まず、プライマー
システムの開発では、多くの場合、このようなすべての変更の記録として、テーブル内の取引システムの合計数を行の数を計算する必要があるかもしれません。あなたが考えるかもしれない。この時、T声明からSELECT COUNT(*)は、まだ解決されていませんか?
しかし、より多くのシステムに記録されているあなたは番号を見つけるだろう、この文は、より多くのゆっくりを実行する必要があります。そして、あなたが望むかもしれませんが、MySQLのどのような愚かなああは、合計が覚えて、あなたが直接読み出す際にチェックしたいたびに、それが好きではありません。
だから、今日は、私たちが最後にCOUNT(*)の文について話をする必要が実現する方法である、そしてなぜMySQLは達成すること。そのようなアプリケーションがある場合、私は再びあなたに話しましょう、頻繁な変更と需要統計行数、業務要求する
デザインを行うことができますどのようにします。
二、COUNT(*)の実装
あなたは様々なMySQLエンジン、COUNT(*)で異なる実装を持っていることを最初にクリアする必要があります
1、MyISAMテーブルものの数(*)すぐに、しかし、トランザクションをサポートしていません。
- MyISAMエンジンは、テーブル内の行の数は、ディスク上に存在するので、実行回数(*)は、直接、高効率の数が返されたときに、
- それが実行されたInnoDBエンジントラブル、COUNT(*)は、内部のエンジンからのデータを1行ずつ読み込む必要があり、その後、累積数。
私たちは、この記事で説明したことに留意すべき条件は、その後、MyISAMテーブルもそう速く返すことができない場所を追加した場合、何のフィルタ条件数(*)は、ありません。
あなたはInnoDBのを使いたい理由かどうかトランザクションのサポート、並行処理やデータセキュリティに、InnoDBはMyISAMテーブルよりも優れているので、前回の記事で、私たちは、一緒に分析します。私はあなたのInnoDBでテーブルでなければならないと思い
エンジン。これは、テーブル内の行の合計数を計算するレコードの数がますます遅くなりますとき、なぜ、より多くのです。
2、正確なのにすぐに戻るには、テーブルのstatusコマンドを示すが、ありません。
あなたがショーのテーブルのstatusコマンドを使用した場合は、そのコマンドの出力を見つけるとTABLE_ROWSがあったテーブルの現在の行数を表示するために使用される、コマンドは非常に迅速に実行し、その後、この
TABLE_ROWSは、count(*)を行うに置き換えることができますか?
あなたは時々間違ったインデックスを選ぶだろう、なぜ10日の記事」MySQLを覚えているかもしれ?「私は前に述べたように、インデックス値を推定するために、統計的サンプリングによって決定されます。以下のため実際には、このサンプリングからTABLE_ROWSは、来ると推定され
、このことは許可されていません。どのように行うことを許可されていない、公式ドキュメントのエラーは、40%〜50%に達する可能性が言いました。したがって、行の数はtablestatusコマンド表示を直接使用することができない示します。
3、InnoDBのテーブル直接COUNT(*)は正確なのに、テーブル全体を横断しますが、パフォーマンス上の問題を引き起こす可能性があります
なぜないInnoDBはMyISAMのと同じではなく、数字、それを維持するには?
