
著者|Invisible (Xing Ying)、NetEase シニア データベース カーネル エンジニア
編集・仕上げ|SelectDBテクニカルチーム
はじめに: NetEase の重要な事業分野として、Lingxi Office と Yunxin は、大規模なログ/時系列データの処理と分析の課題に対処するために、Lingxi Eagle 監視プラットフォームと Yunxin データ プラットフォームをそれぞれ構築しました。この記事では、NetEase ログと時系列シナリオでのApache Dorisのアプリケーションと、Apache Doris を使用して Elasticsearch と InfluxDB を置き換える方法に焦点を当てます。これにより、Elasticsearch と比較して、Apache Doris のクエリ速度が向上し、サーバー リソースが削減され、クエリ パフォーマンスが向上します。少なくとも 11 倍向上し、ストレージ リソースを最大 70% 節約します。
情報技術の急速な発展に伴い、企業データの量は爆発的に増加しました。 NetEase のような大規模なインターネット企業では、社内のオフィス システムであっても、外部が提供するサービスであっても、大量のログと時系列データが毎日生成されます。これらのデータは、トラブルシューティング、問題診断、セキュリティ監視、リスク警告、ユーザー行動分析、エクスペリエンスの最適化のための重要な基礎となっています。これらのデータの価値を最大限に活用することで、製品の信頼性、性能、安全性、ユーザー満足度の向上につながります。
NetEase の重要な事業分野として、Lingxi Office と Yunxin は、大規模なログ/時系列データの処理と分析によってもたらされる課題に対処するために、Lingxi Eagle 監視プラットフォームと Yunxin データ プラットフォームをそれぞれ構築しました。ビジネスが拡大し続けるにつれて、ログ/時系列データも急激に増加し、ストレージ コストの増加、クエリ時間の延長、システムの安定性の低下などの問題が発生しています。初期のプラットフォームは持続不可能だったため、NetEase はより良いソリューションを探すことになりました。
この記事では、NetEase ログおよび時系列シナリオでの Apache Doris の実装に焦点を当て、NetEase Lingxi Office および NetEase Cloud Letter ビジネスでの Apache Doris のアーキテクチャ アップグレードの実践を紹介し、テーブルの作成、インポート、クエリなどの経験を共有します。実際のシナリオに基づいたチューニング計画。
初期のアーキテクチャと問題点
01 Lingxi-Eagle 監視プラットフォーム
NetEase Lingxi Office は、新世代の電子メール共同オフィス プラットフォームです。電子メール、カレンダー、クラウド ドキュメント、インスタント メッセージング、顧客管理などのモジュールを統合します。 Eagle 監視プラットフォームは、NetEase Lingxi Office に多次元でさまざまな粒度のパフォーマンス分析を提供できるフルリンク APM システムです。
Eagle 監視プラットフォームは主に、Lingxi Office、Enterprise Email、Youdao Cloud Notes、Lingxi Documents などのビジネス ログ データを保存および分析します。ログ データは、まず Logstash を通じて収集および処理され、次にリアルタイム ログを実行する Elasticsearch に保存されます。また、Lingxi Office のログ検索およびフルリンク ログ クエリ サービスも提供します。

