編集者:ブログホースパーク金龍https://www.cnblogs.com/f-ck-need-u/p/7717488.html
静的リソースに対する要求を処理することができtomcatには、動的なリソース要求は、サーブレットによって処理することができます。第ジャスパーアセンブリ(具体的のJspServlet)によってJSP動的リソース処理は、JSP、Javaソース・コードに変換し、クラスを実行するようにコンパイルします。知っておく必要があり、同じ静的リソースがサーブレットによって処理され、それが使用することを除いて、サーブレットはサーブレットでの$ CATALINA_HOME / confに/ web.xmlにデフォルトを定義することであるということです。本論文では、(同時)クライアント要求を処理する方法Tomcatを分析し、詳細に動的および静的なリソースをどのように扱いますか。
1.Tomcatコンポーネントアーキテクチャ
次の二つの図:上記は、図Tomcatコンポーネントシステムの図であり、以下の図のサービスコンポーネントが洗練図です。
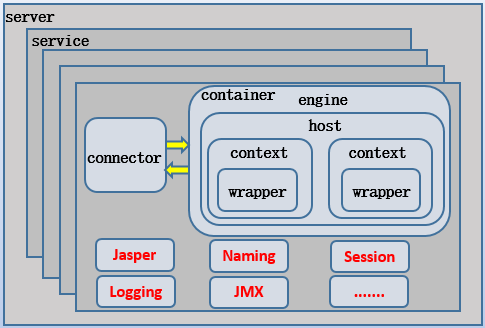

どこで:
server管理コンポーネントアセンブリのTomcatインスタンス、リモートクローズコマンドからのシャットダウンポートを送信する場合に、ポートを監視することができます。serviceコンポーネントが一つの論理コンポーネントであり、結合およびコンテナコネクタの、サービスを提供することができる外側に一般的なサービスクラスとサービスデーモンのようなサービスを表します。サービスJVM(ロード・バランシングを定義する場合、のjvmRoute定義はエンジン部品にJVMを識別するために使用される)に対応したJVM、厳密に言えば、唯一のエンジン部品を開始しますが、コネクタはまた、JVMで動作しているとみなすことができます。connector構成要素であるリスニングコンポーネントを、それが4つの機能があります。- 。(1)オープンリスニングソケットは、外部の要求に耳を傾けると、TCP接続を確立します。
- (2)例えばhttpプロトコル、AJPプロトコルなどのプロトコルとprotocolHandler解析情報要求ポートを使用して、
- (3)プロセサエンジンを使用して、情報要求の分析に基づいて、バインディングにデータを転送します。
- (4)と、クライアントに返された応答データを受信します。
containerコンポーネントのクラスである容器は、構成ファイル(例えば、のserver.xml)に反映されません。エンジンの容器、ホスト容器、コンテキストラッパー、およびコンテナ船:それは4つのコンテナクラスコンポーネントが含まれています。engine分析の結果に応じて、リクエストの上コネクタ組立体を受容するための容器から転送し、仮想ホストに一致するようにパラメータを渡します。エンジンもデフォルトの仮想ホストを指定するために使用されます。hostコンテナは、主にサーブレットコンテナとしてTomcatのため、彼らのルートディレクトリは、各WebアプリケーションのためのappBaseを指定し、仮想ホストを定義します。context容器メインパスと文書ベース、ラッパーアセンブリによれば、いくつかの情報を取得した(これはコンテキストコンテキストと呼ばれているように、動作環境ラッパーを提供する)プロセスの結果。一般的に、デフォルトの標準ラッパークラスで、これはほとんどのコンテキストラッパーアセンブリコンテナに発生しません。wrapperコンテナ処理サーブレットに対応します。これは、サーブレットのライフサイクルを開き、コンテキストが与えられたマッピング情報に応じて、クラスローディング関連オブジェクトの担当のweb.xmlを解析初期化サーブレットのinit()、(サーブレット・コード実行サービスを破壊する)とサービス・サーブレット・オブジェクトの終了Destoryは()。executor各コンポーネントサービスコンポーネントは、スレッドプールを提供し、このような処理要求エンジンは、それによってTomcatの並行処理能力を達成する、スレッドプールからスレッドを取得することができます。スレッドプールエグゼキュータのサイズをメモしておいてくださいは、エンジンの構成部品ではなく、コネクタのセットに設定されている、スレッドコネクタの数がacceptorThreadCount財産コネクター・コンポーネントによって設定されています。コンポーネントは、コンフィギュレーションファイルに設定する場合は、で使用するためのフロントコネクタ・アセンブリ・コネクタ・アセンブリに提供されなければならないexecutorアセンブリ構成エグゼキュータを参照するプロパティ。明示的Connectorコンポーネントには、デフォルトの設定が設定されていない場合は、次のように、デフォルトの設定は次のとおりです。- (1).maxThreads:スレッドの最大数、200のデフォルト値。