これはあっても、同時に複数のクエリは、マルチバージョン同時実行制御(MVCC)の理由から、InnoDBのテーブルは、「行数を返すべきである」ためでも不明です。ここでは例として、私がするあなたのための数値のカウント(*)を使用
について説明します。
表tは私たちが3つの同時ユーザセッションを設計している、今10,000レコードがあると仮定されます。
私たちは、それが年代順に上から下に実行されたと仮定し、同時に同じ行は、ステートメントが実行されます。
MyISAMエンジンは、テーブル内の行の数は、ディスク上に存在するので、実行回数(*)は、直接、高効率の数が返されたときに、
それが実行されたInnoDBエンジントラブル、COUNT(*)は、内部のエンジンからのデータを1行ずつ読み込む必要があり、その後、累積数。
- 最初のセッションは、トランザクションを開始し、テーブルの行数を問い合わせます。
- Bは、トランザクションセッションを開始し、行が挿入された後、テーブル内の行のクエリ数。
- セッションCは、別々のステートメントを開始するルックアップテーブル内の行の行番号を挿入します。

1つのセッションA、B、Cの実行フロー
あなたは3つのセッションA、B、Cはまた、テーブルtの行数を照会しますが、結果は違っていた取得するには、最後の瞬間にそれが表示されます。
関係のデザインのInnoDBとトランザクションは、それがコードに達成するMVCCあるマルチバージョン同時実行制御、によるものである、デフォルト反復可能読み取り分離レベルです。各行のレコードがあるため、彼らは、この会話に見られるべきであるかどうかを判断するために
、InnoDBのデータのカウント(*)要求のため、これはラインの裁判官によって順次ラインを読まなければならなかった、唯一の目に見えるライン「には、この問い合わせに基づいて、」計算するのに使用することができますテーブル内の行数。
注:私はあなたが変更を見ることができない理由:あなたはMVCCのメモリをぼかした場合は、その後のDir 3の記事」トランザクションの分離を確認することができますか?「そして8記事」最終的には業務が分離または単離されていませんか?「関連するコンテンツで。
もちろん、この一見単純な志向のMySQL、実行回数(*)の操作や最適化を行います。
あなたが知っている、InnoDBは索引構成表で、主キーインデックスツリーのリーフノードは、一般的なインデックスツリーのリーフノードは、主キーがある一方で、データです。そのため、一般的なインデックスツリーは、主キーインデックスツリーよりもはるかに小さいです。このような動作回数(*)のために、トラバース
率が同じ木であるの論理的結果を表示します。そのため、MySQLのオプティマイザは、最小の木が横断するでしょう。スキャンしたデータの量を最小限に抑え、正しいロジックを確保する前提の下では、データベース・システムは、普遍的法則の設計です。
ここでは簡単に要約します:
- MyISAMテーブル数(*)はすぐに、それはトランザクションをサポートしていませんが。
- [テーブルのstatusコマンドは、すぐに返すようにがなく、正確ではありません。
- InnoDBテーブルの直接COUNT(*)は正確なのに、テーブル全体を横断しますが、パフォーマンス上の問題を引き起こす可能性があります。
だから、戻って記事の冒頭の問題に、あなたが今のページを持っている場合、多くの場合、最終的には、オペレーティング・レコード取引システムの総数が、それを行う方法をする必要があります表示?答えは、我々は唯一の数を所有することができ、あります。
次に、我々はそれを議論し、それぞれの方法の長所と短所は何を持っているものを、独自の集計方法と同様に、参照してください。
ここで、私はこれらのメソッドの基本的な考え方についてあなたにお話しましょう:あなたは自分で入金の操作テーブルの行数を記録する場所を見つける必要があります。
キャッシュシステムによって格納された第三に、数
更新が頻繁にライブラリがあるためには、キャッシュシステムとの最初の時間は、サポートすることだと思うかもしれません。
あなたは、テーブルの行数を節約するためにRedisのサービスを使用することができます。1つのカウントRedisのインクリメントされる挿入された各表の行は、各行はRedisのカウントがデクリメントされ削除されます。このように、読み取りと更新操作を非常に迅速に、しかし、あなたはそれについてこのように考えて問題がありますか?