時間が経ち、ログ データが増大するにつれて、Elasticsearch を使用するプロセスでいくつかの問題が徐々に明らかになります。
- クエリのレイテンシが高い: 毎日のクエリでは、Elasticsearch の平均応答レイテンシが高く、ユーザー エクスペリエンスに影響を与えます。これは主に、データのサイズ、インデックス設計の合理性、ハードウェア リソースなどの要因によって制限されます。
- 高いストレージ コスト: コスト削減と効率向上の観点から、企業はストレージ コストを削減する必要性がますます高まっています。しかし、Elasticsearchは順列ストレージ、逆行ストレージ、列ストレージなどの複数のデータストアを備えているため、データの冗長性が高く、コスト削減や効率向上に一定の課題を抱えています。
02 Yunxin-データプラットフォーム
NetEase Yunxin は、NetEase の 26 年間のテクノロジーに基づいて構築されたコンバージド コミュニケーションおよびクラウド ネイティブの PaaS サービスのエキスパートで、IM インスタント メッセージング、ビデオ クラウド、SMS、青州マイクロサービス、ミドルウェア PaaS などのコンバージド コミュニケーションおよびクラウド ネイティブのコア製品とソリューションを提供しています。 。 待って。
Yunxin データ プラットフォームは、主に IM、RTC、SMS およびその他のサービスによって生成された時系列データを分析します。初期のデータ アーキテクチャは、主に時系列データベース InfluxDB に基づいて構築されました。データ ソースは最初に Kafka メッセージ キューを通じて報告され、フィールドの解析とクリーニングの後、時系列データベース InfluxDB に保存されて、オンライン クエリとオフライン クエリが提供されました。オフライン側はオフライン T+1 データ分析をサポートし、リアルタイム側は指標監視レポートと請求書のリアルタイム生成を提供する必要があります。
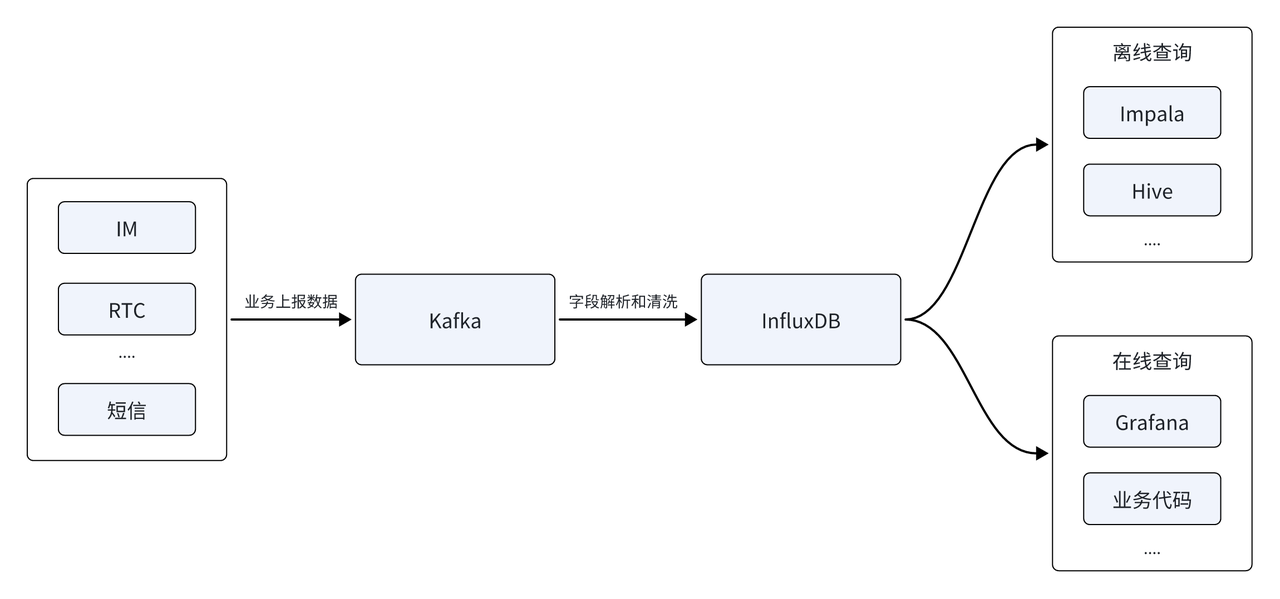
顧客規模の急速な拡大に伴い、報告されるデータ ソースの数は増加し続けており、InfluxDB は一連の新たな課題にも直面しています。
- メモリ オーバーフロー OOM: データ ソースの数が増えると、複数のデータ ソースに基づいてオフライン分析を実行する必要があり、分析の難易度が上がります。現在のアーキテクチャは、InfluxDB のクエリ機能によって制限されているため、複数のデータ ソースからの複雑なクエリに直面するとメモリ不足 (OOM) を引き起こす可能性があり、ビジネスの可用性とシステムの安定性に大きな課題をもたらします。
- 高いストレージ コスト: ビジネスの発展により、クラスターのデータ量も継続的に増加しており、クラスター内のデータの大部分はコールド データであり、ホット データとコールド データが同じ方法で保存されるため、ストレージ コストが高くなります。これはコスト削減と相いれず、効果的な企業目標との矛盾が増大します。
コアエンジンの選択
このため、NetEase は、ログ タイミング シナリオにおいて上記 2 つの主要企業が直面する課題を解決することを目的として、新しいデータベース ソリューションを探し始めました。同時に、NetEase は 1 つのデータベースのみを使用して、2 つの主要なアプリケーション シナリオのビジネス システムと技術アーキテクチャに適応し、非常に使いやすく、低投資というアップグレード ニーズに応えたいと考えています。この点で、Apache Doris は、特に次の点で当社の選択要件を満たしています。
