「ベクトル データベースに加えて、通常の SQL データベースも必要ですか?」
これはよく聞かれる質問です。ユーザーがベクトル データに加えて他のスカラー データ情報を持っている場合、ビジネスでは、セマンティック類似性検索を実行する前に、特定の条件に基づいてデータをフィルタリングする必要がある場合があります。次に例を示します。
-
法律分野では、特定のデータベースから関連する法律用語を検索することのみが必要な場合があります。
-
小売業では、特定のサイズの紳士靴を探す必要があるかもしれません。
-
画像を検索する場合は、2010 年から 2016 年の間に公開され、IMDB 映画評価が 7.0 を超える映画のポスターを検索するとよいでしょう。
これに対する私たちの答えは「ノー」です。ベクトル データベース Milvus またはフルマネージド Milvus サービスである Zilliz Cloud を使用すると、スカラーを保存するために追加の SQL データベースを維持する必要はありません。1 つのシステムだけで、ユーザーは「ベクトル検索 + スカラー フィルタリング」を実装したハイブリッド クエリを送信して、より正確な検索結果を取得できます。
その中で、Milvus を使用すると、ベクトル検索を実行する際に、スカラー データに基づく条件付きフィルタリングを実行できます。データ属性はベクトル以外の任意のフィールドにすることができます。Milvus は、ベクトル フィールドのベクトル インデックスを作成し、ベクトル類似性検索を実行すると同時に、式を使用して検索結果に対してメタデータ フィルタリングを実行することもできます。検索時にフィルター式を入力するだけで、Milvus が両方の処理を自動的に実行します。
このチュートリアルでは、Zilliz Cloud Pipelinesを使用します。これは、テキストとフィルター式によるベクトルの直接検索をサポートしながら、非構造化データを埋め込みベクトルにエンコードするための Zilliz Cloud の組み込み機能です。スカラー フィルタリングを使用して、特定のソース URL や特定のファイル名など、特定の基準に一致するドキュメント フラグメントのみを呼び出す方法を示します。同様のアイデアを使用して、発行年、バージョン番号などの特定のタグが付いたドキュメントを呼び出すこともできます。
01. コレクションとパイプラインの作成
このチュートリアルには無料版のZilliz Cloud(海外版)が必要です。Zilliz Cloud は、ユーザーのデータベースをサーバーレス クラウド サーバーに展開するフルマネージドの Milvus サービスですが、PyMiluvs API インターフェイスを呼び出すことで、Zilliz Cloud ベクトル データベースをローカルで使用することもできます。テストに使用される次のテキストは、PyMilvus ドキュメントからのものです。
