0. 概要
画像レベルの弱教師セマンティック セグメンテーション (WSSS) は、シーンの理解と自動運転に貢献する、基本的かつ困難なコンピューター ビジョン タスクです。既存の手法のほとんどは、初期疑似ラベルとして分類ベースのクラス アクティベーション マップ (CAM) を利用しますが、これらの手法は多くの場合、識別画像領域に焦点を当てており、セグメンテーション タスク用のカスタマイズされた機能が欠けています。この問題を軽減するために、スポットライト ブランチと補償ブランチを利用して重み付けされた CAM を取得し、再キャリブレーション監視とタスク固有の概念を提供する新しい活性化調整および再キャリブレーション (AMR) スキームを提案します。具体的には、アテンション変調モジュール (AMM) を採用して、チャネル空間順序の観点から特徴の重要度の分布を再配分します。これにより、チャネル間の依存関係と空間エンコーディングを明示的にモデル化し、セグメンテーションのアクティベーション応答を適応的に変調するのに役立ちます。さらに、デュアルブランチクロス擬似監視を導入します。これは、2 つのブランチを相互に改善するための意味的類似性の正則化と見なすことができます。広範な実験により、AMR が PASCAL VOC 2012 データセット上で最先端のパフォーマンスを達成し、画像レベルの監視トレーニングを使用した現在の方法を上回るだけでなく、顕著性ラベルなどのより強力な監視に依存するいくつかの方法も上回ることが実証されました。実験により、私たちのスキームはプラグアンドプレイであり、他の方法と組み合わせてパフォーマンスを向上できることが証明されました。私たちのコードは次のリンクから入手できます:https://github.com/jieqin-ai/AMR
1 はじめに
セマンティック セグメンテーションは、多くのアプリケーションで広く使用されているため、コンピュータ ビジョンの分野では基本的かつ重要なタスクです。これは、同じオブジェクト カテゴリに属する画像部分をクラスタリングして、画像のピクセル レベルで予測を行うことを目的としています。程度の差はあれ、ある程度の進歩は見られましたが、最近の成功のほとんどは完全に監視された環境で達成されました (Chen et al., 2017, 2018)。このような細かいピクセルレベルの注釈を取得することは、依然として多大な手作業を必要とする困難な作業です。これらの高価で退屈な注釈を軽減するために、多くの研究は境界ボックス監視 (Dai、He、および Sun、2015)、落書き監視 (Lin et al.、2015) などの弱い監視方法 (Wu et al.、2020、2021) を採用する傾向があります。 、2016 年)、ポイント監督(Bearman et al.、2016)および画像レベルの監督(Chang et al.、2020; Ahn および Kwak、2018)。画像レベルの弱い監視は、そのような粗い注釈が実際の状況と一致し、そのような弱いラベルが実際に取得しやすいため、非常に有利なスキームです。私たちの研究では、画像レベルの弱い監視パラダイムに焦点を当てています。