- ストレージ コストの最適化: Apache Doris は、冗長ストレージを削減するためにストレージ構造に多くの最適化を行いました。圧縮率が高く、S3 および NOS (Netease Object Storage) に基づくホットおよびコールドの階層型ストレージをサポートしているため、ストレージ コストを効果的に削減し、データ ストレージ効率を向上させることができます。
- 高スループットと高性能: Apache Doris は、カラムナ ストレージの高性能ディスク書き込み、シーケンシャル コンパクション、および Stream Load の効率的なストリーミング インポートをサポートし、1 秒あたり数十 GB のデータ書き込みをサポートできます。これにより、ログ データの大規模な書き込みが保証されるだけでなく、低遅延のクエリの可視性も提供されます。
- リアルタイムのログ取得: Apache Doris は、ログ テキストの全文取得をサポートするだけでなく、リアルタイムのクエリ応答も可能にします。 Doris は、内部的に転置インデックスの追加をサポートしています。これにより、文字列型の全文検索と、通常の数値/日付型の同等および範囲の取得が可能になります。同時に、転置インデックスのクエリ パフォーマンスをさらに最適化し、パフォーマンスを向上させることができます。ログデータ分析の要件に適しています。
- 大規模なテナント分離のサポート: Doris は、数千のデータベースと数万のデータ テーブルをホストでき、1 つのテナントが 1 つのデータベースを独立して使用できるようにして、マルチテナントのデータ分離のニーズを満たし、データのプライバシーとセキュリティを確保します。
さらに、過去 1 年間、Apache Doris はログ シナリオの掘り下げを続け、効率的な逆インデックス、柔軟なバリアント データ型などの一連のコア機能を開始して、ログ/時間のより適切な処理と分析を提供しました。シリーズデータ。効率的で柔軟なソリューション。上記の利点に基づいて、NetEase は最終的に新しいアーキテクチャのコア エンジンとして Apache Doris を導入することを決定しました。
Apache Doris に基づく統合ログ ストレージおよび分析プラットフォーム
01 Lingxi-Eagle 監視プラットフォーム

まず、Lingxi Office-Eagle 監視プラットフォームにおいて、NetEase は Elasticsearch を Apache Doris にアップグレードすることに成功し、それによって統合されたログ ストレージおよび分析プラットフォームを構築しました。このアーキテクチャのアップグレードにより、プラットフォームのパフォーマンスと安定性が大幅に向上するだけでなく、強力で効率的なログ取得サービスも提供されます。具体的な利点は以下に反映されます。
- ストレージ リソースが 70% 節約されます: Doris 列ストレージと ZSTD の高い圧縮率のおかげで、Elasticsearch は同じログ データを保存するのに 100T のストレージ スペースを必要としますが、Doris に保存するのに必要なストレージ スペースは 30T だけで、70T を節約できます。ストレージ リソースの %。ストレージ スペースが大幅に節約されるため、同じコストで HDD の代わりに SSD を使用してホット データを保存でき、クエリ パフォーマンスも大幅に向上します。
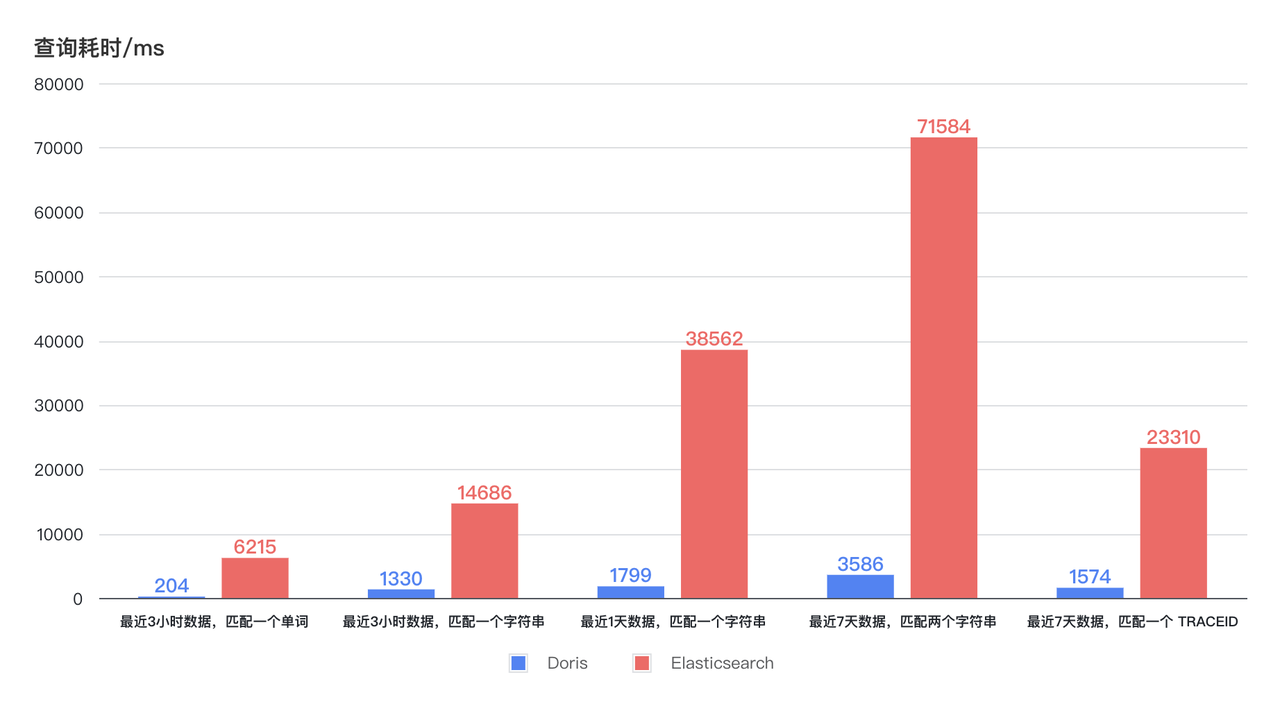
- クエリが 11 倍高速化: 新しいアーキテクチャにより、CPU リソースの消費量が削減され、クエリ効率が数十倍向上しました。以下の図からわかるように、過去 3 時間、1 日、および 7 日間のログ取得の Doris クエリ時間は安定して 4 秒未満であり、最速の応答は 1 秒以内である可能性があります。 Elasticsearch のクエリ時間は変動が大きく、最長でも 75 秒、最短でも 6 ~ 7 秒かかります。リソース使用量が少ないため、Doris のクエリ効率は Elasticsearch の少なくとも 11 倍です。
