

QoS 管理機能により、オンラインおよびオフラインのアプリケーションを均一にスケジュールできるため、リソースの使用率が大幅に向上します。
ソース | ByteDance インフラストラクチャ チーム
オープンソース | github.com/kubewharf/godel-scheduler
この記事は、トップの国際クラウド コンピューティング カンファレンスである SoCC 2023 で Bytedance インフラストラクチャ オーケストレーションおよびスケジューリング チームによって発表された論文「 Gödel: Unified Large-Scale Resource Management and Scheduling at Bytedance」を解釈したものです。

論文リンク: dl.acm.org/doi/proceedings/10.1145/3620678
この論文では、ByteDance が提案した、オンライン タスクとオフライン タスクの混合をサポートする Kubernetes に基づく高スループット タスク スケジューリング システムを紹介します。これは、大規模データ センターにおけるさまざまな種類のタスクのリソース割り当て問題を効果的に解決し、パフォーマンスを向上させることを目的としています。データセンターのリソースの使用率、回復力、およびスケジュールのスループット。
現在、このスケジューリング システムは、数万ノードの超大規模クラスターの管理をサポートし、マイクロサービス、バッチ、ストリーミング タスク、AI などの複数の種類のタスクにリソース プーリング機能を提供します。 2022 年以降、Gödel スケジューラは ByteDance の社内データ センターにバッチで導入され、 ピーク時に60% を超える CPU 使用率と 95% を超える GPU 使用率を実現し、ピーク スケジューリング スループットは 5,000 ポッド/秒近くになることが検証されました。
導入
ここ数年、ByteDance の事業分野の急速な発展に伴い、マイクロサービス、プロモート検索 (推奨/広告/検索)、ビッグデータ、機械学習、ストレージの規模など、社内のビジネスの種類はますます多様化しています。などのビジネスが急速に拡大しており、それに必要なコンピューティングリソースの量も急速に拡大しています。初期の頃、Bytedance のオンライン ビジネスとオフライン ビジネスは独立したリソース プールを持ち、ビジネス間で個別のプール管理が採用されていました。重要なフェスティバルや大規模なイベント中に爆発的に増加するオンライン ビジネス リクエストに対処するために、インフラストラクチャ チームは多くの場合、事前に計画を立て、オフライン ビジネス リソースの一部をオンライン ビジネス リソース プールに貸し出す必要があります。この方法は一時的なニーズには対応できますが、異なるリソース プール間のリソース貸し出しプロセスは長く、複雑で、非効率的です。同時に、独立したリソース プールはオフライン ビジネス間のコロケーションにかかるコストの高さにつながり、リソース利用率を向上させる上限も非常に限られています。この問題に対処するために、この論文は統合オフライン スケジューラ Gödel を提案します。これは、同じスケジューラのセットを使用してオフライン サービスを均一にスケジュールおよび管理し、リソース プーリングを実現し、それによってリソースの使用率とリソースの弾力性を向上させ、ビジネス コストと弾力性を最適化することを目的としています。経験を活かし、運用とメンテナンスのプレッシャーを軽減します。 Gödel スケジューラーは Kubernetes プラットフォームに基づいており、Kubernetes ネイティブ スケジューラーやコミュニティ内の他のスケジューラーよりもパフォーマンスと機能の点で優れています。
エンジンをかけろ
