
著者|Cheng Wei、MetaAPPビッグデータ研究開発エンジニア
ByConity は、ByteDance のオープンソースのクラウドネイティブ データ ウェアハウスであり、柔軟なリソースの拡張と縮小、読み書きの分離、リソースの分離、強力なデータの一貫性などのデータ ウェアハウス ユーザーのニーズを満たし、優れたクエリ、書き込みパフォーマンスも提供します。
MetaApp は中国の大手ゲーム開発者および運営者であり、モバイル情報の効率的な配信に重点を置き、あらゆる年齢層向けの仮想世界の構築に取り組んでいます。 2023 年時点で、MetaApp の登録ユーザー数は 2 億人を超え、これまでに 20 万本のゲームとコラボレーションし、累計配信量は 10 億本を超えています。
MetaApp は、オープンソースの初期に ByConity に注目し、実稼働環境で ByConity をテストして起動した最初のユーザーの 1 つでした。オープンソース データ ウェアハウス プロジェクトの機能を理解するという考えのもと、MetaApp ビッグデータ研究開発チームは ByConity で予備テストを実施しました。ストレージとコンピューティングの分離アーキテクチャと、特にログ分析シナリオにおける優れたパフォーマンス、大規模データに対する複雑なクエリのサポートにより、MetaApp は ByConity の詳細なテストを実施するようになり、最終的に実稼働環境で ClickHouse を完全に置き換えて、リソース コストを削減しました。 50% 以上増加しました。
この記事では、MetaAppデータ分析プラットフォームの機能、ビジネスシーンで遭遇する問題と解決策、ByConityのビジネスへの導入支援を中心に紹介します。
MetaApp OLAP データ分析プラットフォームのアーキテクチャと機能
ビジネスの成長と洗練された運用の導入に伴い、製品では、リアルタイム データのクエリと分析、少人数のグループでの運用戦略の迅速な調整など、データ部門に対するより高い要件が求められています。新機能の有効性を検証する データクエリの時間と難易度が軽減され、専門家でなくても独自にデータを分析および探索できるようになります。ビジネス ニーズを満たすために、MateApp はイベント分析、コンバージョン分析、カスタム保持、ユーザー グループ化、行動フロー分析などの機能を統合する OLAP データ分析プラットフォームを実装しました。
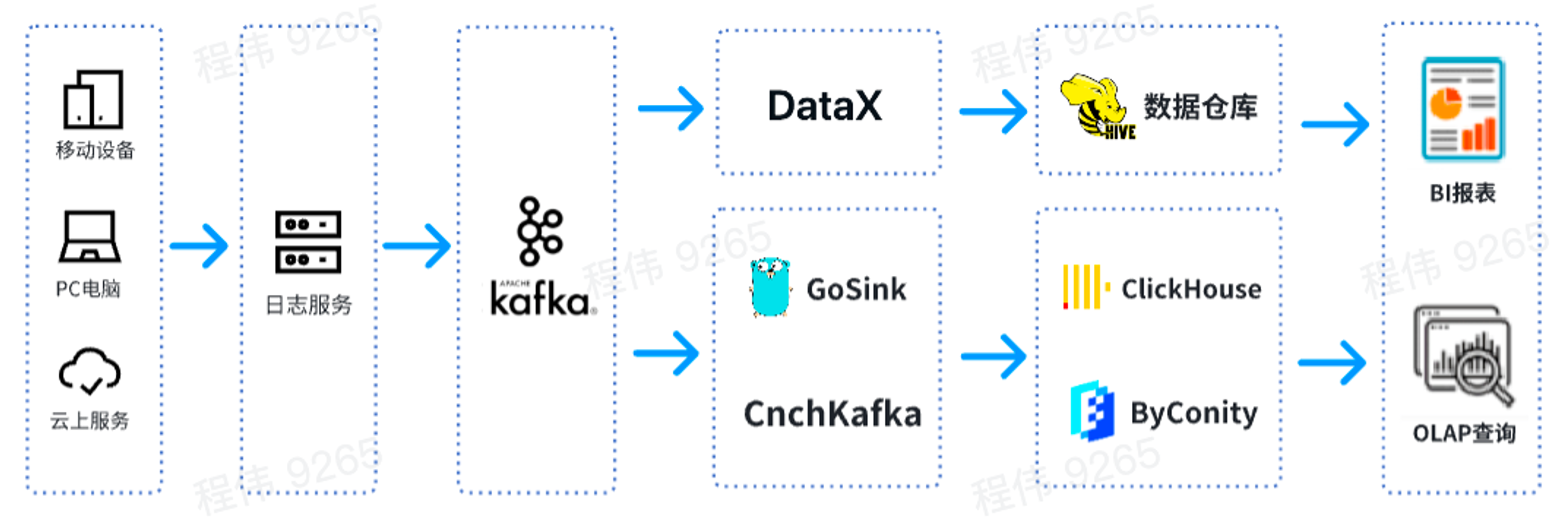
これは典型的な OLAP アーキテクチャであり、オフラインとリアルタイムの 2 つの部分に分かれています。