- https://cloud.zilliz.com/を開き、「Starter」バージョンのクラスターを作成します。
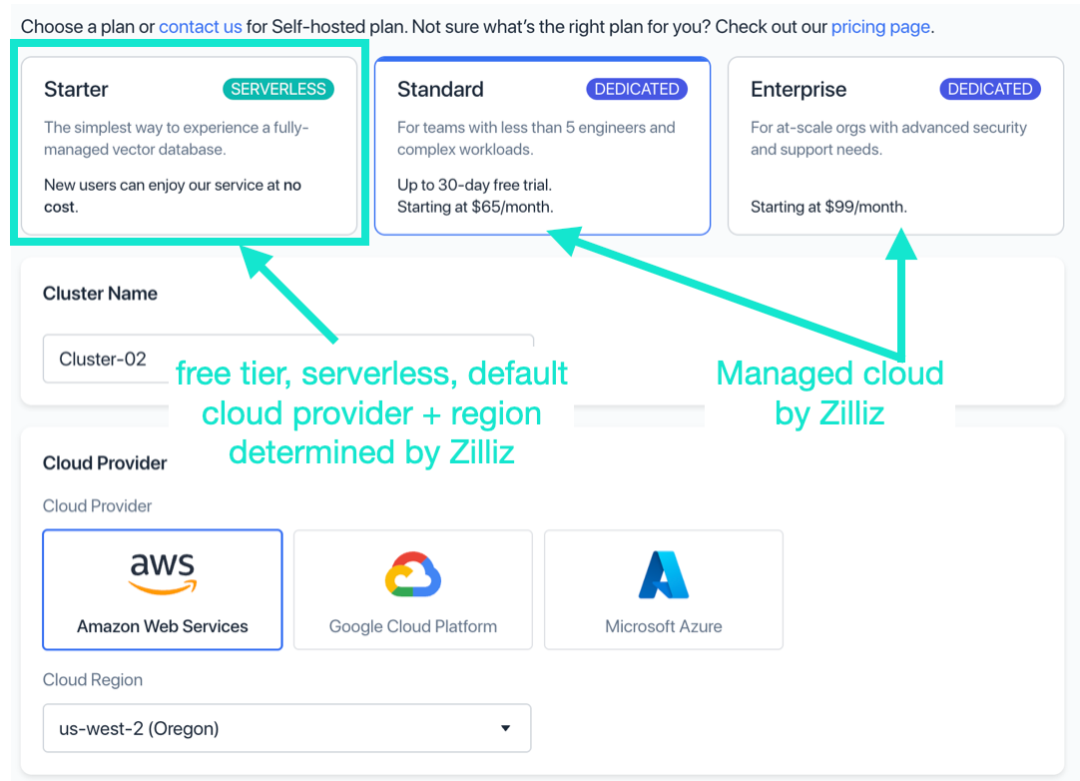
- コレクション名を追加し、「コレクションとクラスターの作成」をクリックします。
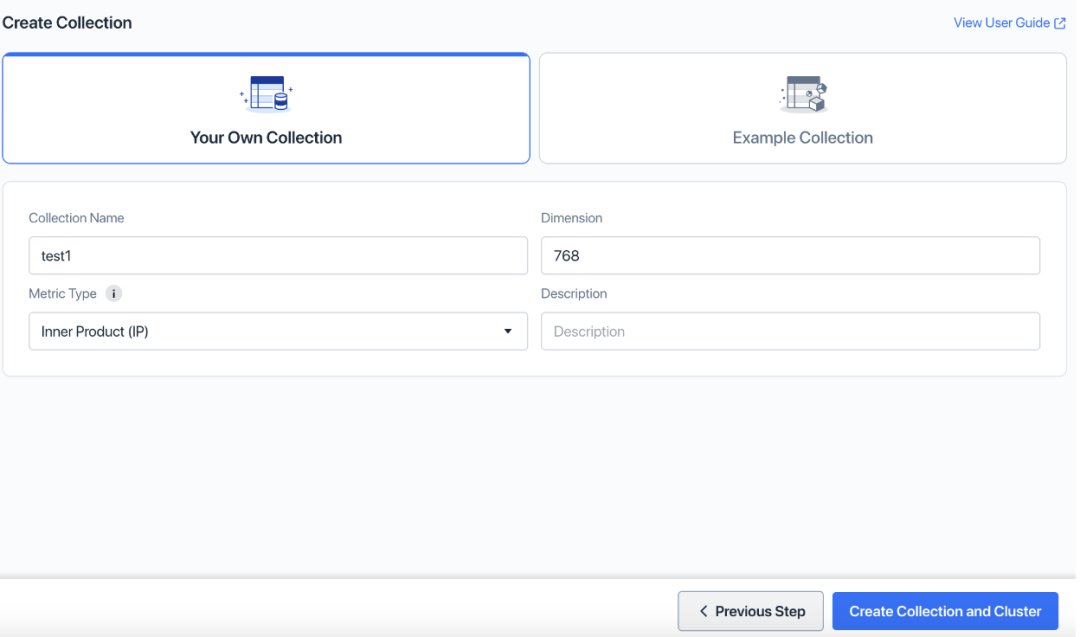
デフォルトでは、Zilliz Cloud クラスターの作成時に 1 つのコレクションが作成されますが、このチュートリアルでは使用されません。後で Zilliz Cloud Pipelines を作成すると、別のコレクションが自動的に作成されます。2 つのコレクションは同じではないことに注意してください。
- 左側のナビゲーション バーで [パイプライン] をクリックし、インターフェイスのプロンプトに従ってパイプラインを作成し、データをアップロードします。
a. 最初に「取り込みパイプライン」を作成することを選択してください。
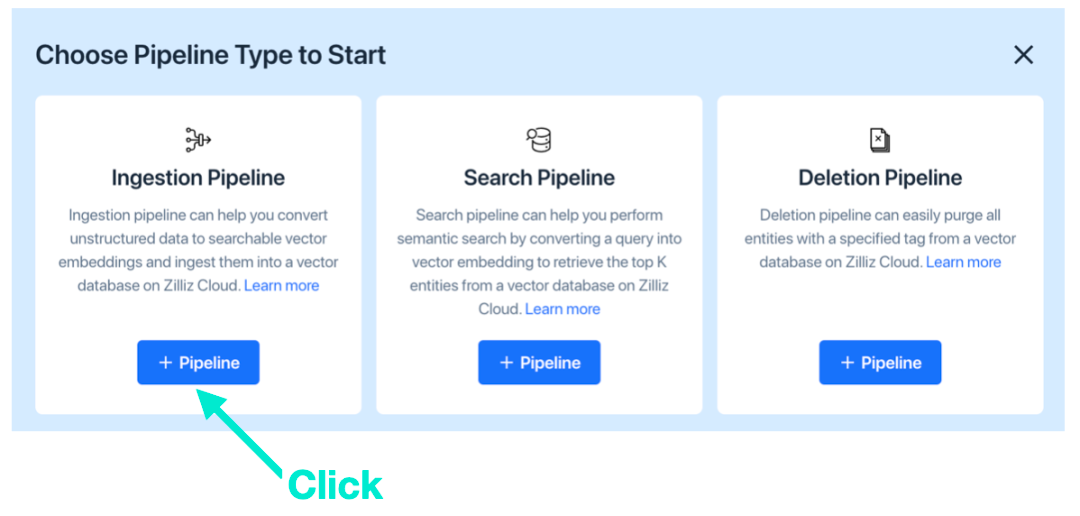
b. 作成したサーバーレス クラスターを選択し、コレクション名とパイプライン名をそれぞれ入力し、[関数の追加] をクリックします。
