
Alibaba Cloud と Tencent Cloud はどちらも、コンポーネントの障害によりすべてのアベイラビリティ ゾーンが同時に麻痺する状況を経験しました。この記事では、アーキテクチャ設計の観点からフォールト ドメインを削減し、フォールト発生時のビジネス損失を最小限に抑える方法を検討し、Sealos の安定性実践を例として取り上げ、経験と教訓を共有します。
マスター/スレーブを放棄し、ピアツーピア アーキテクチャを採用する
Tencent Cloud 障害レポートから、複数のアベイラビリティ ゾーンで同時に障害が発生するのは、基本的に、統合 API、統合認証、その他のシステム障害などの一部の集中コンポーネントが原因であることがわかります。
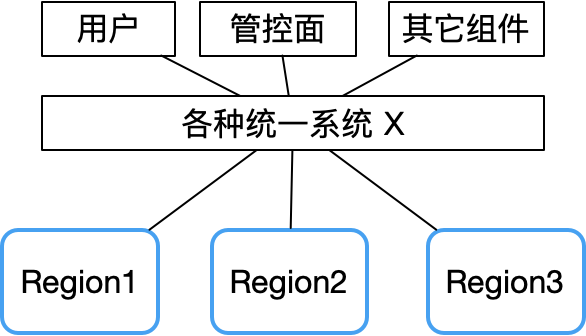
したがって、X システムに障害が発生すると、障害ドメインが非常に大きくなります。
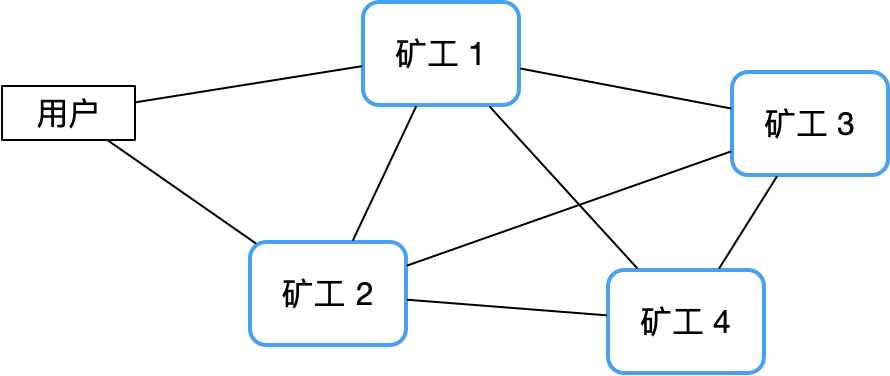
対照的に、分散型ピアツーピア アーキテクチャでは、このリスクをうまく回避できます。ビットコインネットワークを例に挙げると、中央ノードがないため、従来のマスター/スレーブクラスターよりも安定性が非常に高く、ハングアップすることはほとんどありません。
したがって、Sealos は、マルチ アベイラビリティ ゾーンを設計する際に、Alibaba Cloud と Tencent Cloud の教訓を完全に吸収し、すべてのアベイラビリティ ゾーンが自律的なアーキテクチャを採用しました。主な問題は、ユーザー アカウントなどのデータがどのように複数のアベイラビリティ ゾーンに保存されるかです。問題。こんな感じの構造になりました。
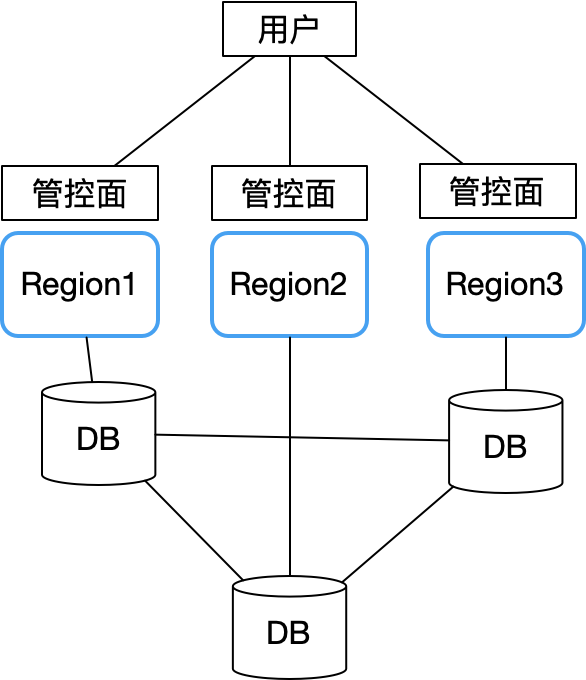
各アベイラビリティ ゾーンは完全に自律しており、リージョン間の分散データベース (CockroachDB を使用) を通じて主要な共有データ (ユーザー アカウント情報など) のみを同期します。各アベイラビリティ ゾーンは、分散データベース CockroachDB のローカル ノードに接続されます。
こうすることで、単一のアベイラビリティーゾーンで障害が発生しても、他のリージョンのビジネス継続性に影響を与えることはありません。分散データベース クラスターで全体的な問題が発生した場合にのみ、すべてのアベイラビリティ ゾーンのコントロール プレーンが使用できなくなります。幸いなことに、CockroachDB 自体はフォールト トレランス、災害復旧、ネットワーク分断への対応において優れたパフォーマンスを備えているため、この状況が発生する可能性は大幅に減少します。このように、全体的なアーキテクチャはシンプルで、データベースの安定性の向上、監視、破壊テストだけに重点を置いています。
これのもう 1 つの利点は、グレースケールのリリースと差別化された操作の利便性が提供されることです。たとえば、最初に一部のエリアで少量のトラフィックで新機能を検証し、安定化後に本格的に開始することもできます。また、完全に一貫性を持たなくても、異なるエリアで顧客グループの特性に基づいてカスタマイズされたサービスを提供することもできます。
絶対に安定したシステムなんて存在しない