オフライン シナリオでは、DataX を使用して Kafka データを Hive データ ウェアハウスに統合し、BI レポートを生成します。 BI レポートは、スーパーセット コンポーネントを使用して結果を表示します。
リアルタイム シナリオでは、1 つのラインはデータ統合に GoSink を使用して GoSink データを ClickHouse に統合し、もう 1 つのラインは CnchKafka を使用してデータを ByConity に統合します。最後に、クエリ用の OLAP クエリ プラットフォームを通じてデータが取得されます。
ByConityとClickHouseの機能比較
ByConity は、ClickHouse コアに基づいて開発されたオープンソースのクラウドネイティブ データ ウェアハウスであり、ストレージとコンピューティングの分離アーキテクチャを採用しています。どちらも次のような特徴があります。
- 書き込み速度は非常に速く、大量のデータの書き込みに適しており、書き込まれるデータ量は 50MB ~ 200MB/s に達します。
- クエリ速度は非常に高速で、大量のデータの場合、クエリ速度は 2 ~ 30 GB/秒に達することがあります。
- 高いデータ圧縮率、低いストレージコスト、圧縮率は0.2~0.3に達します。
ByConity は ClickHouse の利点を備え、ClickHouse との良好な互換性を維持し、読み取りと書き込みの分離、柔軟な 拡張と縮小 、および強力なデータ一貫性の点で強化されています。どちらも次の OLAP シナリオに適用できます。
- データセットは大規模になる可能性があります (数十億行または数兆行)
- データテーブルには多くの列が含まれています
- 特定の列のみをクエリする
- 結果はミリ秒または秒単位で返される必要があります
以前の共有で、ByConity コミュニティは [使用法の観点から] 2 つを比較しました。
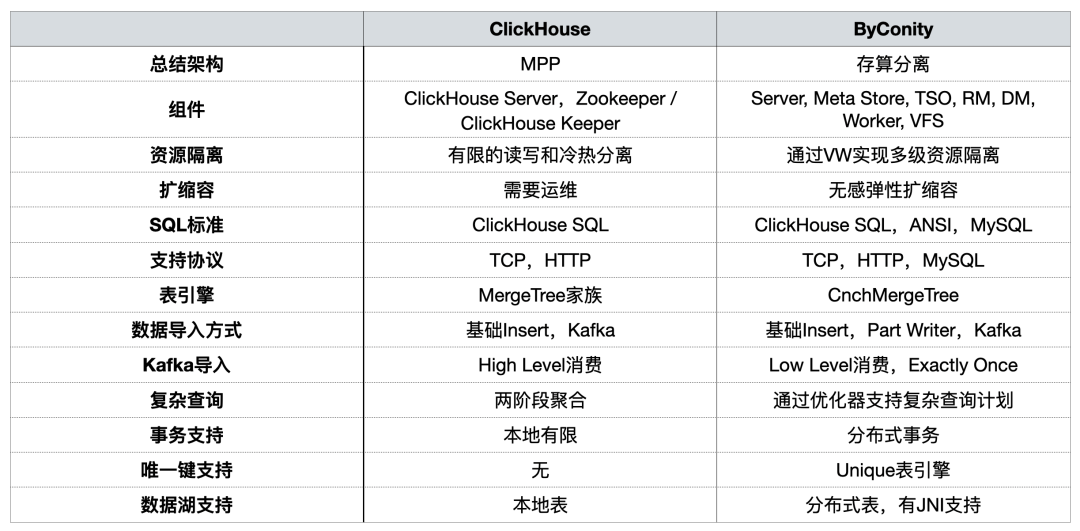
OLAP プラットフォームの構築中、私たちは主にリソースの分離、 容量の拡張と縮小 、複雑なクエリ、分散トランザクションの サポートに焦点を当てました。
ClickHouseの使用時に発生した問題
問題 1: 統合された読み取りと書き込みはリソースを占有しやすく、安定した読み取り/書き込みが保証されません。
ビジネスのピーク時には、データの書き込みに大量の IO リソースと CPU リソースが占有され、クエリに影響が生じます (クエリ時間が長くなります)。データクエリについても同様です。
問題点2: 拡張・縮小 が面倒で時間がかかる
- 長い拡張/縮小時間: マシンは IDC 内にあり、プライベート クラウドに属しているため、ノードの追加サイクルが非常に長いことが問題の 1 つです。ノードの要求が出されてから実際に正常なノードが追加されるまでには 1 ~ 2 週間かかり、ビジネスに影響を及ぼします。