ByteDance は、数十の超大規模マルチクラスター データセンターを運用しており、毎日数千万のコンテナ化タスクが作成および削除されます。夕方のピーク時の単一クラスターの平均タスク スループットは 1000 ポッド/秒を超えます。これらのタスクのビジネス優先度、動作モード、リソース要件は異なります。高品質のタスク SLA とさまざまなタスク リソース要件を確保しながら、これらのタスクを効率的かつ合理的にスケジュールする方法は、非常に困難な課題です。
調査を通じて、コミュニティで一般的に使用されているクラスター スケジューラーのどれも ByteDance の要件を十分に満たすことができないことがわかりました。
- Kubernetes ネイティブ スケジューラはマイクロサービス スケジューリングに非常に適しており、さまざまな柔軟なスケジューリング セマンティクスを提供しますが、同時に、Kubernetes ネイティブ スケジューラのスケジューリング スループットが低い (< 200 ポッド/秒) ため、オフライン サービスのサポートは満足のいくものではありません。 )、サポートされるクラスター サイズも制限されており (通常は 5000 ノード以下)、ByteDance 内の膨大なオンライン ビジネス スケジューリング ニーズを満たすことができません。
- CNCF コミュニティの Volcano は、主にオフライン サービスを目的としたスケジューラで、オフライン サービス (バッチ、オフライン トレーニングなど) のスケジューリング ニーズを満たすことができます (ギャング スケジューリングなど)。ただし、スケジューリング スループット レートも比較的低く、オンライン サービスを同時にサポートすることはできません。
- YARN も人気のあるクラスター リソース管理ツールであり、これまで長い間、オフライン ビジネス スケジューリングの最初の選択肢でした。バッチやオフライン トレーニングなどのオフライン サービスに必要なスケジューリング セマンティクスを適切にサポートしているだけでなく、高いスケジューリング スループット レートも備えており、大規模なクラスターをサポートできます。ただし、主な欠点は、マイクロサービスなどのオンライン ビジネスを十分にサポートしておらず、オンライン ビジネスとオフライン ビジネスのスケジュール ニーズを同時に満たすことができないことです。

したがって、ByteDance は、 Kubernetes と YARN の利点を組み合わせたスケジューラーを開発して、リソース プールを開放し、あらゆる種類のビジネスを均一に管理したいと考えています。上記の議論に基づいて、スケジューラには次の特性があることが期待されます。
- 統合リソースプール
クラスター内のすべてのコンピューティング リソースが表示され、オンラインとオフラインの両方でさまざまなタスクに割り当てることができます。リソースの断片化率とクラスターの運用および保守コストを削減します。
- リソース使用率の向上
クラスターとノードのディメンションで異なるタイプと優先順位のタスクを混合して、クラスター リソースの使用率を向上させます。
- 高いリソース弾力性
クラスターおよびノードの次元では、コンピューティング リソースは、優先度の異なるサービス間で柔軟かつ迅速に転送できます。リソースの利用率を向上させながら、リソースの優先割り当て権と高品質なサービスの SLA を常に保証します。
- 高いスケジューリング スループット
Kubernetes ネイティブ スケジューラやコミュニティの Volcano スケジューラと比較して、オンライン サービスとオフライン サービスの両方でスケジューリング スループットを大幅に向上させる必要があります。 1000 ポッド/秒を超えるビジネス要件を満たします。
- トポロジーを意識したスケジューリング
候補ノードのリソース マイクロトポロジは、kubelet が許可するときではなく、スケジューリングを決定するときに特定され、ビジネス ニーズに基づいてスケジューリングに適切なノードが選択されます。
ゲーデルの紹介