02 Yunxin-データプラットフォーム
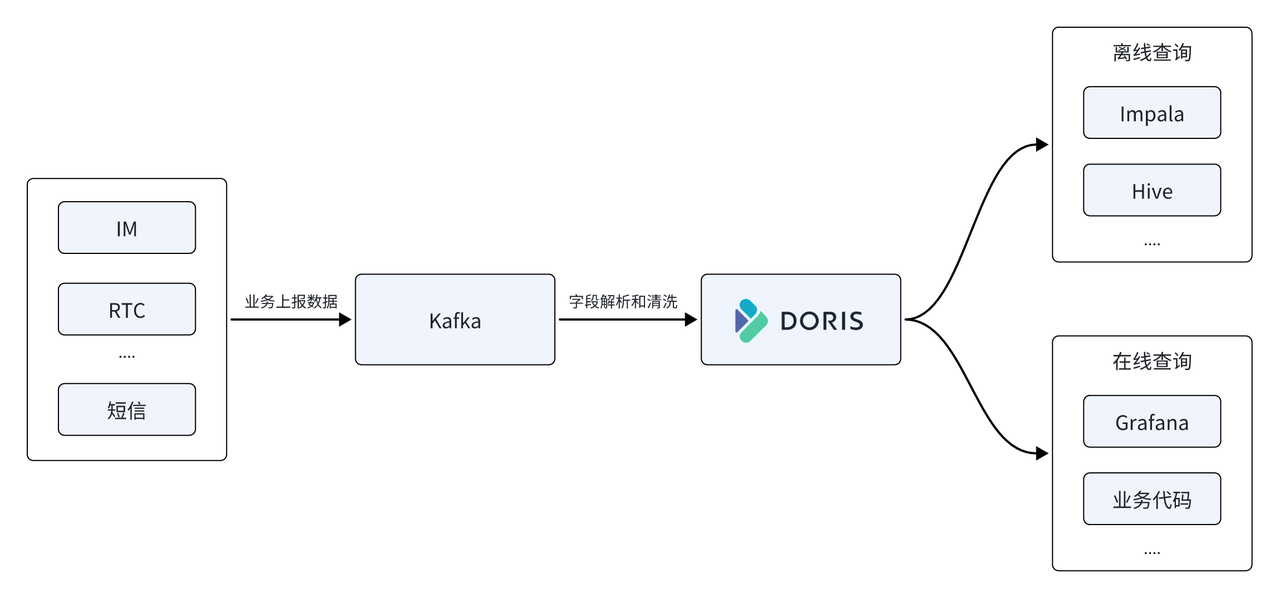
Yunxin データ プラットフォームでは、NetEase も Apache Doris を使用して初期のアーキテクチャの時系列データベース InfluxDB を置き換え、データ プラットフォームのコア ストレージおよびコンピューティング エンジンとして使用します。また、Apache Doris は統合されたオフラインおよびリアルタイムのクエリ サービスを提供します。
- 高スループットの書き込みをサポート: 平均オンライン書き込みトラフィックは 500M/s、ピーク 1GB/s、InfluxDB は 22 台のサーバーを使用し、CPU リソース使用率は約 50% ですが、Doris は 11 台のマシンのみを使用し、CPU 使用率は約 50% です。全体的なリソース消費量は以前のわずか 1/2 です。
- ストレージ リソースが 67% 節約されました: 22 台の InfluxDB を置き換えるために 11 台の Doris 物理マシンが使用されました。同じ規模のデータを保存するには、InfluxDB には 150T のストレージ スペースが必要ですが、Doris に保存する場合は 50T のストレージ スペースしか必要とせず、ストレージ リソースが 67% 節約されます。
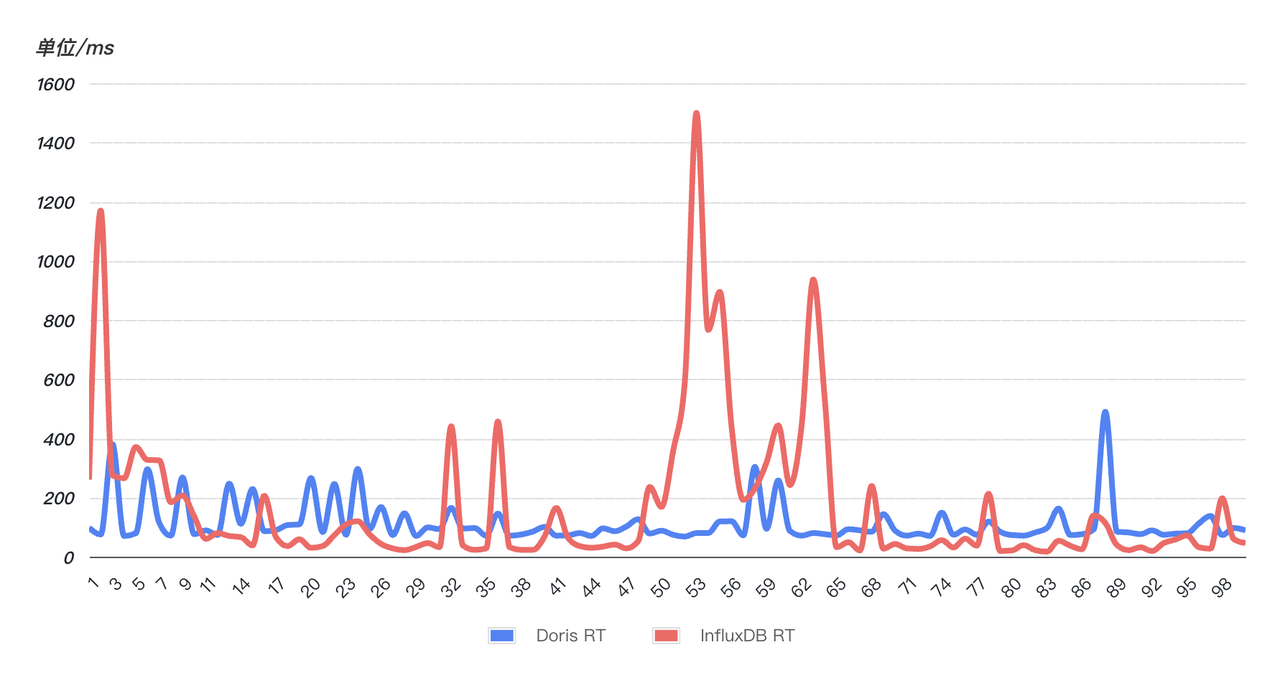
- クエリの応答が速く、より安定しています: クエリの応答速度を検証するために、オンライン SQL がランダムに選択され (過去 10 分間の文字列と一致)、SQL が 99 回連続してクエリされました。以下の図からわかるように、Doris (青) のクエリ パフォーマンスは InfluxDB (赤) よりも安定しています。99のクエリは比較的安定しており、明らかな変動はありません。ただし、InfluxD では複数の異常な変動が発生しています。クエリ時間が急増し、クエリの安定性に重大な影響が出ています。
練習とチューニング
ビジネスを実行する過程で、NetEase はいくつかの問題や課題にも遭遇しました。この機会を利用して、これらの貴重な最適化の経験を編集して共有し、皆様の使用に役立つガイダンスと支援を提供したいと考えています。
01 テーブル作成の最適化
データベース スキーマの設計はパフォーマンスにとって重要であり、ログ データや時系列データを扱う場合も例外ではありません。 Apache Doris は、これら 2 つのシナリオに特化した最適化オプションをいくつか提供しているため、テーブルの作成時にこれらの最適化オプションを有効にすることが重要です。実際に使用する具体的な最適化オプションは次のとおりです。
- DATETIME 型の時刻フィールドを主キーとして使用すると、最新の n 個のログのクエリ速度が大幅に向上します。
- 時間フィールドに基づいた RANGE パーティショニングを使用し、動的 Partiiton を有効にしてパーティションを毎日自動的に管理し、データ クエリと管理の柔軟性を向上させます。
- バケット化戦略に関しては、ランダム バケット化に RANDOM を使用でき、バケットの数はクラスター ディスクの総数のおよそ 3 倍に設定されます。
- 頻繁にクエリが実行されるフィールドの場合は、クエリの効率を向上させるためにインデックスを構築することをお勧めします。また、全文検索が必要なフィールドの場合は、検索の精度と効率を確保するために、適切な単語セグメンタ パラメータ パーサーを指定する必要があります。
- ログおよび時系列のシナリオでは、特別に最適化された時系列圧縮戦略が使用されます。
