まず、今日の内容の要約
今日のテキストの開始前に、私が欲しいものを特別にいくつかの学生が高品質なコメントを残してコメントエリアを感謝します。記事についての知識の学生の人はの業務の可視性について質問上げ、その後、櫛を作っ@ユーザー名がある
質問が、トランザクションは、データの可視性への影響の提出後に開始します。@夏の雨の学生もこの問題に言及し、私は今日は説明を拡大する記事の最後に、トップレビューで答えました。@Justin @ニッケル大人と2人の
学生は2つの良い質問を提起しました。
より深い思考のための問題を引き起こす可能性があり、私はあなたの検索を容易にするため、名前に返信、「良い質問」の内容に書きます、あなたも行くと彼らのメッセージを見ることができます。
記事を見て、そんなにメッセージと非常に高品質のままに非常に慎重にありがとうございます。記事は私のために、みんなのためにいくつかの新しい理解をもたらすがいることを知っていることは大きな励みです。それと同時に、また、他の学生が真剣にコメント欄を見てすることができ、そこにある
自分自身のいくつかは認識していない発見する機会がなく、ある明確ではない知識は、一般的に列全体の品質を向上させることができます。ありがとうございました。
さて、戻って私たちのテキストコンテンツに今日。
ベース記事の前で、私は、インデックスの基本的な概念を紹介し、私はあなたがすでに一意のインデックスと一般的なインデックスの違いを知っていると信じています。一般的なインデックス、または一意のインデックスを選択する必要があります今日は、さまざまなビジネスシナリオで話を続けるだろうか?
あなたが公共のシステムを維持すると仮定し、それぞれの人が、固有のID番号を持っており、サービスコードは、2つのID番号を繰り返さないようにするために書かれています。人々は名前を確認するために、システムのID番号を追跡する必要がある場合、それは似て実行します
SQL文の種類を:
CUser id_cardは=「xxxxxxxyyyyyyzzzzz」から名前を選択します。
だから、あなたはid_cardフィールドにインデックスの構築を検討します。
ID番号フィールドが比較的大きいので、私はあなたが主キーとしてID番号を置くことはお勧めしませんので、今は2つの選択肢があり、どちらかのフィールドをid_cardする一意のインデックスを作成するには、いずれかの共通のインデックスを作成します。ビジネスはコードがされていることを確認していない場合は
IDカード番号を複製するために書かれ、これら2つのオプションのロジックが正しいです。
今、私はあなたがパフォーマンスの考慮事項の観点から、ある聞きしたい、あなたは、一意のインデックスまたは通常のインデックスそれを選ぶのか?それは、選択に基づいて何ですか?
簡単にするために、我々は、第4条「(オン)素人インデックス」フィールドkは繰り返されないと仮定した場合の値の例により説明されるものとします。

図1のInnoDBインデックス構造
次に、インデックス、クエリパフォーマンスへの影響ステートメントとUPDATE文の両方から分析するでしょう。
第二に、問い合わせ処理データ
仮定は、ステートメントは、クエリがTから選択ID K = 5で実行します 。このクエリの過程では、インデックスは、最初の根からのデータの右下隅にある、リーフノードへの層によってB +木、検索することから始め、木を見つけるために
、あなたはその後、二分法によってレコードを検索するために内部のデータ・ページを考慮することができるページ。
- 通常のインデックスがあるためにそれをk = 5の条件を満たしていない第一の記録に当たるまで、条件(5500)を満たす最初のレコードを見つけた後、あなたは、次のレコードを見つける必要があります。
- ユニーク索引の場合、索引定義一意ので、条件を満たしている最初のレコードを見つけた後、それは検索を中止します。
だから、これはどのくらい違うことだろうとの性能差をもたらしますか?答えは非常に少ないです。
あなたが知っている、InnoDBのデータを読み書きするために、ページ単位のデータに基づいています。レコードを読み取るために必要な時間は、このレコードは、ディスク自体アウトから読まれていない場合には、ですが、ページ単位で、全体がメモリに読み込まれました。では
InnoDBは、各データ・ページのデフォルトサイズは16キロバイトです。
エンジンは、ページによってページを読んされているので、それはのメモリ内のデータ・ページを持っているだろうというとき、そのようK = 5つのレコードは、見つけたとき。だから、平均的なインデックスのために、それは操作「次のレコードとの判断を見つけるために、」当時の多くを行う必要があり、我々は
唯一のポインタと1つの計算を見つける必要があります。
K = 5最後のレコードが正確にデータページ、レコードを削除するレコードである場合はもちろん、次のデータ・ページを読み取る必要があり、この操作は少し複雑になります。
我々はあまりにも確率を計算する前にしかし、整数フィールドに、データ・ページはほぼ千個の鍵を置くことができ、したがって、このような状況は低くなります。我々は平均的なパフォーマンスの差を計算した場合、現在のためにそう、それはまだ運用コストを考慮することができる
CPUは無視できます。
第三に、更新プロセスデータ