Gödel Scheduler は、Kubernetes クラスター環境で使用される分散スケジューラーで、オンラインとオフラインのサービスを均一にスケジュールでき、オフラインのビジネス機能とパフォーマンスの要件を満たしながら、優れたスケーラビリティとスケジューリング品質を提供できます。以下の図に示すように、Gödel Scheduler は Kubernetes ネイティブ スケジューラと同様の構造を持ち、Dispatcher、Scheduler、Binder の 3 つのコンポーネントで構成されます。違いは、大規模なクラスターをサポートし、より高いスケジューリング スループットを提供するために、そのスケジューラー コンポーネントはマルチインスタンスでオプティミスティック同時スケジューリングを採用できるのに対し、ディスパッチャーとバインダーは単一インスタンスで実行されることです。
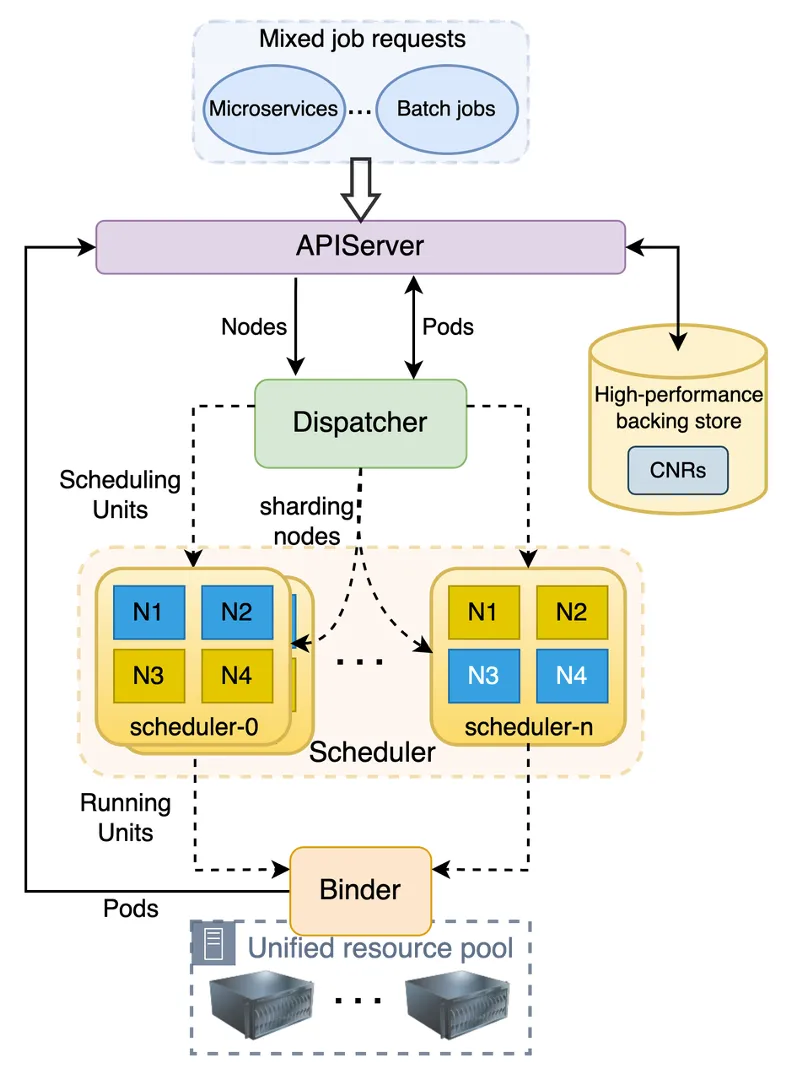
コアコンポーネント
ディスパッチャはスケジューリング プロセス全体への入り口であり、主にタスクのキューイング、タスクの分散、ノードの分割などを担当します。これは主に、ソート ポリシー マネージャー、ディスパッチ ポリシー マネージャー、ノード シャフラー、およびスケジューラー メンテナーのいくつかの部分で構成されます。
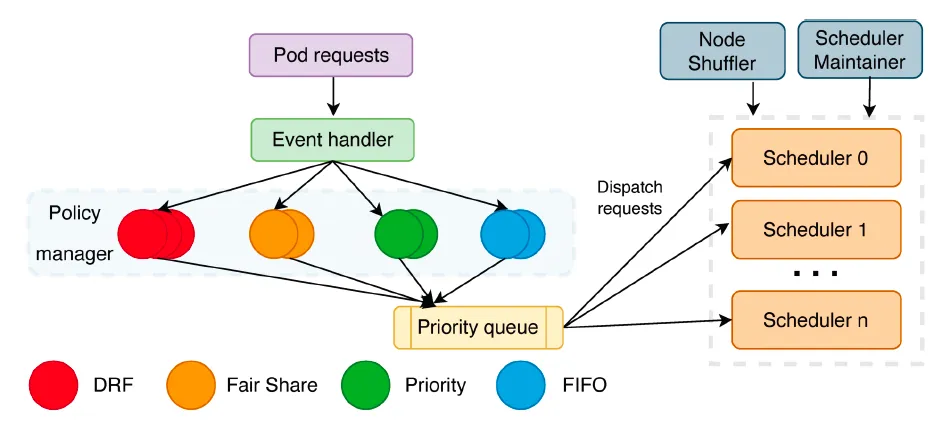
- ソート ポリシー マネージャー: 主にキューイング タスクを担当します。現在、FIFO、DRF、FairShare などのキューイング戦略が実装されています。将来的には、優先順位値ベースなどのキューイング戦略が追加されます。
- ディスパッチ ポリシー マネージャー: 主に、タスクをさまざまなスケジューラー インスタンスに分散し、プラグイン構成を通じてさまざまな分散戦略をサポートします。現在のデフォルトの戦略は、LoadBalance に基づいています。
- Node Shuffler : 主に、スケジューラー インスタンスの数に基づいてクラスター ノードを分割します。各ノードは 1 つのパーティションにのみ存在できます。各スケジューラ インスタンスはパーティションに対応します。スケジューラ インスタンスが動作するとき、要件を満たすノードが見つからない場合は、他のパーティション内のノードを探します。ノードの追加や削除、スケジューラの数の変更など、クラスタのステータスが変化した場合、ノードシャッフルは実際の状況に基づいてノードを再分割します。
- スケジューラ メンテナ: スケジューラ インスタンスの健全性ステータス、負荷ステータス、パーティション ノードの数など、各スケジューラ インスタンスのステータスを維持する主な責任があります。
スケジューラーはディスパッチャーからタスク要求を受け取り、タスクの特定のスケジューリングとプリエンプションの決定を行いますが、実際にそれらを実行するわけではありません。 Kubernetes ネイティブ スケジューラと同様に、Gödel のスケジューラも、さまざまなリンクにある一連のプラグインを通じてスケジューリングの決定を決定します。たとえば、次の 2 つのプラグインは、要件を満たすノードを見つけるために使用されます。
- プラグインのフィルタリング: タスクベースのリソース要求、要件を満たさないノードのフィルタリング。
- プラグインのスコアリング: 上記でフィルタリングされたノードをスコアリングし、最適なノードを選択します。
Kubernetes ネイティブ スケジューラとは異なり、Gödel のスケジューラでは複数のインスタンスを分散方式で実行できます。非常に大規模なクラスターや高スループットを必要とするシナリオの場合、ニーズを満たすために複数のスケジューラー インスタンスを構成できます。現時点では、各スケジューラー インスタンスは、ノードを選択するときに、最初にインスタンスが属するパーティションから選択されるため、パフォーマンスが向上しますが、適切なノードが存在しない場合にのみ保証されます。ローカル パーティション内のノードは、インスタンスが属するパーティションから選択されます。ノードは他のインスタンスのパーティション内で選択されますが、これにより競合が発生する可能性があります。つまり、複数のスケジューラー インスタンスが同時に同じノードを選択します。スケジューラ インスタンスが多いほど、競合が発生する可能性が高くなります。したがって、インスタンスの数は、多いほど良いとは限りません。