以前の画像レベルの弱教師セマンティック セグメンテーション (WSSS) 手法 (Lee et al., 2019; Singh and Lee, 2017; Wang et al., 2020b; Choe, Lee, and Shim, 2020) のほとんどは、クラス活性化を生成するために分類ネットワークを採用していました。セグメンテーションの初期疑似ラベルとしてマップ (CAM) (Zhou et al., 2016) を使用します。ただし、この CAM は分類用に設計されており、セグメンテーション特性に対するカスタマイズされた最適化が欠けています。つまり、分類器は最も識別力の高い領域のみを強調表示しているように見えるため、図 1 に示すように、取得された CAM シードは、スポットライト CAM と一致するターゲット オブジェクトの一部のみをカバーします。この問題を解決するために、いくつかの方法では、識別応答領域を拡大し、初期の CAM シードを改善しようとします。 SEAM (Wang et al., 2020b) は、より多くのシード領域を取得するために、さまざまな変換画像に等分散正則化を追加します。同様に (Wei et al., 2017) は、CAM シードを繰り返し消去することで、モデルを他の領域に焦点を当てました。ただし、これらの方法では通常、拡張プロセスを反復消去などの複雑なトレーニング フェーズに形式化するため、時間がかかり、最適な反復回数を決定するのが困難です。さらに、分類ネットワークによって提供される識別領域に大きく依存しているため、重要性の低い領域が見落とされやすくなります。
上記の問題をより適切に処理するために、AMR と呼ばれる新しい活性化調整および再調整スキームを提案します。このスキームは、スポットライト ブランチと補償ブランチを利用して、WSSS に補完的なタスク指向の CAM を提供します。スポットライト ブランチは、CAM を生成するための基本的な分類ネットワークを表し、通常は馬の頭や車の窓などの識別領域と分類固有の領域を強調表示します (図 1 を参照)。 AMR は、以前の研究で分類ベースの CAM を使用してセグメンテーション タスクを実行する際のタスク ギャップの問題を軽減し、よりセマンティック セグメンテーション固有の手がかりを提供するのに役立ちます。さらに、アテンション変調モジュール (AMM) を使用して、チャネル空間順序の観点からアクティベーションの重要度の分布を再配置し、セグメンテーション指向のアクティベーション応答を適応的に調整するのに役立ちます。 AMR の貢献は次のように要約できます。
1. 私たちの知る限り、私たちは補完的な監視とタスク固有の CAM を提供するために WSSS のプラグイン補償ブランチを探索しようと試みた最初の企業です。補償ブランチは、セグメンテーションの主要な領域 (図 1 の馬の脚や車のシャーシなど) を掘り出すことができます。これは、セグメンテーション タスクにおける分類ベースの CAM のアプリケーション ボトルネックを突破するために非常に重要です。補償 CAM は、スポットライト CAM を再調整することにより、セグメンテーション指向の CAM を生成するのに役立ちます。さらに、デュアル ブランチからの出力 CAM を最適化するためのクロス擬似監視を導入します。これは、背景に集中しすぎてスポットライト CAM に近づく CAM の補償を回避するための意味的類似性正則化とみなすことができます。