- ZSTD 圧縮を使用すると、より優れた圧縮効果が得られ、ストレージ領域を節約できます。
CREATE TABLE log
(
ts DATETIME,
host VARCHAR(20),
msg TEXT,
status INT,
size INT,
INDEX idx_size (size) USING INVERTED,
INDEX idx_status (status) USING INVERTED,
INDEX idx_host (host) USING INVERTED,
INDEX idx_msg (msg) USING INVERTED PROPERTIES("parser" = "unicode")
)
ENGINE = OLAP
DUPLICATE KEY(ts)
PARTITION BY RANGE(ts) ()
DISTRIBUTED BY RANDOM BUCKETS 250
PROPERTIES (
"compression"="zstd",
"compaction_policy" = "time_series",
"dynamic_partition.enable" = "true",
"dynamic_partition.create_history_partition" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-7",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "250"
);
02 クラスタ構成の最適化
FE構成
# 开启单副本导入提升导入性能
enable_single_replica_load = true
# 更加均衡的tablet分配和balance测量
enable_round_robin_create_tablet = true
tablet_rebalancer_type = partition
# 频繁导入相关的内存优化
max_running_txn_num_per_db = 10000
streaming_label_keep_max_second = 300
label_clean_interval_second = 300
BE 構成
write_buffer_size=1073741824
max_tablet_version_num = 20000
max_cumu_compaction_threads = 10(cpu的一半)
enable_write_index_searcher_cache = false
disable_storage_page_cache = true
enable_single_replica_load = true
streaming_load_json_max_mb=250
03 ストリームロードインポートチューニング
ビジネスのピーク時には、Yunxin-data プラットフォームは 100 万を超える書き込み TPS と 1 GB/秒を超える書き込みトラフィックに直面しており、システム パフォーマンスに対して非常に高い要求が課せられることは間違いありません。ただし、ビジネス側には小さな同時テーブルが多数あり、クエリ側にはデータに対するリアルタイム性の要件が非常に高いため、バッチ処理を短時間で十分な大きさの Batch に蓄積することは不可能です。ビジネス関係者と共同で一連の最適化を実施した後も、Stream Load は依然として Kafka のデータを迅速に消費できず、その結果、Kafka でのデータ バックログがますます深刻になります。
詳細な分析の結果、ビジネスのピーク時に、ビジネス側のデータ インポート プログラムがパフォーマンスのボトルネックに悩まされていたことが判明しました。これは、主に CPU およびメモリ リソースの過度の占有に反映されています。ただし、Doris 側のパフォーマンスにはまだ大きなボトルネックは見られませんが、Stream Load の応答時間には明らかな上昇傾向があります。
