
2024 年春のカンファレンスで、Kangaroo Cloud はデータ スタック製品の V6.2 バージョンの新しいリリースを発表しました。その中で、EasyMR はデータ スタック V6.2 の主要な機能であり、Kangaroo Cloud のビッグ データ エコシステムに対する深い理解と継続的な革新を表しています。
EasyMR (以下、総称して EMR)は、Hadoop、Hive、Spark、Flink、HBase などのオープンソース コンポーネントに基づいて Kangaroo Cloud によって構築されたエラスティック コンピューティング エンジンであり、安全で信頼性が高く、弾力的に拡張可能で、低コストの大きなコンピューティング エンジンを提供します。データストレージおよびコンピューティングサービス。そのうち、独自に開発したエンタープライズレベルのビッグデータ運用保守管理プラットフォーム「EasyManager」は、Hadoopクラスターの作成、管理、展開、運用保守、監視機能をワンストップでサポートし、効率的なデータセンターソリューションを提供します。
企業のデータ処理と分析のニーズの高まりに直面して、EMR6.2 バージョンは、より優れたビッグデータの運用および保守サービスとコンピューティング パフォーマンスの最適化をユーザーに提供します。以下では、ユーザーがこの革新的な製品を完全に理解できるように、EMR6.2 バージョンの 4 つの主要な機能の最適化について詳しく説明します。
UI が完全にリフレッシュされアップグレードされました: シンプルで快適なインタラクティブ エクスペリエンス
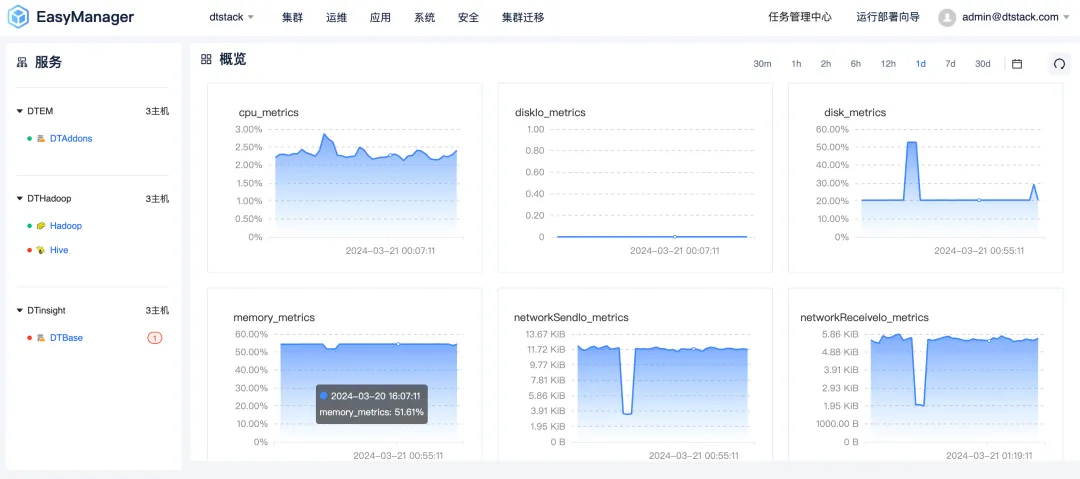
