展開MongoDBのレプリケーションセット(レプリカセット)
環境
オペレーティングシステム:Ubuntuの18.04
MongoDBの:4.0.3
サーバー
3台のサーバがノード2から、第一マスタノード1を展開+

3台のコンテンツサーバのIPは以下のとおりです。
10.140.0.5(マスターノード)
10.140.0.6(ノード01から)
10.140.0.7(ノード02から)
MongoDBのをインストールします。
次に、各サーバー上にMongoDBをインストールする必要があります。
インストールプロセスが参照できる完全な
公式ドキュメント
。
便宜上、この記事では提供して
ワンクリックでMongoDBのためのスクリプトをインストールします
。
rootユーザーに切り替え
sudoのSU -
インストールスクリプトを実行します
wgetのhttps://gitlab.com/caizhifei2003/scripts/raw/master/install/mongodb/ubuntu-1804.sh ます。chmod uの+ X ubuntu-1804.sh ./ubuntu-1804.sh
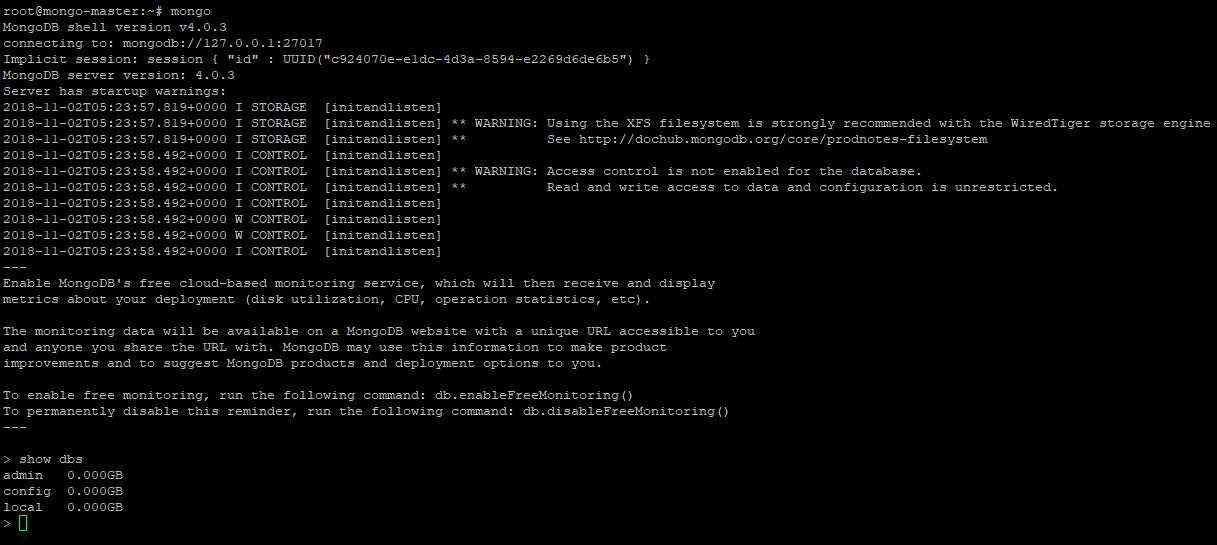
この時点で、あなたはモンゴデータベースでコマンドを入力することができます
設定の複製セット
セットレプリケーションセット名
レプリケーションセットの名前を設定するには2つの方法があります。一つはのmongodコマンドであり、もう一方は、設定ファイルを変更することです。
複製セット名を設定する設定ファイルの方法を変更することにより、本明細書で使用される場合、各ノードは、データベースを起動するために、同じ構成を使用して再起動することができることを確認してください。
MongoDBはUbuntuの上の設定ファイルを開きます
vimの/etc/mongod.conf
レプリケーションの構成セクションを探します
レプリケーション:
replSetName: "RS0"
MongoDBののIPアドレスのバインド
ネット構成セクションを探します
ネット:
ポート:27017
bindIp:localhostを、10.140.0.5
これは、マスタのアドレス、バインドに対応するスレーブノードであります
10.140.0.6
10.140.0.7
ファイルを保存し、サービスのmongodを再起動します
サービスのmongod再起動
