エンドツーエンドのアスペクトに基づく評判分析のための対話型マルチタスク学習ネットワーク
簡単に
この記事では、小さなデータセットの問題として問題に対処するために、共有パラメータ文書コーパスの一部を訓練しながら、タスク、マルチタスクにアスペクト抽出及びアスペクトsenmetiment分類を統合することです。
概要
あなたが同時に共同関連のタスク、トークンレベル別のドキュメントレベルの両方でより多くを学ぶことができます。この記事のプレゼントインタラクティブなマルチタスク学習ネットワークインタラクティブなマルチタスク学習ネットワーク。唯一異なるタスクに共通の特徴を頼る伝統的なマルチタスク学習方法とは異なり、メッセージパッシングアーキテクチャのIMNの導入、情報の集合は、反復異なるタスク間で受け渡される潜在変数の他の国々と共有することができます。
良好な実験結果。
入門
従来の治療とのABSAの問題は二つの質問に分割され、パイプラインが行われ、そこにいくつかの合同訓練、合同訓練が、それらの方法、ちょうど接触2つのタスクが一緒に統一ラベルを通じてですが、各リンクは明らかではありません。また、唯一のクラスの側面コーパスから学習しますが、クラスや小規模コーパス、情報の無いその他の予期しない良いの使用は、そのようなドキュメントレベルの感情分析コーパスに関連するとして、感情に関連する言語学と便利な知識でコーパスの側面かつ容易に取得します。
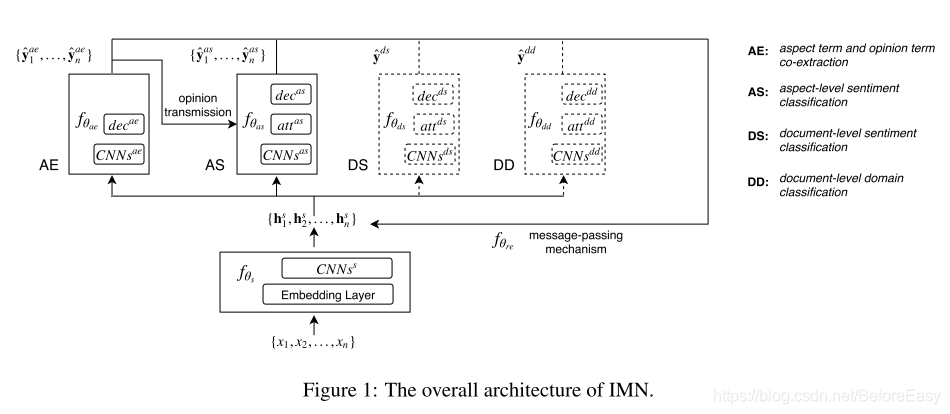
この記事では、AEおよびASに対応しつつ、IMNを説明し、2つのタスク間のリンクをより有効に活用。情報の大規模コーパスの使用で訓練を受けたAEおよびASレベルのタスクと文書は加えて、;また、比較的新しいメッセージングメカニズムを導入し、潜在的に有用な情報が異なるタスクから共有表現に送り返されます。そして、共有情報は、以降の処理の可能性を表現するために組み合わせられます。この反復プロセスは、反復回数の増加に伴って、行われ、情報が変更され、複数のリンクに分散することができます。マルチタスク学習はほとんどよりも、IMN共有特性が、また、メカニズム、明示的なモデリングタスクを渡すメッセージの間の相互作用によってできるだけでなく。
またIMNは、2つのドキュメントレベルの分類のタスクに統合:感情の分類(DS)とを一緒にフィールド(DD)、およびAE ASトレーニングによって分類。
関連研究
マルチタスク学習
従来のマルチタスク学習は、特徴空間と特徴空間2つのタスク固有を得るために、共有タスクの特定のネットワークと2つの共有ネットワークです。並列学習関連のタスクの共有意味表現を使用して、いくつかのケースでは、マルチタスク学習は、タスク間の相関関係を捕捉し、モデルの一般化を改善することができます。
しかし、従来のマルチタスク学習と明示的なモデリング作業の間には相関関係-相互作用だけミス、学習特性を介して2つの逆伝播タスク、およびこの相互作用は、制御可能ではありません。
IMNはなく、メッセージパッシング機構明示的なモデリングタスクの間の関係を介してだけでなく、共有表されます。
情報伝達機構
CVとNLPは、グラフィカルモデルの推論アルゴリズムのネットワーク表現をメッセージング研究されています。これらのメッセージは、ネットワーク・アーキテクチャを引き起こす可能性がありますリカレントニューラルネットワークのためのモデリングアルゴリズムを実行します。また、ネットワーク内の情報の普及で同様の研究を更新しているが、構造は、マルチタスク学習の問題を解決するために設計されています。各反復更新電位が同一のネットワーク構造によって表されるので、我々のアルゴリズムは、大まかに、RNN構造と呼ぶことができます。
提案された方法
図1に示した構造、入力トークンの集合であり、
特徴を抽出します。
CNNは、さらに、ワード単位に組み込まれた機能のいくつかの層で抽出します。
出力のこのレベルはされて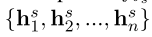
さまざまなタスク間で共有します。これは、次の情報が更新されるように、上の異なるタスクから伝播するために使用されることを示します。
このグループは、彼らが順番に異なるタスクを入力するために使用されることが示されました。各タスクは、出力成分の独自のセットを有し、それがタグ配列のセットです。AEのミッションでは、各単語のラベルの出力は、単語や単語の感情的な側面かどうかを示し; AS、スピーチワードのキャリブレーションの一部に。分類タスク、例のための出力および入力で、出力感情、DD出力ドメインをDS。各反復は、共有表現の組上記権利情報戻ります。情報は、特に、当該被験体、ASへAEから送信されたタスク情報を、様々なコンポーネントの間で伝送することができます。Tは、出力変数の予測を行うための情報の倍の伝送を反復の後。
3.1縦横レベルのタスク
AEは、5つのマークが、すべての側面との意見の単語を抽出したい: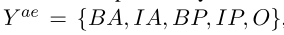 :、ASは、シーケンスラベリング問題、3個のタグである
:、ASは、シーケンスラベリング問題、3個のタグである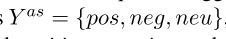 、唯一のアスペクト単語をマーク。例では、これは:
、唯一のアスペクト単語をマーク。例では、これは:


AS層に追加の自己注目があり、層AE出力層を得ることができる次のように、ASタスク番号抽出意見ワードAEを使用してその結果、特定の注意が計算される:
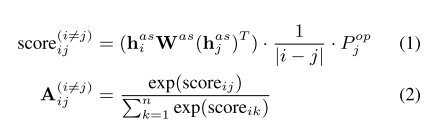
化学式1において、第1の要因は、二つの単語間のより大きなこの距離aより小さい第三項は、j個の意見ワードの確率がAEを加算することにより出力されることを示して両者間の相関の測度、第二距離、ですBP IP]タブを検索します。このように、AS AEは直接影響によって影響を受けます。
AEでは、ワードは埋め込み、i番目のトークンの最終的な表現として一緒にスプライスされた最初の共有タスクの特定を表します。
ASに、最終的な表現として共有表現と自己注目アップのスプライシングを示しました。各タスクは、前の確率ソフトマックス接続層の完全な計算を持っています。
ドキュメントレベルのタスク
为了解决aspect-level 训练数据不足的问题,IMN引入有情感信息的文档级别语料。引入两个文档级分类任务加入联合训练,分别是文档级情感分类和文档级领域分类。
两个都是多层CNN然后attention层 然后decode层,共享表示过了CNN之后,用softmax方式计算attention,最终得到加权和的表示过全连接和softmax
message passing mechanism
为了利用不同任务之间的交互,消息传递机制汇总了上一次迭代中不同任务的预测,并用这些信息来更新这次迭代中的共享表示。
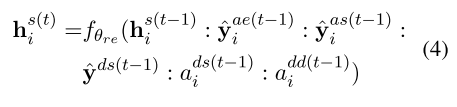
:表示拼接,f表示ReLu激活的全连接。a表示注意力之后的表示,与情感或领域相关度更高的词更可能成为opinion word或aspect word
learning
交替在aspect level 和document level上进行训练。在asoect-level:
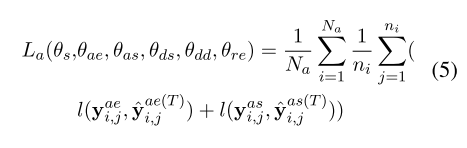
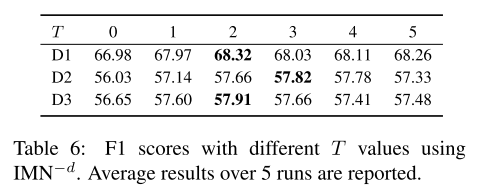
T 是迭代的最大次数,
表示aspect-levle训练数据总数,ni表示第i个训练实例中的token数,y表示的是各自标签的one-hot编码,l表示cross entropy loss。只考虑aspect term。
在document-level loss中:
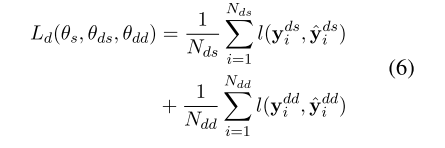
在训练document level时不需要用到message passing mechanism
首先用document-level数据预训练网络几轮,然后以比率r在aspect level和 document level交替训练。算法如下:
D表示训练数据

experiments
データ:Semeval2014 Semeval2015、ドキュメントレベルと二つのデータセット。
この部分は、実験パラメータのセットです。
分析の結果
結果を表3に示します。

ケーススタディの結果:
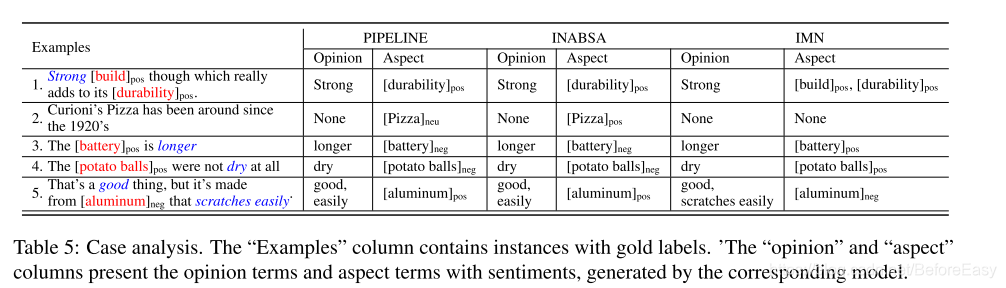
比較するには、ドキュメントレベルの発見情報の導入が有効です。
結論
彼はマルチタスク学習ネットワーク、共同訓練の抽出と分類側面と意見用語の感情的な側面を提案しました。IMNはまた、新しいメッセージパッシングメカニズムの導入、タスクのより良い使用の間のリンクを提案しました。加えて、ドキュメントレベルのデータの側面から貴重な情報を得るために、他のトレーニングデータから情報を得ることに焦点を当てました。また、このモデルでは、他の関連するタスクの数で使用することができます。
