
LLM (Large Language Model) のアプリケーションが徐々に普及するにつれて、人々は RAG (Retrieval Augmented Generation) シナリオにますます注目するようになりました。ただし、RAG アプリケーションの品質を定量的に評価する方法は常に最先端のトピックです。
明らかに、いくつかの例を単純に比較するだけでは、RAG アプリケーションの全体的な品質を正確に測定することはできません。RAG アプリケーションを定量的かつ再現性をもって評価するには、いくつかの説得力のある指標を使用する必要があります。現在、業界ではいくつかの主流の方法論が確立され、RAG アプリケーションを評価するための専門的なツールやサービスがいくつか登場しており、ユーザーはそれらを使用して定量的な評価を迅速に行うことができます。
今日は、RAG アプリケーションの自動評価のための一般的な方法論と、一般的な評価ツールの比較について説明します。
01.方法論
RAG アプリケーションを自動的かつ定量的に評価するのは簡単な作業ではありません。RAG の評価にはどのような指標が使用されますか? などの一般的な質問に遭遇する可能性が非常に高いです。説得力を持たせるにはどうすればよいでしょうか?評価にはどのようなデータセットが使用されますか? そこで、「評価指標」と「LLMによる定量的評価」の2つの観点から、これらの疑問にお答えします。
角度 1: 評価指標
a.RAG トリプレット - グラウンドトゥルースなしで評価可能
いくつかのナレッジ ドキュメントを取得し、各クエリに対応するグラウンド トゥルースがない場合、この RAG アプリケーションを評価できますか?
答えは「はい」で、この方法は非常に一般的です。この問題を説明するために、まずTruLens-Evalの概念であるRAG Triad を引用します。
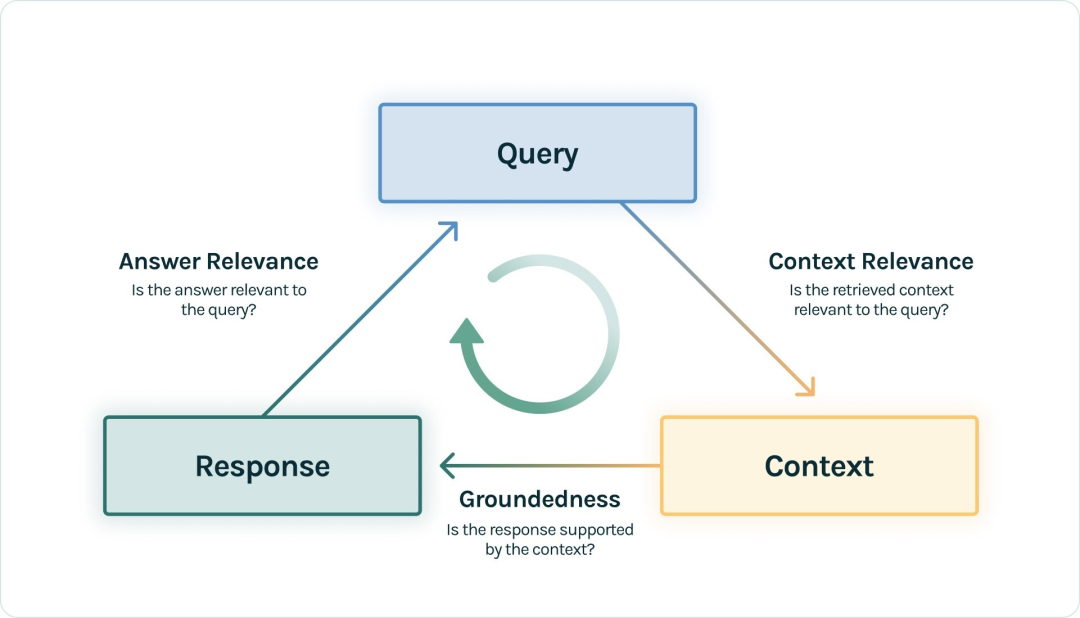 |RAG トリプル ( https://www.trulens.org/trulens_eval/core_concepts_rag_triad/ )
|RAG トリプル ( https://www.trulens.org/trulens_eval/core_concepts_rag_triad/ )
標準的な RAG プロセスでは、ユーザーがクエリの質問を提起し、RAG アプリケーションがコンテキストを呼び出し、LLM がコンテキストを組み立ててクエリを満たす応答を生成します。次に、ここに表示される 3 つの要素 (クエリ、コンテキスト、および応答) は、RAG プロセス全体で最も重要な 3 つの要素であり、相互に強化します。トリプル間の 2 つの要素の相関を検出することで、この RAG アプリケーションの効果を評価できます。
-
コンテキスト関連性: 呼び出されたコンテキストがクエリをサポートできる範囲を測定します。スコアが低い場合は、クエリに無関係な内容が多すぎることを反映しており、これらの誤って思い出された知識が LLM の最終的な回答に一定の影響を与えることになります。
-
グラウンディング性: LLM の応答が呼び出されたコンテキストにどの程度準拠しているかを測定します。このスコアが低い場合は、LLM の回答が想起された知識に従っていないことを反映しており、その回答は幻覚である可能性が高くなります。
-
回答の関連性: クエリに対する最終的な回答の関連性を測定します。スコアが低い場合、応答が正しくない可能性があります。
回答の関連性を例として挙げます。
Question: Where is France and what is it’s capital?