2. チャネルおよび空間次元の特徴を順次変調することで、活性化マップがターゲット オブジェクト全体に注意を均等に分散するように促す、注意変調モジュール (AMM) を設計しました。変調関数は、二次的な特徴を強調し、スポットライト ブランチによってキャプチャされた顕著な特徴にペナルティを与えるために、アクティブ化された特徴の分布を再配置するために使用されます。チャネル空間シーケンシャル アプローチは、チャネル間の相互依存性と各レベルの局所受容野内の空間エンコーディングを明示的にモデル化し、セグメンテーション指向の特徴応答を適応的に調整するのに役立ちます。
3. 私たちの手法は、検証セットとテストセットでそれぞれ 68.8% と 69.1% の mIoU を達成し、PASCAL VOC2012 データセットで新しい最先端の WSSS パフォーマンスを達成しました (Everingham et al., 2015)。広範な実験により、AMR は画像レベルの監視を使用してトレーニングされた現在の方法よりも優れているだけでなく、顕著性ラベルなどのより強力な監視に依存する一部の方法よりも優れていることが実証されています。実験では、私たちのスキームがプラグアンドプレイであり、他の方法と組み合わせてパフォーマンスを向上できることも明らかにしました。
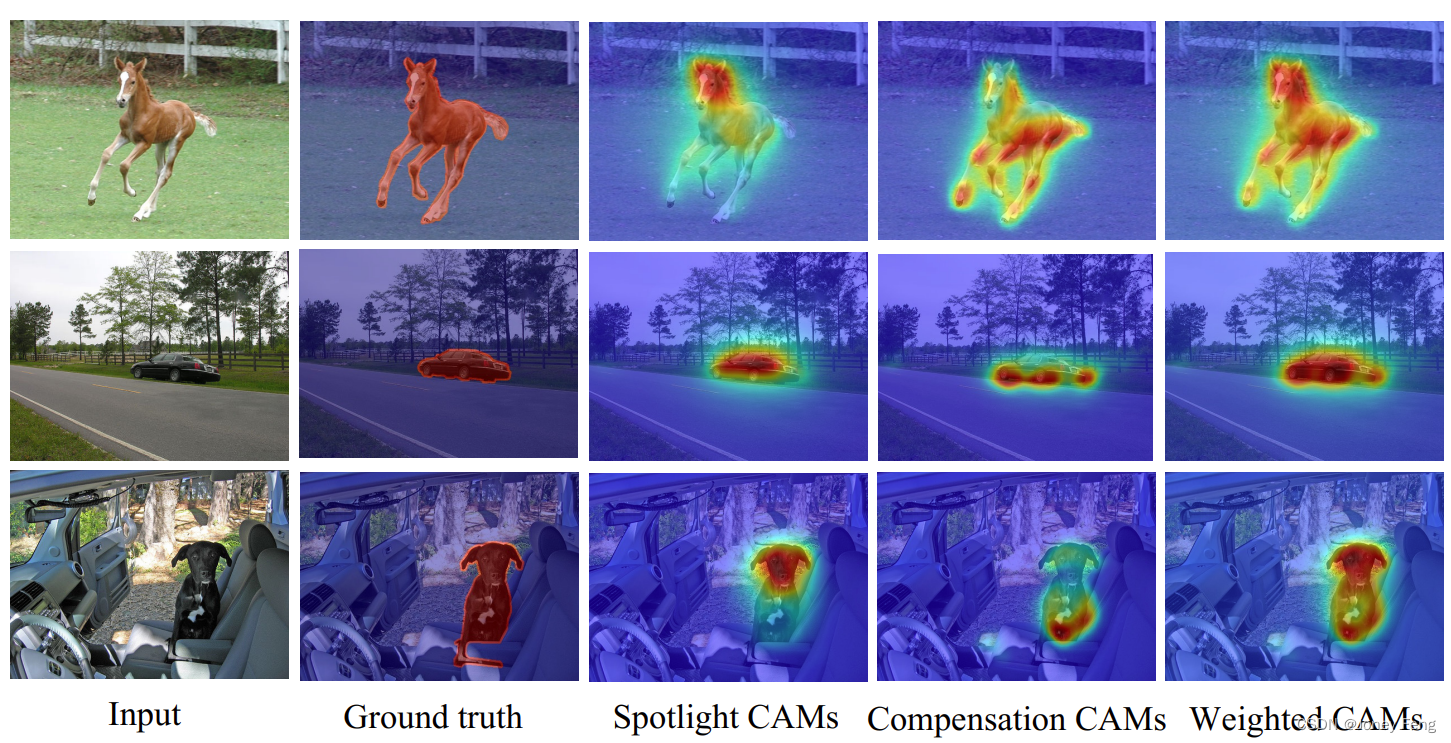
図 1: AMR スキームにおける CAM の視覚化。 「Spotlight CAM」は、従来の CAM と同様の領域に重点を置いています。 「補償 CAM」は、重要だが見落とされやすい領域を明らかにするのに役立ちます。スポットライト CAM は、CAM を補償することによって再調整され、さらに「加重 CAM」を取得するため、よりセグメンテーション指向の概念が提供されます。
2.関連作品
2.1. 弱く監視されたセマンティックセグメンテーション
一方では、AutoML などのテクノロジーに基づくセマンティック セグメンテーションに関する徹底的な研究 (Li et al., 2021; Ren et al., 2021; Li et al., 2020, 2019; Xuefeng Xiao および Lianwen Jin 、2017; Xia and Ding、2020)は、セグメンテーションの品質を向上させるために適用されます。一方、低コストで学習できる軽量のアノテーションは、近年広く研究されている画像レベルの WSSS です。既存の最先端の手法は、多くの場合、分類ネットワークによって生成されたクラス活性化マップ (CAM) のシード領域に依存しています (Zhou et al., 2016)。これらの取り組みのほとんどは、高品質の CAM シードの生成と擬似ラベルの改善という 2 つの側面に分けることができます。一方で、元の活性化マップは画像の識別領域のみを強調表示するため、一部の方法では CAM の応答領域を直接拡張します。 (Wei et al.、2018) は、異なる拡張率の拡張畳み込みを使用して、ターゲット領域を拡大します。 (Wang et al., 2020b) 等変正則化を介して、分類ネットワーク内の変換された画像から個別の領域をキャプチャします。一方、初期の CAM に基づいて擬似ラベルを改善することに焦点を当てた作品もあります。 (Kolesnikov and Lampert、2016) は、シードを改善するための 3 つの原則、つまりシード、拡張、制約を検討しました。 (Ahn と Kwak、2018) は、ピクセル間の関係を学習し、ランダム ウォーク アルゴリズムを通じて同様の意味論的なピクセルを伝播します。さらに、一部の方法(Yao et al.、2021; Lee et al.、2019)は、CAMを前景キューとして使用し、顕著性マップ(Zhang et al.、2019)を背景キューとして使用します。 (Yao et al., 2021) は、非顕著領域内のオブジェクトを発見するために、グラフベースのグローバル推論ユニットを導入しました。ただし、これらの方法は反復的かつ確率的に行われるため、重要な情報が失われる可能性があります。この問題を解決するために、高品質の CAM を生成するための活性化変調と再校正スキームを提案します。
2.2. アテンションメカニズム
アテンション メカニズム (Wu, Hu, & Yang, 2019; Wu, Hu, & Wu, 2018) は、画像のグローバル コンテキストを確立するためにセグメンテーション ネットワークで広く使用されています。 Non-local (Wang et al., 2018a) は、特徴マップ内の各空間点間の相関を初めて考慮したものです。次に、asymmet (Zhu et al., 2019) は、非ローカル ネットワークの接続を強化するために、非対称非ローカル ネットワークを提案しました。 SE (Hu、Shen、Sun、2018 年) は、チャネル間の相互作用を計算することでチャネル機能の重要性を学習します。この研究に続いて、(Wang et al., 2020a) はチャネルベースの畳み込みを使用して相互作用を学習しました。 CBAM (Woo et al., 2018) は、空間およびチャネルの注意を利用して、チャネルおよび空間次元の重要な手がかりを強調します。 (Cao et al., 2019) は、基本的な注意モジュールに長距離依存関係を導入しています。この論文では、セグメンテーション タスクにおける二次的だが重要な機能を強化するアテンション変調モジュールを紹介します。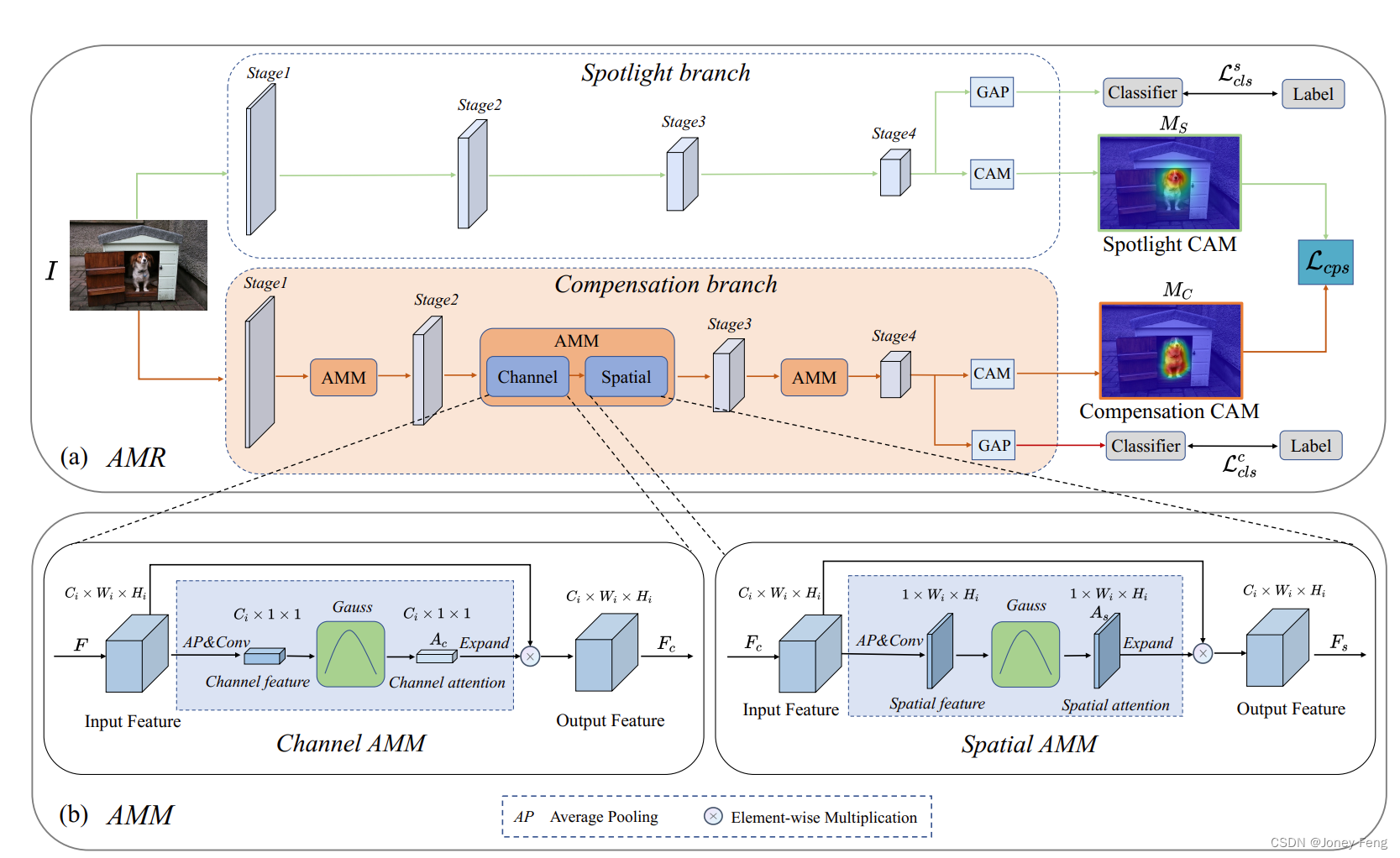
図 2: AMR スキームのフレームワーク。 (a) AMR のプロセス全体を表します。 AMR は、スポットライト ブランチと補償ブランチの 2 つのブランチで構成されます。 「GAP」とは、世界平均プーリングを意味します。 (b) は、チャネル空間シーケンシャル方式で機能の活性化マップを変調することを目的とする AMM の概略図を示しています。
3. 方法論
このセクションでは、まず CAM の生成に使用される従来の方法を簡単に紹介します。次に、活性化変調および再校正スキーム (AMR) を導入します。次のセクションでは、提案された AMM の動機と詳細を紹介します。最後に、変調関数とトレーニング損失関数を示します。
