I、EDITORIAL
書き込み爬虫類爬虫類は、スタンドアローンされる前に、私は、これは、分散クローラの初めての経験で、クローラを分散しようとしていません。いわゆる分散型クローラ、スタンドアローンする爬虫類を比較して、データをクロール同時に一台のコンピュータよりも多くを使用することで、爬虫類は速くクロール分散するだけでなく、優れたIP検出に対応できます。この記事は、分散クローラのRedisデータベースの実装を使用することを記載し、Redisのは、人気のフィリピンのリレーショナルデータベースである、一般的なデータ型が文字列、ハッシュ、セット、リストおよびソートセットが含まれ、それはRedisのに重要であり、ホストができ、マスタースレーブのレプリケーションをサポートしていますスレーブにデータを同期させる、別の読み取りと書き込みを実現することが可能です。Redisのように、我々は要求モジュールを意味し、送信要求の特性を使用して、抽出されたウェブデータを解析し、単純な分散クローラを実装することができます。
第二に、基本的な環境
Pythonのバージョン:のpython3
Redisのバージョン:5.0
IDE:Pycharm
第三に、環境設定
Windowsでインストール構成が比較的簡単であるので、これだけ、ここで言うインストールおよびLinux環境(例えばUbuntuのと)のRedisを設定します。
1. Redisのをインストールします。
1)をインストールしやすいです。
$ sudoのRedisのサーバーをインストールapt-getを
2)コンパイルしてインストールします。
$ のwget のhttp :/ / ダウンロード.redis .IO / リリース/ Redisの- 5.0.0.tar.gz
$ タール- xzvf Redisの- 5.0.0.tar.gz
$のCDのRedisの- 5.0.0
$のメイク
$ make installを
2. [設定のRedis
まずredis.confファイルを見つけ、その後、コマンドはsudoのvi redis.confを入力し、次のように進みます。
リモートで接続するには、バインド127.0.0.1番号をコメント、この工程はまた、バインド127.0.0.1の代わりに0.0.0.0をバインドすることができます
プロテクトモードはい改为プロテクトモードなし
何改为はイエスデーモン化しないデーモン化
6379ポートが占有されている場合は、我々はまた、どのようなポート番号を変更する必要があります。また、接続する必要はリモートでファイアウォールをオフにします。
chkconfigをは#は、ファイアウォールをオフにオフfirewalld
systemctl状態firewalld#ファイアウォールの状態を確認
3.リモート接続のRedis
コマンドはRedisの-CLI -h <IPアドレス> -p <ポート番号>
注:Windowsの表示IPアドレスでipconfig、LinuxはifconfigコマンドでIPアドレスを表示します。
第四に、基本的な考え方
私は、サイトのクロールこの時間:http://www.shu800.com/が、そこにこのサイトの分類、すなわち、セクシーな美しさ、純粋で美しい、スターモデル、アニメーションや美容ストッキングの脚はトップ5に家にいる、そうまず最初に、これらのURLの分類を取得することです。次に、各分類のウェブクローリングの下で、次の情報がページ要素を表示して見つけることができます:

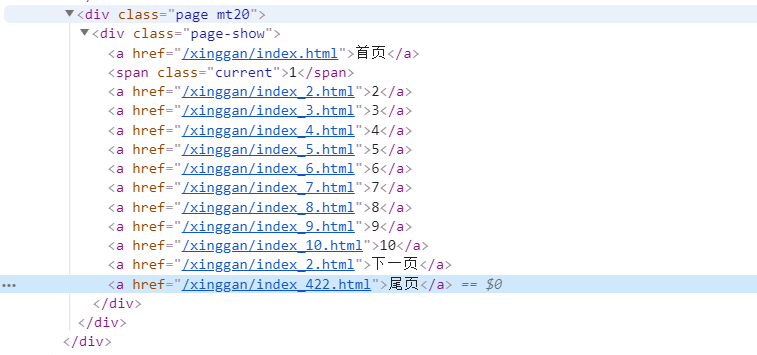
あなたはこの比率を毎回明確に限り、ページを抽出することになる最後のページのURLに取得するなど、一定のルールに沿ったもので、各ページのURLを参照してくださいすることができますまた、すべてのページのURLを構築することができるようになりますし、次のURLを簡単に取得します。各アトラス下の画像については、だけでなく、各ページのURLの画像を同じ方法で取得します。最後は写真のURLのページの画像から抽出されませんし、次にダウンロードし、ローカルに保存します。
