ニューラルネットワーク勾配降下(ニューラルネットワークのための勾配降下)
このビデオでは、私はこの方程式があなたのニューラルネットワークのための正しいいくつかの具体的な勾配降下方程式を達成することであるなぜ我々は次のビデオで紹介します、あなたはバックプロパゲーション勾配降下方程式やアルゴリズムを達成与えます。
あなたの単一の隠れ層ニューラルネットワークは、あろうWである[1] 、B [1] 、Wは、[2] 、Bは[2]これらのパラメータは、存在するN- Xは、入力フィーチャの数を表し、N - [1]隠れユニットを表しを数は、N- [2]出力単位の数を表します。
私たちのケースでは、我々はこのような場合、パラメータで導入しました:
行列Wは、[1]の寸法(あるN- [1] 、N- [0] )、Bは[1]であるN- [1]次元ベクトルのように書くことができる(N- [1] 、図1)は、列ベクトルです。行列Wである[2]寸法が(N- [2] 、N- [1] )、B [2]の寸法は、(N- [2] 、1)寸法。
あなたはバイナリ分類タスクを行っていると仮定すると、コスト関数ニューラルネットワークを持っていますか、そして、あなたの費用関数は以下のようになります。
コスト関数:
公式:J(W [1] 、B [1] 、W [2] 、B [2] )= 1 m個I = 1 、M個のL (Y 、Y)
損失関数とやっ前ロジスティックまったく同じ回帰を。
トレーニングパラメータは、ニューラルネットワークを訓練するとき、ランダムな初期化パラメータではなく、すべてのゼロを初期化するよりも、重要であり、勾配降下を行う必要があります。あなたのパラメータは、いくつかの値に初期化されている場合、各サイクルは、以下の勾配降下予測値を計算します:

(前話さ)次のように前方伝播方程式は、次のとおり
前方伝播:

次のように逆伝搬方程式は以下のとおりです。
バックプロパゲーション:
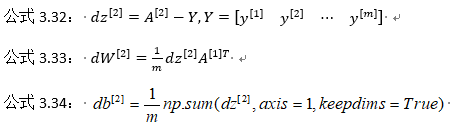
公式3.35:


上記ステップバックプロパゲーション。注:これらは、すべての量子化されたサンプルについて行われ、Yは、である1×M行列;ここでnp.sumはパイソンのnumpyのコマンド、軸= 1は、水平加算、keepdimsを示しPythonは、それらの奇数ランク数の出力防止することである(Nは、)アレイマトリックスことを確実にするためにこれを追加し、D B [2]この次元ベクトルが出力される(nは、1)この標準形。
これまでのところ、我々は計算しているとロジスティック回帰は非常に似ていますが、コンピューティングの普及を逆転し始めたとき、あなたは計算する必要があり、使用して中間層派生出力の関数であるシグモイドは、バイナリ分類関数です。ので、ここで要素を乗じた元素であり、Wは、[2] T D Z [2]及び(Zは[1] )の両方である(N- [1] 、M)マトリックス;
もう一つは、予防のpython、出力奇数順位番号を明示的に行列形式で書かれた出力np.sumを再構築起動する必要があります。
これらは、4つの方程式前方に伝播し、私が直接次のビデオに与えられた逆伝播方程式6、です、私は逆伝播のこれらの6つの方程式をエクスポートする方法を教えてくれます。あなたはこれらのアルゴリズムを実装する場合は、あなたが前方に正しいと逆拡散操作を実行する必要があり、あなたは、ニューラルネットワークのパラメータを学習するすべてのデリバティブ、勾配降下のニーズを計算することができなければなりません。あなたが直接、同じ深さの成功実践者の多くを学ぶことができますこのアルゴリズムを実装して、我々は彼らの知識を理解していません。
ランダム初期化(ランダム+初期化)
あなたは、ニューラルネットワークを訓練すると、ランダムな重みの初期化は非常に重要です。ロジスティック回帰のために、重みももちろん可能のゼロに初期化されています。あなたはパラメータが0に初期化されている重みを置いた場合でも、ニューラルネットワークのために、または、その後、勾配降下は動作しません。
のはなぜ見てみましょう。請求が2つの入力があり、N- [0] = 2、2隠れ層ユニットN- [1] 2であるが。したがって1つの隠れ層のマトリックスに関連付けられた、またはWである[1] 2×2の行列であり、2×2行列を0に初期化されているものとし、B [1]とも等しい[0 0 ] T、バイアス用語bが 0に初期化され合理的であるが、Wゼロに初期化は問題があるでしょう。あなたは、この問題が初期化されるように従っている場合、あなたは常にあります1 [1] 及び2 [1]と等しく、この活性化ユニットとユニットが同じにアクティブになります。2つの隠しユニットが同一の関数で算出しますので、逆伝播計算を行う場合、DZをもたらす。1 [1] とDZ 2 [1]は同じになり、これらの隠れユニットは対称性が、それを持っている初期化するように出力これは、それにより、正確に同じ重みであろうWである[2]に等しくなる[00] 。