クラウドの安定性については誰もがよく不満を言いますが、どのクラウド ベンダーも例外なく失敗を経験しています。ここで最も重要なのは、技術的な問題だけでなく、組織的な問題でもあります。経営上の問題はコストの問題でもあります。これについては、私たちが起業の過程で遭遇した具体的な例に基づいてお話しします。
シーロスが失敗から学んだ教訓
2023 年 3 月 17 日の Laf の大規模障害
これは、私たちが起業して初めて遭遇した大きな失敗でした。私たちがそのときのことを鮮明に覚えているのは、それがちょうど会社の 1 周年記念式典だったからです。 、ケーキを切る時間すらなかった、それは夜中の3時くらいまで続いた。
障害の最終的な原因は非常に奇妙で、安価なサーバーでコンテナーをネットワーク仮想化すると、最終的にクラスター全体を通常の VPC サーバーに移行することになりました。セックスとコストは切り離せないものでした。
したがって、パブリック クラウドは高価であると多くの人が考えています。多くの場合、残りの 10% の問題を解決するには何倍もの費用がかかります。
Laf はその後、複数のテナントが MongoDB ライブラリを共有するモデルを使用していたため、データベース関連の一連の安定性の問題に遭遇しました。最終的な結論は、この方法は機能せず、データベースの分離を解決するのは困難であるということでした。という問題があったため、現在ではすべてが独立したデータベース方式を採用し、最終的に問題が解決されました。
ゲートウェイの安定性の問題もあります。当初は信頼性の低い Ingress コントローラーを選択していましたが、これにより頻繁に問題が発生しました。最終的には、それを Higress に置き換えました。これにより、現在では問題が完全に解決されました。必要なリソースも少なく、より安定しています。また、私たちが明らかにした問題のおかげで、Higress はより成熟し、双方にとって有利な状況になりました。Alibaba Higress チームの個人的なサポートにも非常に感謝しています。
2023 年 6 月に Sealos パブリック クラウドが正式に開始されました。私たちが遭遇した最大の問題の 1 つは、大規模なトラフィックによる CC 攻撃による攻撃でした。ただし、これはコストの高騰を意味します。この 2 つは非常に複雑です。安定性を妨げなければ、それを解決するのは困難です。安定性を妨げると、販売してもコストを回収できなくなります。その後、ゲートウェイを置き換えた後、Envoy が非常に強力で、攻撃トラフィックに実際に抵抗できることがわかりました。それまでは、ワンストップの Nginx を使用していました。さらに、K8s の優れた点は、ゲートウェイがダウンしても 5 分以内に自己修復する強力な機能です。同時にダウンしない限り、ビジネスに影響はありません。
安定性の収束のためのベスト プラクティス
トラブルシューティングのプロセス
システムの安定性を継続的に向上させるために、Sealos は内部で厳格な障害管理プロセスを確立しました。
障害が発生するたびに、それを詳細に記録し、継続的にフォローアップする必要があります。多くの企業は失敗のレビュープロセスを終了しますが、実際には、重要なのは、同様の失敗が二度と起こらないようにするための実践的な是正措置を策定し、実行することです。障害対応完了後も、障害が発生しなくなったことを確認するまで、一定期間監視を続ける必要があります。