- 迅速なスケールアップとスケールダウンができない: スケールアップ後にデータを再分散する必要があります。そうしないと、ノードの負荷が非常に高くなります。
問題点 3: 運用保守が煩雑であり、繁忙期の SLA が保証できない。
- 多くの場合、ビジネス ノードの障害が原因で、データ クエリが遅くなり、データの書き込みが遅れます (数時間から数日)。
- ビジネスのピーク時には深刻なリソース不足が発生しており、優先度の高いサービスを提供するには一部のサービスのデータを削除するしか方法がありません。
- ビジネスの閑散期には、多くのリソースが使用されておらず、コストが膨らみます。 IDC に属していますが、IDC マシンの購入もコスト管理の対象となり、また、通常の使用中に無制限にノードを拡張することはできません。
- クラウド リソースと対話できません。
ByConity導入後の改善点
まず、ByConity では読み取りと書き込みのコンピューティング リソースが分離されているため、読み取りと書き込みのタスクが比較的安定しています。読み取りタスクが十分でない場合は、拡張にクラウド リソースを使用するなど、対応するリソースを拡張して不足を補うことができます。
次に、スケールアップとスケールダウンは比較的簡単で、分レベルで実行できます。 HDFS/S3分散ストレージを採用し、コンピューティングとストレージが分離されているため、拡張後のデータの再分散が不要で、拡張後すぐに利用可能です。
また、クラウドネイティブの導入や運用・保守も比較的簡単です。
- HDFS/S3 のコンポーネントは比較的成熟していて安定しており、容量の拡張と縮小、成熟した災害復旧ソリューションがあり、問題は迅速に解決できます。
- ビジネスのピーク期間中は、リソースを急速に拡張することで SLA を保証できます。
- ビジネスの閑散期には、ストレージ/コンピューティング リソースを削減することでコストを削減できます。
ByConityの使用と運用
ByConity クラスターの使用状況
現在、当社のプラットフォームはビジネス シナリオで ByConity を安定して使用しています。継続的な移行により、ByConity は ClickHouse クラスターのデータを完全に引き継ぎ、安定したサービスを提供し始めました。クラウド上で S3 と K8 を使用して ByConity クラスターを構築しました。また、平日の午前 10 時に拡張し、午後 8 時に削減できる、スケジュールされた拡張および縮小ソリューションも使用しました。日。 。計算によると、この方法では、年間および毎月のサブスクリプションを直接使用する場合と比較して、リソースが約 40% ~ 50% 削減されます。また、コスト削減とサービスの安定性向上という目的を達成するために、プライベートクラウド+パブリッククラウドの組み合わせも推進しています。