图3.11.1 但是如果你这样初始化这个神经网络,那么这两个隐含单元就会完全一样,因此他们完全对称,也就意味着计算同样的函数,并且肯定的是最终经过每次训练的迭代,这两个隐含单元仍然是同一个函数,令人困惑。dW 会是一个这样的矩阵,每一行有同样的值因此我们做权重更新把权重W[1]⟹W[1]-adW 每次迭代后的W[1] ,第一行等于第二行。
由此可以推导,如果你把权重都初始化为0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管你训练网络多长时间,隐含单元仍然计算的是同样的函数。因此这种情况下超过1个隐含单元也没什么意义,因为他们计算同样的东西。当然更大的网络,比如你有3个特征,还有相当多的隐含单元。
如果你要初始化成0,由于所有的隐含单元都是对称的,无论你运行梯度下降多久,他们一直计算同样的函数。这没有任何帮助,因为你想要两个不同的隐含单元计算不同的函数,这个问题的解决方法就是随机初始化参数。你应该这么做:把W[1] 设为np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如0.01,这样把它初始化为很小的随机数。然后b 没有这个对称的问题(叫做symmetry breaking problem),所以可以把 b 初始化为0,因为只要随机初始化W 你就有不同的隐含单元计算不同的东西,因此不会有symmetry breaking问题了。相似的,对于W[2] 你可以随机初始化,b[2] 可以初始化为0。
W1=np.random.randn2,2 * 0.01 ,
b[1]=np.zeros((2,1))
W[2]=np.random.randn(2,2) * 0.01 , b[2]=0
你也许会疑惑,这个常数从哪里来,为什么是0.01,而不是100或者1000。我们通常倾向于初始化为很小的随机数。因为如果你用tanh或者sigmoid激活函数,或者说只在输出层有一个Sigmoid,如果(数值)波动太大,当你计算激活值时z[1]=W[1]x+b[1] , a[1]=σ(z[1])=g[1](z[1]) 如果W 很大,z 就会很大。z 的一些值a 就会很大或者很小,因此这种情况下你很可能停在tanh/sigmoid函数的平坦的地方(见图3.8.2),这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
回顾一下:如果w 很大,那么你很可能最终停在(甚至在训练刚刚开始的时候)z 很大的值,这会造成tanh/Sigmoid激活函数饱和在龟速的学习上,如果你没有sigmoid/tanh激活函数在你整个的神经网络里,就不成问题。但如果你做二分类并且你的输出单元是Sigmoid函数,那么你不会想让初始参数太大,因此这就是为什么乘上0.01或者其他一些小数是合理的尝试。对于w[2] 一样,就是np.random.randn((1,2)),我猜会是乘以0.01。
事实上有时有比0.01更好的常数,当你训练一个只有一层隐藏层的网络时(这是相对浅的神经网络,没有太多的隐藏层),设为0.01可能也可以。但当你训练一个非常非常深的神经网络,你可能会选择一个不同于的常数而不是0.01。下一节课我们会讨论怎么并且何时去选择一个不同于0.01的常数,但是无论如何它通常都会是个相对小的数。
好了,这就是这周的视频。你现在已经知道如何建立一个一层的神经网络了,初始化参数,用前向传播预测,还有计算导数,结合反向传播用在梯度下降中。