はい、キャッシュシステムの更新が失われる可能性があります。
Redisのデータは、この値を置く場所を見つけるだろうので、メモリ内に恒久的に保存されたままに定期的に永続的であることはできません。しかし、そうであっても、あなたはまだアップデートが失われる可能性があります。単にデータテーブルに行を挿入した場合、Redisのメディエータを想像
しますが、この値はRedisのデータを格納したいの再起動がリードバック、そしてこれはちょうど1を追加した後も保存された値が、その後、Redisの異常な再起動、1を追加しましたカウント動作が失われました。
もちろん、これは可解です。例えば、異常再起動Redisの後、単一のカウント(*)実際の行数を取得し内部データベースを実行するために、この値は、その上にRedisのに書き戻されます。結局再起動し、多くの場合ではない
。この時に、全表スキャンのコストが起こる、または許容できます。
しかし、実際には、カウントはキャッシュシステムに保存されている方法は、だけでなく、更新の問題を失いました。でも、Redisの通常の操作、この不正確な値またはロジック。
あなたは、このようなページがあることを想像することができ、運転レコードの合計数も100を表示しながら最新の操作を記録し、表示します。その後、カウントのRedisを削除し、データを記録するデータテーブルを取得するために最初に必要になります論理ページ。
私たちはとても不正確な定義は以下のとおりです。
、新たにRedisのプラス1にカウントされない、レコードを挿入した行100で見出された結果、
前記他の行100の結果に見られるが全く新しく挿入されたレコードがない、とのRedisカウントはすでに1を加えました。
どちらの場合も、論理が矛盾しています。我々は、このタイミング図を見てみましょう。
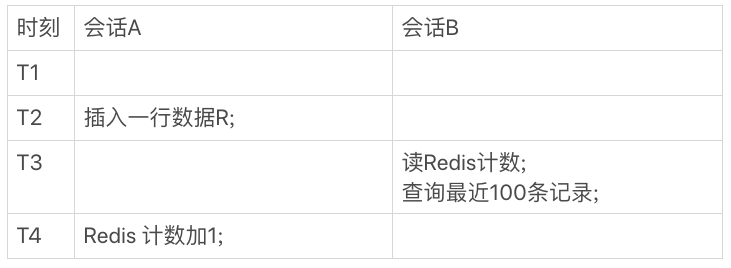
2つのセッションA、B図実行タイミングで
図2において、セッションは、論理トランザクションレコードがテーブルデータRに行を挿入し、挿入され、その後、カウントがインクリメントされRedisの、ページが表示されたときにBセッション問合せデータが必要とされます。
時間T3 Bでセッションを照会する場合には、図2で、このシーケンスでは、新たに挿入されたレコードRが表示されますが、Redisのカウントがインクリメントされません。この時点で、我々は一貫性のないデータについて話します。
あなたは私たちが新しいレコードロジックを実行すると、データテーブルを作成することですので、これはある、と言う、その後、Redisの数を変更します。読み出しは、Redisのを読んで、データテーブルを読み取ることがあるときには、この順序が逆になります。だから、あなたが同じ順序を維持した場合
、その後、何の問題ではありませんか?我々は結果を見て、変更のセッション今更新の順です。
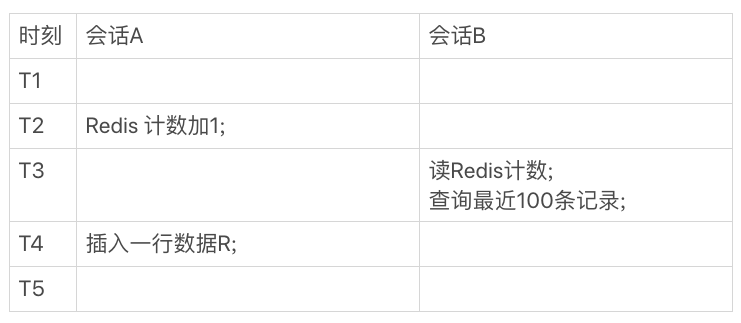
図3の調整シーケンスの後、セッションのA、図実行タイミングのB
あなたは、この時間というターン、時間T3のクエリでセッションBを、見つけるRedisのカウントが1増加するだけでなく、このライン、また、データの不整合を新たに挿入されたRを見つけることです。
これは並行システムにおいて、我々は正確に実行のタイミング異なるスレッドを制御することはできません、図の動作のそのような配列が存在するからである。したがって、我々は不正確Redisの通常の動作と言っても、このカウント値はロジックです。
第四に、データベースに保存された回数
上記の分析によると、不正確な数のキャッシュ・ストレージ・システムとデータ損失の問題を数えます。我々は表Cで別々のカウントには、データベースに直接このカウントを置くのであれば、その後、何が起こるのだろうか?
まず、それが失われたクラッシュの問題を解決し、InnoDBはデータを失うことはありませんクラッシュ回復をサポートすることです。
注意:InnoDBのクラッシュ復旧のために、あなたは、第二の記事、「ログシステムを再検討可能性がありますどのようにSQL文を更新するために実行されますか?「関連するコンテンツで。
私たちは、不正確な数の問題を解決することができるならば、我々が表示されます。
あなたはこれがあなたと同じではないことを言うのだろうか?図の操作に過ぎない。Redisの3、表Cのカウント動作に 3限り、この実行シーケンスがありますように、この問題は右、何の解決策ではありませんか?