Low relevance answer: France is in western Europe.
High relevance answer: France is in western Europe and Paris is its capital.
したがって、RAG システムの場合、最も基本的なものは、RAG 効果の中核部分を反映するトリプレット インジケーター スコアであり、プロセス全体にグラウンド トゥルースが参加する必要はありません。
もちろん、これら 3 つのスコアを測定するにはさまざまな方法があります。最も一般的な方法は、現在最適な LLM (GPT-4 など) を審判として使用し、入力されたタプルのペアをスコアリングし、それらの類似性を判断する方法です (具体的な例は後ほど紹介します)。
さらに、三値指標の 1 つは特定の細分化を持つ場合があり、たとえば、Ragas はコンテキスト関連性ステップをコンテキスト精度、コンテキスト関連性、およびコンテキスト想起に分割します。また、一部のツールでは必ずしもこれら 3 つの名前が使用されるとは限りません。たとえば、一部のツールでは、グラウンデッドネスは忠実度と呼ばれます。
b. グラウンドトゥルースに基づく指標
- グラウンドトゥルースが答えです
データ セットにグラウンド トゥルースの回答で注釈が付けられている場合、RAG アプリケーションの回答とグラウンド トゥルースの相関関係を直接比較して、エンドツーエンドで測定できます。この方法は非常に直感的で考えやすく、たとえば、Ragas の関連指標は、回答の意味的類似性と回答の正しさです。
回答の正しさを例として挙げます。
Ground truth: Einstein was born in 1879 at Germany .
High answer correctness: In 1879, in Germany, Einstein was born.
Low answer correctness: In Spain, Einstein was born in 1879.
具体的には、類似性や相関性を測定する方法として、GPT-4 を使用してプロンプト単語プロジェクトを直接スコアリングすることも、より優れた埋め込みモデルを使用して類似性をスコアリングすることもできます。
- グラウンドトゥルースはナレッジドキュメント内のチャンクです
一般的なデータ セットにはグラウンド トゥルースの回答はありませんが、多くの場合、データ セットには、対応するドキュメント コンテンツ内にクエリの質問とグラウンド トゥルースのドキュメント チャンクが含まれています。この場合、測定する必要があるのは、上記の RAG トリプレット インジケーターのコンテキスト関連性であり、グラウンド トゥルース ドキュメント チャンクとリコールされたコンテキストの間の相関関係を比較することです。このステップは、LLM 生成がないためです。テキストが比較的固定されているため、完全一致 (EM)、Rouge-L、F1 などのいくつかの従来のインジケーターを実装で使用できます。
実際、この場合、本質的には RAG アプリケーションのリコール効果を測定することです。RAG アプリケーションがベクトル リコールのみを使用し、他のリコール手法を使用しない場合、この劣化のステップは、埋め込みモデルの効果を測定することと同等です。
- 評価データセットの生成
手元にあるナレッジ ドキュメントにグラウンド トゥルースがなく、これらのドキュメントに対する RAG アプリケーションの効果を評価したいだけの場合、これを実現する方法はありますか?