業務プログラムは Stream Load を同期的に呼び出すため、Stream Load の応答速度が全体のデータ処理効率に直接影響します。したがって、単一のストリーム ロードの応答時間を効果的に短縮できれば、システム全体のスループットが大幅に向上します。
Apache Doris コミュニティの学生とコミュニケーションを取った後、Doris がログとタイミングのシナリオに対して 2 つの重要なインポート パフォーマンスの最適化を開始したことを知りました。
- 単一コピーのインポート: 最初に 1 つのコピーに書き込み、他のコピーが最初のコピーからデータをプルします。この方法では、複数のコピーのソートとインデックス構築を繰り返すことによって生じるオーバーヘッドを回避できます。
- シングルタブレットインポート:通常モードで複数のタブレットにデータを分散して書き込む方法と比較して、一度に1つのタブレットにのみ書き込む戦略を採用できます。この最適化により、書き込み中に生成される小さなファイルの数と IO オーバーヘッドが削減され、全体的なインポート効率が向上します。この機能は、インポート中
load_to_single_tabletにパラメータを に設定することでtrue有効にできます。
上記の方法を使用して最適化した後、インポートのパフォーマンスが大幅に向上しました。
- Kafkaの消費速度が2倍以上に向上
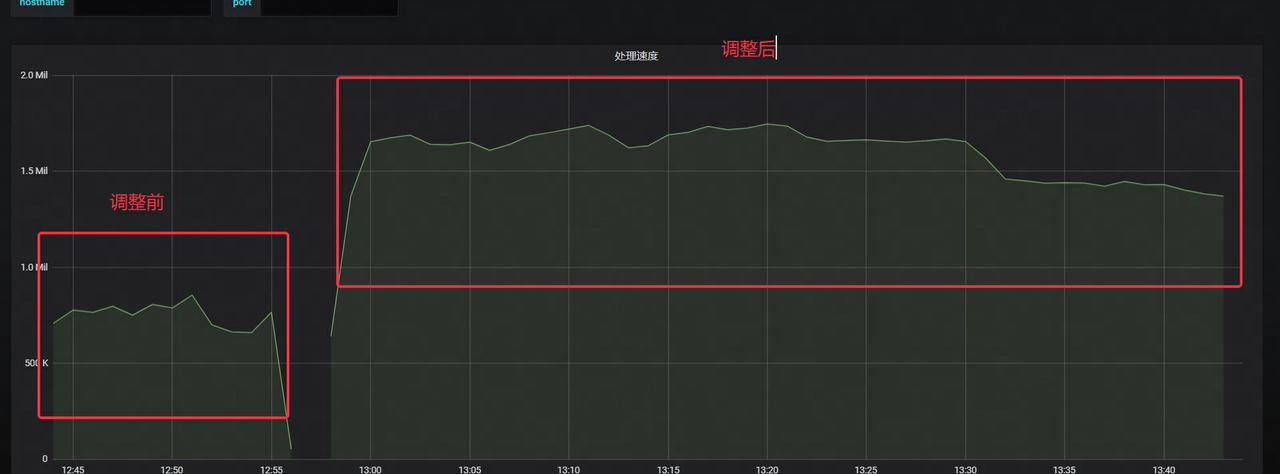
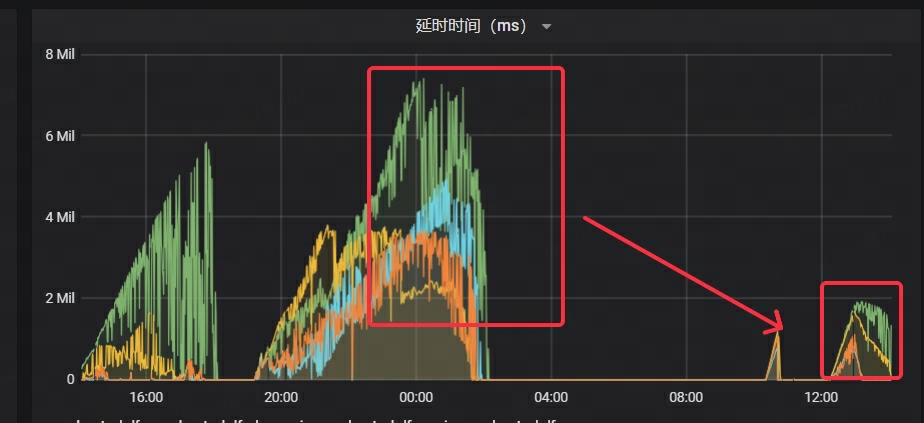
- Kafka のレイテンシは大幅に短縮され、元の時間のわずか 1/4 になりました。
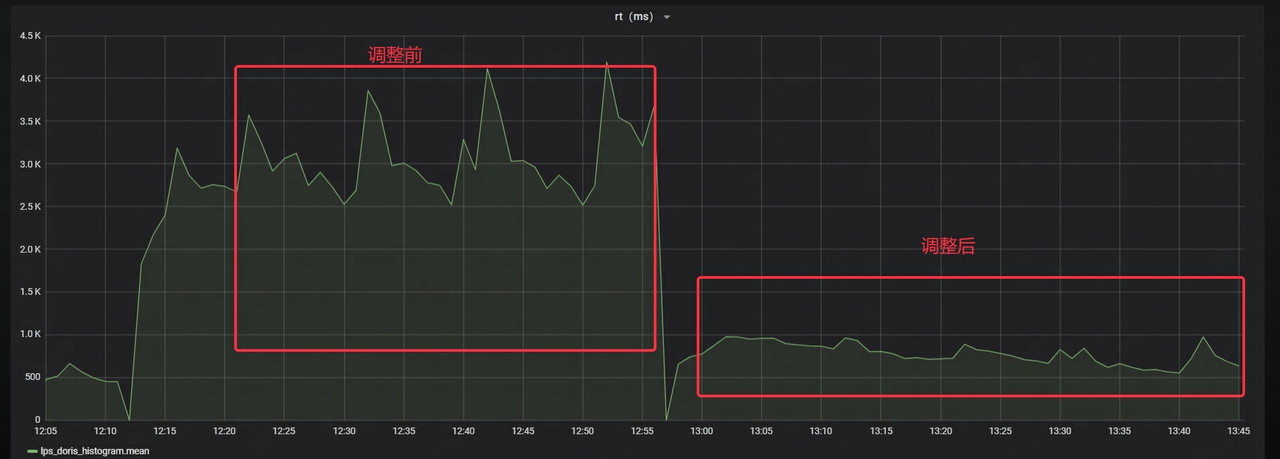
- ストリーム負荷のRTが約70%削減
NetEase は、正式リリース前に重度のストレス テストとグレースケールの試行運用も実施し、継続的な最適化作業を経て、最終的に大規模なシナリオでもシステムがオンラインで安定して動作できることを確認し、ビジネスを強力にサポートしました。
1. ストリーム読み込みタイムアウト:
ストレステスト開始当初は、データインポートのタイムアウトやエラーレポートが頻繁に発生する問題があり、プロセスやクラスタの状態が正常な場合、監視でBEのメトリクスデータが正常に収集できないという問題がありました。
Pstack を通じて Doris BE のスタックを取得し、PT-PMT を使用してスタックを分析します。主な理由は、クライアントがリクエストを開始したときに HTTP チャンク エンコーディングも Content-Length も設定されていなかったため、Doris がデータ送信がまだ終了していないと誤って信じ込み、待機状態が続いたことであることが判明しました。州。クライアントにチャンクエンコーディング設定を追加すると、データのインポートが通常に戻りました。
2. Stream Load によって一度にインポートされるデータの量がしきい値を超えています。
streaming_load_json_max_mbこの問題は、パラメータを 250M (デフォルトは 100M) に増やすことで解決されます。
3. コピー数不足と書き込みエラー: alive replica num 0 < quorum replica num 1
show backends1 つの BE が異常な状態にあり、OFFLINE と表示されていることがわかります。対応するbe_custom構成ファイルを確認し、存在することを確認しますbroken_storage_path。 BE のログをさらに詳しく調べたところ、エラー メッセージが「オープン ファイルが多すぎます」を示していることが判明しました。これは、BE プロセスによってオープンされたファイル ハンドルの数がシステムによって設定された最大数を超え、IO 操作が失敗したことを意味します。