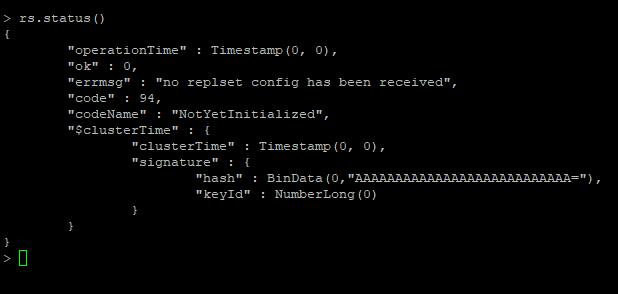
この場合、任意のノードに入ります。ビュー・レプリケーションの設定状態。
初期レプリケーションセット
Mongoのシェルによってデータベースにマスタ・ノード
初期化を実行するコマンドセットをコピーします

rs.initiate({
_id: "RS0"、
メンバー:[
{_id:0、ホスト: "10.140.0.5:27017"}、
{_id:1、ホスト: "10.140.0.6:27017"}、
{_id:2 、ホスト: "10.140.0.7:27017"}
]
})
ビュー・レプリケーションの設定状態
rs.status()
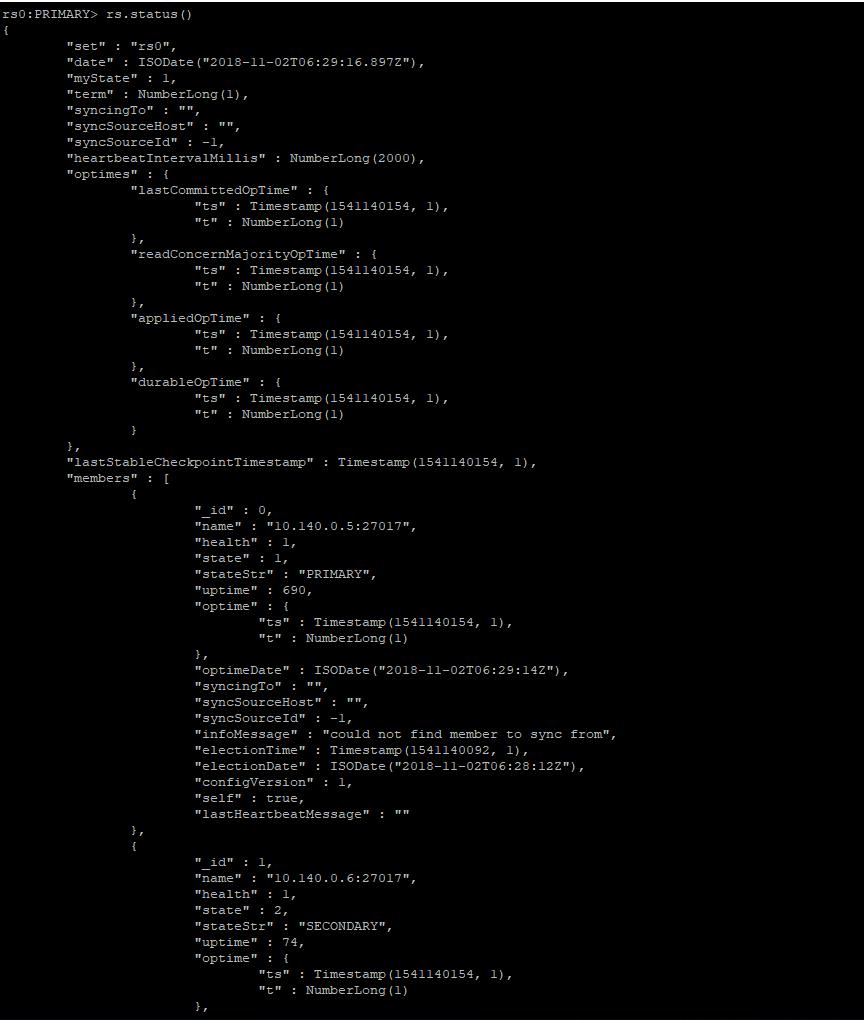
これは、セットが正常に作成されたコピー。
テストデータの同期
次のコマンドを実行して、プライマリノード上のデータを挿入
use test
db.test.insertOne({"name": "kenny"})
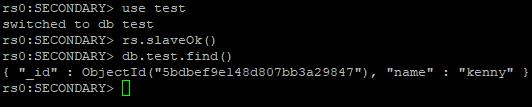
进入任何一个从节点,查看数据是否被同步。
use test rs.slaveOk() db.test.find()
默认情况下,MongoDB只允许在主节点上写入和读取数据。这里的rs.slaveOk()是为了在从节点上也读取数据而需要执行的session(如果退出mongo shell,需要重新执行该命令)级别的命令。
显示的内容如下:
测试重新选举主节点
在3个节点上分别使用rs.isMaster()命令
10.140.0.5:
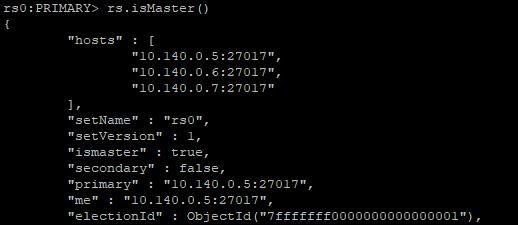
10.140.0.6:
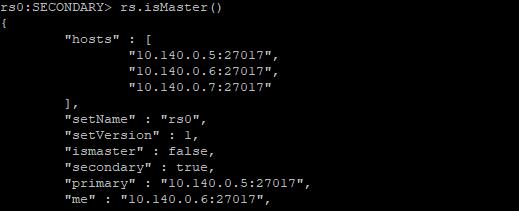
10.140.0.7
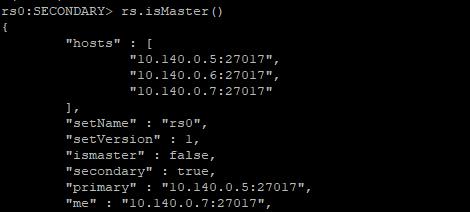
强制关闭主节点上的MongoDB服务
use admin db.shutdownServer()
在两个从节点上,通过rs.isMaster()命令查看状态
10.140.0.6:
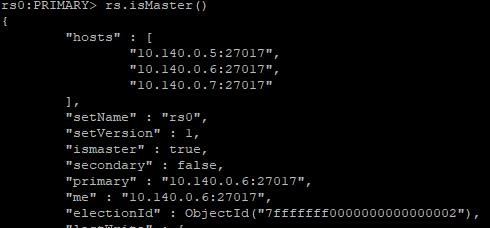
10.140.0.7:
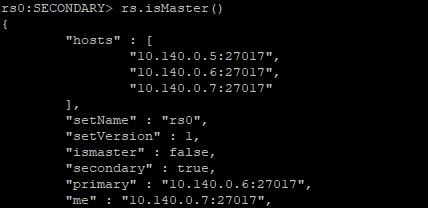
从上面的运行结果可以看出,10.140.0.6已经被推选成新的主节点。此时所有服务一切正常。