さらに、オンラインとオフラインの両方のタスクをサポートするために、Gödel Scheduler は2 レベルのスケジューリング セマンティクスを採用しています。つまり、Pod Group や ReplicaSet などのビジネス デプロイメントを表すスケジューリング ユニットとポッドの実行ユニットの 2 レベルのスケジューリングをサポートしています。具体的な使い方は後ほど紹介します。
バインダーは 主に、オプティミスティックな競合チェック、特定のプリエンプション操作の実行、バインド前のタスクの準備 (ストレージ ボリュームの動的作成など)、そして最終的にバインド操作の実行を担当します。一般に、これは Kubernetes Binder のワークフローに似ていますが、Gödel では、Binder は複数の Scheduler インスタンスによって引き起こされるより多くの競合に対処する必要があります。競合が発見されたら、すぐに電話をかけ直してスケジュールを変更してください。プリエンプション操作の場合、Binder は、同じインスタンス (つまり、Victim Pod) をプリエンプトしようとしている複数の Schduler インスタンスがあるかどうかを確認します。このような問題が存在する場合、Binder は最初のプリエンプションのみを処理し、残りの Schduler インスタンスによって発行されたプリエンプション要求を拒否します。ギャング/共同スケジュールの場合、バインダーはポッド グループ内のすべてのポッドの競合 (存在する場合) を処理する必要があります。すべてのポッドの競合が解決され、各ポッドが個別にバインドされるか、ポッド グループ全体のスケジューリングが拒否されます。
CNR は Custom Node Resource の略で、ノードのリアルタイム情報を補足するために ByteDance によって作成された CRD です。これは Gödel Scheduler 自体の一部ではありませんが、Gödel のスケジューリング セマンティクスを強化できます。この CRD は、ノードのリソース量やステータスを定義するだけでなく、デュアルソケット ノード上の各ソケットの CPU/メモリ消費量やリソース残量など、リソースのマイクロ トポロジも定義します。これにより、スケジューラは、マイクロトポロジ アフィニティ要件を持つタスクをスケジュールするときに、CNR によって記述されたノード ステータスに基づいて適切なノードを選択できるようになります。
トポロジ マネージャーのみを使用するネイティブ Kubernetes と比較して、CNR を使用すると、トポロジ制限を満たさないノードにポッドがスケジュールされているときに kubelet で発生するスケジューリング エラーを回避できます。ノード上でポッドが正常に作成されると、CNR は Katalystに属するノード エージェントによって更新されます 。
2段階のスケジュール設定
Bytedance が Gödel を設計していたとき、その主な目標の 1 つは、オンライン サービスとオフライン サービスの両方のスケジュール ニーズを満たすことでした。この目標を達成するために、ゲーデルは、スケジューリング ユニットと実行ユニットという 2 つのレベルのスケジューリング セマンティクスを導入しました。