Kangaroo Cloud はユーザー エクスペリエンスの重要性を理解しているため、EMR6.2 バージョンでは UI インターフェイスを包括的に更新およびアップグレードしました。新しいインターフェースのデザインは、シンプルかつエレガントなスタイルを踏襲しており、ユーザーに直感的で快適なインタラクティブ体験を提供することを目指しています。初心者でも経験豊富なユーザーでも、すぐに使い始めて、複雑なビッグ データ クラスターを簡単に管理できます。
さらに、インターフェースの応答速度と操作の流暢性も最適化され、ユーザーがクラスターの運用および保守時によりスムーズな操作体験を享受できるようにしました。
差別化された構成: 多様なニーズに対応
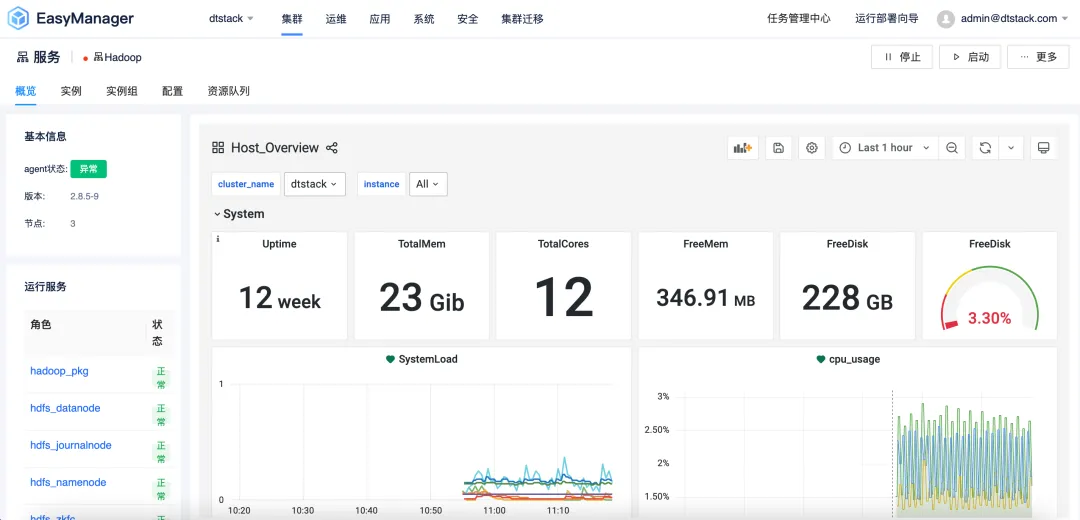
EMR6.2バージョンでは、インスタンスグループ差別化構成機能を導入し、ユーザーがニーズに合わせてクラスター構成をカスタマイズできるようになりました。ユーザーは、 EMR クラスター内のさまざまなノードから独立したインスタンス グループを構築し、インスタンス グループに特定の構成パラメーターを設定して、パフォーマンス、リソース使用率、およびタスクのスケジューリングを向上させることができます。
コスト重視の新興企業であっても、より高いパフォーマンス要件を必要とする大企業であっても、EMR6.2 はさまざまなユーザーのニーズを満たす柔軟な構成オプションを提供します。
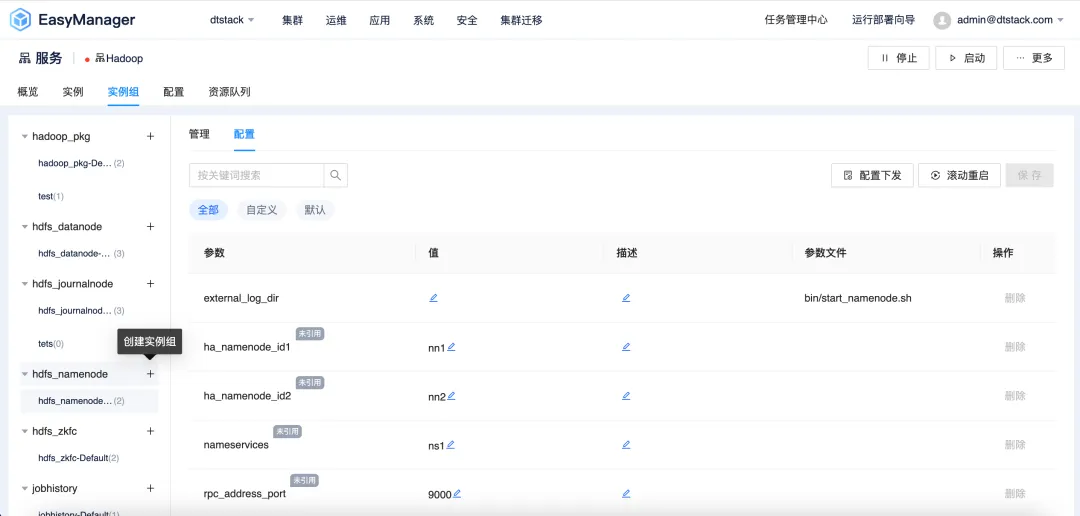
インスタンス グループに差別化された構成戦略を実装することの具体的な利点には次のようなものがありますが、これらに限定されません。
● リソースの割り当て
差別化された構成により、さまざまなタスクの固有のニーズに応じて、コンピューティング、ストレージ、ネットワーク リソースなどの複数のレベルをカバーする、洗練されたリソース割り当てを効果的に実装できます。リソースの無駄を回避し、リソースの使用率を向上させて、クラスター内のすべてのタスクが適切なリソースでサポートされるようにします。
●タスクスケジュールの最適化