至此,部署MongoDB复制集的基本操作已经完成。
总结
MongoDB复制集的部署还是比较简单的,
官方文档也给出了较为详细的说明。
同任何其它数据库一样,MongoDB的副本集也是为了增强数据的安全性,避免因为服务器出现异常时,而导致数据服务不可用的情况出现。同时,数据被完整的保存在多个节点中,任何一台服务器的硬盘出现问题,都不会丢失数据。但是这里也存在风险,那就是数据同步存在时间差,如果还没有等到数据被同步到从节点,主节点就当机的话,那么这部分数据是无法找回的。
官方建议的副本集节点数量是3个,1个主节点+2个从节点。或者是1个主节点+1个从节点+1个仲裁节点。仲裁节点的作用是在主节点不可用时,通过算法找到最适合的从节点成为新的主节点。不建议将仲裁节点和数据节点放在同一个服务器上。
环境
操作系统:Ubuntu 18.04
MongoDB: 4.0.3
服务器
首先部署3台服务器,1台主节点 + 2台从节点
3台服务器的内容ip分别是:
10.140.0.5 (主节点)
10.140.0.6 (从节点01)
10.140.0.7 (从节点02)
安装MongoDB
接下来,需要在每一台服务器上安装MongoDB。
完整安装过程可参考
官方文档。
为了方便,本文提供
MongoDB的一键安装脚本。
切换成root用户
sudo su -
运行安装脚本
wget https://gitlab.com/caizhifei2003/scripts/raw/master/install/mongodb/ubuntu-1804.sh chmod u+x ubuntu-1804.sh ./ubuntu-1804.sh
此时,可以通过mongo命令进入数据库
配置复制集
设置复制集名称
有两种方式来设置复制集的名称。一种是通过mongod命令,另一种是通过修改配置文件。
本文使用通过修改配置文件的方式来设置复制集名称,确保每次节点重新启动后能够使用相同的配置启动数据库。
打开MongoDB在Ubuntu上的配置文件
vim /etc/mongod.conf
找到replication配置节
replication:
replSetName: "rs0"
绑定MongoDB的IP地址
找到net配置节
net:
port: 27017
bindIp: localhost,10.140.0.5
这里是主节点的地址,相应的从节点要绑定
10.140.0.6
10.140.0.7
保存文件,重新启动mongod服务