- (2).minSpareThreads:アイドルスレッドの最小数、25のデフォルト値。
- (3).maxIdleTime:アイドルスレッドは1分です60,000のデフォルト値を破壊しますどのくらいのアイドルスレッドです。
- (4).prestartminSpareThreads:executorを開始するかどうかのスレッドは、デフォルト値がfalseの場合、直接入力への接続要求がある場合にのみ、それが作成される、すなわち、アイドル状態のスレッドの最小数に等しい作成します。
上述のTomcatのコンポーネントアーキテクチャは、プロセスは、一般推定要求を処理することは非常に容易です。
Client(request)-->Connector-->Engine-->Host-->Context-->Wrapper(response data)-->Connector(response header)-->Client
2.Tomcatとのhttpd / nginxの処理要求の違いとリッスン
リスニングと処理要求に、Tomcatとのhttpd / nginxのサービスプログラムは、同じではありませんが、違いは巨大です。処理要求が理解されている際に、Tomcatのに設定のhttpd / nginxの処理モードであってはなりません。
httpdの/ nginxのについて私の他の記事を参照して、詳細については、それらとTomcatの違いを反映するために、接続のサービスプログラムの処理時間、ここでの唯一の簡単な説明:ソケットとTCP接続プロセスを知っている必要があります。
(1)。からhttpd / nginxのは、すべてのプロセス/スレッドを聞いているの接続要求を聞いたときに、監視する責任がある新しいものが生成されます已连接套接字接続と呼ばれるキューに置かを、再びリスニングに行くために継続して、プロセス/スレッドを監視します。キューからの要求と業務プロセス/スレッドを処理するための責任が取得已连接套接字し、クライアントとTCPコネクションを確立し、クライアント、リソース要求データ、応答データを受信し、クライアントを構築するなど、クライアントと通信します。
(2).tomcatリスニングと処理要求も処理のためのさまざまなコンポーネントを使用して動作しますが、スレッドのモニタコネクタは、直接TCPコネクションの確立を要求するために、接続を維持するために、クライアントと協力してきたが。コネクタのスレッドは、エンジンのスレッドが構築するために要求と応答のデータを処理するための責任があるが、任意の接続エンジンコンポーネントとクライアントを確立しません、要求とバインドされているエンジンコンポーネントに転送結果を分析します。すべてのデータソースは、エンジンコネクターは、いずれかのクライアントのリソース要求は、コネクタ、コネクタに送信され、エンジンに転送されますされています。エンジンレスポンスを構築した後、応答が再びコネクタによって、コネクタにデータを転送するクライアントに返信するためにいくつかの処理(例えば、プラスヘッダフィールド)を行います。
限り、それは明確に接続Tomcatと要求処理を推測することができるよう:外フローからいつでも要求はコネクタを介して行くことにバインドされ、また地元から流れる任意の応答時間データは、コネクタを経由します。これは、コネクタは、クライアントとサーバーのサーブレットを接続する──の意義です。
同時リクエストを処理するための方法を2.1 Tomcatの
IOコネクタアセンブリプロトコルは、4種類をサポートしています。同期ブロッキングBIOは、同期非ブロックNIOは、非同期NIO2を非ブロック、IOモデル4月にApache財団(IO 4月のモデルはちょうどライブラリモジュールの機能の一つです)。差はBIOの添加は、IOリクエストで他のモデルは、新しい非ブロッキングに受け入れられ、以下のようになり、BIOは、したがって、ここでは考慮していないが、コネクタは、今BIOモード提供誰もありません。