さまざまなタイプのタスクまたはジョブに対して、その特性に応じてさまざまな構成パラメータを設定して、タスクのスケジューリングと実行効率を最適化できます。
● 耐障害性と安定性
差別化された構成により、クラスターの耐障害性と安定性を向上させることができます。ノードまたはインスタンス グループの重要性と負荷に応じて、さまざまなフォールト トレランス メカニズムと障害処理戦略を設定して、異常な状況に直面してもクラスターが安定した動作を維持できるようにすることができます。
● コスト管理
差別化された構成はコストの管理にも役立ちます。ビジネス ニーズと予算の制約に応じて、クラスター内のさまざまなインスタンス グループを合理的に構成して、リソースの無駄を回避し、運用コストと保守コストを削減し、パフォーマンスとコストのバランスを見つけることができます。
クラスターの移行: ビジネスを中断することなくシームレスに移行
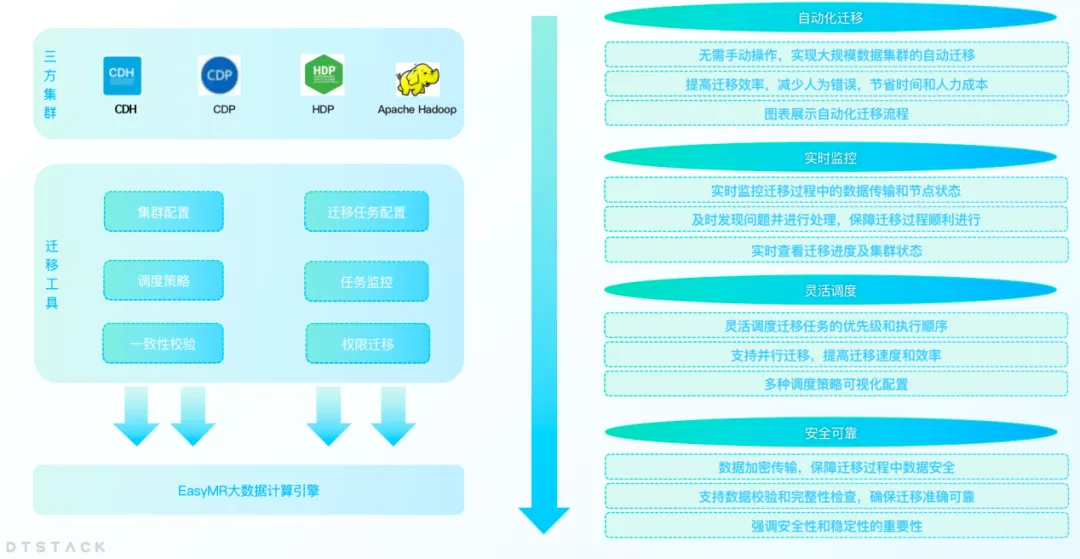
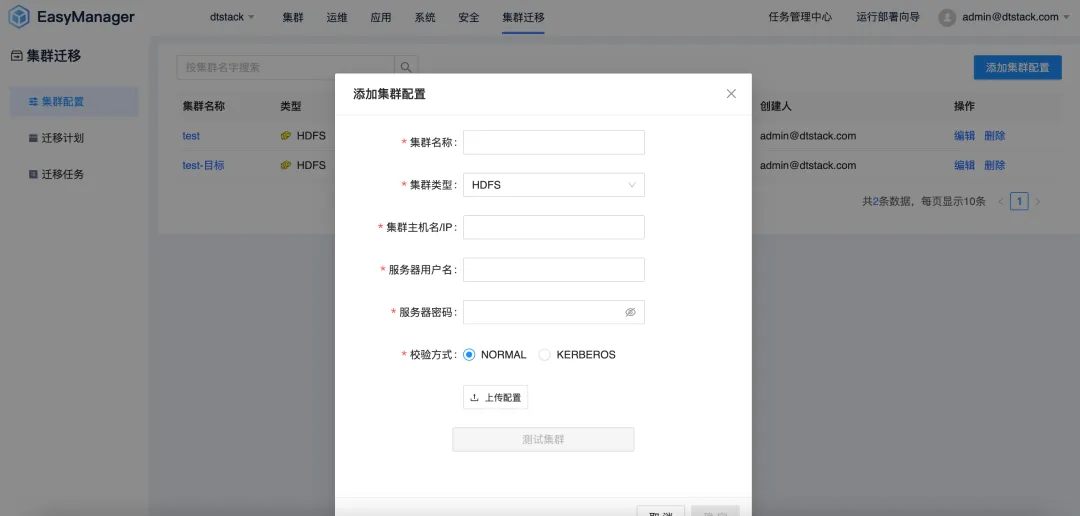
企業のビジネスが発展するにつれて、データ量の増加により、データセンターの容量不足やデータセンターの変更などの問題が発生することがよくあります。同時に、ローカリゼーションの置き換えの文脈で、CDH、HDP、CDP などの非イノベーション プラットフォームをローカライズされたビッグ データ プラットフォームに移行する企業がますます増えています。そこでEMRは、企業がデータセンターの移行を効率的に完了できるよう、ビッグデータクラスター移行機能を開始した。
クラスター移行機能を使用すると、ユーザーはデータ損失やビジネスの中断を心配することなく、異なるデータセンターまたはクラウド サービス間でビッグ データ クラスターをシームレスに移行できます。この機能により、企業は IT インフラストラクチャをより柔軟に調整して、市場のニーズの変化に適応できます。