問題は本当に解決策ではありません。
私たちは、クエリが直接形成返したときに、直接、その後まで保存し、そして、この記事で問題を解決したいInnoDBはInnoDBテーブルで、その結果、トランザクションをサポートによるものである(*)カウントすることはできません。
息子の息子を攻撃する、いわゆるシールド槍、そして今、私たちは「取引」この機能を使用し、問題が解決されます。

図4セッションA、Bの図実行タイミング
私たちは今、結果を見てください。読み取り操作セッションBはT3で実行され続けますが、カウントはセッションBのために、この操作を増分するように、この時点ため、更新トランザクションは、提出されていないが表示されません。
したがって、結果はセッションBに見られ、そして「最後の100のレコードは」結果を参照してくださいカウント値をチェックし、論理的に一貫しています。
ファイブ異なる使用回数
前の記事、コメントエリア、一部の学生にメッセージを残すとに尋ねた:(?)SELECT COUNTでは内部このような問合せトンから、COUNT(*)、(フィールド)、(主キーID)をカウント数えると、(1)およびその他のさまざまな使用を数えますパフォーマンス、どのような違い
ません。今日は私が詳細にあなたに、使用これらのタイプの間のパフォーマンスの違いを説明するために、この機会を利用したいと思い、COUNT(*)のパフォーマンスの問題を話しました。
以下の議論は、InnoDBエンジンに基づいていることに注意してください。
ここでは、まずあなたは、count()のセマンティクスを把握する必要があります。カウント()カウント関数のパラメータがNULLでないかどうかを判断する行ずつ、重合の関数、返された結果セットであり、累積値を1つ、または含まないことにより増加されます。最後に、累積戻り値。
したがって、(プライマリ・キーID)をカウントし、カウント、(*)カウント行の数で表されている設定された基準を満たすために、返された(1)、数(フィールド)、パラメータ「フィールド」の内部状態データ行を返すしNULLの合計数。
パフォーマンスの差の時間分析として、あなたは、いくつかの原則を思い出すことができます。
- 何かを与えるために何1.サーバー層と、
- 唯一必要な値に2のInnoDB。
- 3.オプティマイザは行いません。他の「明白な」最適化「の行番号を取る」の意味として、COUNT(*)を最適化。
それは何を意味するのでしょうか?次に、我々は見て一つ一つを取ります。
、InnoDBエンジンは、テーブル全体を横断するのカウント(プライマリ・キーID)のために、それぞれの行のID値は、取り出されるサーバ層に戻されます。サーバー層IDを取得し、判決は、蓄積された行は空になることはほとんどありません。
カウントのために(1)値は、テーブル全体トラバースInnoDBエンジンである、ではありません。各行は、サーバ層を返さに番号「1」を置くために、決意を蓄積行を空にすることは不可能です。
ただ、これらの2つの使用の違いを見て、あなたは速い(1)を実行したよりも数(主キーID)をカウントし、それを比較することができます。復帰動作IDが解析されたデータライン、およびコピーエンジンからのフィールド値を伴うため。
数(フィールド)の場合です:
- 1「フィールドが」NOT NULLとして定義されている場合、その行によってこの行が内部記録フィールドから読み出し、累積行、ヌルいないと判定されました。
- 2.「フィールドは」時間の後、実装、ヌルを許可するように定義されている場合、裁判官はヌルかもしれませんが、また再び取り出される値を決定するために、ヌル蓄積していないだけ。
第一原理の目の前にある、サーバー層がどのような分野、InnoDBはどのようなフィールドを返します。
COUNT(*)は例外で
しかし、COUNT(*)は例外で、フィールド全体が値を取り出しますが、特に最適化ではなく、されるわけではありません。(*)カウント確かにnullではありませんが、行が蓄積されます。
ここを参照してください、あなたはオプティマイザが理由ではないに対処するために、カウント(*)に基づいて、どのように簡単な最適化ああ、主キーIDは確かにああ空ではない、それについて自分で決めることができない、と言うだろう。
もちろん、MySQLはこの文のために最適化され、またではありません。しかし、あまりにも多くの場合は、これは、特殊な最適化が必要であり、MySQLが(*)カウント最適化されており、そして、あなたはそれでこの使用法を使用しています。