Doris システムはこの異常を検出すると、ディスクを使用不可としてマークします。テーブルはシングルコピー戦略で構成されているため、コピーのみが存在するディスクに障害が発生した場合、コピー数が不足し、データの書き込みを継続できなくなります。
そのため、プロセス FD の最大オープン制限が 100 万に調整され、be_custom.conf構成ファイルが削除され、BE ノードが再起動され、最終的にサービスは通常の動作を再開しました。
4. FEメモリジッター
ビジネスグレースケールテスト中にFEに接続できない問題が発生しました。監視データを確認したところ、JVMの32Gメモリが枯渇し、FEメタディレクトリ内のbdbファイルディレクトリが50Gに異常拡張していることが分かりました。
ビジネスでは高度な同時ストリーム ロード データ インポート操作が実行されており、FE はインポート プロセス中に関連するロード情報を記録するため、各インポートによって生成されるメモリ情報は約 200K になります。これらのメモリ情報のクリーニング時間はstreaming_label_keep_max_secondパラメータによって制御されます。デフォルト値は 12 時間で、これを 5 分に調整すると、一定期間実行するとメモリが枯渇することがわかります。 1 時間周期に応じたジッターが発生し、ピークメモリ使用率は 80% に達します。コードを分析した結果、ラベルをクリーンアップするスレッドがlabel_clean_interval_second1 時間おきに実行されることがわかりました。これを 5 分に調整すると、FE メモリが非常に安定しました。
04 クエリチューニング
Lingxi-Eagle 監視プラットフォームがクエリ テストを実行しているときに、一致条件を満たさない結果が読み取られたのではないかと疑われました。この現象は明らかに予想される検索ロジックに準拠していませんでした。以下の最初のレコードに示すように:
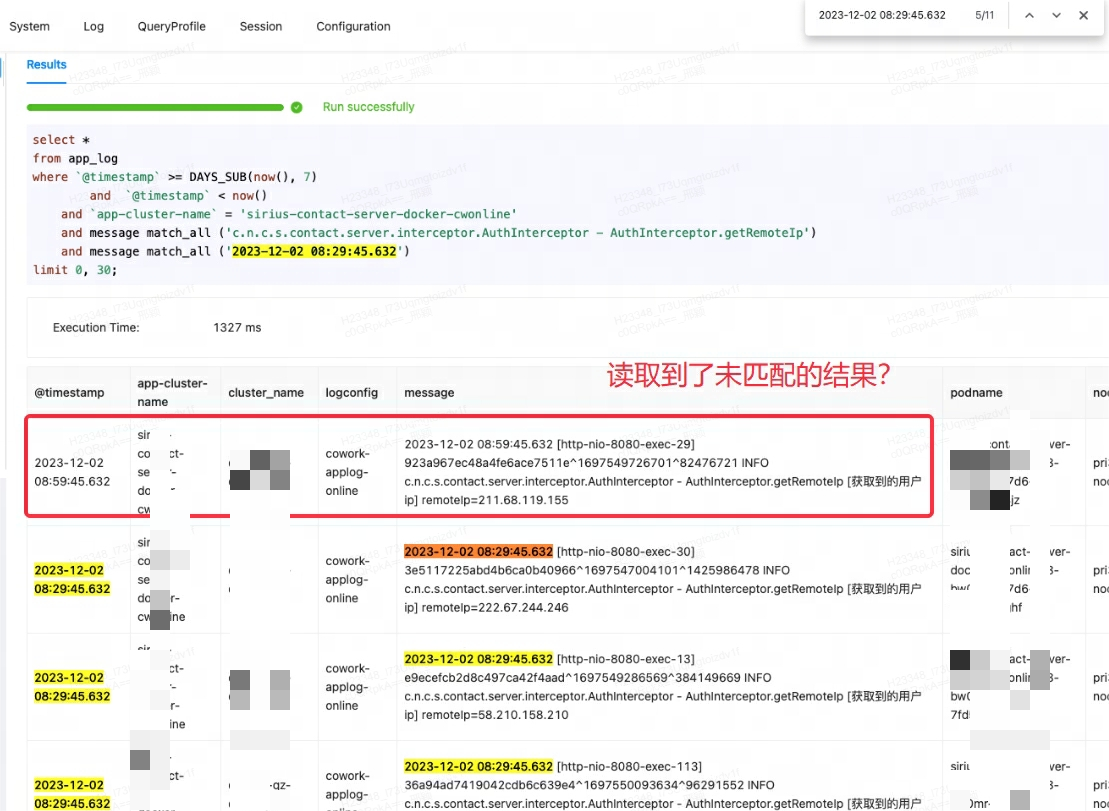
最初はドリスのバグだと勘違いし、同様の問題や回避策を探してみました。しかし、コミュニティ メンバーに相談し、公式ドキュメントを注意深く検討した結果、問題の根本はmatch_all使用シナリオの誤解であることが判明しました。
match_allの動作原理は、単語の分割が存在する限り照合を実行でき、単語の分割はスペースまたは句読点に基づいています。この場合、match_allの '29' は最初のレコードの後続の内容の '29' と一致するため、予期しない結果が出力されます。
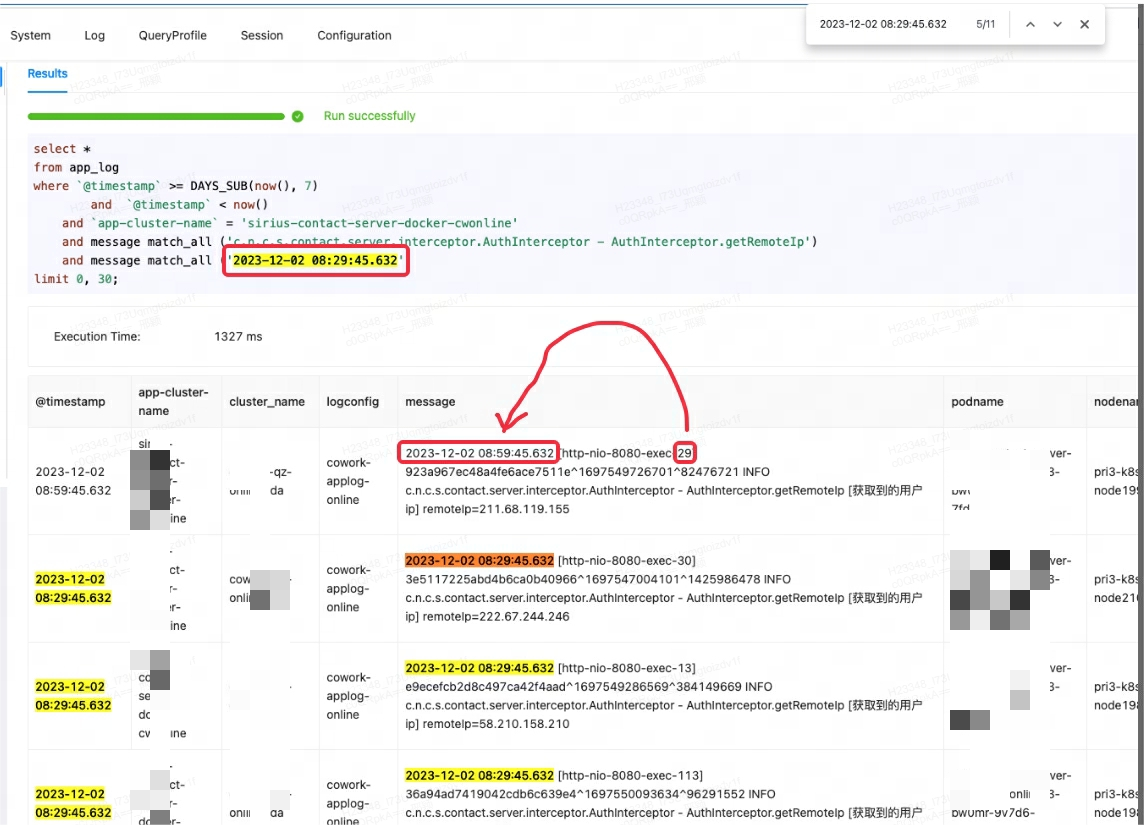
このケースでは、テキスト内の順序要件を満たすことができるMATCH_PHRASEマッチングに使用するのが正しい方法です。MATCH_PHRASE
-- 1.4 logmsg中同时包含keyword1和keyword2的行,并且按照keyword1在前,keyword2在后的顺序
SELECT * FROM table_name WHERE logmsg MATCH_PHRASE 'keyword1 keyword2';
マッチングを使用する場合はMATCH_PHRASE、インデックスの構築時に指定する必要がありますsupport_phrase。指定しない場合、システムはテーブル全体のスキャンを実行してハード マッチングを実行し、クエリ効率が低下します。
