データ処理の課題
漸進的な蓄積と、エンタープライズデータ、リレーショナル・データベース・アーキテクチャ単一ノードからのデータ、サブライブラリーサブテーブルの進化、及びその後のNoSQLとHadoopの生態へと進化を増大させます。生態系の繁栄をHadoopの、統一標準アーキテクチャは、現在よりはpiplineによって接続されたストリーム・コンピューティング、バッチ処理、オンラインストレージ独立の主な特徴であるラムダアーキテクチャで使用されていません。
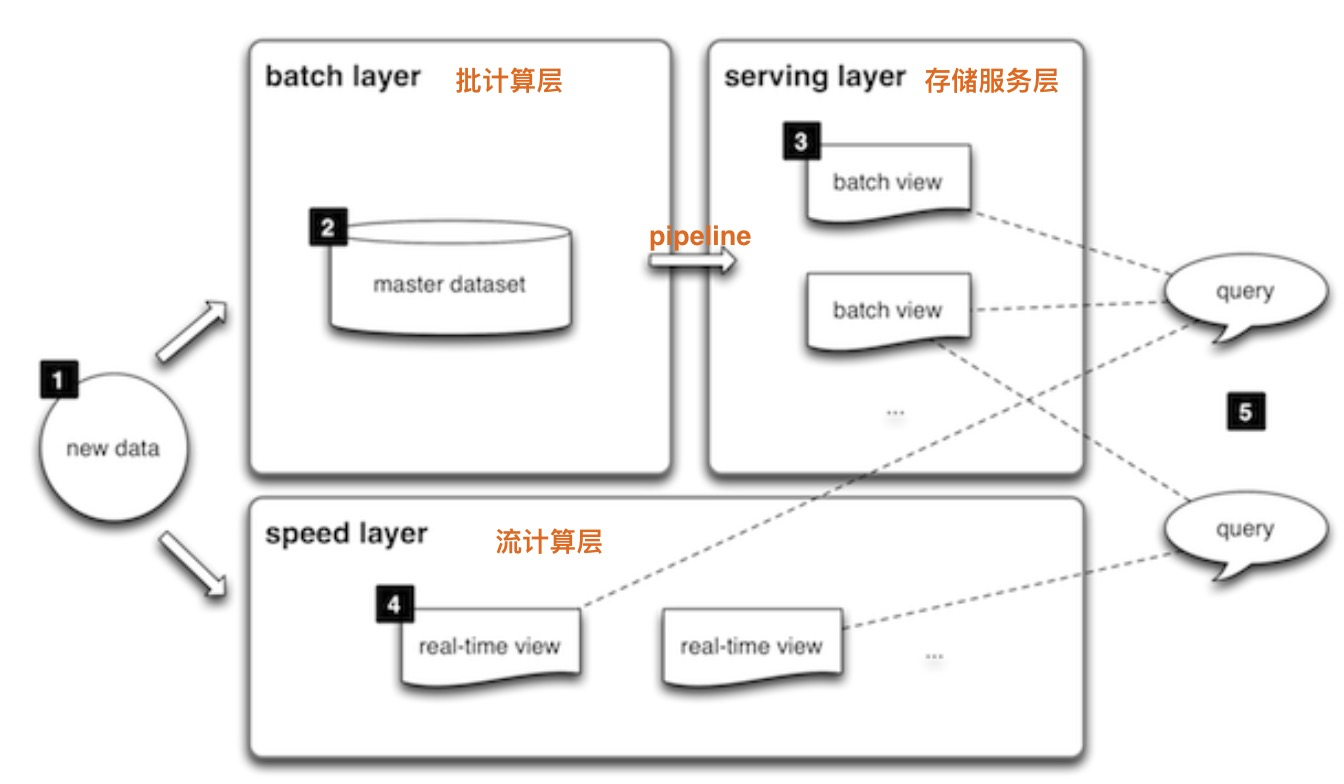
ビッグデータラムダ・アーキテクチャは、フローは、バッチは、オンライン・ストレージは別の建物、およびデータ交換の流れを行うためのデータpiplineを構築する必要性を必要とする、より複雑です。
- データが書かれている:バッチ処理、ストリーミング、データのオンラインストレージを個別に書き込む必要があります。詳細なデータに直接書き込む事業の多くはHBaseの、カサンドラ、MongoDBのようにオンライン・ストレージ・システムのようになりますしながら、一方では、と多くの上の2つのストリームは、別々の書き込みデータが必要です。
- データ交換:ETLのバッチジョブの多くを構築するためのオンラインストレージの必要性を切り替えるバッチ処理、
- データ品質:バッチ処理、ストリーミング、データのオンラインストレージを書き込む必要がある、それぞれ、複雑なデータのメンテナンスにつながる、データリンクが異なるに書き込まれない場合があります