前者はデプロイされたジョブに対応し、1 つ以上の実行ユニットで構成されます。たとえば、ユーザーが Kubernetes Deployment を通じてジョブをデプロイすると、ジョブはスケジューリング ユニットにマップされ、タスクを実行する各ポッドは実行ユニットに対応します。ネイティブ Kubernetes の直接的な Pod 指向のスケジューリングとは異なり、Gödel の 2 レベルのスケジューリング フレームワークでは、スケジューリング ユニットの全体的なステータスが常に承認原則として使用されます。スケジューリング ユニットがスケジュール可能であるとみなされると、それに含まれる実行ユニット (つまりポッド) が順番にスケジュールされます。
スケジューリング ユニットがスケジュール可能かどうかを判断するルールは、スケジューリング条件を満たす Min_Member 実行ユニットが存在することです。つまり、スケジューラーがジョブ内の十分なポッドのリソース要件を満たすノードを見つけることができた場合、ジョブはスケジューリング可能であると見なされます。スケジュール可能であること。この時点で、各ポッドはスケジューラによって順番に指定されたノードにスケジュールされます。そうしないと、すべてのポッドがスケジュールされず、ジョブのデプロイメント全体が拒否されます。
Scheduling Unit の Min_Member が非常に重要なパラメータであることがわかります。異なる Min_Member を設定すると、さまざまなシナリオのニーズを満たすことができます。 Min_Member の値の範囲は [1, 実行中のユニットの数] です。
たとえば、マイクロサービス ビジネスを対象とする場合、Min_Member は 1 に設定されます。各Scheduling Unit内の1つのRunning Unit/Podのリソース要求を満たす限り、スケジューリングを実行できます。この時点で、Gödel スケジューラーは基本的にネイティブ Kubernetes スケジューラーと同じように実行されます。
Gang セマンティクスを必要とするバッチやオフライン トレーニングなどのオフライン サービスに直面する場合、Min_Member の値は実行ユニット/ポッドの数と等しくなります (一部のサービスは、実際のニーズに応じて 1 から実行ユニットの数までの値に調整することもできます) )、つまり、すべての Pod がリソース要求に対応できる場合にのみスケジューリングが開始されます。 Min_Member の値は、ビジネス展開テンプレートのビジネス タイプとパラメーターに基づいて自動的に設定されます。
パフォーマンスの最適化
ByteDance 自体のビジネス ニーズのため、スケジューリング スループットには高い要件があります。ゲーデルの設計目標の 1 つは、高いスループットを提供することです。この目的を達成するために、ゲーデル スケジューラは、フィルタリング ノードの最も時間のかかる部分を、同時に実行できるマルチインスタンス スケジューラに配置します。一方で、複数のインスタンスで競合が発生するため、Schduler インスタンスの数が必ずしも優れているわけではありません。その一方で、複数のインスタンスによってもたらされるパフォーマンスの向上だけでは、1000 ~ 2000 ポッド/ポッドという夜のピークに対処するには十分ではありません。単一クラスター内のスループット要件。スケジューリング効率をさらに向上させるために、ゲーデルは次の点でさらなる最適化を行いました。
- キャッシュ候補ノード
ノードをフィルタリングするプロセスでは、フィルタと優先順位付けの 2 つの部分が最も時間のかかります。前者はリソース要求に基づいて利用可能なノードをフィルタリングし、後者は候補ノードにスコアを付けて最適なノードを見つけます。これら 2 つの部分の実行速度を向上させることができれば、スケジューリング サイクル全体が大幅に短縮されます。
ByteDance 開発チームは、コンピューティング リソースはさまざまなビジネス ユニットのさまざまなアプリケーションによって使用されているにもかかわらず、特定のビジネス ユーザーのアプリケーションのすべてまたはほとんどのポッドには通常同じリソース要件があることに気づきました。