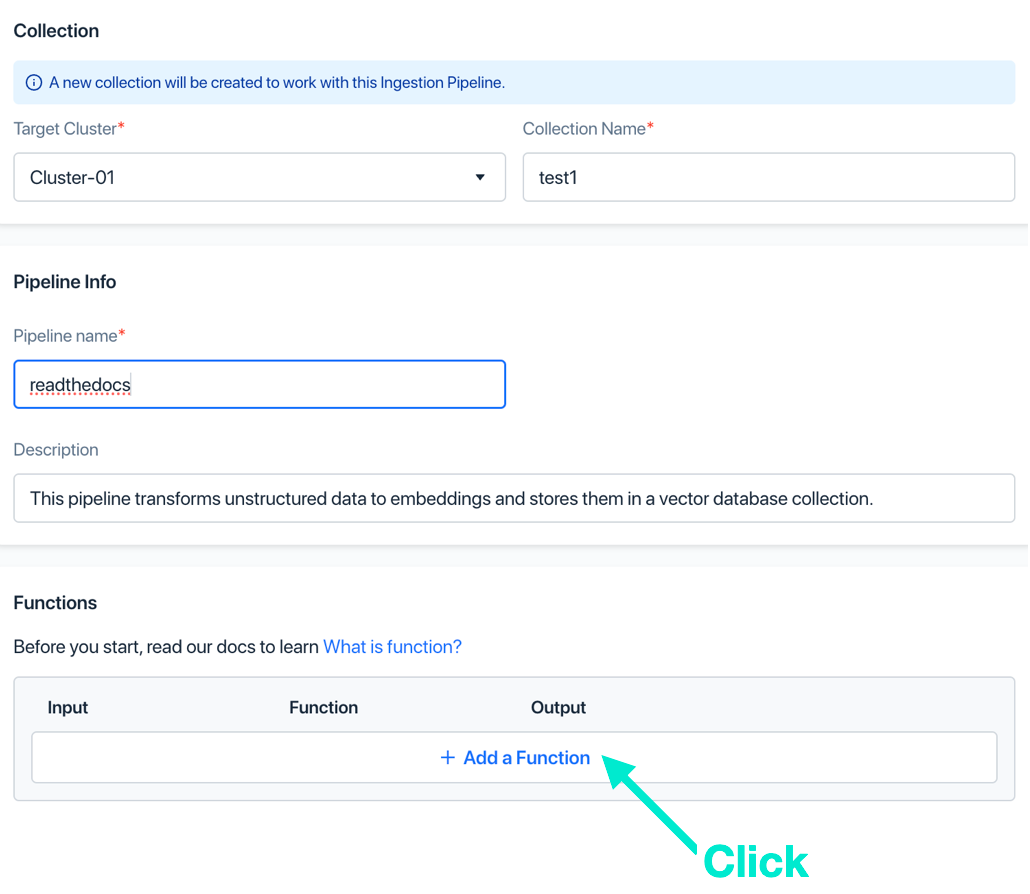
c. INDEX_DOC 関数を選択し、関数名を入力し、他のパラメータ値はデフォルトのままにして、「追加」をクリックします。この関数はドキュメントをベクトルにスライスします。
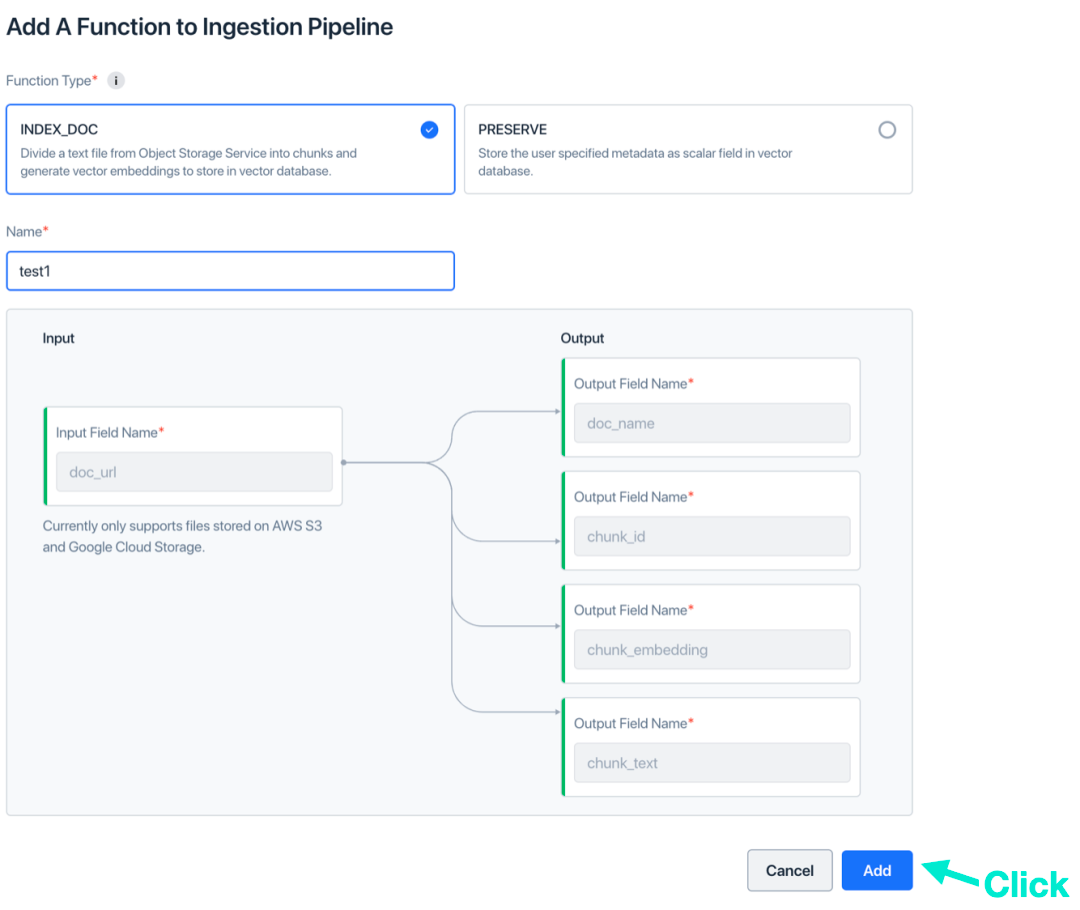
d. (オプション) [機能の追加] を再度クリックします。
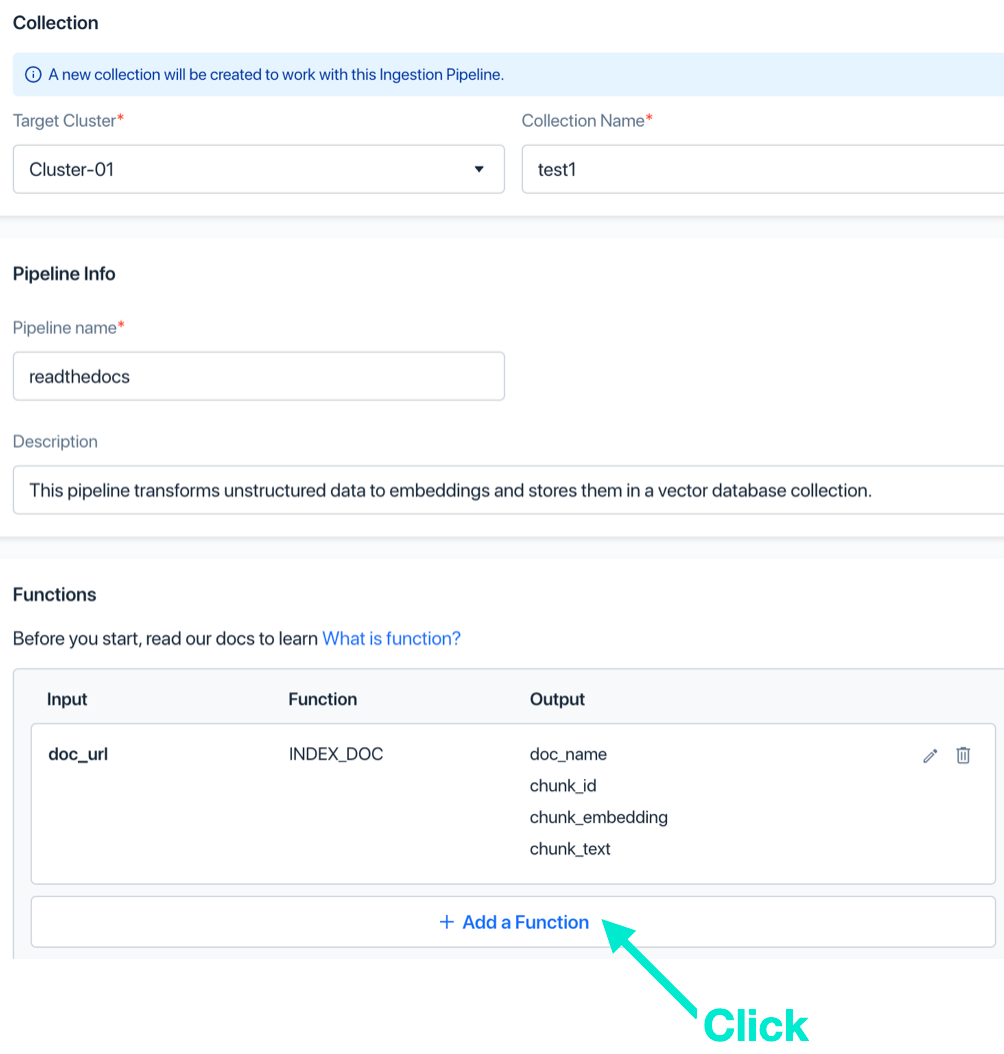
e. (オプション) PRESERVE 関数を選択し、名前を付けて、[追加] をクリックします。この機能は、ドキュメントのタグ情報を保存するために使用されます。
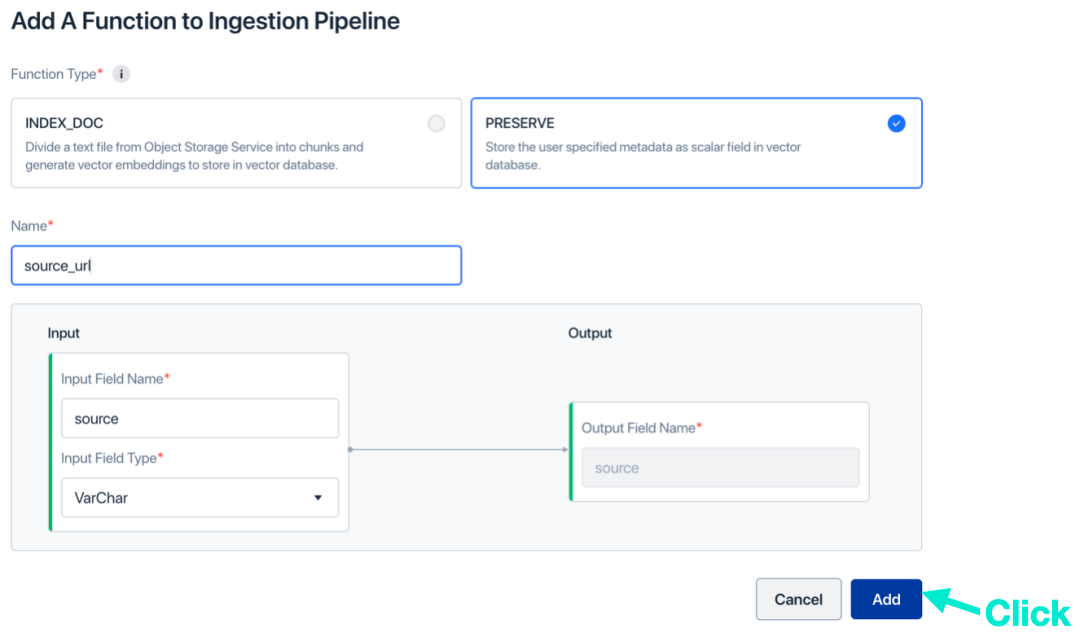
- 「取り込みパイプラインの作成」をクリックします。これで、取り込みパイプラインとコレクションの作成が完了しました。
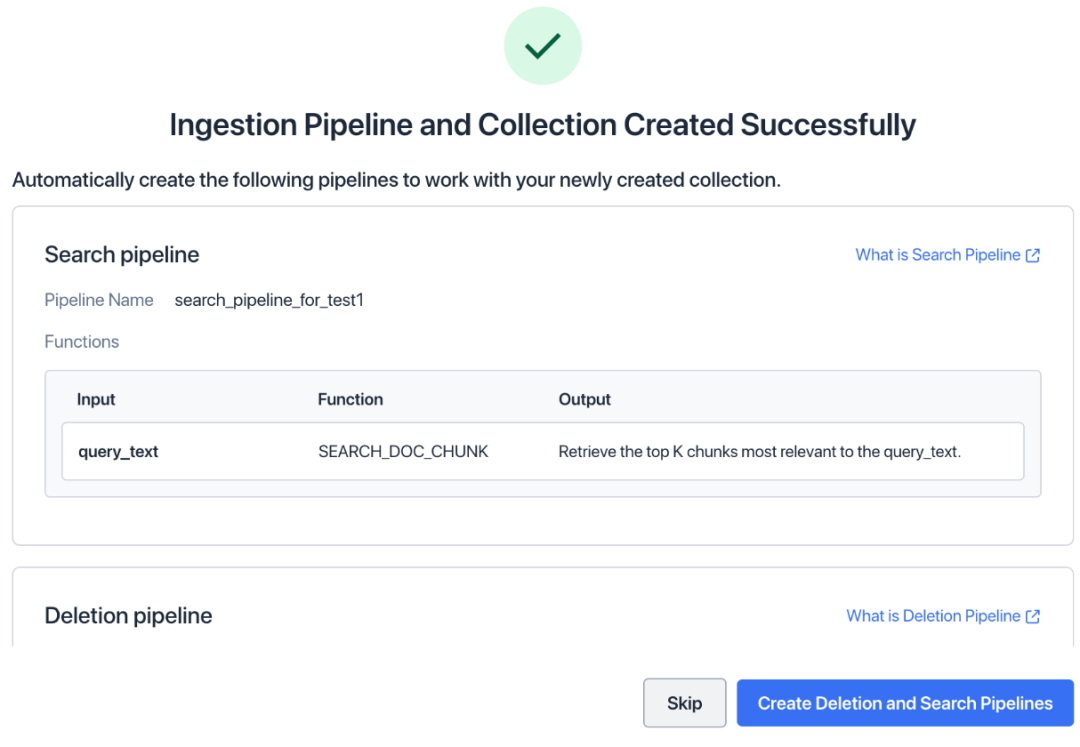
-
「削除と検索パイプラインの作成」をクリックします。
-
パイプライン リスト ページに入り、ボタン「▶️」をクリックして取り込みパイプラインを実行します。
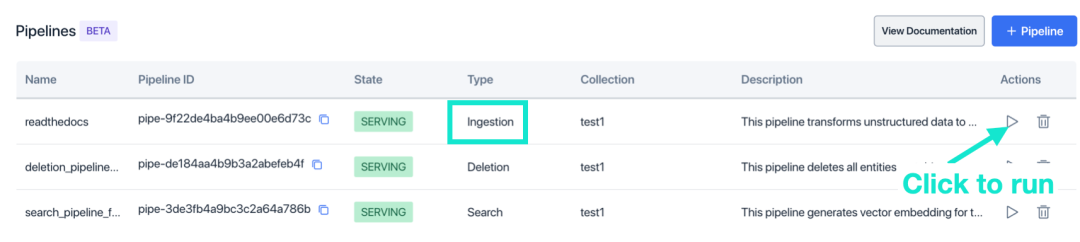