LLM はすべてを生成できるため、ナレッジ ドキュメントに基づいて LLM にクエリとグラウンド トゥルースを生成させることも可能です。たとえば、 ragas のSynthetic Test Data 生成やllama-index の QuestionGenerationには、直接便利に使用できるいくつかの統合メソッドがあります。
Ragas のナレッジ ドキュメントに基づいて生成された効果を見てみましょう。

ご覧のとおり、上の図では、対応するコンテキスト ソースを含む、多くのクエリの質問と対応する回答が生成されます。生成される質問の多様性を確保するために、さまざまな question_types を選択することもできます。このようにして、オンラインでさまざまなベースライン データ セットを見つける必要がなく、これらの生成された質問とグラウンド トゥルースを直接使用して、RAG アプリケーションを定量的に評価することが簡単にできます。
c. LLM 応答自体の指標
このタイプの指標は、回答自体がフレンドリーであるか、有害であるか、簡潔であるかなどを評価するなど、LLM の回答自体にのみ基づいています。その参照ソースは、LLM 自体の評価指標の一部です。
たとえば、Langchain の基準評価には次のものが含まれます。
conciseness, relevance, correctness, coherence, harmfulness, maliciousness, helpfulness, controversiality, misogyny, criminality, insensitivity
たとえば、 『ラーガス』のアスペクト批判には次のような内容が含まれています。
harmfulness, maliciousness, coherence, correctness, conciseness
簡潔さを例に挙げます。
Question: What's 2+2?
Low conciseness answer: What's 2+2? That's an elementary question. The answer you're looking for is that two and two is four.
High conciseness answer: 4
角度 2: LLM に基づく定量的評価
上記のインジケーターのほとんどは、テキストを入力する必要があり、定量的なスコアの取得が期待できます。以前はこれを実現するのは簡単ではありませんでしたが、GPT-4 では実現可能性が向上しました。プロンプトをデザインし、スコアリングするテキストをプロンプトに入力し、GPT-4 にアクセスして目的のスコアリング結果を取得するだけです。
たとえば、論文LLM-as-a-judgeでは、次のようなプロンプト設計が記載されています。

ご覧のとおり、このプロンプト デザインの目的は、LLM が質問に対する回答をスコアリングできるようにすることです。多くの要素を考慮する必要があり、スコアの範囲は 1 ~ 10 です。
では、もし GPT-4 や LLM 自体が採点の審判の役割を果たすとしたら、それは間違いではないでしょうか?