表では、ほとんどの懸念は、「次の要求を待つ」である行、NIO / NIO2 / APRは非ブロックしている、これは要求が処理されているときにブロックされない、Tomcatを達成することである追加のリクエストを受け取ることができますリクエストを処理するために、同時キー。
同時コネクタアセンブリおよび関連セットアップ・オプションの数を見てください:
acceptorThreadCount:用于接收连接请求的线程数。默认值为1。多核CPU系统应该增大该值,另外由于长连接的存在,也应该考虑增大该值。maxThreads:线程池中最多允许存在多少线程用于处理请求。默认值为200。它是最大并发处理的数量,但不影响接收线程接收更多的连接。maxConnections:服务端允许接收和处理的最大连接数。当达到该值后,操作系统还能继续接收额外acceptCount个的连接请求,但这些连接暂时不会被处理。当Connector类型为BIO模型时的默认值等于maxThread的值,当为NIO/NIO2模型时的默认值为10000,当APR时默认长度为8192。acceptCount:当所有请求处理线程都处于忙碌状态时,连接请求将进入等待队列,该值设置等待队列的长度。当达到队列最大值后,如果还有新连接请求进入,则会被拒绝。默认队列长度为100。
从上面几个属性的意义来分析并发机制:
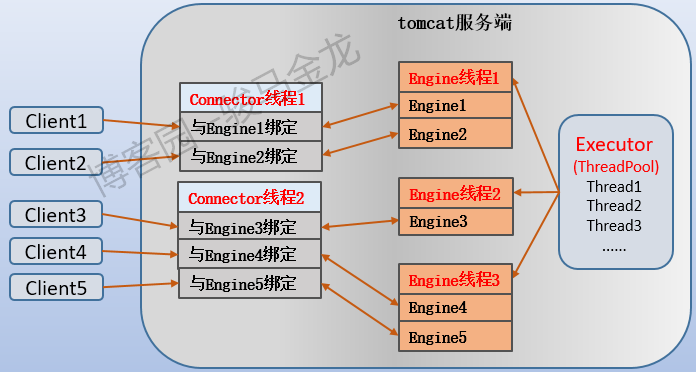
- (1).connector中最多有acceptorThreadCount个专门负责监听、接收连接请求并建立TCP连接的线程,这些线程是非阻塞的(不考虑BIO)。当和某客户端建立TCP连接后,可以继续去监听或者将Engine返回的数据发送给客户端或者处理其它事情。
- (2).线程池中的最大线程数maxThreads决定了某一刻允许处理的最大并发请求数,这是专门负责处理connector转发过来的请求的线程,可以认为这些线程专门是为Engine组件服务的(因此我将其称之为Engine线程)。注意,maxThreads决定的是某一刻的最大并发处理能力,但不意味着maxThreads数量的线程只能处理maxThreads数量的请求,因为这些Engine线程也是非阻塞的,当处理某个请求时出现IO等待时,它不会阻塞,而是继续处理其它请求。也就是说,每个请求都占用一个Engine线程直到该客户端的所有请求处理完毕,但每个Engine线程可以处理多个请求。同时还能推测出,每个connector线程可以和多个Engine线程绑定(connector线程的数量远少于Engine线程的数量)。
- (3).当并发请求数量逐渐增多,tomcat处理能力的极限由maxConnector决定,这个值是由maxThreads和acceptorThreadCount以及非阻塞特性同时决定的。由于非阻塞特性,无论是connector线程还是Engine线程,都能不断接收、处理新请求。它的默认值看上去很大(10000或8192),但分配到每个线程上的数量并不大。假设不考虑监听线程对数量的影响,仅从处理线程上来看,10000个连接分配给200个处理线程,每个处理线程可以轮询处理50个请求。和nginx默认的一个worker线程允许1024个连接相比,已经很少了,当然,因为架构模型不一样,它们没有可比性。
- (4).当并发请求数量继续增大,tomcat还能继续接收acceptCount个请求,但不会去建立连接,所以也不会去处理。实际上,这些请求不是tomcat接收的,而是操作系统接收的,接收后放入到由Connector创建的队列中,当tomcat有线程可以处理新的请求了再去队列中取出并处理。
再来细分一下tomcat和httpd/nginx的不同点:
- (1).httpd/nginx的监听者只负责监听和产生
已连接套接字,不会和客户端直接建立TCP连接。而tomcat的监听者connector线程不仅会监听,还会直接建立TCP连接,且一直处于ESTABLISHED状态直到close。 - (2).httpd/nginx的工作进程/线程首先从已连接套接字队列中获取已连接套接字,并与客户端建立TCP连接,然后和客户端通信兵处理请求、响应数据。而tomcat的工作线程(Engine线程)只接受来自connector转发过来的请求,处理完毕后还会将响应数据转发回connector线程,由connector将响应数据传输给客户端(和客户端的所有通信数据都必须经过连接器connector来传输)。