一般的なインデックスと、この質問の一意のインデックス更新文のパフォーマンスへの影響を説明するために、私はバッファを変更することを紹介する話をする必要があります。
あなたは、データ・ページを直接メモリに更新した場合、データ・ページを更新する必要があり、データ・ページが前提の下で、メモリ内のデータの一貫性に影響を与えずに、ケースされていない場合、InooDBは、これらのキャッシュされた変更が更新されます場合は
バッファを、あなたは、ディスクからデータページに読み込む必要がありませんように。クエリはデータ・ページにアクセスする必要がある次の時間は、データページがメモリに読み込まれてから、このページに関連する業務の変化バッファを実行しています。このように、
式は、データ論理の正しさを保証することができます。
名前が変更バッファと呼ばれているものの、実際には永続的なデータであることに留意すべきです。言い換えれば、変更バッファはメモリ内のコピーがディスクに書き込まれます持っています。
動作変更バッファは、元のデータ・ページに適用され、プロセスの最新の結果をマージと呼ばれ得ます。マージをトリガーするデータ・ページにアクセスするには、さらに、システムは、バックグラウンドスレッドが定期的にマージしています。ノーマルクローズデータベースに
プロセスの(シャットダウン)、操作実行がマージされます。
もちろん、私たちは刑の執行のディスク読み込み速度が大幅に改善される減らし、変更バッファ内の最初のレコードを更新することができます。また、データがメモリに読み込まれ、この方法でも避けることができるように、バッファプールを占有する必要が
改良されたメモリの利用のための空きメモリを。
だから、何の条件は、それをバッファリング変更使用することができますか?
ユニーク索引の場合、すべての更新操作は、最初の操作は、ユニーク制約に違反するかどうかを決定する必要があります。たとえば、このレコードを(4400)を挿入するために、我々は最初に現在のレコードのk = 4がすでにテーブルに存在するかどうかを決定する必要があり、これは数たくなければなりません
判断にメモリにデータページを。あなたは既にメモリに読み込まれている、そのメモリは、直接変更バッファを使用する必要を更新しない速くなります。場合
そのため、更新は、実際には、唯一の一般的な指標を使用することができ、ユニークな屈折率変化のバッファを使用することはできません。メモリ内のバッファプールを使用してバッファを変更し、したがって無限に大きくすることができません。大きな変化バッファ
の小さなは、動的パラメータinnodb_change_buffer_max_sizeによって設定することができます。このパラメータは、50%のバッファプールの最大の変化バッファ占有率の大きさを示すために50に設定されている場合。
さて、あなたはその後、私たちは見てみましょう、変更バッファのメカニズムを理解する必要がありますが、このテーブルに新しいレコードを挿入したい場合は(4400)の言葉、InnoDBの処理の流れは次のようです。
最初は、このレコードは、メモリ内のターゲット・ページを更新することです。この場合、以下のようにInnoDBのプロセスです。
- 一意のインデックスのために、3と5との間の位置を求めるには、競合がないと判定され、値が挿入され、文の終わりを実行します。
- 一般的な指標のために、3と5との間の位置を見つけること、文の実行が終了し、この値を挿入します。
これは、更新された影響評価書のパフォーマンスの違いについての一般的なインデックスとユニークインデックスように思われるが、裁判官は、わずかなCPU時間を消費します。
しかし、これは我々の焦点ではありません。
後者の場合には、このレコードがターゲットページを更新することにあるメモリではありません。この場合、以下のようにInnoDBのプロセスです。
- ユニーク索引の場合、データ・ページは、文の実行が終了し、この値を挿入し、競合がないかを決定するために、メモリに読み込まれる必要があります。
- 一般的なインデックス、変更バッファに吸い込ま更新レコードの場合は、文の実行が終わりました。
IOに関連するデータへのランダムアクセスは、ディスクからメモリに読み込み、データベース内部で動作し、最高のコストの一つです。性能を向上させるために減少ランダムディスクアクセスのchangebufferので、アップデートは非常に明らかであろう。
私は一つのことに遭遇する前に、ライブラリメモリは事業の割合が突然75%、99%から減少し、システム全体がブロックされている、すべての更新ステートメントを打つためのフィードバックDBAの学生は、彼が担当していたことを私に言っていますブロックされました。そして、その探索
後で理由を、私は彼が一般のインデックスにユニークインデックスにこれらのいずれかを置く前にデータを挿入する操作の数が多い、日があり、このビジネスを見つけました。
四、変更の緩衝機構とアプリケーションのシナリオ
上記の分析を通じて、あなたが変更バッファを使用して更新プロセスを加速する上で明確な役割を持って、明確に変更バッファは、とないユニークインデックスにシーンの一般的な指標での使用に限定されます。まあ、今そこにある
問題はこれです:すべてのシーン、変更バッファ通常のインデックスの使用は、それを加速させる役割を果たしていることができますか?