3.1. 事前の準備作業
クラス活性化マップ (CAM) (Zhou et al.、2016) は、入力画像 I ∈ R3×H×W 内のカテゴリー固有の応答領域を表します。マルチラベル分類ネットワークを使用してすべてのカテゴリの特徴をエンコードすると、これらの特徴マップ F(I) ∈ RC×H×W を利用して、最終分類層の前に特徴マップを抽出できます。 C は、特徴マップのチャネル数を表します。次に、単純に F(I) に対して行列乗算を実行して CAM を生成します。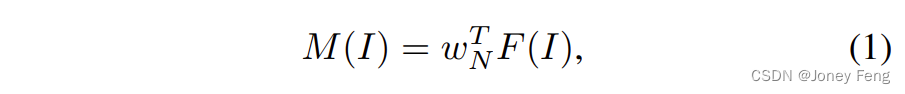
ここで、M(I) ∈ RN×H×W は取得された CAM です。 w T N は、N カテゴリの最後の完全に接続された層の重みです。ただし、これらの CAM は分類指向であり、セマンティック セグメンテーションのタスクの特異性を無視します。言い換えれば、ネットワークは、いくつかの識別領域を通じて分類タスクを達成できるように、分類ベースの損失を通じて最適化されます。これにより、オブジェクト全体の完全な境界を取得する必要がある、弱く監視されたセマンティック セグメンテーションのパフォーマンスが犠牲になります。この問題を解決するために、初期 CAM をよりタスク固有の CAM に再調整する活性化変調および再調整 (AMR) スキームを提案します。
3.2. 調整および再校正スキームをアクティブにする
図 2 に、活性化変調と再校正 (AMR) スキームを示します。 AMR には、スポットライト ブランチと補償ブランチが含まれます。スポットライト ブランチは、分類損失を使用してそれ自体を最適化し、スポットライト CAM MS を生成する以前の方法 (Wei et al., 2017; Jiang et al., 2019; Lee, Kim, and Yoon, 2021) に似ています。スポットライト ブランチはトレーニング中に情報豊富な機能をアクティブにすることが多いため、取得された CAM は主にターゲット オブジェクトの識別領域を強調表示します。
補償ブランチは、スポットライト CAM の補助監視機能として機能するように巧みに設計されています。これは、以前の研究で分類ベースの CAM を使用してセグメンテーション タスクを実行する際のタスク ギャップの問題を軽減し、よりセマンティック セグメンテーション固有の手がかりを提供するのに役立ちます。補償ブランチは、スポットライト ブランチでは見落とされがちなセグメンテーションの重要な領域を活用するプラグ アンド プレイ コンポーネントと考えることができます。取得された補償 CAM MC は、スポットライト CAM MS を再校正して、次のように表される最終的な重み付き CAM MW を生成するのに役立ちます。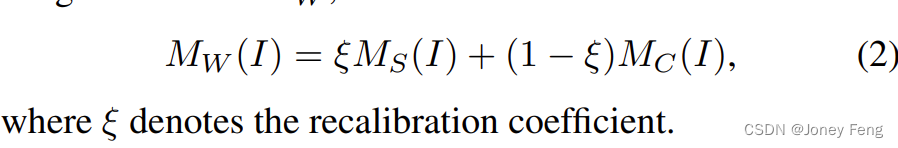
3.3. 注意力調整モジュール