- (3).不难推断出,一个Connector线程可以和多个客户端建立TCP连接,也可以和多个Engine线程建立绑定关系,而一个Engine线程可以处理多个请求。如果不理解并发处理机制,这一点很容易被"Connector组件和Engine组件绑定在一起组成Service组件"这句话误导。这句话的意思并不是要求它们1:1对应,就像httpd/nginx也一样,一个监听者可能对应多个工作者。
因此,tomcat处理连接的过程如下图所示,其中我把Engine线程处理请求的过程用"Engine+N"来表示,例如Engine线程1下的Engine1表示该Engine线程处理的某个请求,Engine2表示该线程处理的另一个请求。
3.Tomcat处理jsp动态资源的过程
假设tomcat的配置如下,其中项目名称为"xiaofang"。
1
2
3
4
5
6
7
8
9
10
11
12
13
<Connector connectionTimeout="20000" port="8080" protocol="HTTP/1.1" redirectPort="8443"/> <Engine name="Catalina" defaultHost="localhost"> <Host name="www.xiaofang.com" appBase="webapps/xiaofang" unpackWARs="true" autoDeploy="true"> <Context path="" docBase="" reloadable="true" /> <Context path="/xuexi" docBase="xuexi" reloadable="true" /> </Host> <Host name="localhost" appBase="webapps" unpackWARs="true" autoDeploy="true"> </Host> </Engine> 当客户端访问http://www.xiaofang.com:8080/xuexi/abc.jsp时,其请求的是$CATALINA_HOME/webapps/xiaofang/xuexi/abc.jsp文件。
(1).Connector组件扮演的角色。
Connector组件首先监听到该请求,于是建立TCP连接,并分析该请求。Connector分析请求的内容包括请求的协议、端口、参数等。因为这里没考虑集群问题,因此只可能是http协议而不可能是ajp协议的请求。分析后,将请求和相关参数转发给关联的Engine组件进行处理。
(2).Engine组件扮演的角色。
Engine组件主要用于将请求分配到匹配成功的虚拟主机上,如果没有能匹配成功的,则分配到默认虚拟主机上。对于上面的请求,很显然将分配到虚拟主机www.xiaofang.com上。
(3).Host组件扮演的角色。
Host组件收到Engine传递过来的请求参数后,将对请求中的uri与Context中的path进行匹配,如果和某个Context匹配成功,则将请求交给该Context处理。如果匹配失败,则交给path=""对应的Context来处理。所以,根据匹配结果,上面的请求将交给<Context path="/xuexi" docBase="xuexi" />进行处理。
注意,这次的uri匹配是根据path进行的匹配,它是目录匹配,不是文件匹配。也就是说,只匹配到uri中的xuexi就结束匹配。之所以要明确说明这一点,是因为后面还有一次文件匹配,用于决定交给哪个Servlet来处理。
(4).Context和Wrapper组件扮演的角色。
到了这里,就算真正到了Servlet程序运行的地方了,相比于前面几个组件,这里的过程也更复杂一些。
请求http://www.xiaofang.com:8080/xuexi/abc.jsp经过Host的uri匹配后,分配给<Context path="/xuexi" docBase="xuexi" />进行处理,此时已经匹配了url中的目录,剩下的是abc.jsp。abc.jsp也需要匹配,但这个匹配是根据web.xml中的配置进行匹配的。
首先,从项目名为xiaofang的私有web.xml中进行查找,即webapps/xiaofang/WEB-INF/web.xml。由于此处仅为简单测试,因此并没有该文件。
于是从全局web.xml即$CATALINA_HOME/conf/web.xml中匹配abc.jsp。以下是web.xml中能匹配到该文件名的配置部分。
1
2
3
4
5
6
7
8
9
10
11
<!-- The mappings for the JSP servlet -->
<servlet-mapping>