エンジンのアップグレードが明らかに: パフォーマンスの飛躍、新たな体験
最も興味深いのは、EMR6.2 バージョンがコンピューティング エンジンのパフォーマンスにおいて大きな進歩を遂げたことです。既存の Spark および Flink コンピューティング エンジンを最適化するだけでなく、新しいアルゴリズムとテクノロジーを導入して、データ処理速度とコンピューティング効率を向上させました。これは、ユーザーがより複雑なデータ分析タスクをより短時間で完了できることを意味し、それによって意思決定プロセスがスピードアップされ、企業の競争力が向上します。
● Spark3 は Z-order インデックスの最適化をサポートします
Z - Order は、多次元データを 1 つの次元に圧縮できるテクノロジーであり、データの複数のフィールドをデータの複数の次元としてみなすことができ、多次元データをマッピングするために特定のルールを渡すことができます。一次元データ。
具体的には、 z 値は一定の規則に従って構築され、このとき、z 値は前述の 1 次元データとして理解され、その 1 次元データに基づいて並べ替えることができます。以下に示すように:
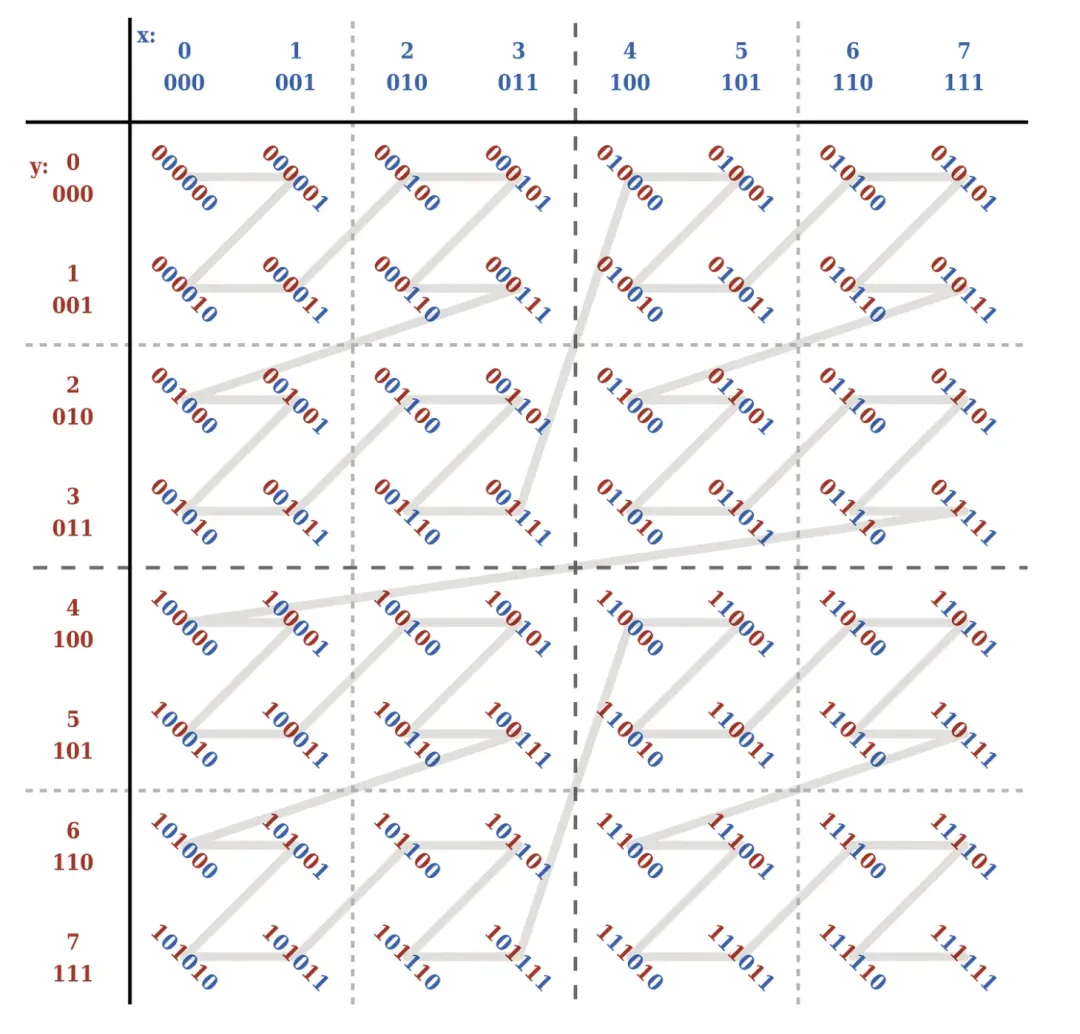
Spark SQL では、Kangaroo Cloud は Z-Order インデックスをサポートするOPTIMIZE XX ZORDER BY 構文を追加し、INSERT INTO テーブル、INSERT OVERWRITE テーブル、CREATE TABLE table AS SELECT、DISTINCT およびその他の SQL の Z-Order インデックスの最適化を実現します。