例: ソーシャル APP は 20,000 の HTTP サーバーを作成するために適用され、各サーバーには 4 つの CPU コアと 8GB のメモリが必要です。ビッグ データ チームは、10,000 のサブタスクを含むデータ分析プログラムを実行する必要があります。各サブタスクには 1 つの CPU コアと 4 GB のメモリが必要です。
これらの大量作成タスクのほとんどの Pod には、同じリソース アプリケーション、同じネットワーク セグメント、デバイス アフィニティ、その他の要件があります。次に、フィルター プラグインによって選択された候補ノードは最初のポッドのニーズを満たし、このタスクに対する他のポッドのニーズも満たす可能性があります。
したがって、Gödel スケジューラは最初の Pod をスケジュールした後に候補ノードをキャッシュし、次のスケジュールではキャッシュから利用可能なノードを優先的に検索します。クラスターのステータスが変化する (ノードの追加または削除) か、異なるリソース要件を持つポッドに遭遇しない限り、ラウンドごとにクラスター内のノードを再スキャンする必要はありません。スケジューリング プロセス中に割り当てるリソースがないノードはキャッシュから削除され、クラスターのステータスに基づいて並べ替えが調整されます。この最適化により、同じビジネス ユーザーに対して Pod のグループをスケジュールする場合、ノード スクリーニング プロセスを大幅に最適化でき、理想的には時間の複雑さを O(n) から O(1) に減らすことができます。
- スキャンされるノードの割合を減らす
上記の最適化により候補ノードの構築プロセスは削減できますが、クラスターのステータスやリソースのアプリケーションが変更された場合は、クラスター内のすべてのノードを再スキャンする必要があります。
時間のオーバーヘッドをさらに削減するために、ゲーデルは候補リストのスキャン率を調整し、グローバル最適解の近似代替としてローカル最適解を使用しました。スケジューリング プロセス中にすべての実行ユニット/ポッドに対して十分な候補ノードを見つける必要があるため、ゲーデルは履歴データの分析に基づいて、少なくとも # の実行ユニット ノードをスキャンします。デフォルトでは、Gödel は # の実行ユニット + 50 ノードをスキャンします。候補を見つけます。適切な番号が見つからない場合は、同じ番号が再度スキャンされます。この方法を候補ノードのキャッシュと組み合わせると、Pod に適したノードを見つける際のスケジューラーの時間のオーバーヘッドが大幅に削減されます。
- データ構造とアルゴリズムを最適化する
上記の 2 つの最適化に加えて、ゲーデル スケジューラはデータ構造とアルゴリズムも継続的に最適化します。
候補ノード リストを低コストで維持し、ノード リストの頻繁な再構築によって引き起こされるオーバーヘッドを回避するため。ゲーデルは 、ネイティブ Kubernetes スケジューラーの NodeList メンテナンス メカニズムを再構築し、ノード リストを離散化することで超大規模実稼働クラスターのパフォーマンス問題を解決し、より低いオーバーヘッドでより優れたノード離散化効果を実現しました。
全体的なリソース使用率を向上させるために、ByteDance は高品質のオンライン タスクと低品質のオフライン タスクを混合して展開します。ビジネスの潮の満ち引きの特性により、多くのオンライン ビジネスが夜のピーク時に戻ります。そのため、多くの場合、低品質のオフライン ビジネスを高頻度でプリエンプトする必要があります。プリエンプション プロセスには大量の検索計算が含まれ、頻繁なプリエンプションはスケジューラの全体的な作業効率に重大な影響を与えます。この問題を解決するために、ゲーデル スケジューラは、ポッドとノードに基づく多次元プルーニング戦略を導入します。これにより、プリエンプション スループットが迅速に回復し、プリエンプション遅延が大幅に削減されます。