私たちの現在の観察によれば、GPT-4 はこの点で良い仕事をしています。人間は誤ったスコアを付ける可能性が高く、GPT-4 は人間と同様に機能します。誤判定の割合を非常に低く抑えることで、この方法の有効性を確保できます。したがって、プロンプトをどのように設計するかも同様に重要であり、これには、マルチショットや CoT (Chain-of-Thought) 思考チェーン技術など、高度なプロンプト エンジニアリング技術を使用する必要があります。これらのプロンプトを設計するとき、LLM の一般的な位置バイアスなど、LLM のバイアスを考慮する必要がある場合があります。プロンプトが比較的長い場合、LLM はプロンプトの先頭にあるコンテンツの一部に気づき、プロンプトの一部のコンテンツを無視する傾向があります。真ん中。
幸いなことに、これらのプロンプトの設計は、RAG アプリケーション評価ツールに設計および統合されています。私たちの焦点は他のところに置くことができます。たとえば、GPT-4 などの LLM への大規模なアクセスには、多数の API キーが必要です。また、 、LLM が安くなるか、ローカル LLM が「優れた審判」のレベルに到達できることを期待しています。
02. 各種評価ツール
次に、現在一般的で使いやすいRAG評価ツールの基本的な使用方法とその特徴を紹介します。
- ラガス
Ragasは、RAG アプリケーションの評価に重点を置いたツールで、次のようなシンプルなインターフェイスを通じて評価を行うことができます。
from ragas import evaluate
from datasets import Dataset
# prepare your huggingface dataset in the format
# Dataset({
# features: ['question', 'contexts', 'answer', 'ground_truths'],
# num_rows: 25
# })
dataset: Dataset
results = evaluate(dataset)
# {'ragas_score': 0.860, 'context_precision': 0.817,
# 'faithfulness': 0.892, 'answer_relevancy': 0.874}
RAG プロセス内のquestion、contexts、answer、ground_truthsが Dataset インスタンスに組み込まれていれば、ワンクリックで評価を開始できるので非常に便利です。
Ragas インジケーターは種類が豊富で、RAG アプリケーション フレームワークに関する要件はありません。また、langsmithを使用して各評価のプロセスを監視し、各評価の理由を分析し、API キーの消費を観察することもできます。
- ラマインデックス
Llama-Index はRAG アプリケーションの構築に非常に適しており、そのエコシステムは比較的充実しており、現在急速な反復開発が行われています。Llama-Index にはいくつかの評価関数もあり、ユーザーは Llama-Index 自体で構築された RAG アプリケーションを簡単に評価できます。
from llama_index.evaluation import BatchEvalRunner
from llama_index.evaluation import (
FaithfulnessEvaluator,
RelevancyEvaluator,
)
service_context_gpt4 = ...
vector_index = ...
question_list = ...
faithfulness_gpt4 = FaithfulnessEvaluator(service_context=service_context_gpt4)
relevancy_gpt4 = RelevancyEvaluator(service_context=service_context_gpt4)
runner = BatchEvalRunner(
{"faithfulness": faithfulness_gpt4, "relevancy": relevancy_gpt4},
workers=8,
)
eval_results = runner.evaluate_queries(
vector_index.as_query_engine(), queries=question_list
)
runner.evaluate_queries()では、インスタンスを に渡す必要があることがわかりますBaseQueryEngine。これは、Llama-Index 自体によって構築された RAG アプリケーションを評価するのにより適していることを意味します。他のアーキテクチャ上に構築された RAG アプリケーションの場合は、エンジニアリングの変換が必要になる場合があります。
- TruLens-Eval
Trulens-Eval は、RAG インジケーターの評価に特に使用されるツールでもあり、LangChain および Llama-Index との統合が比較的良好で、これら 2 つのフレームワークによって構築された RAG アプリケーションの評価に簡単に使用できます。例として、LangChain の RAG アプリケーションの評価を見てみましょう。
from trulens_eval import TruChain, Feedback, Tru,Select
from trulens_eval.feedback import Groundedness
from trulens_eval.feedback.provider import OpenAI
import numpy as np
tru = Tru()
rag_chain = ...