時間をマージすることは、本当に時間データの更新を実行し、データ・ページの前に、変更変更バッファレコードマージんので、変更バッファの主な目的は、キャッシュされた操作のレコードを変更することですされているので
、このページ上に、それがある(詳細は大きな更新の回数)、メリットより。
追記多くの中小企業を読むためにこのように、ページの確率は直後に最高の演出変更バッファを使用して、この時間は、比較的小さなへのアクセスを終えました。このビジネスモデルは、共通の課金クラス、クラスのシステムログです。
逆に、ビジネスの更新モードは条件は、変更バッファ内の最初の更新レコード成立しているが、データ・ページにアクセスすることにより直ちに後に、それはすぐにあまりにもマージトリガする場合でも、クエリを記述した直後に行われたと
チェン。このように、ランダムアクセスIOの数が減少するが、変更バッファのメンテナンスコストを増加させたことはありません。したがって、このビジネスモデルのため、変更バッファであるが、副作用を果たしました。
第五に、インデックス選択の実践
背中資料の冒頭に私たちの質問は、一般的なインデックスとユニークインデックスが選択する方法でなければなりません。実際には、クエリ機能上のインデックスこれらの2つのタイプには違いありません、主な考慮事項は、更新のパフォーマンスへの影響です。だから、私はあなたが定期的にインデックスを選択しようとすることを示唆しています。
アップデートの背後にあるすべてをすぐにレコードのクエリに関連付けられている場合は、changebufferをオフにする必要があります。他の例では、チェンジ・バッファは、パフォーマンスの更新を向上させることができます。
一般的なインデックスと変更バッファは、テーブルを更新するために、大量のデータを最適化するために使用されて実際の使用では、あなたが見つけるだろう、明らかです。
具体的には、このメカニズムのほとんど変化バッファを持つ機械のハードディスクを使用することは、非常に重要です。だから、あなたが同様の「履歴データ」のライブラリを持っており、機械的なハードドライブを使用する際のコストを考慮して、その後、あなたがに特に注意を払う必要があるとき
、インデックステーブルを一般的なインデックスを使用しようとした後、大きな変化バッファを開こうとすると、データは、この「過去のデータ」テーブルのスピードを書くことを保証するために、
六、バッファおよびログをやり直す変更
変更バッファの原則を理解し、あなたは私の思うかもしれないと、あなたは以前の記事で説明されているログとWALやり直していました。
コメント以前の記事で、私はいくつかの学生がREDOログおよび変更バッファを混同していることが分かりました。WALは、コアメカニズムのパフォーマンスを向上させると、確かに、二つの概念を混同して本当に簡単、ランダム読み取りを最小限にして書くことです。だから、私はここにそれを置く、
我々はあなたが二つの概念を区別しやすさを示すために一つの配列を置きます。
注意:ここでは、ログシステム」の記事の下に2を振り返ることができますどのように更新するためのSQL文が実行されますか?「関連するコンテンツで。
今、私たちはテーブルの上にINSERT文を実行する必要があります。
MySQLの> T(ID、K)の値(ID1、K1)に挿入、(ID2、K2)。
ここでは、メモリ内のK1データ・ページの場所を、見つけた後k個のインデックスツリー、(InnoDBbufferプール)、k2はメモリにないデータページの現在の状態と仮定します。図2に示すように変化バッファの状態で更新されます。

変化バッファ更新処理と図2
メモリー、ログをやり直す(ib_log_fileX)、データテーブルスペース(t.ibd)、システム・テーブル・スペース(ibdata1と):この更新文の分析では、あなたはそれが四つの部分を含んでいることがわかります。
この更新ステートメントは、(図中の番号順に)次の操作を行います。
メモリ内の1ページ1は、ダイレクトメモリが更新される。
2. 2ページがメモリにない、メモリの変化バッファ領域、この情報「私は2ページの行を挿入したい」の記録
3. 2つのノートの操作REDOログ(図3、図4)。
上記に行われ、トランザクションが完了することができます。だから、あなたはつまり、二つのメモリの書き込みは、その後、(ディスクを書き込むために一緒に2つの操作を)ディスクを作成し、この更新ステートメントの実装のコストが非常に低いことがわかり、また書面でオーダーします。
一方、図の2つの破線の矢印は、更新の応答時間には影響しません、バックグラウンド操作です。
その要求これを読んだ後、どのようにそれに対処するには?