Spark3 は、Z オーダー最適化をサポートしています。これにより、データ処理とクエリの効率が大幅に向上し、IO オーバーヘッドが削減され、ジョブの実行が高速化されます。特に、大規模なデータ セットや複雑なクエリ操作を処理する必要があるシナリオでは、Z オーダーの最適化が重要な役割を果たします。ファイル圧縮率の問題を解決する際、Z オーダー最適化を使用した後、ファイル圧縮率は手動最適化と比較して 20% 近く増加し、オープンソースの Spark3 と比較して元のタスクと比較して 10 倍近く増加しました。タスクのパフォーマンスも 30% 近く向上し、オフライン操作のパフォーマンスと効率が大幅に向上しました。
● Flink ジョブごとのタスクのホット アップデート
実際の運用操作では、リアルタイムのタスク パラメータの変更やオペレータと関数の調整が頻繁に発生します。通常、最初に現在のタスクをキャンセルすることしかできず、その後、CheckPoint が選択されて復元または再実行されます。このプロセス全体には約 3 ~ 5 分かかります。待ってください、これは非常に困難です、タスク開発時間の大きな無駄です。
従来のジョブごとのモードでのタスクの更新によって引き起こされるサービス中断の問題を解決するために、タスクの安定性とシステムの可用性を向上させ、本番環境でのビジネス継続性と高可用性の要件を満たします。 Kangaroo Cloud Engine チームは、関連する調査とソース コードの改善を実施し、ジョブごとのタスク キャンセルの非同期コールバックでのタスクのホット リスタートを最適化しました。
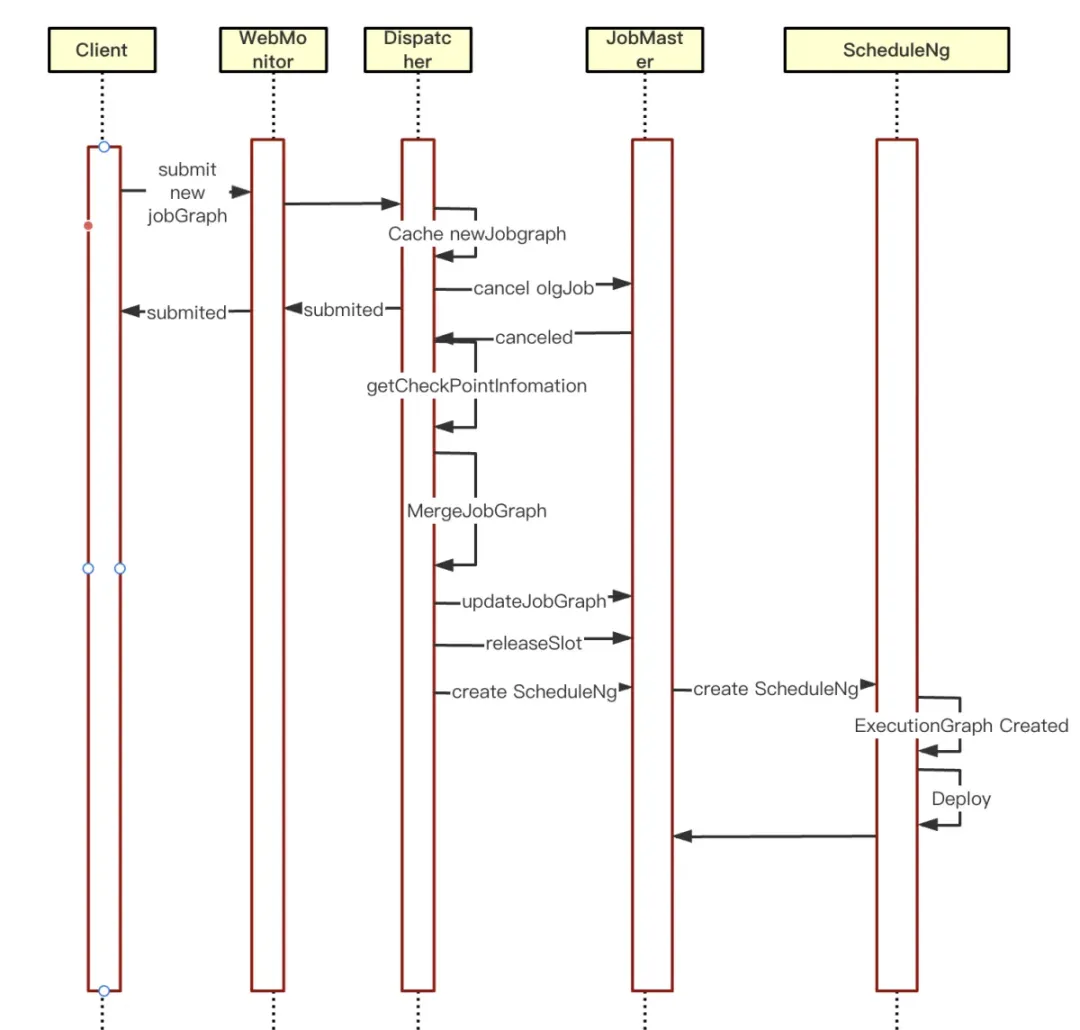
① まず、現在新しい JobGraph キャッシュがあるかどうかを確認します。キャッシュがある場合は、ホット リスタート ロジックに入ります。
②キャンセルされたタスクのCheckPoint情報を取得し、新しいJobGraphに記入する
③JobGrapをJobMasterに更新し、JobGraphのキャッシュ情報をクリアする