以下の図は、OLAP サーバーを使用して、オフライン IDC コンピューター ルームの ClickHouse クラスターと ByConity で共同クエリを実行する現在の使用状況を示しています。短期的には、ClickHouse クラスターは、ClickHouse に部分的に依存している企業の移行手段として引き続き使用されます。
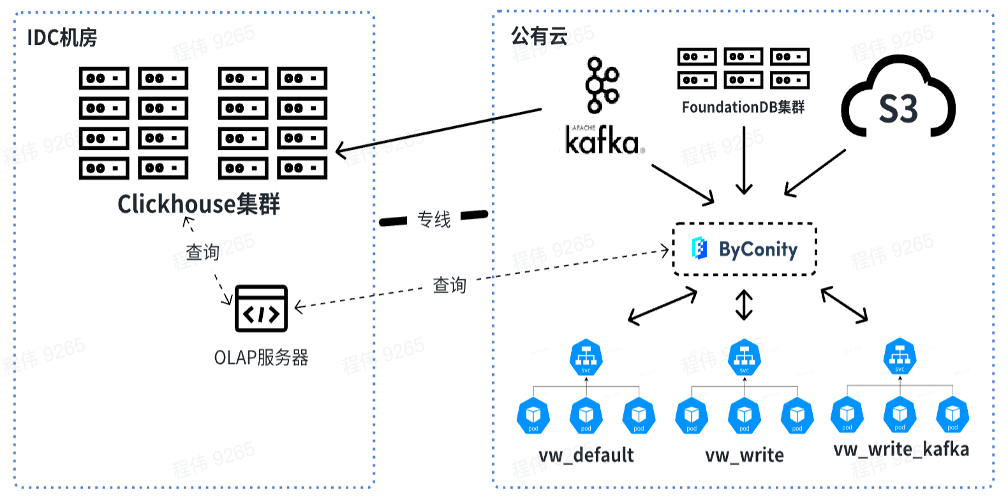
将来的には、オフラインでデータのクエリとマージを実行し、Kafka によって消費されるリソースはオンラインで使用されるようになります。リソースを拡張する場合、vw_default および vw_write のリソースをオンラインで拡張し、パブリック クラウドのリソースを合理的に使用して、リソース不足の問題に対処できます。同時に、ビジネスの閑散期には容量が削減され、パブリック クラウドの消費量が削減されます。
ビジネス データにおける ByConity クエリと ClickHouse クエリの比較
テストデータセットとリソース構成
- データ件数:日付ごとに分割、1日で40億件、10日間で合計400億件
- 表形式データ: 2800 列
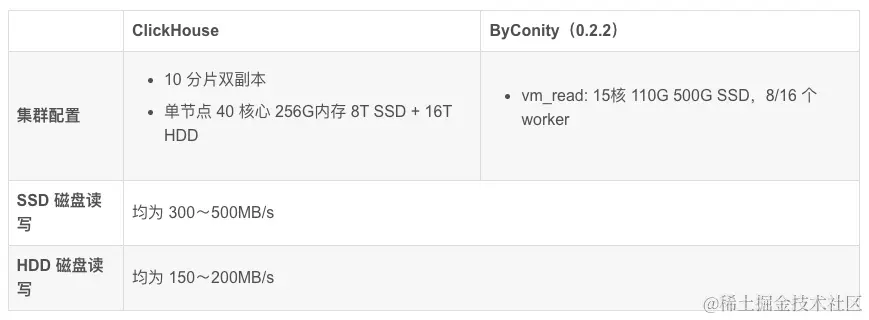
上の表からわかるように:
ClickHouse クラスター クエリで使用されるリソースは次のとおりです: 400 コアと 2560G メモリ
ByConity 8 ワーカー クラスター クエリで使用されるリソースは次のとおりです: 120 コアと 880G メモリ
ByConity 16 ワーカー クラスター クエリで使用されるリソースは次のとおりです: 240 コアと 1760G メモリ
ビジネス SQL クエリ結果の概要
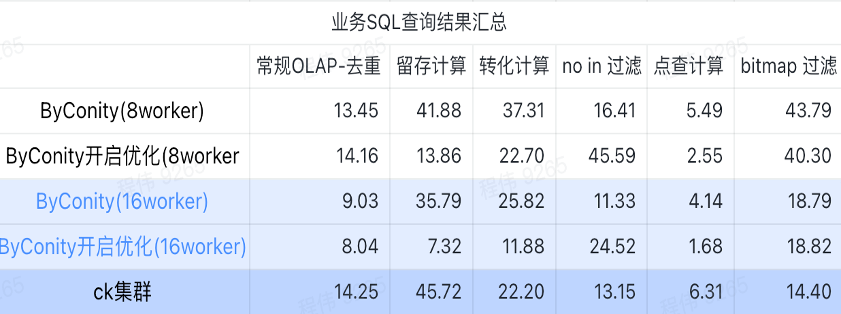
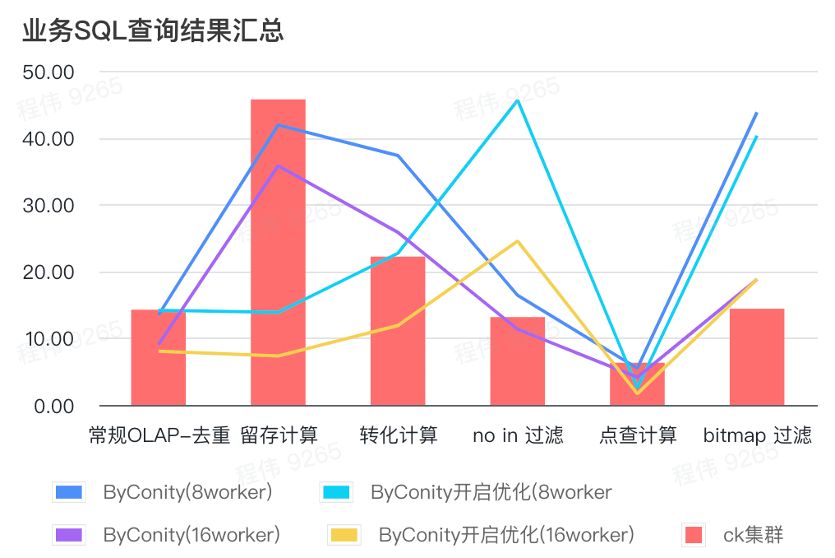
ご覧のとおり、ここでの概要では平均値が使用されています。
- 従来の OLAP - 重複排除、保持、変換、および列挙は、比較的少ないリソース コスト (120C、880G) で ClickHouse クラスター (400C、2560G) と同じクエリ効果を達成でき、リソース (240C、1760G) を拡張することで 2 倍にすることができます。 ) クエリ速度を 2 倍にする効果を実現します。より高いクエリ速度が必要な場合は、より多くのリソースを拡張できます。