たとえば、私たちは今(でT K SELECT * FROM実行したい K1、K2)。ここで、私は2つの読み取り要求のフローチャートを描きます。
あなたはまもなく更新文の後の文を読んでいる場合は、メモリ内のデータはまだそこにあるので、この時間は2は、システムテーブルスペースに(ibdata1とする)の読み取り操作(ib_log_fileXは)無関係なREDOログ。だから、私は図の二つの部分を描画しませんでした。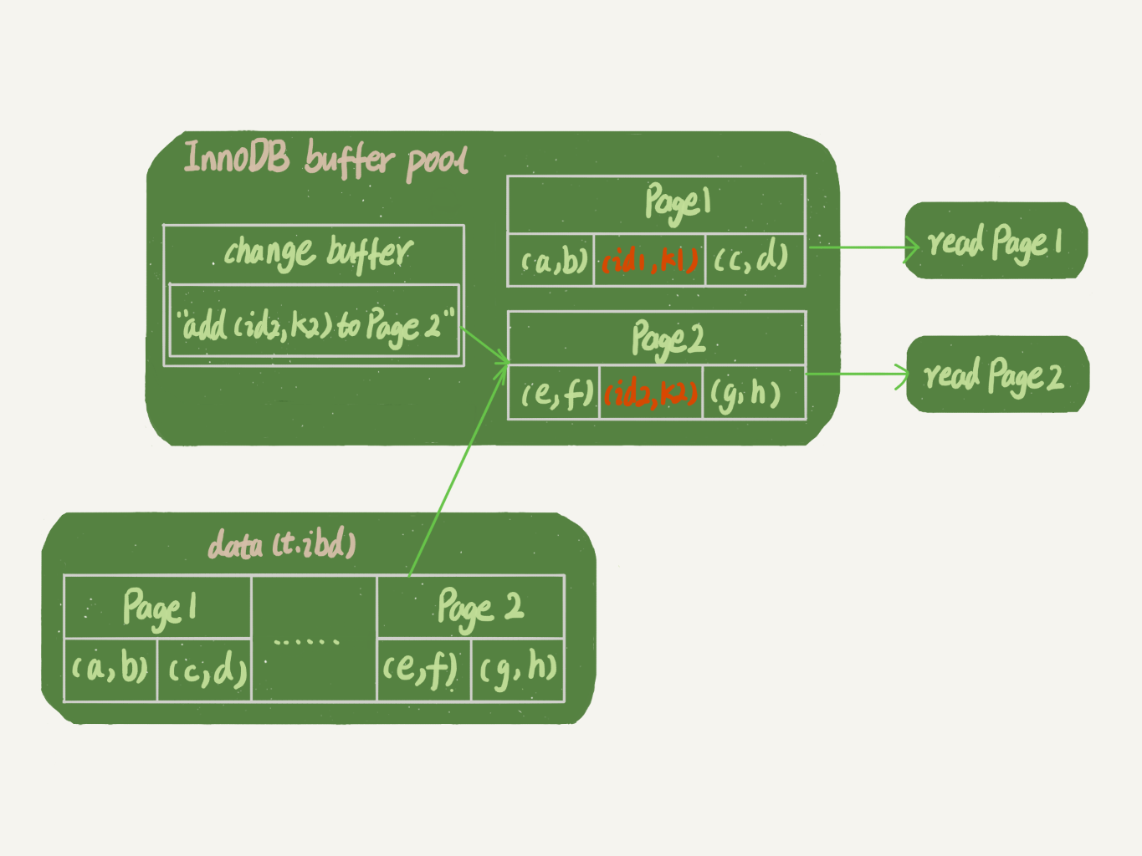
変化緩衝液で、図3のプロセスを読み取ります
これは、図から見ることができます。
メモリから直接返さ1.読むページ1。データがディスクを読み取ることは必ずしもない場合は、前の記事のコメントのいくつかの学生はWALを読んだ後、尋ね、必ずしもそこからデータの更新をREDOログされていません
前に、後で返すことができますか?実際には、それが使用されていません。あなたは、データの前にディスク上にまだあるが、図3の状態を見ることができますが、その結果は、ここではメモリから直接返された結果が正しいです。
時間を読むために2ページ2、ページ2がディスクからメモリに読み込まれる必要があり、その後、操作ログの内部に変更バッファーを適用する、正しいバージョンを生成し、結果を返します。これは、データ・ページがメモリに読み込まれるとき、2ページを読み込む必要までは見ることができます。
あなたは、単に持ち上げ更新パフォーマンスにこれら二つのメカニズムの収益を比較したいのであれば、その後、大手貯蓄ランダム書き込みREDOログ・IOは、ディスク(シーケンシャル書き込みに変換)を消費し、メイン貯蓄をバッファに変更ランダムリードディスクですIO消費。
VII概要
今日、私はから選択するには、一般的なインデックスとユニークインデックスを開始し、クエリおよび更新データを共有して、メカニズムやシナリオがバッファを変更し、最終的にはインデックス選択の実践について話しました説明します。
一意のインデックスの事業を受け入れることができますので、もしアクセス最適化のメカニズムは、バッファを変更する必要はありませんので、パフォーマンスの観点から、私はあなたがユニークでないインデックスに優先権を与えることをお勧めします。
最後に、彼は時間の質問に行ってきました。
あなたはそれを失ったこの時間は、バッファを変更するにはつながらない場合は、マシンパワーダウンが再開、変更バッファメモリが先頭を書くことで、図2で見ることができますか?変更バッファ損失は小さなものではありませんし、その後ディスクから読み取ります
データは、データの損失に等しいだろう、マージプロセスを持っていないかもしれません。それが起こるのだろうか?
あなたは、私は次の記事を終了し、あなたがこの問題を議論、コメント欄に書かれた自分の考えやアイデアを置くことができます。聴いてくれてありがとう、あなたは一緒に読むためにもっとたくさんの友達にこの共有を送るために歓迎されています。
彼は加えました:
コメントエリア、我々はより多くの議論を持っている主の場合にもつれ、「一意のインデックスを使用するかどうか」「ビジネスは、ことを保証することはできないかもしれません」。ここでは、私が説明しましょう:
まず、ビジネスの正しさの優先順位。この記事の前提は、パフォーマンス上の問題を議論しないように、「業務コードは、データのない重複があることを確認するために書かれている」であるしましょう。ビジネスが保証するものではありませんまたはサービスが約行うためにデータベースを依頼する場合には
、ビームの選択肢を持っていなかった、そして、あなたは一意のインデックスを作成する必要があります。この場合は、この記事の重要性は、あなたがデータ挿入遅く、メモリのヒット率の多くに実行する場合、彼らはあなたにトラブルシューティングのアイデアの多くを与えることができるということです。
その後、いくつかの「アーカイブライブラリ」のシーンには、共通のインデックスの使用を検討することができます。たとえば、オンラインのデータだけで半年を維持する、とアーカイブライブラリ内の履歴データ。このとき、アーカイブはデータのみをキーパンチがないことを確実にするためである
の競合を。アーカイブの効率を向上させるために、一般的な指標に一意のインデックス内のテーブルを考えてみます。
八、時間の問題
ステージ上での質問です:「データが変更することはできません、」シーンを構築する方法。コメント地区は、多くの学生は、正しい答えを与えている、私はここで説明します。

このように、セッション私は効果を見るもののスクリーンショット。
実際には、別のシーンがあり、学生はまた、メッセージ領域に記載されていません。

この一連の動作は尽き、セッション私のショットの内容を見ても、効果を再現することができます。このセッションB「ので早くAより開始トランザクションが、実際には、私たちの卵の可視性規則トランザクションのバージョンを記述する際に、残りの期間で
判断活発な事業、「私はここに補充滞在する覚悟ルールがあり」。
私はここで完全なルールを教えしようとしたとき、我々は最終的には問題が孤立単離されるか、またはされていない」最初の8記事を見つけましたか?解析は非常に複雑であるように解釈は、「あまりにも多くの概念を導入しました。
だから私は、最初の8つを書き直したので、私たちは、労働時間の可視性を判断するために、より便利になります。[ここを参照してください、私はあなたが最初の8件の記事を再度開き、真剣に時間を勉強することができることを示唆しています。学習プロセスは、質問があれば、
あなたは私にメッセージを与えるために歓迎されています]
セッションをB分析する新しい方法「更新がなぜセッションAに表示されない:セッションでビュー
アレイの瞬間ビューが作成され、セッションのB」がアクティブであり、「コミットされていないバージョン、目に見えない」場合です。
あなたはヨシュアはソリューションの「楽観的ロック」を提供@、問題のビジネスのこのタイプをバイパスしたい場合は、見てのメッセージエリアに行くことができます。
九、古典的なメッセージ
一般的なインデックスはインデックスのみで選択しますか?