④JobMasterでSloyPoolが管理しているリソースをクリアする
⑤JobMaster はScheduleNgを再作成し、実行をスケジュールします。これにより、新しい JobGraph スケジュールの実行が開始されます。
Flink ジョブごとのタスクのホット アップデートの最適化により、開発効率が大幅に向上し、ダウンタイムが削減され、アプリケーションの柔軟性と信頼性が向上します。迅速な反復と動的な調整が必要なリアルタイム アプリケーションに、究極の効率エクスペリエンスをもたらします。
開発効率の向上: 開発者は、面倒な停止と再起動のプロセスを経ることなく、コードを迅速にテストして反復できるため、開発サイクルが短縮され、より頻繁なリリースが可能になります。
· ダウンタイムの削減: ホット アップデートによりアプリケーションのダウンタイムが最小限に抑えられるため、サービスの可用性が向上します。これは、ミッション クリティカルなリアルタイム アプリケーションにとって特に重要です。
· パラメータを動的に調整: 並列処理やオペレータ パラメータなどのジョブ構成パラメータは、ジョブを再起動せずに動的に調整できるため、リアルタイムのデータ フローや負荷条件に基づいて柔軟に調整できます。
●その他の機能開発
さらに、エンジン側では、エンジンのタスクのセキュリティとスケーラビリティを強化しながら、エンジンのコンピューティング パフォーマンスを向上させるために、 Spark Ranger ドッキング、Spark マテリアライズド ビューの最適化、Flink セッション モードのクラス読み込み分離などの機能も開発しました。
要約する
要約すると、EMR6.2のリリースは、ビッグ データ サービスの分野における Kangaroo Cloud の新たな重要なマイルストーンとなります。 EMR6.2 は、包括的な UI の更新とアップグレード、差別化された構成、クラスターの移行とエンジンのアップグレードを含む 4 つの主要な機能の最適化を通じて、より強力で柔軟かつ効率的なビッグ データ コンピューティング エンジン プラットフォームをユーザーに提供し、企業のデータ管理と A を支援します。分析における質的な飛躍。