- フィルタリングを行わない場合、ClickHouse クラスター (400C、2560G) と同様の効果を達成するには、中程度のリソース コスト (240C、1760G) が必要になる場合があります。
- ビットマップでは、ClickHouse クラスターと同様の効果を実現するには、より多くのリソース コストが必要になる場合があります。
一般クエリ/イベント分析クエリ
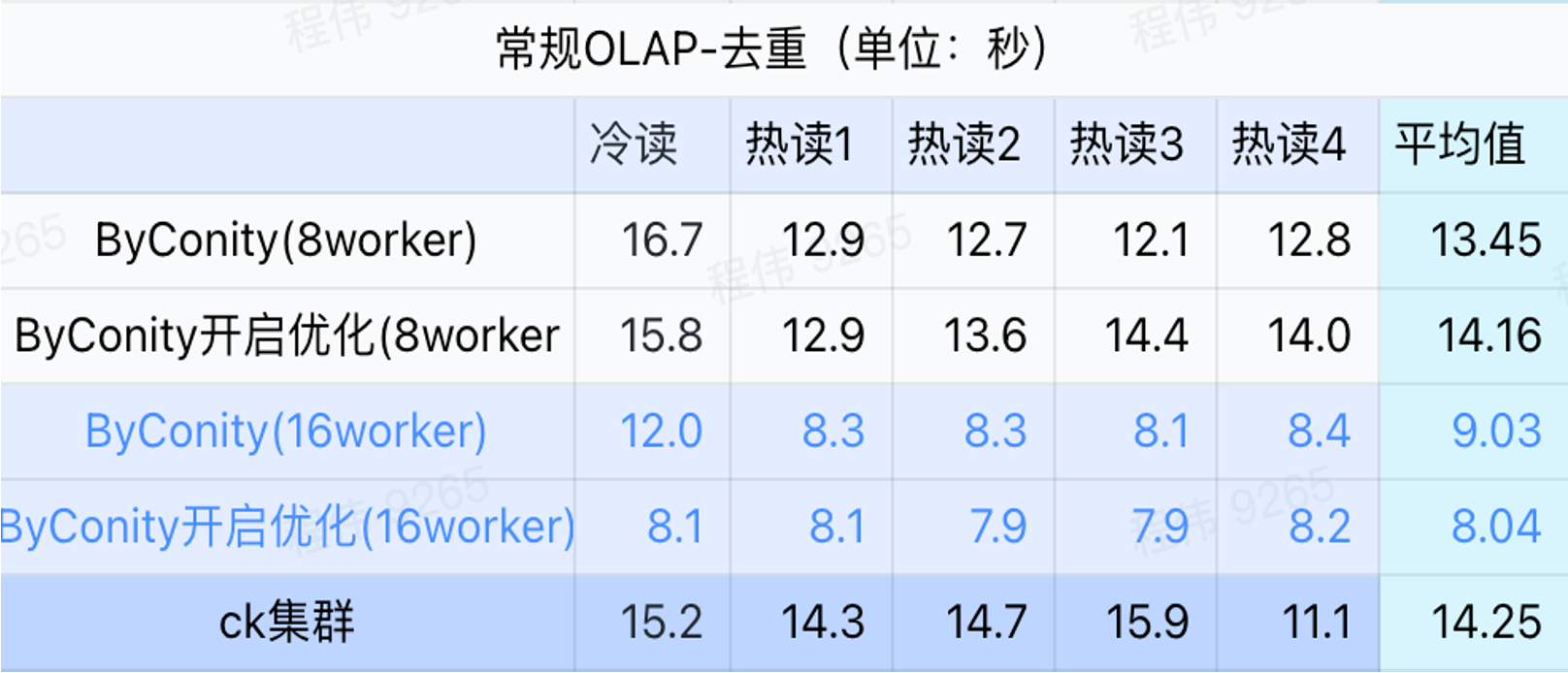
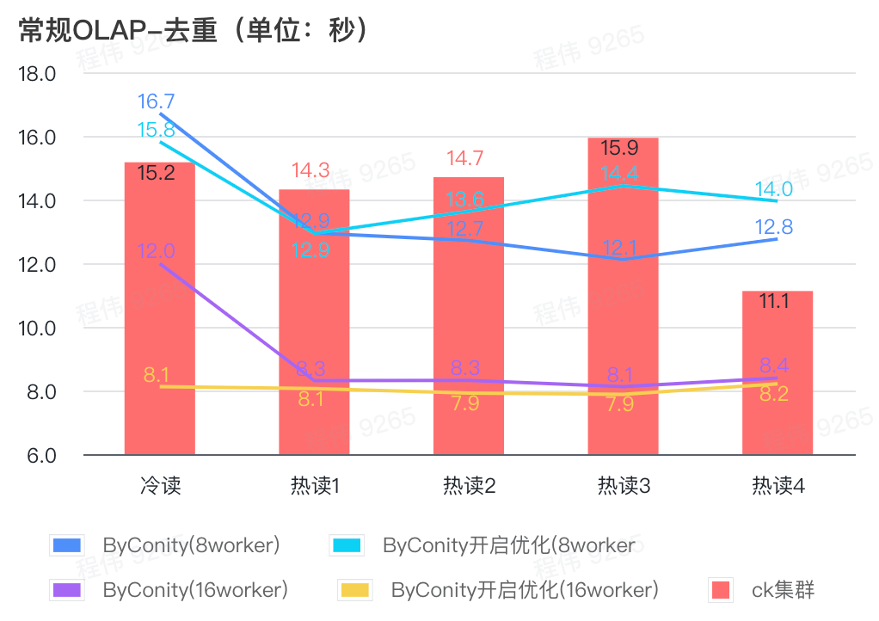
上の図からわかるように:
- 重複排除クエリのシナリオでは、ByConity の最適化を有効にする場合と無効にする場合に大きな違いはありません。
- 8 ワーカー (120C 880G) は基本的に ClickHouse に近いクエリ時間を達成します。
- 重複排除シナリオでは、コンピューティング リソースを拡張することでクエリ速度を高速化できます。
保持率の計算
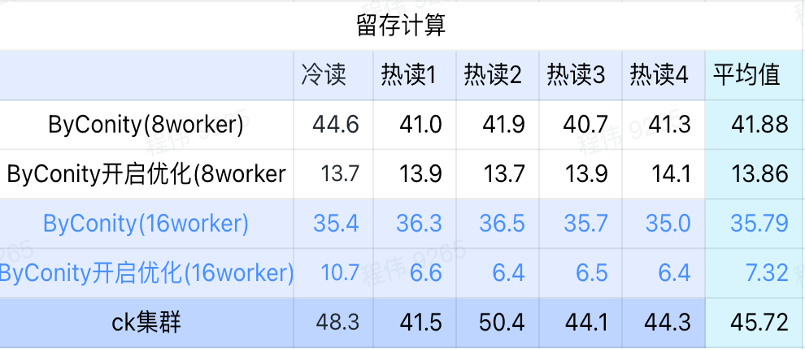
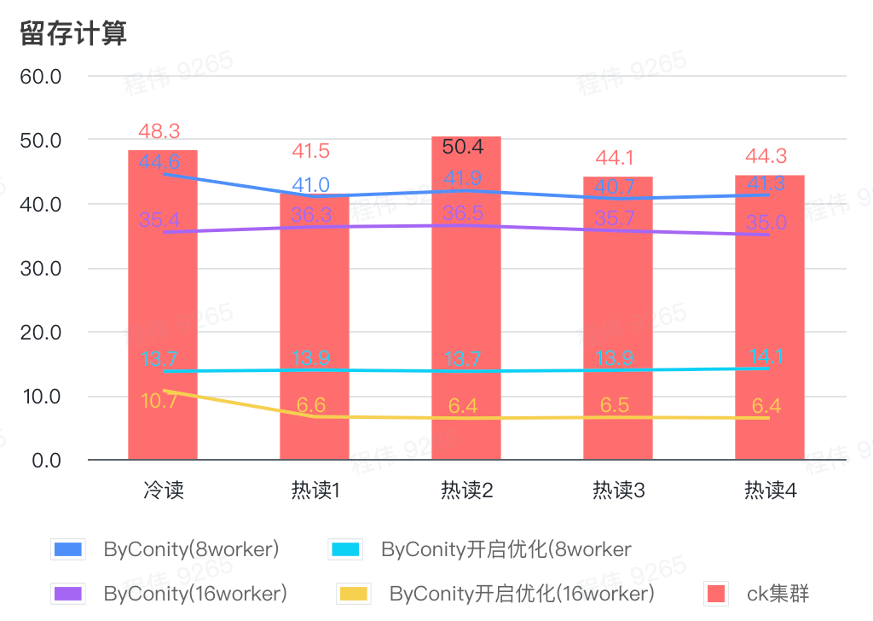
上の図からわかるように:
- 保持型コンピューティング シナリオでは、ByConity が最適化をオンにした後のクエリ時間は、最適化をオンにしない場合のクエリ時間の 33% です。
- 8 ワーカー (120C 880G) 最適化をオンにした場合のクエリ時間はクエリ時間の 30% です。
- 保持型コンピューティング シナリオでは、コンピューティング リソースの拡張と最適化により、クエリ速度を CK クエリ時間の 16% まで高速化できます。
換算計算
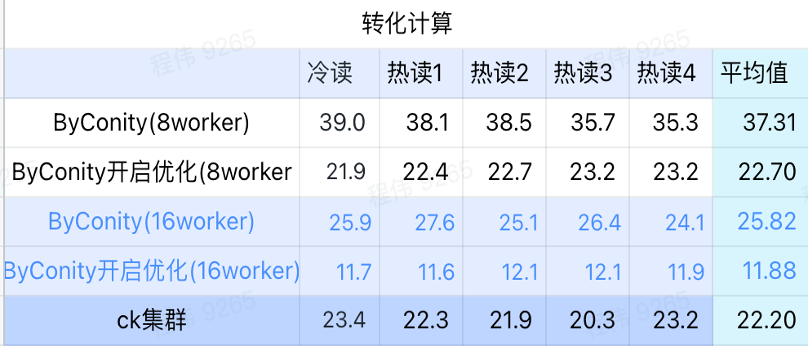
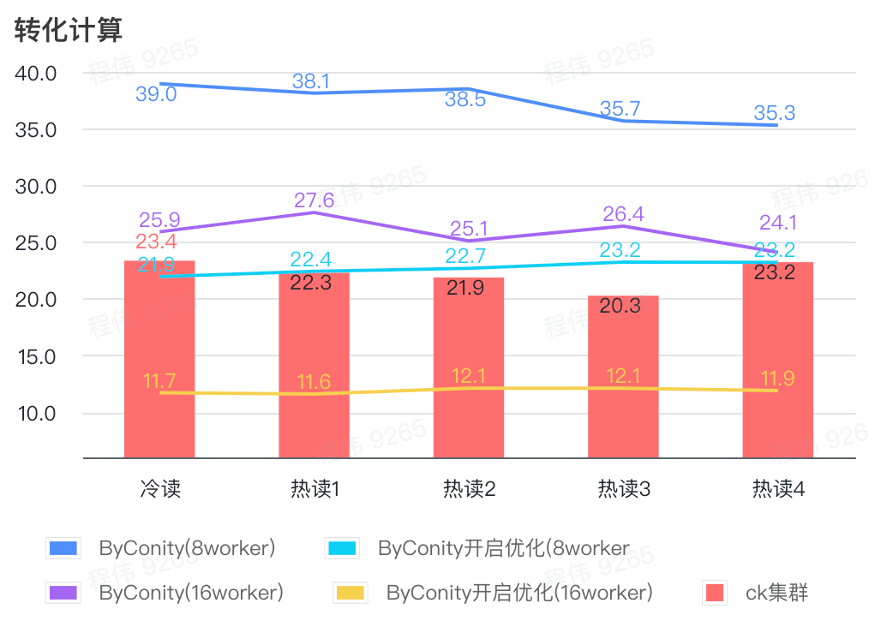
上の図からわかるように:
- 変換計算シナリオでは、ByConity の最適化が有効になった後のクエリ時間は、最適化なしのクエリ時間の 60% になります。
- 最適化をオンにした 8 ワーカー (120C 880G) のクエリ時間は、ClickHouse のクエリ時間に近いです。
- コンピューティング シナリオを変革し、コンピューティング リソースの拡張と最適化により、クエリ速度を ClickHouse クエリ時間の 53% まで加速できます。
フィルターに入っていない
「フィルタリングに含まれていない」は、主にユーザーのグループ化シナリオとユーザーのタグ付けシナリオで使用されます。

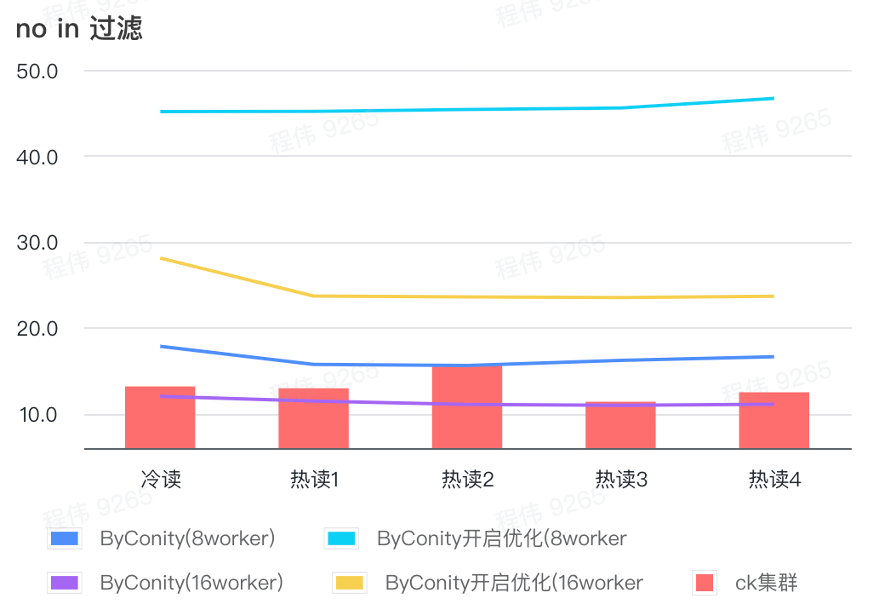
上の図からわかるように:
- フィルタリングなしのシナリオでは、最適化がオンになっている ByConity は、最適化がオンになっていない ByConity よりも悪いため、このシナリオでは、最適化をオンにしない方法を直接使用します。
