1、カフカアーキテクチャモデル
生産者、消費者の話題ブローカーの基本的な構造に基づいて、など

。5 、カフカのコンポーネントが導入します
トピック:メッセージはトピックによって分類されます
プロデューサー:によってメッセージを送信
消費者:メッセージの受信者
ブローカー:カフカの各インスタンス(サーバー)
飼育係:メタ情報を保存するには、クラスタに依存。
トピックスコンポーネント入門
トピック:メッセージのタイプ、トピックは、各パーティション(ゾーン)に分割クラスタ構成ファイル内に配置されています。
パーティション:ストレージ・レベルは、複数のセグメントファイルが含まれている論理アペンドログファイルです。
セグメント:実際のファイルのメッセージストアは、新しい生成していきます。
オフセット:ファイルの場所(オフセット)の各メッセージを。オフセットデジタルはそれだけでメッセージをマークである、長いです。
パーティション
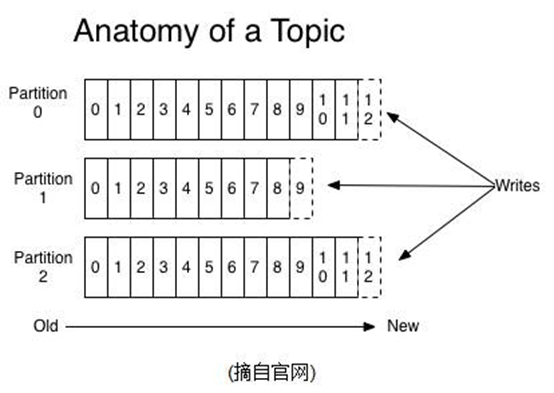
1、それは論理的なストレージレベルアペンド・ログ・ファイル、パーティションの複数からなる各セグメントです。
2、このパーティションには、ログファイルの末尾に直接追加されるすべてのニュースリリース。
3、各パーティションはメモリインデックスのリストに対応する、最初のメッセージセグメントの各レコードは、オフセット。最初のメッセージは、位置インデックスリストに配置されており、そのようなルックアップ・メッセージは、ファイル、ブロック速度を読み取ります。
図4に示すように、メッセージトピックを送信するために、パブリッシャが均等複数の部分に分配され、ブローカは、対応する部分に解放メッセージの最後のセグメントに受信したメッセージを追加します。
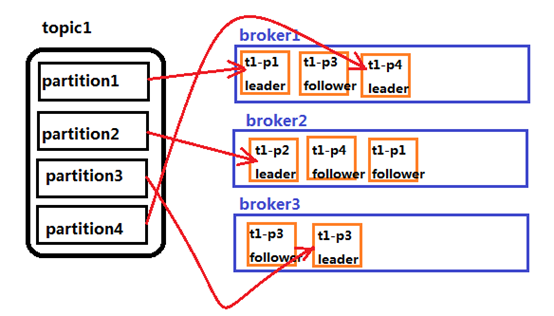
パーティションの分布
1、 partitions分区到不同的server上,一个partition保存在一个server上,避免一个server上的文件过大,同时可以容纳更多的consumer消费,有效提升并发消费的能力。
2、 这个server(如果保存的是partition的leader)负责partition的读写。可以配置备份。
3、 每个partition都有一个server为"leader",负责读写,其余的相对备份机为follower,follower同步leader数据,负责leader死了之后的接管。n个leader均衡的分散在每个server上。
4、 partition的leader和follower之间监控通过zookeeper完成。
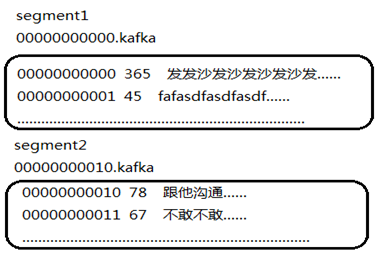
segment
1、 每个segment中存储多条消息,消息id由其逻辑位置决定,即从消息id可直接定位到消息的存储位置,避免id到位置的额外映射。
2、 当某个segment上的消息条数达到配置值或消息发布时间超过阈值时,segment上的消息会被flush到磁盘,只有flush到磁盘上的消息订阅者才能订阅到
3、 segment达到一定的大小(可以通过配置文件设定,默认1G)后将不会再往该segment写数据,broker会创建新的segment。

offset
offset是每条消息的偏移量。
segment日志文件中保存了一系列"log entries"(日志条目),每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";
每个日志文件都有一个offset来唯一的标记一条消息,offset的值为8个字节的数字,表示此消息在此partition中所处的起始位置.
每个partition在物理存储层面,有多个log file组成(称为segment).
segment file的命名为"最小offset".log.例如"00000000000.log";其中"最小offset"表示此segment中起始消息的offset.