- Ingestion Pipeline は、オブジェクト ストレージ (AWS S3 や Google Cloud Storage など) へのファイルのアップロードをサポートしています。この例では、データを AWS S3 にアップロードします。アップロードが完了したら、「署名付き URL 経由で共有」をクリックします。共有リンク (署名付き URL) をコピーします。オブジェクト ストレージがない場合は、署名済み URL として提供されるテスト ファイル リンクhttps://publicdataset.zillizcloud.com/milvus_doc.mdを使用できます。
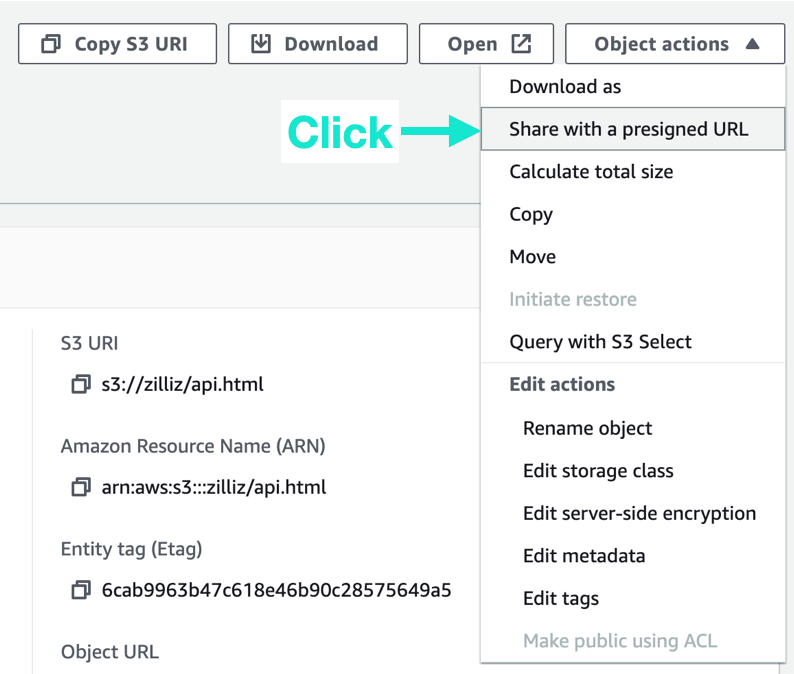
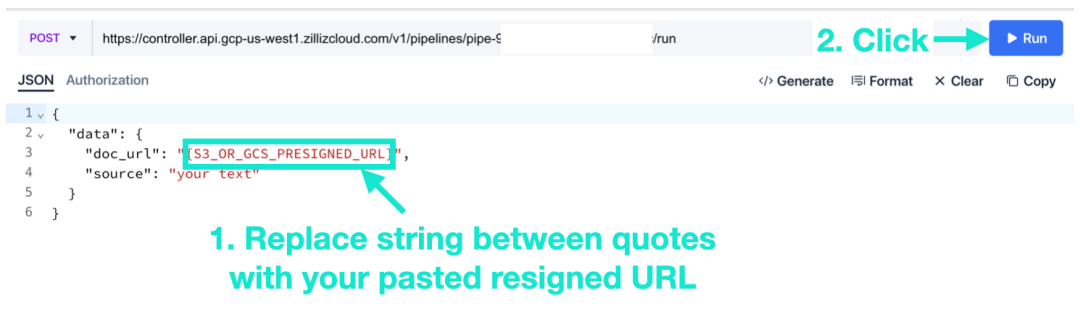
- 事前署名された URL をコードに貼り付けて、「実行」をクリックします。このステップでは、ファイルを断片化してベクトルを抽出し、ベクトル データベース コレクションにインポートします。
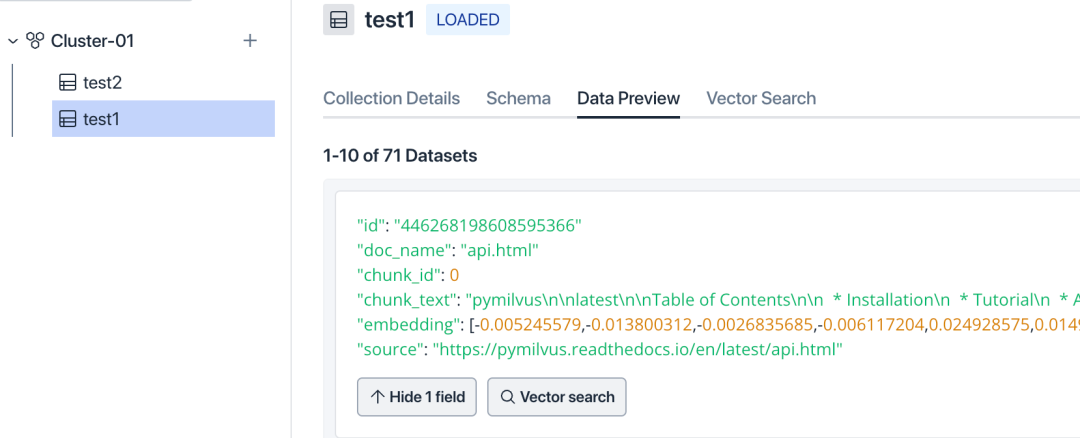
- コレクション ページに入り、コレクションとスキーマが正しいかどうかを確認します。この時点で、ドキュメント フラグメントのベクトルがデータ プレビューにすでに表示されているはずです。
