記事のディレクトリ

アウトライン
ES中国は、最初の66フペルジン先生と学習継続します
コース住所:https://www.roncoo.com/view/55
無意味シャードクラスタの再起動時に再割り当て
クラスタの再起動では、いくつかの設定がある場合に、プロセスのシャードの回復に影響を与えます。
まず、我々は、デフォルトの設定、何が起こるかシャード回復プロセスを理解する必要があります。
私たちは10のノードを持っている場合は、各ノードがシャードを持って、プライマリー断片またはレプリカのシャードであってもよいし、インデックスを持っている、5つのプライマリー断片が存在し、各プライマリー断片は、レプリカのシャードを持っています。
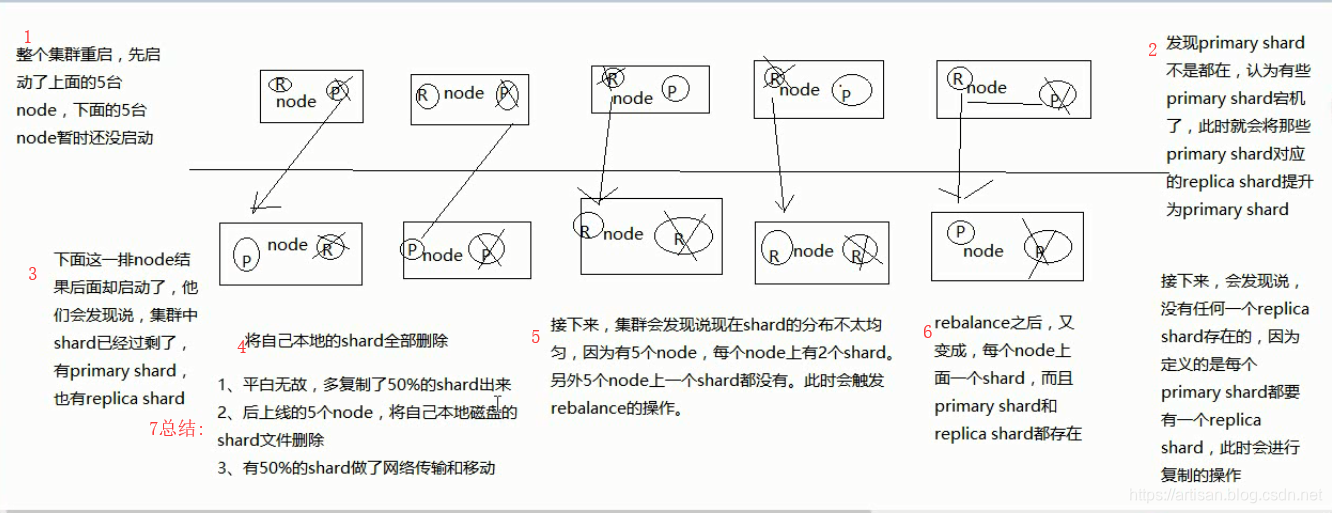
私たちは、このようなディスクのようなものに新しいマシンを設置するなど、いくつかのメンテナンス操作は、クラスタ全体をシャットダウンした場合。私たちは、クラスタノードが開始した後、間違いなく一つです再起動すると、5つのノードが最初に起動した後、残りの5つのノードが起動していないがあるかもしれません。
残りの5つのノードが開始する時間を持っていなかった、または何らかの理由で遅れているので、おそらくそれは、要するに、何らかの理由で、唯一の5つのノードがオンラインになっている今です。この5つのノードは、ゴシッププロトコル、マスターの選挙を介して相互に通信し、次にクラスタを構成するであろう。彼らは起動しない5つのノードが存在するため、そのノード5上のシャードは、クラスタは、シャードの半分以下で、利用できない、データが均一に分散されていないことがわかります。このオンライン5ノードでは、各プライマリー断片のための適切な複製シャードコピーしながら、部分レプリカのシャードは、プライマリー断片に昇格送信します。
最後に、残りの5つのノードがクラスタに追加することができます。しかし、これらのノードは、彼らがシャードを再度コピーして置い5ノードにする前に、この時間は、彼らはあなたのローカルデータが削除されますされています開催発見されている可能性があります。その後、クラスタは、リバランスの動作破片、均等に5ノードまでの後に開始するノードに配布さ5つのシャードの最も早い開始を開始します。
プロセス、これらの再シャードのコピー、移動、削除、移動、再プロセスでは、ディスクおよびネットワークリソースを大量に消費します。データクラスタの膨大な量のために、クラスタは、長い時間がかかりますクラスタの起動につながる可能性、TBレベルのデータを移動する理由はありません、毎回再起動する可能性があります。しかし、すべてのノードがクラスタ全体のすべてのノードを待つことができるかどうかは、すべてのデータは、その後、あなたがシャードをコピーして移動するかどうかを決定した後、状況は非常に良いだろう、後で行に完全にあります。
シャード回復配置
だから今、私たちはその後、我々はこの問題を解決するために、いくつかの設定を行うことができ、問題を知っています。
まず、我々はパラメータを設定する必要がありますgateway.recover_after_nodes: 8。
このパラメータの後シャードの回復のプロセスを開始し、その後、ES十分なノードがあるまでは、ライン上にあることができる、と。このパラメータは特定のクラスタに関連付けられているので、我々のクラスタ・ノードの数に応じて決定されます。
また、あなたはまた、少なくともこれらのノードの待機時間を持っている必要があり、クラスタ内のノードの数を設定する必要がありますgateway.expected_nodes: 10,gateway.recover_after_time: 5m。
上記設定後、動作は、クラスタES以下となり、その後5分まで待って、オンラインの少なくとも8つのノードを待つ、または10個のノードシャードの回復のプロセスを開始し、オンラインです。
ノードが開始の数が少ないが、それはすぐにシャード回復を開始したときにこれが回避でき、でもシャード回復プロセスは、数時間から数分に短縮することができ、ディスクおよびネットワークリソースを大量に消費します。