クエリの処理のためにあります:
、一般的な指標は、最初のレコードが条件満たしていないことを知って、次のレコードを検索していき、条件を満たした後、最初のレコードを発見した
インデックスがユニークであるので、一意のインデックスをbは、最初のレコードの条件を満たしていることが見いださ取得するために停止した後、
しかし、2つの間の性能差は最小限です。InnoDBのページが読み込まれ、データに基づいて書かれているので。
更新プロセスについて次のとおりです。
コンセプト:変更バッファ
あなたは、データ・ページが直接データの一貫性に影響を与えることなく、メモリ内にない場合は、メモリ内で更新された場合、データ・ページを更新する必要がある場合、InnoDBは変更のバッファ・キャッシュ内のこれらの更新プログラムで動作します。次回は、クエリはデータページがメモリに読み込まれ、データ・ページにアクセスする必要があり、その後のページ変更バッファに関連付けられている操作を実行します。
変更バッファは、永続的なデータです。ディスクに書き込まれるメモリ内のコピーがあります。
パージ:動作変更バッファはプロセスの最新の結果を取得し、元のデータ・ページに適用され、データ・ページパージのアクセスとなってパージをトリガーすると、システムは定期的にパージを実行すると、データベースをシャットダウンする通常のプロセスでは、パージバックグラウンドスレッドを持っています
更新一意のインデックスは、変更のバッファを使用することはできません
変化バッファがメモリ・バッファ・プールで使用され、変更バッファサイズを動的パラメータinnodb_change_buffer_max_sizeによって設定することができます。このパラメータは、50%のバッファプールの最大の変化バッファ占有率の大きさを示すために50に設定されている場合。
IOに関連するデータへのランダムアクセスは、ディスクからメモリに読み込み、データベース内部で動作し、最高のコストの一つです。
減少ランダムディスクアクセスによる変更バッファ、アップデートは、パフォーマンスを向上させるように、明らかです。
変更バッファの使用シナリオ
データ・ページの前にパージを行い、より多くの変更バッファレコードの変更、メリットも大きいです。
書き込みのために一度、すぐに最高の演出変更バッファを使用して、比較的小さな、この時間に仕上がっアクセスした後、ページの可能性を多くの中小企業をお読みください。このビジネスモデルは、共通の課金クラス、クラスのシステムログです。
逆に、仮定ビジネス更新モードは、条件が満たされた場合でも、クエリを記述した直後の変化バッファ内の最初の更新レコードを行われますが、データ・ページにアクセスすることにより直ちに後に、それはすぐにパージ処理をトリガーします。
このように、ランダムアクセスIOの数が減少するが、変更バッファのメンテナンスコストを増加させたことはありません。したがって、このビジネスモデルのため、変更バッファであるが、副作用を果たしました。
インデックスの選択と実践:
可能な限りは、通常のインデックスを使用しています。
(シーケンシャル書き込みに変換)の主要な貯蓄ランダム書き込みディスクIOの消費をREDOログ、および主要な貯蓄をバッファに変更すると、IOは、ディスクを消費ランダム読み取ります。