「産業指標システム白書」ダウンロードアドレス:https://www.dtstack.com/resources/1057 ?src=szsm
「Dutstack 製品ホワイトペーパー」ダウンロードアドレス:https://www.dtstack.com/resources/1004 ?src=szsm
「データ ガバナンス業界実践ホワイト ペーパー」ダウンロード アドレス: https://www.dtstack.com/resources/1001?src=szsm
ビッグデータ製品、業界ソリューション、顧客事例について詳しく知りたい、または相談したい場合は、Kangaroo Cloud 公式 Web サイトをご覧ください: https://www.dtstack.com/?src=szkyzg
ライナスは、カーネル開発者がタブをスペースに置き換えるのを防ぐことに自ら取り組みました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子はオープンソース コアです。寄稿者Robin Li: 自然言語 は 新しいユニバーサル プログラミング言語になるでしょう。オープン ソース モデルは Huawei にますます後れをとっていきます 。一般的に使用されている 5,000 のモバイル アプリケーションを Honmeng に完全に移行するには 1 年かかります。 リッチテキスト エディタ Quill 2.0 が リリースされ、機能、信頼性、開発者は「恨みを取り除く 」 ために握手を交わしました。 Laoxiangji のソースはコードではありませんが、その背後にある理由は非常に心温まるものです。Googleは大規模な組織再編を発表しました。