service mongod restart
此时,进入到任何一个节点。查看复制集状态。
初始化复制集
通过mongo shell进入主节点的数据库
执行复制集初始化命令
rs.initiate( {
_id : "rs0",
members: [
{ _id: 0, host: "10.140.0.5:27017" },
{ _id: 1, host: "10.140.0.6:27017" },
{ _id: 2, host: "10.140.0.7:27017" }
]
})
查看复制集状态
rs.status()
到此,复制集已经创建成功。
测试数据同步
执行如下命令,在主节点上插入一条数据
use test
db.test.insertOne({"name": "kenny"})
进入任何一个从节点,查看数据是否被同步。
use test rs.slaveOk() db.test.find()
默认情况下,MongoDB只允许在主节点上写入和读取数据。这里的rs.slaveOk()是为了在从节点上也读取数据而需要执行的session(如果退出mongo shell,需要重新执行该命令)级别的命令。
显示的内容如下:
测试重新选举主节点
在3个节点上分别使用rs.isMaster()命令
10.140.0.5:
10.140.0.6:
10.140.0.7
强制关闭主节点上的MongoDB服务
use admin db.shutdownServer()
在两个从节点上,通过rs.isMaster()命令查看状态
10.140.0.6:
10.140.0.7:
从上面的运行结果可以看出,10.140.0.6已经被推选成新的主节点。此时所有服务一切正常。
至此,部署MongoDB复制集的基本操作已经完成。
总结
MongoDB复制集的部署还是比较简单的,
官方文档也给出了较为详细的说明。
同任何其它数据库一样,MongoDB的副本集也是为了增强数据的安全性,避免因为服务器出现异常时,而导致数据服务不可用的情况出现。同时,数据被完整的保存在多个节点中,任何一台服务器的硬盘出现问题,都不会丢失数据。但是这里也存在风险,那就是数据同步存在时间差,如果还没有等到数据被同步到从节点,主节点就当机的话,那么这部分数据是无法找回的。
官方建议的副本集节点数量是3个,1个主节点+2个从节点。或者是1个主节点+1个从节点+1个仲裁节点。仲裁节点的作用是在主节点不可用时,通过算法找到最适合的从节点成为新的主节点。不建议将仲裁节点和数据节点放在同一个服务器上。