経営目標に関しては、当初、2024 年第 1 四半期の OKR における安定性と収束の目標を次のように定義しました。

その後、この一般的なスローガン形式の OKR は信頼性が低く、安定性の収束をより具体的にする必要があることがわかりました。この KR の結果は、それを達成できず、ほとんど効果がありませんでした。収束のプロセスでは、四半期ごとにいくつかのコア ポイントに焦点を当て、数四半期繰り返し続けるだけで、収束は非常に良好になります。
そこで第 2 四半期では、より具体的な目標を設定します。

安定性の設定は、指標の設定に限定することはできず、また、具体的で目に見える対策や特定の測定方法を必要とすることもできません。
たとえば、99.9% が設定されている場合、それを達成するにはどうすればよいでしょうか?それで、現在の可用性は何ですか?現在の主要な問題は何ですか?測定方法?何をする必要がありますか?誰がやるの?設定は利用可能な時間に限定されるものではなく、障害レベル、障害数、障害期間、大規模な顧客障害の監視など、詳細にリストする必要があります。
データベースの安定性、ゲートウェイの安定性、大規模な顧客サービスの可用性指標、CPU/メモリ リソースの過負荷障害など、特別なカテゴリを分けて優先順位をリストする必要があります。
また、Auto Chess、FastGPT 商用顧客、Chongchunxue Studio などの大規模顧客の監視にも重点を置く必要があります (月間使用量が 30 コアを超え、代表的なものを 5 つ選択します)。
これらの大規模な顧客に十分なサービスが提供されれば、基本的には小規模な顧客にも対応できるようになります。現在の主要な安定性の問題を解決することに重点を置き、完全な追跡プロセスを確立してください。
不具合を起こした学生は罰則を受けたり、ボーナスを減額されたり、退学になったりすることもあります。スタートアップ企業としては、関係者は不具合を起こしたくないので、通常は懲罰的措置は行いません。本当に戦えるのは、被害を受けた人たちです。ポジティブなインセンティブを好みます。たとえば、「四半期ごとの故障頻度が減少した場合は、適切にインセンティブを与える」などです。
シンプルな建築デザイン
システムのアーキテクチャは設計の初期段階から安定性に関係するため、アーキテクチャが複雑になればなるほど問題が発生しやすくなります。私は企業のアーキテクチャの設計やレビューに参加することが多いのですが、この点に注意を払っていないことが多いです。 Sealos のマルチアベイラビリティ ゾーンは、データベースの安定性を向上させるだけで十分な例です。データベースのテーブル構造の設計はシンプルで、多くの安定性の問題はクレードル内で解決されています。
メーターシステムも同様で、当初は十数個のCRDを搭載する予定でしたが、半年以上悩んだ末、最終的にシステムの再設計と選定に時間がかかりました。開発には 2 週間かかり、1 か月で安定してオンラインになりました。
したがって、安定性にはシンプルなデザインが非常に重要です。
対象を絞った中程度のモニタリング
監視は諸刃の剣であり、やりすぎても十分ではありません。 Sealos の障害の多くは、Prometheus が過剰なリソースを占有し、API サーバーに負荷がかかり、それが新たな安定性の問題を引き起こしました。教訓を学んだ後、監視指標の数を厳密に制御しながら、VictoriaMetrics のようなより軽量な監視ソリューションに切り替えました。 Uptime Kuma のようなツールは、リージョン間で相互にテストし、時間内に問題を発見できるため、非常に役立ちます。