実験結果
この論文では、スケジューリング スループット、クラスター サイズなどの観点からゲーデル スケジューラーのパフォーマンスを評価しています。
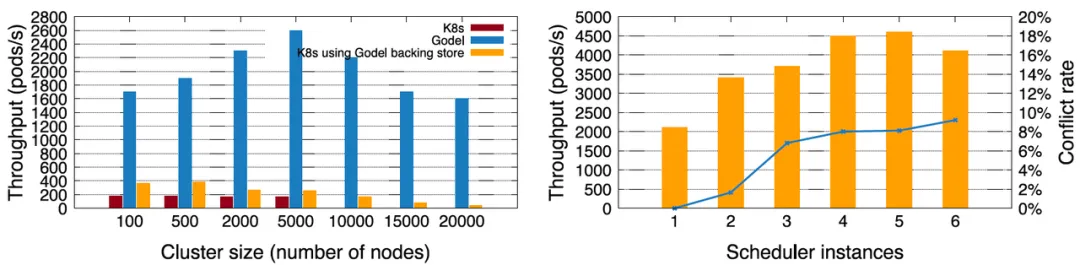
まず、マイクロサービス ビジネスに関して、ByteDance は Gödel (単一インスタンス) と Kubernetes ネイティブ スケジューラーを比較しました。クラスターのスケールに関しては、ネイティブ Kubernetes はデフォルトで最大 5,000 ノードのクラスターのみをサポートし、最大スケジューリング スループットは 200 ポッド/秒未満です。 Byte による高性能のキーバリュー ストア オープン ソースである KubeBrainを使用した後 、ネイティブ Kubernetes は大規模なクラスターをサポートできるようになり、スケジューリングのスループットも大幅に向上しました。しかし、Kubernetes + KubeBrain の組み合わせのパフォーマンスは、依然として Gödel よりもはるかに小さいです。 Gödel は、5,000 ノードのクラスターで 2,600 ポッド/秒のパフォーマンスを達成できますが、20,000 ノードでも依然として約 2,000 ポッド/秒であり、これは ネイティブ Kubernetes スケジューラのパフォーマンスの10 倍以上です。
より高いスケジューリング スループットを実現するために、Gödel は複数のインスタンスを有効にすることができます。下の右の図は、10,000 ノードのクラスター内で 1 ~ 6 のスケジューラー インスタンスが順番に開かれていることを示しています。スループットは初期段階で徐々に増加し、ピーク値は約 4,600 Pod/秒に達することがあります。ただし、インスタンスの数が 5 を超えると、パフォーマンスが低下します。これは、インスタンスの数が増えると、インスタンス間の競合が増加し、スケジューリングの効率に影響するためです。したがって、スケジューリング インスタンスが多ければ多いほど良いというわけではありません。
Gang セマンティック要件を伴うオフライン タスクについて、この論文では、Gödel と、オープンソース コミュニティで一般的に使用されている YARN および K8s-volcano を比較しています。 Gödel のパフォーマンスが K8s-volcano よりもはるかに高いだけでなく、YARN のパフォーマンスのほぼ 2 倍であることがはっきりとわかります。 Gödel は、オンライン タスクとオフライン タスクの同時スケジューリングをサポートしており、システムに送信されるオフライン タスクの割合を変更することで、異なるビジネスが混在するシナリオをシミュレートします。オフライン サービスの割合に関係なく、Gödel のパフォーマンスは比較的安定しており、スループットは約2,000 Pods/sに維持されていることがわかります 。
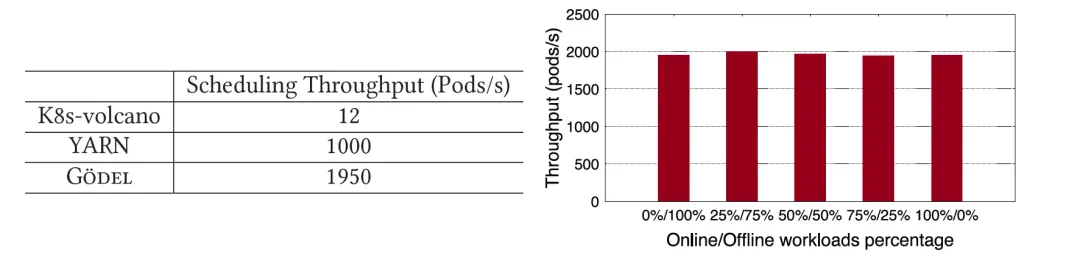
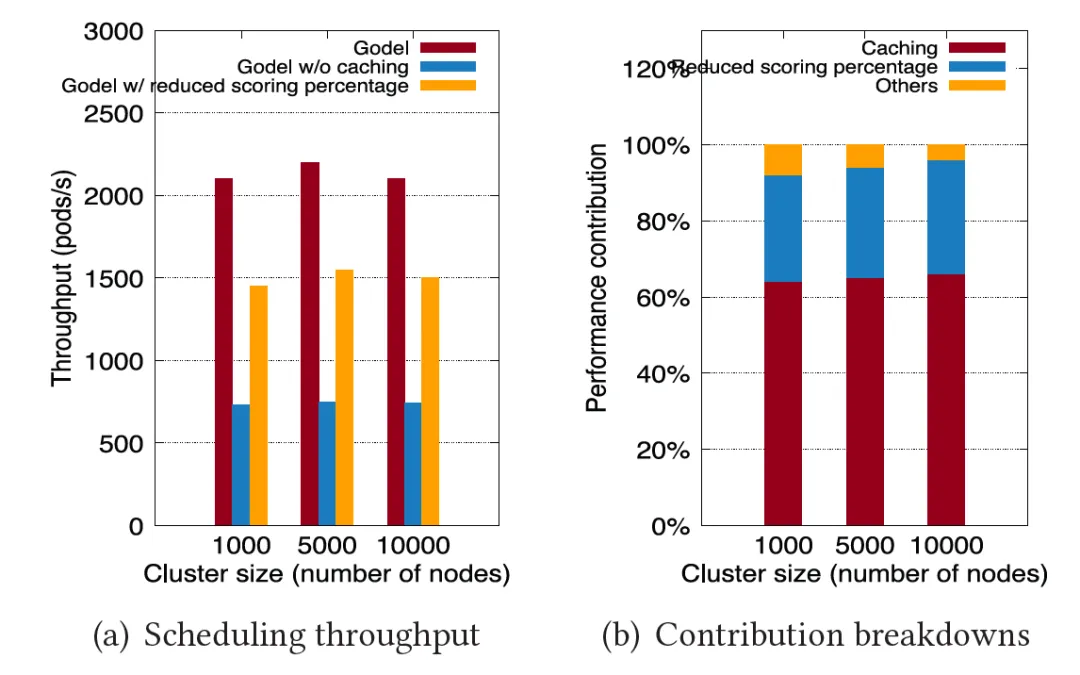
なぜ Gödel によってこれほど大幅なパフォーマンス向上が得られるのかを実証するために、この論文では、「候補ノードのキャッシュ」と「スキャン率の低減」という 2 つの主要な最適化の影響を分析することに焦点を当てています。以下の図に示すように、Gödel のフルバージョン、ノード キャッシュの最適化のみをオンにした Gödel、およびスキャン率の低減のみをオンにした Gödel を使用して前の実験が繰り返されました。実験結果は、これら 2 つの主要な最適化項目が約 100% に寄与することを証明しました。 それぞれ60% と 60 % の パフォーマンスの向上。
ベンチマークを使用してゲーデルの優れたパフォーマンスを評価することに加えて、この論文では、運用環境でゲーデル スケジューラを使用した ByteDance の実際の経験も示しており、ゲーデルがリソース プール、弾力性、循環において優れた機能を備えていることを示しています。