- 最適化なしの 8 ワーカー (120C 880G) のクエリ時間は、ClickHouse のクエリ時間よりも遅くなりますが、それほど多くはありません。
- フィルタリング シナリオでは、コンピューティング リソースを拡張することで、クエリ速度を ClickHouse クエリ時間の 86% まで高速化できます。
クリック計算 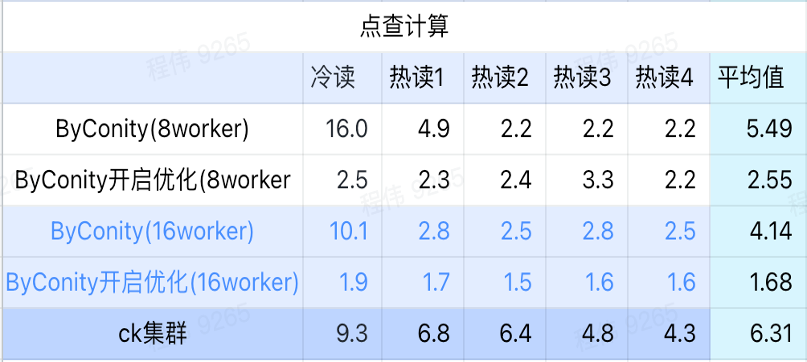
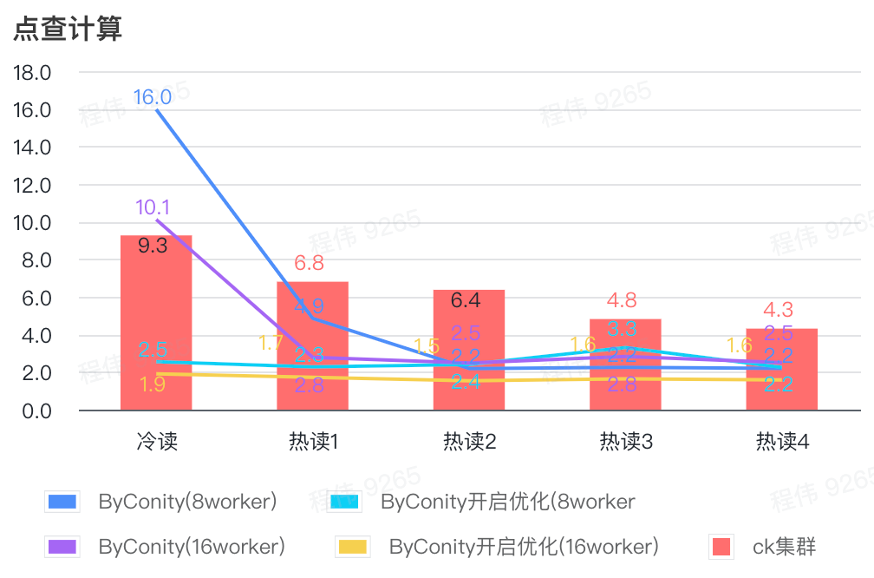
上の図からわかるように:
- シーンを確認した後、ByConity で最適化をオンにしないよりも、ByConity をオンにして最適化する方が良いでしょう。
- 最適化なしの 8 ワーカー (120C 880G) のクエリ時間は、ClickHouse のクエリ時間に近いです。
- クリックスルー シナリオでは、コンピューティング リソースを拡張し、最適化を有効にすることで、クエリ速度を ClickHouse クエリ時間の 26% まで高速化できます。
ビットマップクエリ
ビットマップ クエリは、AB テストでよく使用されるシナリオです。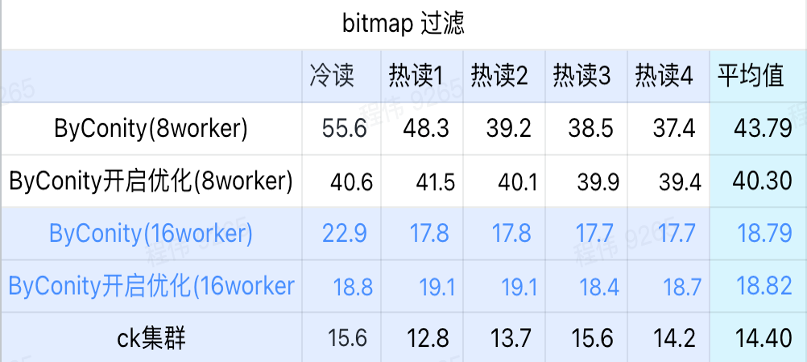
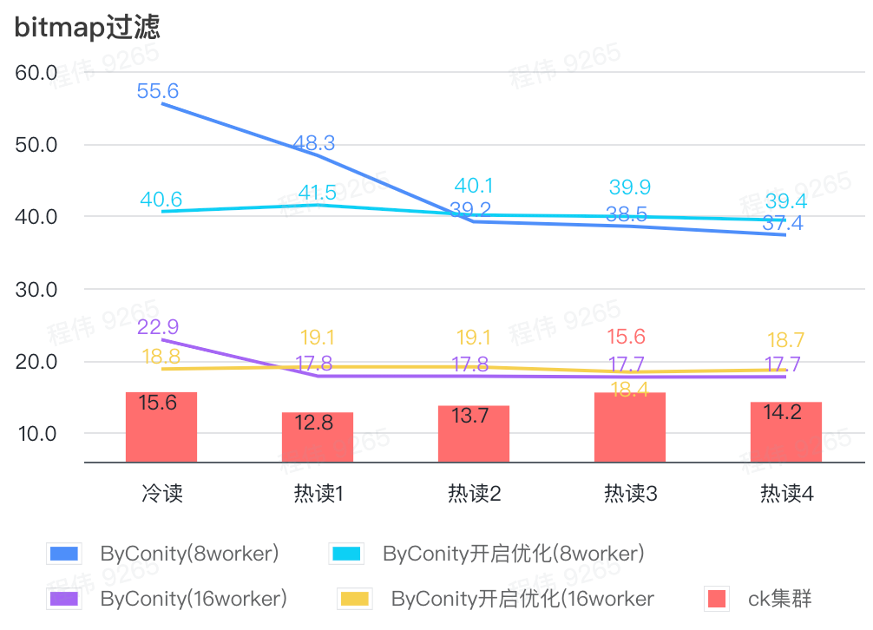
上の図からわかるように:
- ビットマップ フィルタリング シーンでは、ByConity 最適化を使用しないよりも ByConity 最適化をオンにした方が良いでしょう。
- 最適化なしの 8 ワーカー (120C 880G) のクエリ時間は、ClickHouse のクエリ時間よりも大幅に遅くなります。
- ビットマップ フィルタリング シーン、リソースを 16 ワーカー (240C 1769G) に拡張すると、ClickHouse クエリよりも遅くなります。
ByConity の完全移行後の利益
資源の削減
以下は CPU の違いを考慮したものではありません。データは参考用です。
ByConity を使用した完全な移行後
- クエリとマージのリソース消費量を比較すると、CPU 消費量が以前と比べて約 75% 削減されていることがわかります。
- データ書き込みリソースを比較すると、CPU消費量が従来に比べて約35%削減されています。
- 購入する必要があるのは固定リソースの半分だけで、残りの半分は勤務日の柔軟性 (午前 10 時から午後 8 時まで) に依存します。コストは、リソースの全量を購入する場合と比べて約 25% 削減されます。
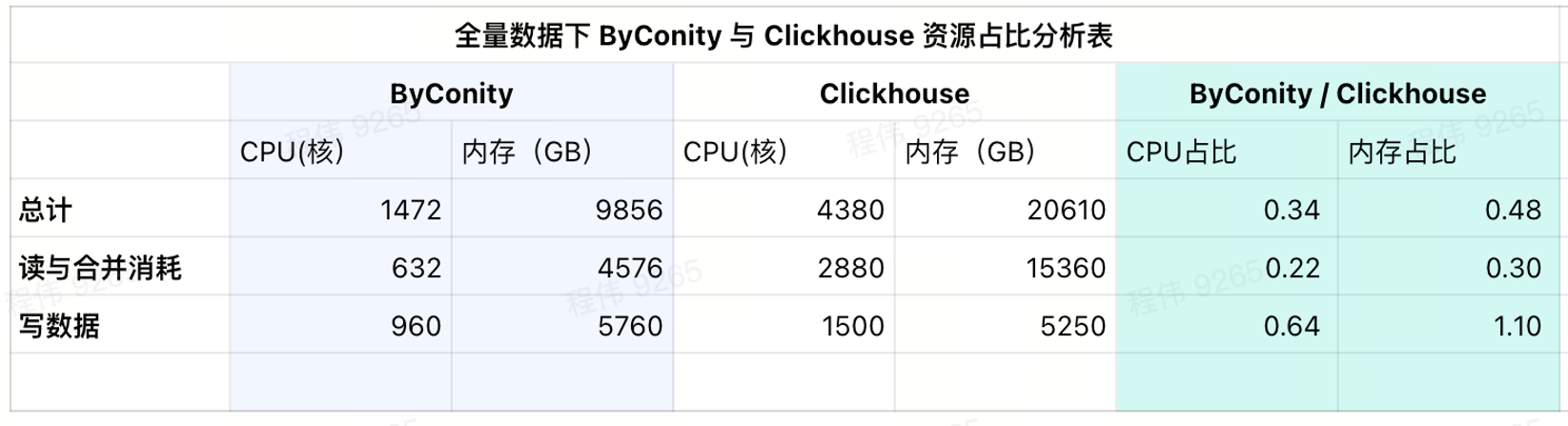
現在の使用量消費量