その後、Playground インターフェイス上で、または API を呼び出してデータをクエリできます。
02. スカラー フィルタリングを使用して、特定のラベルに一致するベクトルを呼び出す
-
パイプラインリストで「検索パイプライン」を見つけ、右側のボタン「▶️」をクリックして検索パイプラインを実行します。
-
リクエストに質問を入力し、「実行」をクリックします。
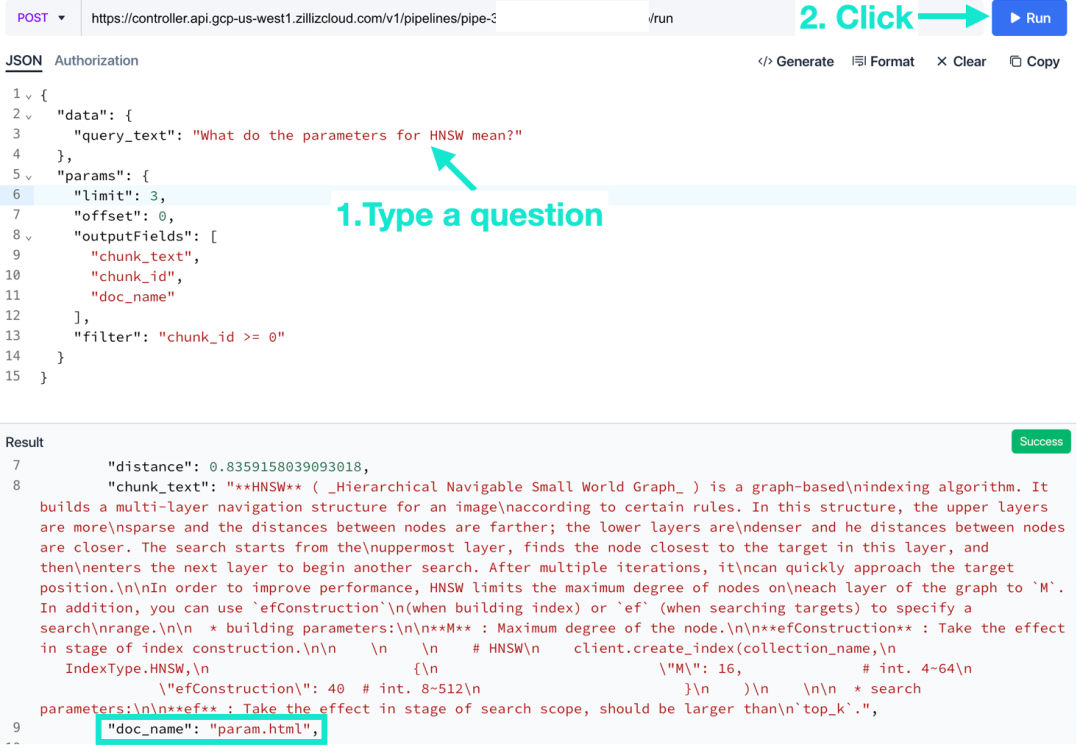
- 「フィルター」を編集します。ブール式を使用してください。「実行」をクリックすると、入力した条件に基づいて Zilliz Cloud が検索結果をフィルタリングしたことがわかります。
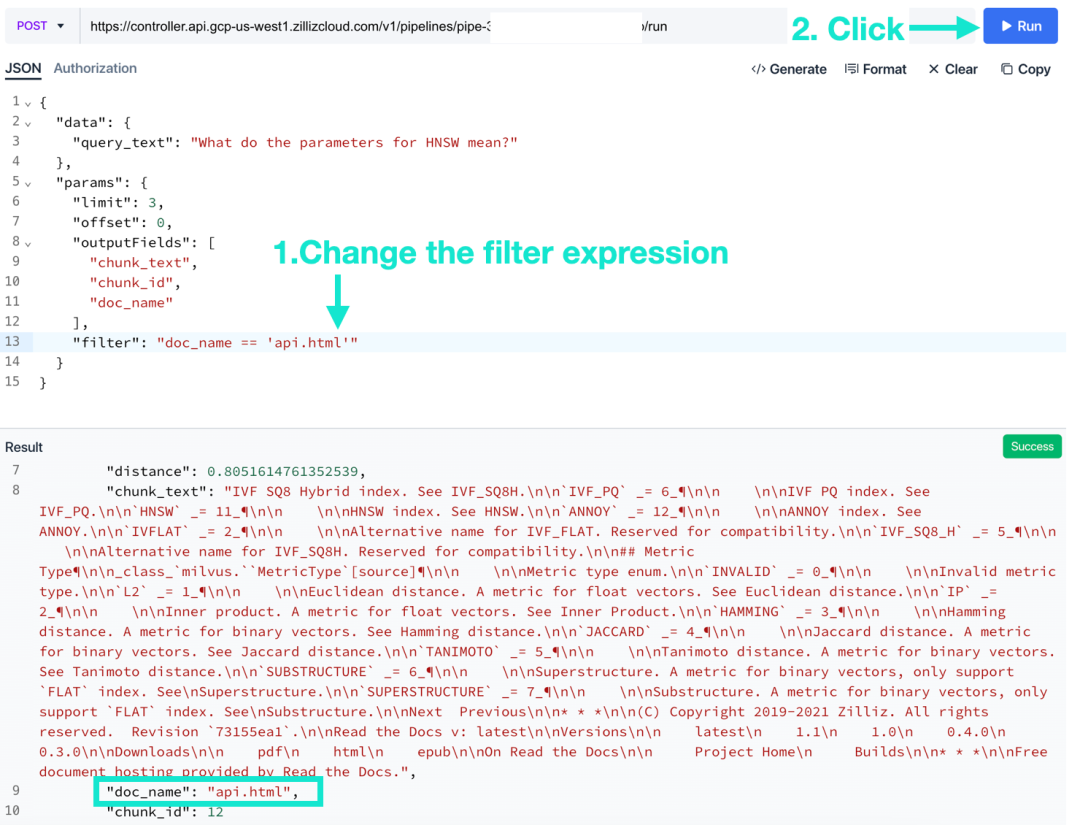
Zilliz Cloud Pipelines を使用したメタデータのフィルタリングはとても簡単です。ブール式を使用して、ベクトル フィールドを除くすべてのスカラー フィールドを条件付きでフィルター処理できます。
03. APIインターフェースによる検索
同様に、APIインターフェースを呼び出して検索することもできますが、APIを使用する場合、ユーザーは次の2点を指定する必要があります。
-
Ziliz APIトークン
-
パイプラインID
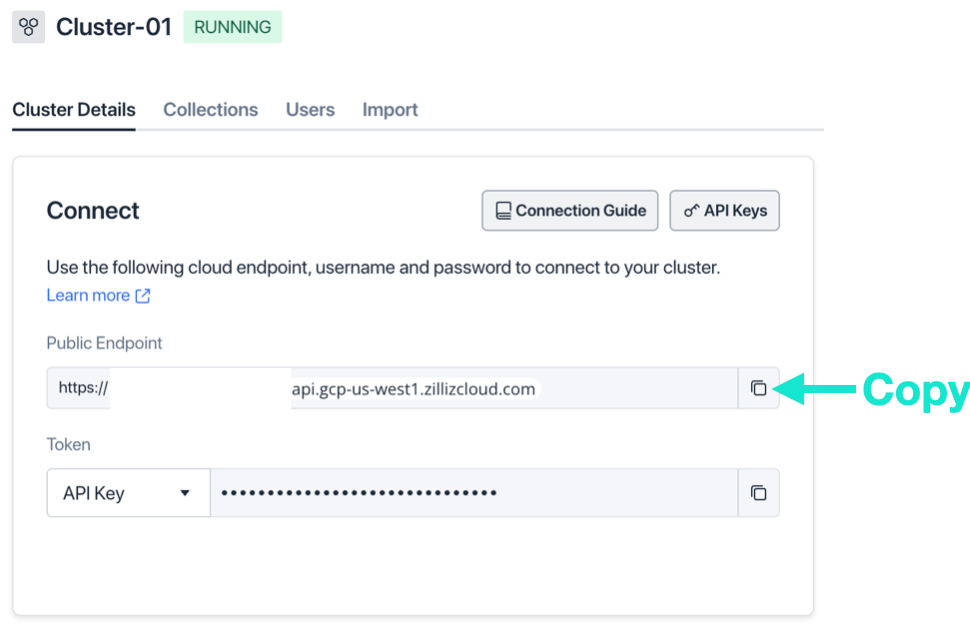