オンコールにも同じことが当てはまります。毎日何千ものアラームがあります。そこで、ここでは基本的に0からスタートして、例えば「大口顧客のビジネスの最終的な安定性」という観点から、例えばコンテナ障害でこれが起動した場合、オンコールがある場合などをまずやっていきます。 、おそらく電話は鳴り止まないでしょう。次に、ホストの準備ができていないなどの内容をゆっくりと追加します。理論的には、ホストは準備ができていなくてもビジネスに影響を与えることはありません。システムが徐々に成熟するにつれて、最終的にはオンコールを必要とせずにホストを準備ができていない状態にすることが可能になります。
障害を報告するときに恥ずかしさを恐れないでください
Tencent Cloud のレビューレポートは非常に優れており、失敗の理由を誠実に説明し、何が不十分かを客観的に分析し、積極的に修正することを約束しました。このような率直で責任感のある姿勢が、実はユーザーの信頼を勝ち取りやすいのです。逆に、世論の発酵を恐れてこの問題を秘密にしておくのは、喉の渇きを潤すために毒を飲むようなものであり、むしろユーザーに不透明なブラックボックスであり、将来何が起こるかわからないと感じさせます。貴社の製品を心から愛し、貴社とともに成長する意欲のある顧客は、非原則的な間違いを許容できます。重要なのは、真の改善に向けた誠意と行動を示すことです。
要約する
Sealos パブリック クラウドサービスは開始から 1 年以上が経過し、累計登録ユーザー数は100,000 人を超えています。優れた機能、経験、費用対効果により、多くの開発者に支持されており、一部の大規模顧客もビジネスを Sealos クラウドに移行しようと試み始めています。たとえば、「ハッピー オート チェス」というゲームには400 万人を超えるアクティブ ユーザーがいます。
将来に目を向けると、当社はシンプルで効率的なアーキテクチャ設計、安定した監視戦略、そしてオープンで誠実なコミュニケーション姿勢によって補完されたクラウドである Sealos を通じて、体系的な障害管理を通じて安定性を高め続けると信じています。国内の小さなオープンソース企業が育て、開発した、非常に先進的なクラウドとなることは間違いありません。
ライナスは、カーネル開発者がタブをスペースに置き換えることを阻止するために自ら問題を解決しました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子は中核です。ファー ウェイ: 一般的に使用されている 5,000 のモバイル アプリケーションを変換するのに 1 年かかった Java はサードパーティの脆弱性が最も発生しやすい言語です。Hongmeng の父: オープンソースの Honmeng は唯一のアーキテクチャ上の革新です。中国の基本ソフトウェア分野で 馬化騰氏と周宏毅氏が握手「恨みを晴らす」 元マイクロソフト開発者:Windows 11のパフォーマンスは「ばかばかしいほど悪い」 老祥基がオープンソースであるのはコードではないが、その背後にある理由は Meta Llama 3 が正式にリリースされ、 大規模な組織再編が発表されました。