現在の結果表からわかるように、ByConity の CPU とメモリの比率はそれぞれ ClickHouse の 34% と 48% です。
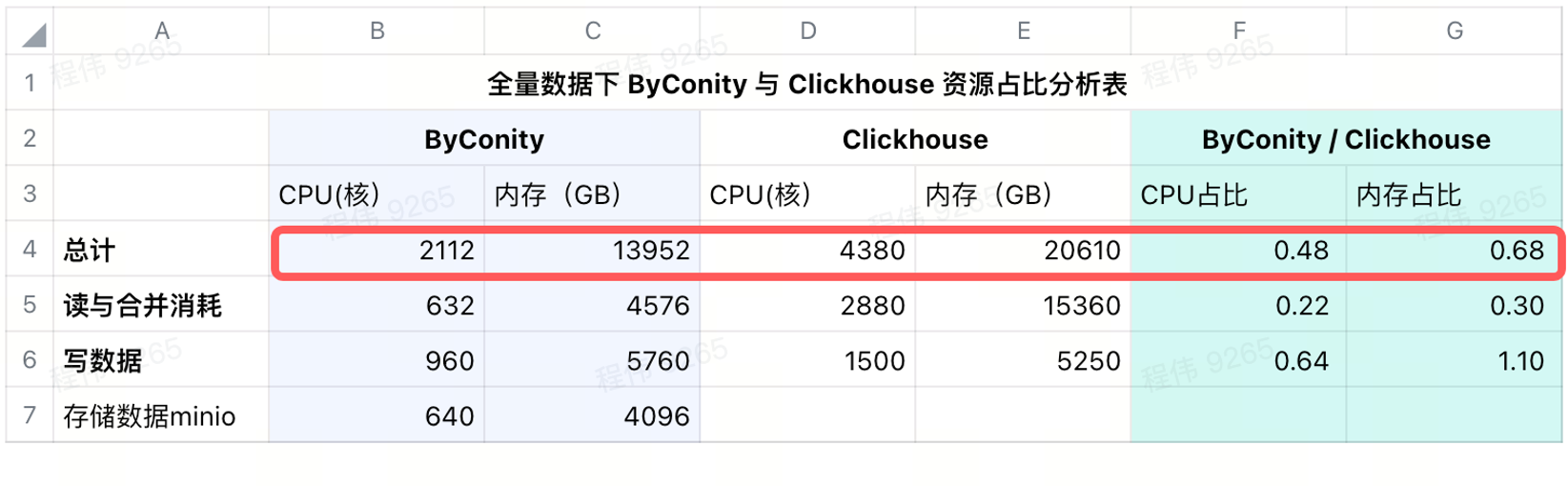
リモートストレージ追加後の消費量
IDC のデータ ストレージには minio を使用し、640 コアの CPU、4096G のメモリ、16 ノード、40 コアの単一ノード、256G、および 36T のディスクを使用しています。これらのコストを ByConity に加算した後の ByConity の CPU とメモリの比率は次のようになります。 ClickHouse よりも低く、それぞれ ClickHouse の 48% と 68% です。リソース使用量に関しては、年および月ベースで計算すると、ByConityをオンデマンドで開始および停止すると、コストは約 25% 削減され、従来よりも少なくとも約 50% 削減されると言えます。 リソースを全額購入する場合と比較して 。
運用および保守コストの削減
- 構成データを書き込む簡単な方法。これまで、特別に設定した書き込みサービスでは、パーツが多すぎるなどの問題が頻繁に発生していました。
- ピーク クエリの拡張は簡単で、ポッドの数を追加するだけですぐに容量を拡張できます。「なぜ 30 分チェックしてもデータが出力されなかったのですか?」と尋ねる人はいません。
ClickHouse を ByConity に置き換えるための提案
- SQL がビジネスの ByConity プラットフォームで正常に実行できるかどうかをテストします。互換性がある場合は、基本的に実行されます。個々のケースで軽微な問題がある場合は、コミュニティで問題を提起して、すぐにフィードバックを得ることができます。
- テスト クラスターのリソースを制御し、データ セット サイズをテストし、ByConity クラスターと ClickHouse クラスターのクエリ結果を比較して、期待を満たしているかどうかを確認します。予想される場合は、交換を計画できます。計算に重点を置いたタスクの場合、ByConity の方がパフォーマンスが向上する可能性があります。
- テスト データ セットのサイズ、消費された S3 および HDF スペース、帯域幅、QPS コンピューティング リソースの使用量に基づいて、全量のデータのストレージとコンピューティングに必要なリソースが評価されます。
- ByConity または ClickHouse クラスターに同時にデータを入力し、一定期間デュアル実行を開始して、デュアル実行中に発生する問題を解決します。例えば、社内にリソースが足りない場合は、まずクラウド上にByConityクラスターを構築し、業務の一部を移行し、空いた後に徐々に置き換えていきます。 IDC リソースでは、これらを移動できます。データの一部はオフラインで移行されます。
