localhostを:2888:3888:オブザーバー
フォロアとオブザーバーの違い:フォロワーとオブザーバーは、読み取りサービスを提供することができ、書き込みサービスを提供することができません。両者の唯一の違いは、それは、リーダーオブザーバーが書き込み動作に参加しない、選挙プロセスのマシンに参加しないで、したがって、オブザーバーは、書き込みパフォーマンスに影響を与えない場合に、クラスタの読み取り性能を向上させることができ、戦略「成功の半分以上書きました」。
飼育係のアーキテクチャ
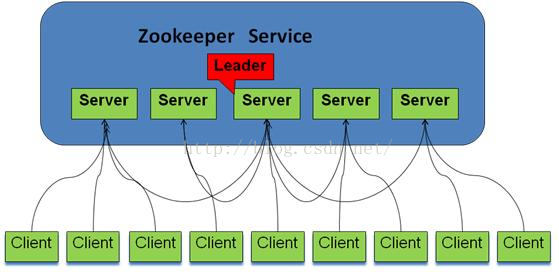
飼育係は、リーダーからなる複数のサービス(ノード)のクラスタ、従動複数の各サーバ部分のデータの一片、読み出し及び書き込み分散一貫したグローバル・データ、クライアント・リーダー実施形態によって転送された更新要求です。
彼らは、クライアントがどのサーバーに接続されているかどうかをアトミックデータ更新、どちらかのデータ更新が成功または失敗し、データグローバルにユニークな試みを、順次送られて実行されるのと同じ順序を更新するために、クライアントからの要求を更新要求を注文して、データは、ビューと一致しています。
原子放送の飼育係コアは、このメカニズムのこのメカニズム性を保証同期プロトコルの実装は、各サーバ間ザブ契約.Zab契約は2つのモードがあり、それらは回復モードとブロードキャストモードであると呼ばれます。
(1)サービスの開始時やリーダーがクラッシュした後、ザブが選出され、状態同期のサーバと指導者の大半を完了したのリーダーシップは、リカバリモードが終わったとき、リカバリーモードに入った。同期状態保証リーダーとサーバが同じシステムの状態を持っています。
リーダーがされているとフォロワーのほとんどは、状態同期した後は(2)、彼は放送状態に、あること、ニュースを放送するために始めることができます。サーバは、リカバリモードで起動します飼育係のサービス、発行リーダーに追加され、このとき同期が終了するまで、それはまた、ブロードキャストメッセージに関与し、状態やリーダーを同期します。
ZooKeeperのデータモデルのznode
(1)ノードが
分散、一般的な「ノード」は、クラスターの各マシンの組成物を指します。znodeと呼ばれるデータモデル内のデータ単位、そのデータ手段でZooKeeperのノード。
(2)ZooKeeperのノード属性
これまでの説明により、本発明者らは、図1に示すように重要な特性の数は、ノードによって表される状態を有するそれ自体ことを理解することができます。
znodeノード属性構造:

(3)データモデル構造
ZooKeeperのメモリに格納されている全てのノードデータ、データモデルは、(ツリーのznode)ツリーで、スラッシュで割ったパス(/)のような/ HBaseの、のznodeである/マスター、前記のHBaseそして、すべてのznodeを習得。各のznodeは、コンテンツ上のデータが保存されます、そしてそれは、属性情報のシリーズを開催します。ZooKeeperのは、階層的な名前空間を有しており、図3.1に示すように、これは、標準のファイルシステムに非常に類似しています。
ZooKeeperのデータモデルとファイルシステムのディレクトリツリー:


(4)参照
よるZonde パス参照 Unixファイルパスとして、。彼らはスラッシュ文字でなければなりませんので、パスは、絶対にする必要があり冒頭に。加えて、彼らはこれらのパスを変更できないように、各パスのみ表現であることを意味し、一意である必要があります。ZooKeeper、Unicode文字列によってパス、およびいくつかの制限があります。そのようなキー割り当て量情報として、管理情報を保存するには、文字列「/飼育係」。
(5) のznode構造
ZooKeeper命名空间中的Znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。图中的每个节点称为一个Znode。 每个Znode由3部分组成:
① stat:此为状态信息, 描述该Znode的版本, 权限等信息
② data:与该Znode关联的数据
③ children:该Znode下的子节点
ZooKeeper虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以KB为大小单位。ZooKeeper的服务器和客户端都被设计为严格检查并限制每个Znode的数据大小至多1M,但常规使用中应该远小于此值。
(6) 数据访问
ZooKeeper中的每个节点存储的数据要被原子性的操作。也就是说读操作将获取与节点相关的所有数据,写操作也将替换掉节点的所有数据。另外,每一个节点都拥有自己的ACL(访问控制列表),这个列表规定了用户的权限,即限定了特定用户对目标节点可以执行的操作。
(7) 节点类型
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
① 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
② 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
(8) 顺序节点
当创建Znode的时候,用户可以请求在ZooKeeper的路径结尾添加一个递增的计数。这个计数对于此节点的父节点来说是唯一的,它的格式为"%10d"(10位数字,没有数值的数位用0补充,例如"0000000001")。当计数值大于232-1时,计数器将溢出。
(9) 观察
客户端可以在节点上设置watch,我们称之为监视器。当节点状态发生改变时(Znode的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次,这样可以减少网络流量。
ZooKeeper服务中操作
在ZooKeeper中有9个基本操作,如下图所示:
ZooKeeper类方法描述

更新ZooKeeper操作是有限制的。delete或setData必须明确要更新的Znode的版本号,我们可以调用exists找到。如果版本号不匹配,更新将会失败。
更新ZooKeeper操作是非阻塞式的。因此客户端如果失去了一个更新(由于另一个进程在同时更新这个Znode),他可以在不阻塞其他进程执行的情况下,选择重新尝试或进行其他操作。
尽管ZooKeeper可以被看做是一个文件系统,但是处于便利,摒弃了一些文件系统地操作原语。因为文件非常的小并且使整体读写的,所以不需要打开、关闭或是寻地的操作。
Watch触发器
(1) watch概述
ZooKeeper可以为所有的读操作设置watch,这些读操作包括:exists()、getChildren()及getData()。watch事件是一次性的触发器,当watch的对象状态发生改变时,将会触发此对象上watch所对应的事件。watch事件将被异步地发送给客户端,并且ZooKeeper为watch机制提供了有序的一致性保证。理论上,客户端接收watch事件的时间要快于其看到watch对象状态变化的时间。
(2) watch类型
ZooKeeper所管理的watch可以分为两类:
① 数据watch(data watches):getData和exists负责设置数据watch
② 孩子watch(child watches):getChildren负责设置孩子watch
我们可以通过操作返回的数据来设置不同的watch:
① getData和exists:返回关于节点的数据信息
② getChildren:返回孩子列表
因此
① 一个成功的setData操作将触发Znode的数据watch
② 一个成功的create操作将触发Znode的数据watch以及孩子watch
③ 一个成功的delete操作将触发Znode的数据watch以及孩子watch
(3) watch注册与处触发
图 6.1 watch设置操作及相应的触发器如图下图所示:

① exists操作上的watch,在被监视的Znode创建、删除或数据更新时被触发。
② getData操作上的watch,在被监视的Znode删除或数据更新时被触发。在被创建时不能被触发,因为只有Znode一定存在,getData操作才会成功。
③ getChildren操作上的watch,在被监视的Znode的子节点创建或删除,或是这个Znode自身被删除时被触发。可以通过查看watch事件类型来区分是Znode,还是他的子节点被删除:NodeDelete表示Znode被删除,NodeDeletedChanged表示子节点被删除。
Watch由客户端所连接的ZooKeeper服务器在本地维护,因此watch可以非常容易地设置、管理和分派。当客户端连接到一个新的服务器 时,任何的会话事件都将可能触发watch。另外,当从服务器断开连接的时候,watch将不会被接收。但是,当一个客户端重新建立连接的时候,任何先前 注册过的watch都会被重新注册。
(4) 需要注意的几点
Zookeeper的watch实际上要处理两类事件:
① 连接状态事件(type=None, path=null)
这类事件不需要注册,也不需要我们连续触发,我们只要处理就行了。
② 节点事件
节点的建立,删除,数据的修改。它是one time trigger,我们需要不停的注册触发,还可能发生事件丢失的情况。
上面2类事件都在Watch中处理,也就是重载的process(Event event)
节点事件的触发,通过函数exists,getData或getChildren来处理这类函数,有双重作用:
① 注册触发事件
② 函数本身的功能
函数的本身的功能又可以用异步的回调函数来实现,重载processResult()过程中处理函数本身的的功能。
Zookeeper下载安装与配置
Zookeeper下载安装
-
从ZooKeeper官网下载
下载地址:https://archive.apache.org/dist/zookeeper/ -
解压配置
tar -xf /usr/local/src/zookeeper-3.4.9.tar.gz -C /usr/local/src/ ln -sv /usr/local/src/zookeeper-3.4.9/ /usr/local/zookeeper cd /usr/local/zookeeper/
3.配置ZooKeeper
vim zoo.cfg
# zoo.cfg文件中内容如下 tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181
- tickTime 单位为微秒,用于session注册和客户端和ZooKeeper服务的心跳周期。session超时时长最小为 tickTime的两倍。
- dataDir ZooKeeper的状态存储位置,看名字就知道书数据目录。在你的系统中检查这个目录是否存在,如果不存在手动创建,并且给予可写权限。
- clientPort 客户端连接的端口。不同的服务器可以设置不同的监听端口,默认是2181。
4.启动ZooKeeper
# 这里命令写的长是为了便于知道ZooKeeper是如何使用配置文件的。
/usr/local/zookeeper/bin/zkServer.sh start /usr/local/zookeeper/conf/zoo.cfg
# 查看ZooKeeper是否运行
ps –ef | grep zookeeper
# 也可以使用jps ,可以看到java进程中有QuorumPeerMain列出来。
# 查看ZooKeeper的状态
zkServer.sh status
# 常用的ZooKeeper用法,这个属于Linux基础的部分,就不过多说明了
./zkServer.sh {start|start-foreground|stop|restart|status|upgrade|print-cmd}
5.使用zkCli连接ZooKeeper
/usr/local/zookeeper/bin/zkCli.sh -server localhost:2181
集群配置
1.创建配置文件
cd /usr/local/zookeeper touch zoo1.cfg zoo2.cfg zoo3.cfg

注意 端口不要冲突,dataDir不要相同。
2.配置数据目录与数据存放目录内容
cd /tmp/zookeeper
mkdir {zoo1,zoo2,zoo3}
echo 1 > zoo1/myid
echo 2 > zoo2/myid
echo 3 > zoo3/myid
注意:这里的myid文件中一定要对应上面配置文件中server.[id]的数字,不然ZooKeeper启动会出错。
3.启动Zookeeper
zkServer.sh start /usr/local/zookeeper/conf/zoo1.cfg zkServer.sh start /usr/local/zookeeper/conf/zoo2.cfg zkServer.sh start /usr/local/zookeeper/conf/zoo3.cfg
4.查看效果
使用ps -ef | grep zoo可以看到有三个zookeeper启动起来了。
连接ZooKeeper
# 192.168.8.250是ZooKeeper服务器的地址 zkCli.sh -server 192.168.8.250:2181,192.168.8.250:2182,192.168.8.250:2183
Zookeeper命令篇
- 连接远程Server:
zkCli.sh –server <ip>:<port>
比如连接到本地Zoopker服务:./zkCli.sh -server localhost:2181 - 查看节点数据:
ls <path>,比如ls / 则查看根目录节点数据 - 查看某个服务Service的提供者
ls 服务名/providers - 查看节点数据并能看到更新次数等数据:
ls2 <path>,输出字段含义如下:
cZxid:创建节点的事务id
ctime:创建节点的时间
mZxid:修改节点的事务id
mtime:修改节点的时间
pZxid:子节点列表最后一次修改的事务id。删除或添加子节点,不包含修改子节点的数据
cversion:子节点的版本号,删除或添加子节点,版本号会自增
dataVersion:节点数据版本号,数据写入操作,版本号会递增
aclVersion:节点ACL权限版本,权限写入操作,版本号会递增
ephemeralOwner:临时节点创建时的事务id,如果节点是永久节点,则它的值为0
dataLength:节点数据长度(单位:byte),中文占3个byte
numChildren:子节点数量 - 创建节点:
create <path> <data> - 获取节点,包含数据和更新次数等数据:
get <path> - 修改节点:
set <path> <data> - 删除节点:
delete <path>,如果有子节点存在则删除失败
笔记来源:
ZooKeeper学习第一期---Zookeeper简单介绍