私は2台のコンピュータ、マスタマスタとして一つのスレーブスレーブとして他の使用分散クローラー。各ページのURLの画像をクロールし、オープンRedisのサービスをホストし、URLがのために抽出された場合、RedisのURLが聞いているかどうか、ホストへのリモート接続からのRedis、RedisのマシンのコレクションにURLを保存するためにクロールすべてのURLを抽出してダウンロードされるまで画像をダウンロード。
第五に、メインコード
1.最初のコードは、美容アトラスURL内のすべてのページクロールであり、URLがデータベースに保存され、コレクションは、コードの重量にリンク先URLを使用することによって達成することができ、Redisのコレクションに本明細書中で使用されます次のように:
1 DEF get_page(URL): 2 "" " 3は、 各ページに美しさのポートフォリオの下にURLをクロール 4 :PARAMのURL:ページのURLを 5 :リターン: 6 " "" 7。 試し: 8 R&LT = Redisの(=ホスト" ローカルホスト"= 6379ポートは、DB = 1) 位のRedisを接続する 。9 time.sleep(はrandom.Random()) 10 RES = requests.get(URL、ヘッダー= ヘッダ) 。11 res.encoding = " UTF-8 " 12である ら= etree.HTML(res.text) 13であります href_list = et.xpath(' / HTML /本体/ DIV [5] / DIV [1] / DIV [1] / DIV [2] / UL /リー/ / HREF @ ' ) 14 のための HREF でhref_list: 15 HREF = " http://www.shu800.com " + HREF 16 r.sadd(" HREF "、HREF) #中保存到数据库 17 以外requests.exceptions: 18の ヘッダー[ " ユーザエージェント" ] = ua.random 19 get_page(URL)
2.あなたには、いくつかの直接の実行を待たない場合、それは、Pythonよりも再帰の深さに簡単ですので、私は設定しているため、コードの第二段落は、何もURLが存在しない場合、スレーブが実行する前に5秒待って、そこにRedisのURLコードかどうかを監視しています実行する前に、5秒待ちます。逆に、URLをRedisのに追加された場合、それはURLのクロールを抽出する必要がある、モジュールで使用される方法は、Redisのセットから要素を返すのRedis SPOP()メソッドです。URLが最初のターン列strに抽出された後ことに留意すべきです。
1 DEF get_urls(): 2 "" " 3 クロール抽出するがあれば何が実行された場合のRedis、URLが監視されていない 4 :リターン 5 " "" 6 IF B " HREF " でr.keys (): 7 しばらく真: 8 試し: 9 URL = r.spop(" HREF " ) 10 (URL = url.decode "UTF-8 ") #のユニコードトランスフェクトSTR 11。印刷(" URLをクロール:" 、URL) 12は GET_IMAGE(URL) 13である get_img_page(URL) 14 を除く: 15 IF B " HREF " はありません で()r.keys: #1 クロールプログラム終了 16 ブレーク 。17 他: 18である 続行 19。 他: 20である 時間。 SLEEP(5 ) 21である )(get_urls
第六に、営業成績
以下は9633にポートフォリオ全体をクロールするホストマスター、上で実行されているのスクリーンショットは、次のとおりです。
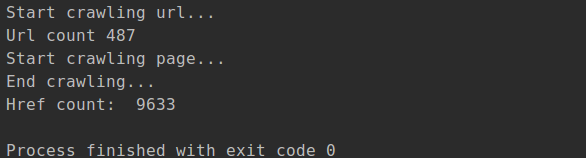
継続的クロールするURLデータベースのRedisから子機から抽出された、図ランタイムのスクリーンショットです。
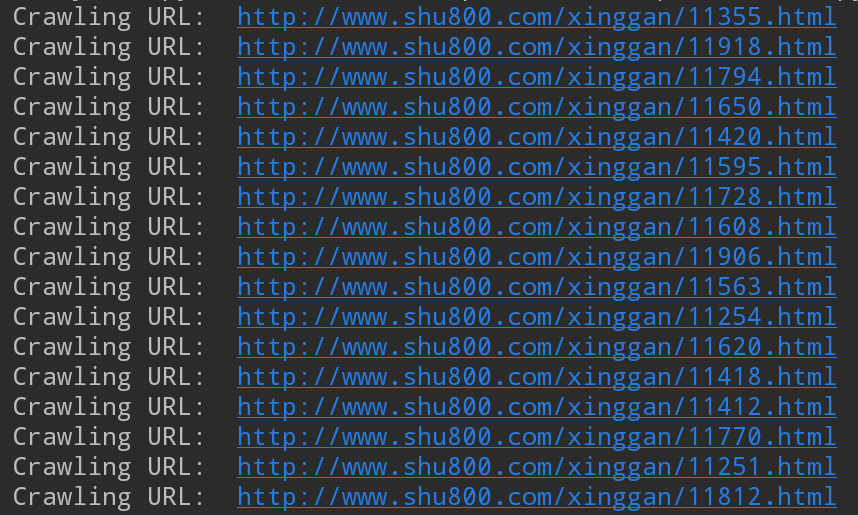
絵を下に登るために持っているものを見るためにフォルダを開きます(これはタイトル、少し難しいDingaです...)。
完全なコードはにアップロードされたGitHubの!