# Initialize provider class
openai = OpenAI()
grounded = Groundedness(groundedness_provider=OpenAI())
# Define a groundedness feedback function
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons)
.on(Select.RecordCalls.first.invoke.rets.context)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
# Question/answer relevance between overall question and answer.
f_qa_relevance = Feedback(openai.relevance).on_input_output()
tru_recorder = TruChain(rag_chain,
app_id='Chain1_ChatApplication',
feedbacks=[f_qa_relevance, f_groundedness])
tru.run_dashboard()
もちろん、Trulens-Eval はネイティブ RAG アプリケーションを評価することもできます。コードは比較的複雑になるため、instrumentRAG アプリケーションのコードに登録する必要がありますが、詳細は公式ドキュメントを参照してください。さらに、Trulens-Eval はブラウザで視覚的な監視用のページを起動することもでき、各評価の理由を分析し、API キーの消費を観察するのに役立ちます。
- フェニックス
Phoenix は、 Embedding 効果の評価や LLM 自体の評価など、LLM を評価するための機能を多数備えています。RAGの能力を評価する上で、エコシステムと接続するインターフェースも用意されていますが、指標の種類はそれほど多くないのが現状です。以下は、Phoenix を使用して Llama-Index を評価するために構築された RAG アプリケーションの例です。
import phoenix as px
from llama_index import set_global_handler
from phoenix.experimental.evals import llm_classify, OpenAIModel, RAG_RELEVANCY_PROMPT_TEMPLATE, \
RAG_RELEVANCY_PROMPT_RAILS_MAP
from phoenix.session.evaluation import get_retrieved_documents
px.launch_app()
set_global_handler("arize_phoenix")
print("phoenix URL", px.active_session().url)
query_engine = ...
question_list = ...
for question in question_list:
response_vector = query_engine.query(question)
retrieved_documents = get_retrieved_documents(px.active_session())
retrieved_documents_relevance = llm_classify(
dataframe=retrieved_documents,
model=OpenAIModel(model_name="gpt-4-1106-preview"),
template=RAG_RELEVANCY_PROMPT_TEMPLATE,
rails=list(RAG_RELEVANCY_PROMPT_RAILS_MAP.values()),
provide_explanation=True,
)
開始するとpx.launch_app()、Web ページをローカルで開くことができ、RAG アプリケーション リンクの各ステップを確認できます。最近の評価結果はまだretrieved_documents_relevanceここにあります。
- 他の
上記のツールに加えて、DeepEval、LangSmith、OpenAI Evalsおよびその他のツールはすべて、RAG アプリケーションを手動で評価する機能を統合しています。これらは、使用方法と原則が似ています。興味のある友人は、それらについて詳しく学ぶことができます。
03. 概要
この記事では主に、現在主流の評価フレームワークと方法論をレビューし、関連ツールの使用法を紹介します。現在、LLM のさまざまなアプリケーションが急速に開発されているため、RAG を評価する軌道にはさまざまな手法やツールが雨後の筍のように出現しています。
これらの手法は、大きな枠組みでは似ていますが、プロンプトの設計などの具体的な実装の観点では、依然として隆盛を保っています。現時点ではどのツールが最終的な王になるのかまだ判断できず、テストにはまだ時間が必要です。私たちは、大きな波の後に、開発者が自分たちに最適なツールを見つけられることを願っています。
Bilibiliは2度クラッシュ、テンセントの「3.29」第1レベル事故…2023年のダウンタイム事故トップ10を振り返る Vue 3.4「スラムダンク」リリース MySQL 5.7、莫曲、李条条…2023年の「停止」を振り返る 続き” (オープンソース) プロジェクトと Web サイトが 30 年前の IDE を振り返る: TUI のみ、明るい背景色... Vim 9.1 がリリース、 Redis の父 Bram Moolenaar に捧げ、「ラピッド レビュー」LLM プログラミング: Omniscient 全能&&愚かな 「ポスト・オープンソースの時代が来た。ライセンスの有効期限が切れ、一般ユーザーにサービスを提供できなくなった。チャイナ ユニコムブロードバンドが突然アップロード速度を制限し、多くのユーザーが苦情を申し立てた。Windows 幹部は改善を約束した: Make the Start」メニューもまた素晴らしいです。 パスカルの父、ニクラス・ヴィルトが亡くなりました。