API トークンはクラスターの詳細ページから取得できます。
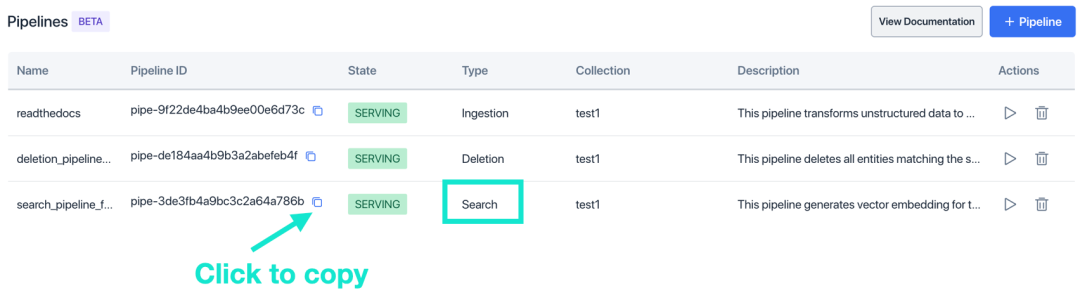
パイプライン ID を取得するには、まず [パイプライン] リスト ページで検索パイプラインを見つけて、[パイプライン ID] 列のパイプライン ID をコピーします。API インターフェイスを呼び出すときに、パイプライン ID を URL に貼り付けます。
import requests, json
url = "https://controller.api.gcp-us-west1.zillizcloud.com/v1/pipelines/pipe-xxxx/run"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {TOKEN}",
}
data = {
"data": {
"query_text": SAMPLE_QUESTION
},
"params": {
"limit": TOP_K,
"offset": 0,
# Any of these fields can be used in filter expression.
"outputFields": ["chunk_text", "chunk_id", "doc_name", "source"],
"filter": "doc_name == 'param.html'"
}
}
# Send the POST request
response = requests.post(url, headers=headers, json=data)
API を使用したメタデータのフィルタリング検索はとても簡単です。Zilliz Cloud Pipelines の使用方法について詳しく知りたい場合は、Pipelines を使用してタグ フィルター機能を備えた RAG Q&A ロボットを構築するためのノートブックを参照してください。
Broadcom は、既存の VMware パートナー プログラム Deepin-IDE バージョン アップデートの終了を発表し 、新しい外観に なりました。WAVE SUMMIT は第 10 回を迎えます。Wen Xinyiyan が最新の情報を公開します。 周宏儀: 紅夢ネイティブは間違いなく成功するだろう GTA 5 の完全なソースコードが公開された ライナス: クリスマスイブにはコードを読まないつもりだ Java ツールセットの新バージョン Hutool-5.8.24をリリースする来年。一緒 にフリオンについて文句を言いましょう。商業探査: ボートは通過しました。万中山、v4.9.1.15 Apple、オープンソースのマルチモーダル大規模言語モデルをリリース フェレット ヤクルト会社、95G データが漏洩したことを確認