だから、結論は次のとおりです。ソート効率は、その後、<数(1)≈count(*)<数(主キーID)(フィールド)カウントので、私はあなたがCOUNT(*)を使用しようと示唆しています。
VIの概要
今日では、あなたと私は、MySQLでおしゃべりテーブルの行数を取得するには、2つの方法があります。私たちは、COUNT(*)実装は同じではありませんが、また、キャッシュ・メモリ・システムの問題のカウント値で問題を分析異なるエンジンに言及しました。
実際には、正確で一貫性のあるビューを取得することはできません、分散トランザクションをサポートしていません、このシステムは、2つの異なるストレージで構成され、内部のRedisを頼り、およびMySQLが集計表データ、正確で一貫性のある理由を保証することはできません。カウントしながら
値も一貫したビューの問題を解決するために、MySQLの中に置かれています。
InnoDBエンジンのサポートサービスは、我々は、トランザクションの原子性およびアイソレーションを生かすには、ビジネス開発のロジックを簡素化することができます。また、これはInnoDBエンジンが好まれる理由の一つです。
最後に、我々は、今日の質問時間に向けます。
ただ議論方式では、我々は正確なカウントを保証するためにトランザクションを使用していました。トランザクションは、中間結果は、このようにカウント値の順序を変更し、別のトランザクションを読み取ることができないことを保証して挿入することがあるので、新しいレコードは、ロジックの結果には影響を与えません。しかし、並行システムの
システムのパフォーマンスに関する考慮事項の視点は、あなたは操作が最初に記録を挿入する必要があり、このトランザクションシーケンスに思います、またはあなたは、カウントテーブルを更新する必要がありますか?
私は記事の最後に次の参照で私の答えを与える、コメント欄に書かれた自分の考えやアイデアを置くことができます。聴いてくれてありがとう、あなたは一緒に読むためにもっとたくさんの友達にこの共有を送るために歓迎されています。
七、時間の問題
問題に関する私の代わりに大きなスペースを占有しますテーブルtエンジン= InnoDBのテーブルを変更するために使用したときにある左。
この記事のコメント欄内では、我々はテーブル自体には空がなく、例えば、単にテーブルを再構築するための操作を実施している、つまり、ポイントを言及しています。
ただ、実行の外に存在する場合にDDL、DMLの間に、この期間中にいくつかの新しい空を導入することができます。
@フライングは私達が記事に言わなかった、より深いメカニズムに言及しました。テーブルを再構築すると、InnoDBはテーブル全体を埋めないであろう、各ページは、1月16日以降の更新が残されています。これは、実際には、ない再建テーブルの後に
「最も」コンパクトです。
それは、このようなプロセスである場合:
1.表トン一度再構築;
2.いくつかのデータを挿入しますが、データが挿入され、予約された空間の一部を過ごした。
このような状況下では3、その後、テーブルtを再構築し、問題の現象が出現することがあり。
八、古典的なメッセージ
1、ケン
システム性能同時考慮の観点から、記録動作が最初に挿入されるべきで、その後カウントテーブルを更新します。
「ラインロック功罪における知識:ラインロックのパフォーマンスへの影響を軽減するためにどのように?「
更新回数テーブルの行には、トランザクション間のロック待機を最小限に抑えることができます更新し、それは競争、最初のインサートに来てロックしているため、同時実行の度を高めます。
著者の回答:
いくつかの学生はそう、あなたが最初のソースを示していると述べました
2は、本当にケースです
:I.は、どのようにこのカウントのMySQL + Redisのプログラム依頼する
1.トランザクション(トランザクション・プログラム)
データを挿入2.MySQL
Redisの更新カウント3個の原子を
更新更新がRedisのは、トランザクションをロールバックに失敗した場合の成功のRedisは、トランザクションをコミットしている場合4.。
二、.NETとJavaプログラムのトランザクションのコードと取引MySQLの関係はどのようなものです、何の関連性?
著者の回答:
1.良い質問は、まだ我々は一貫性について話している問題を解決していません。その3〜4であるあなたは、論理セッションBを挿入した場合
、私はそれが(実行開始)トランザクションを開始推測2.不確実カザフスタン、すべてのフレームについて調べるませんでした、それの終わりに(実行がコミット)を提出