<servlet-name>jsp</servlet-name> <url-pattern>*.jsp</url-pattern> <url-pattern>*.jspx</url-pattern> </servlet-mapping> <servlet> <servlet-name>jsp</servlet-name> <servlet-class>org.apache.jasper.servlet.JspServlet</servlet-class> </servlet>首先根据<servlet-mapping>中的url-pattern进行文件匹配,发现该url匹配的是servlet-name为"jsp"的servlet,然后再找到与该名称对应的<servlet>标签段,发现处理该动态资源的类为org.apache.jasper.servlet.JspServlet,于是找到该类对应的class文件,该class文件归档在$catalina_home/lib/jasper.jar中。

JspServlet程序的作用是将jsp文件翻译成java源代码文件,并放在$catalina_home/work目录下。然后将该java源文件进行编译,编译后的class文件也放在work目录下。这个class文件就是abc.jsp最终要执行的servlet小程序。
1
2
[root@xuexi ~]# ls /usr/local/tomcat/work/Catalina/www.xiaofang.com/xuexi/org/apache/jsp/
index_jsp.class index_jsp.java new_ 在翻译后的servlet小程序中,不仅会输出业务逻辑所需的数据,还会输出html/css代码,这样一来,客户端接收到的数据都将是排版好的。
4.Tomcat处理静态资源的过程
对于tomcat来说,无论是动态还是静态资源,都是经过servlet处理的。只不过处理静态资源的servlet是默认的servlet而已。
在$catalina_home/conf/web.xml中关于静态资源处理的配置如下。
1
2
3
4
5
6
7
8
9
10
<!-- The mapping for the default servlet -->
<servlet-mapping> <servlet-name>default</servlet-name> <url-pattern>/</url-pattern> </servlet-mapping> <servlet> <servlet-name>default</servlet-name> <servlet-class>org.apache.catalina.servlets.DefaultServlet</servlet-class> </servlet>需要记住的是,web.xml中的url-pattern是文件匹配,而server.xml中的<Context path="URL-PATTERN" />是目录匹配。
上面web.xml中的<url-pattern>/</url-pattern>表示的是默认servlet。这意味着,当web.xml中没有servlet-mapping能匹配请求url中的路径时,将匹配servlet-name,即名为default的servlet。然后找到处理default的类为org.apache.catalina.servlets.DefaultServlet,该类的class文件归档在$catalina_home/lib/catalina.jar中。该servlet不像JspServlet会翻译jsp文件,它只有最基本的作用:原样输出请求文件中的内容给客户端。
例如,根据前面的配置,下面几个请求都将采用默认servlet进行处理,即当作静态资源处理。
1
2
3
4
http://www.xiaofang.com:8080/xuexi/index.html
http://www.xiaofang.com:8080/xuexi/abc.js http://www.xiaofang.com:8080/xuexi/index http://www.xiaofang.com:8080/xuexi/index.txt 但http://www.xiaofang.com:8080/xuexi则不一定,因为tomcat中默认的index文件包含index.jsp和index.html,而index.jsp排在index.html的前面,只有不存在index.jsp时才请求index.html。