INDEX idx_name4(column_name4) USING INVERTED PROPERTIES("parser" = "english|unicode|chinese", "support_phrase" = "true")
すでにデータが書き込まれているテーブルの場合、これを有効にするにはsupport_phrase、DROP INDEX古いインデックスを削除して、ADD INDEX新しいインデックスを追加します。このプロセスは、テーブル全体のデータを書き換えることなく、既存のテーブルに対して段階的に実行されるため、操作の効率が確保されます。
Elasticsearch と比較して、Doris のインデックス管理方法はより柔軟であり、ビジネス ニーズに応じてインデックスを迅速に追加または削除できるため、利便性と柔軟性が向上します。
結論
Apache Doris の導入により、NetEase のログとタイミング シナリオのニーズが効果的に満たされ、NetEase Lingxi Office および NetEase Cloud Letter の初期のログ処理および分析プラットフォームの高いストレージ コストと低いクエリ効率の問題が効果的に解決されます。
実際のアプリケーションでは、Apache Doris は、より低いサーバー リソースで平均 500MB/s のオンライン書き込みトラフィック、ピーク値で 1GB/s 以上を伝送しました。同時に、クエリの応答も Elasticsearch と比較して大幅に向上し、クエリ効率が少なくとも 11 倍向上しました。さらに、Doris は圧縮率が高く、以前と比べてストレージ リソースを 70% 節約できます。
最後に、継続的なサポートをしていただいたSelectDB 技術チームに心より感謝いたします。将来的に、NetEase はApache Dorisの推進を継続し、NetEase の他のビッグ データ シナリオに Apache Doris を徹底的に適用する予定です。同時に、Apache Doris の開発を共同で推進するために、Doris に関心を持つより多くのビジネス チームとの深い交流を期待しています。
オープンソースの貢献
ビジネスの実装と問題のトラブルシューティングのプロセス中に、NetEase の学生はオープンソースの精神を積極的に実践し、Apache Doris コミュニティに一連の貴重な PR を提供して、コミュニティの開発と進歩を促進しました。
- ストリームロードのバグ修正
- ストリームロードコードの最適化
- 適切な Rowset 最適化を見つけるためのホットおよびコールド層別化
- ホット層とコールド層化により無効な走査が減少します
- ホットおよびコールドの階層型ロック間隔の最適化
- ホットおよびコールドの階層化データ フィルタリングの最適化
- 高温・低温成層能力判定の最適化
- ホットおよびコールド階層ソートの最適化
- FE エラー報告の標準化
- 新
array_agg機能 - 集計関数のバグ修正
- 実行計画のバグ修正
- タスクグループマネージャーの最適化
- BE クラッシュ修理
- 文書の変更:
- https://github.com/apache/dris/pull/26958
- https://github.com/apache/dris/pull/26410
- https://github.com/apache/dris/pull/25082
- https://github.com/apache/dris/pull/25075
- https://github.com/apache/dris/pull/31882
- https://github.com/apache/dris/pull/30654
- https://github.com/apache/dris/pull/30304
- https://github.com/apache/dris/pull/29268