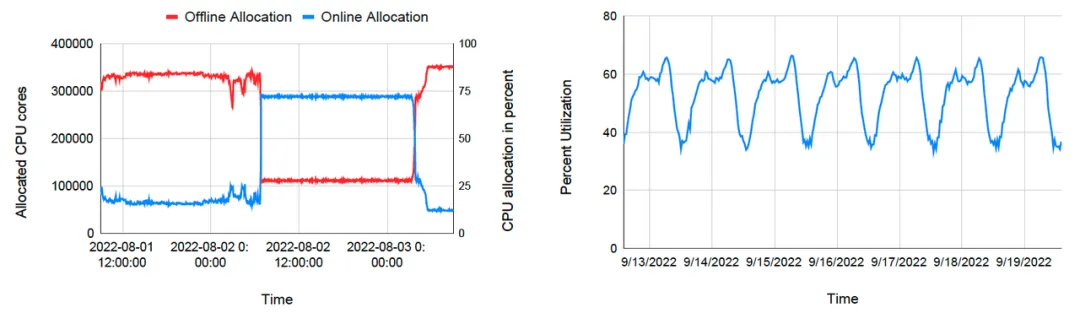
下図左は、あるクラスタにおける一定期間内のオンラインタスクとオフラインタスクのリソース割り当てを表したものです。最初は、オンライン タスクはほとんどリソースを消費せず、優先度の低いオフライン タスクに大量のコンピューティング リソースが割り当てられます。特別なイベント (緊急、ホットサーチなど) によりオンライン タスクのリソース需要が急増した場合、ゲーデルは即座にオンライン タスクにリソースを割り当て、オフライン タスクへのリソース割り当て量は急速に減少します。ピークが過ぎると、オンライン タスクはリソース要求を減らし始め、スケジューラは再びリソースをオフライン タスクにシフトします。オフライン プーリングと動的なリソース転送により、ByteDance は常に高いリソース使用率を維持できます。夕方のピーク時間帯にはクラスターの平均リソース率が 60% 以上に達し、日中の谷期でも約 40% を維持できます。
まとめと今後の展望
この論文では、オフライン リソース プールを統合するために ByteDance オーケストレーションおよびスケジューリング チームによって設計および開発されたスケジューリング システムである Gödel について紹介します。スケジューリング システムは、超大規模クラスターでのオンライン タスクとオフライン タスクの同時スケジューリングをサポートし、リソース プーリング、弾力性、循環をサポートし、高いスケジューリング スループットを備えています。 Gödel は 2022 年に ByteDance の自社データ センターでバッチで開始されて以来、ほとんどの内野企業のコロケーション ニーズを満たし、夕方のピーク時に 60% 以上の平均リソース使用率 と約5,000 ポッド/ポッドのスケジューリング スループットを達成しました。 s 。
今後、オーケストレーションおよびスケジューリング チームは、ゲーデル スケジューラの拡張と最適化を推進し、スケジューリング セマンティクスをさらに強化し、システムの応答性を向上させ、複数インスタンスの状況での競合の可能性を低減するとともに、初期スケジューリングを最適化します。また、システムの再ルーティング機能、設計および開発の Gödel Rescheduler を構築および強化します。 Gödel Scheduler と Rescheduler の共同作業を通じて、サイクル全体を通じてクラスター リソースの合理的な割り当てが実現されます。
Gödel スケジューラは現在オープンソースです。コミュニティ開発者や企業がコミュニティに参加し、プロジェクトの共同構築に参加することを心から歓迎します。プロジェクトのアドレスはgithub.com/kubewharf/godel-schedulerです。

QR コードをスキャンして ByteDance オープンソース コミュニティに参加してください
ライナスは、カーネル開発者がタブをスペースに置き換えるのを防ぐことに自ら取り組みました。 彼の父親はコードを書くことができる数少ないリーダーの 1 人であり、次男はオープンソース テクノロジー部門のディレクターであり、末息子はオープンソース コアです。寄稿者Robin Li: 自然言語 は 新しいユニバーサル プログラミング言語になるでしょう。オープン ソース モデルは Huawei にますます後れをとっていきます 。一般的に使用されている 5,000 のモバイル アプリケーションを Honmeng に完全に移行するには 1 年かかります。 リッチテキスト エディタ Quill 2.0 が リリースされ、機能、信頼性、開発者は「恨みを取り除く 」 ために握手を交わしました。 Laoxiangji のソースはコードではありませんが、その背後にある理由は非常に心温まるものです。Googleは大規模な組織再編を発表しました。