- デュアル実行で問題がなくなったら、ClickHouse クラスターからサブスクライブを解除できます。
このプロセスでは、いくつかの考慮事項があります。
- S3 および HDFS リモート ストレージの読み取り帯域幅と QPS は高くなる可能性があり、特定の準備が必要です。たとえば、1 秒あたりのピーク読み取りおよび書き込み帯域幅は、書き込み 2.5 GB/読み取り 6 GB、1 秒あたりのピーク QPS は、2 ~ 6k です。
- ワーカー ノードの帯域幅がいっぱいになると、クエリのボトルネックも発生します。
- デフォルト ノード (つまり、読み取りコンピューティング ノード) のキャッシュ ディスクは、適切に大きくなるように構成できます。これにより、クエリ中の S3 の帯域幅の圧力が軽減され、クエリが高速化されます。
- キャッシュされていないデータが見つかった場合は、コールド スタートの問題が発生する可能性があります。 ByConity には、これに対する運用上の提案もいくつかありますが、これは自社のビジネスとより統合する必要があります。たとえば、コールド スタートの問題のこの部分を軽減するために、午前中に事前チェックを使用します。
これからの計画
今後、ByConityデータレイクソリューションのテストと導入を推進してまいります。さらに、データ インジケーター管理とデータ ウェアハウス理論を組み合わせて、クエリの 80% がデータ ウェアハウスに当てられるようにします。どなたでもぜひ体験にご参加ください。
GitHub |https://github.com/ByConity/ByConity

QR コードをスキャンして ByConity Assistant を追加します
仲間のニワトリがDeepin-IDE を 「オープンソース」化し、ついにブートストラップを達成しました。 いい奴だ、Tencent は本当に Switch を「考える学習機械」に変えた Tencent Cloud の 4 月 8 日の障害レビューと状況説明 RustDesk リモート デスクトップ起動の再構築 Web クライアント WeChat の SQLite ベースのオープンソース ターミナル データベース WCDB がメジャー アップグレードを開始 TIOBE 4 月リスト: PHPは史上最低値に落ち、 FFmpeg の父であるファブリス ベラールはオーディオ圧縮ツール TSAC をリリースし 、Google は大規模なコード モデル CodeGemma をリリースしました 。それはあなたを殺すつもりですか?オープンソースなのでとても優れています - オープンソースの画像およびポスター編集ツール