アテンション モジュレーション モジュール (AMM) は、セマンティック セグメンテーション タスクにとって重要な、より多くの領域の分岐抽出を補うために提案されています。図 2 に示すように、AMM にはチャネル アテンション調整と空間アテンション調整が含まれます。まず、特徴 F(I) をチャネル AMM に入力します。チャネル間の相互依存性は、情報豊富な特徴に対する感度を反映する平均プーリング層と畳み込み層を通じて明示的にモデル化されます。 (Jiang et al., 2019) に触発され、最も敏感な特徴は識別領域に対応し、二次特徴は重要だが見落とされやすい領域を表し、当たり障りのない特徴は背景概念を表す可能性があります。したがって、変調機能を利用して二次的な機能を強化し、最も感度の高い機能と最も感度の低い機能を抑制します。上記の操作は次のように表現できます。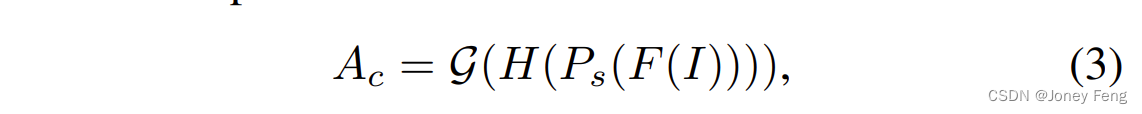
ここで、Ac はチャネル アテンション マップです。 Ps を空間平均プーリング関数、H を畳み込み層として表します。次に、変調関数 G を利用して特徴の分布を再分配し、チャネル次元の二次特徴を強調します。次に、チャネル アテンション マップと入力特徴マップの要素ごとの乗算を実行して、次のように定義される再割り当てされた特徴を生成します。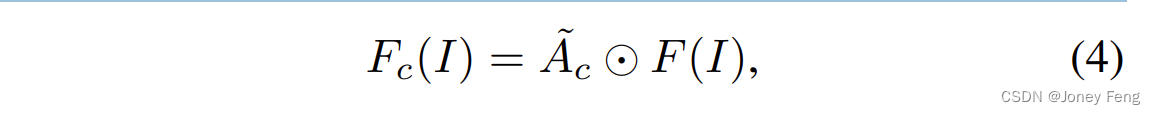
ここで、A~c は、特徴マップ次元に拡張されたチャネル アテンション マップを表します。 Fc(I) は出力特徴マップを表します。空間次元における空間間の関係をさらにモデル化するために、チャネル AMM の直後に空間 AMM も導入します。具体的には、まずチャネル次元の Fc(I) に対してチャネル平均プーリング Pc を実行し、次にそれらに畳み込み演算 H を適用します。出力フィーチャ マップは、空間次元に沿ったフィーチャの重要性を示します。次に、出力特徴マップに対して変調関数演算を実行して、二次アクティベーションを追加します。実装プロセスは次のように表現できます。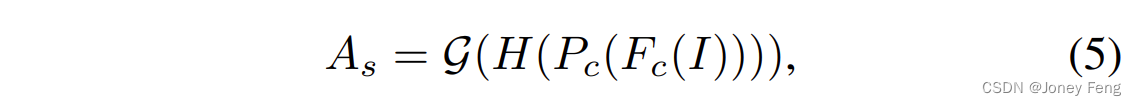
ここで、As は空間アテンション マップです。 As の高い活性化値は、見落とされやすい領域を反映しています。次に、空間アテンション マップとチャネル アテンション マップの間で要素ごとの乗算を実行して、変調されたアテンション マップを生成します。このプロセスは次のように表現できます。

図 3: 変調機能の概略図。軸上の値は活性化分布の範囲を表します。 (a) は元の活性化分布を表します。 (b) は再分配された活性化を表し、二次活性化を強調するためにガウス関数によって変調されます。
3.4. 調整機能
ここで、μ と σ は活性化マップの平均と標準偏差です。 μ と σ の設定に従って、G の活性化値をマッピングします。図 3 に、変調前後の活性化分布を視覚化します。ガウス投影により、最も重要なアクティベーションと最も重要でないアクティベーションが大幅に抑制されることが観察されます。二次活性化を強調して、見落とされやすい領域を直接抽出します。これはセグメンテーション タスクにとって重要です。さらに、しきい値を直接設定して重要度の分布を変更することも検討します。しかし、すべての画像に適用する均一のしきい値を決定するのは困難です。さまざまな変調関数の実験結果を表 4 にまとめます。
3.5.損失関数
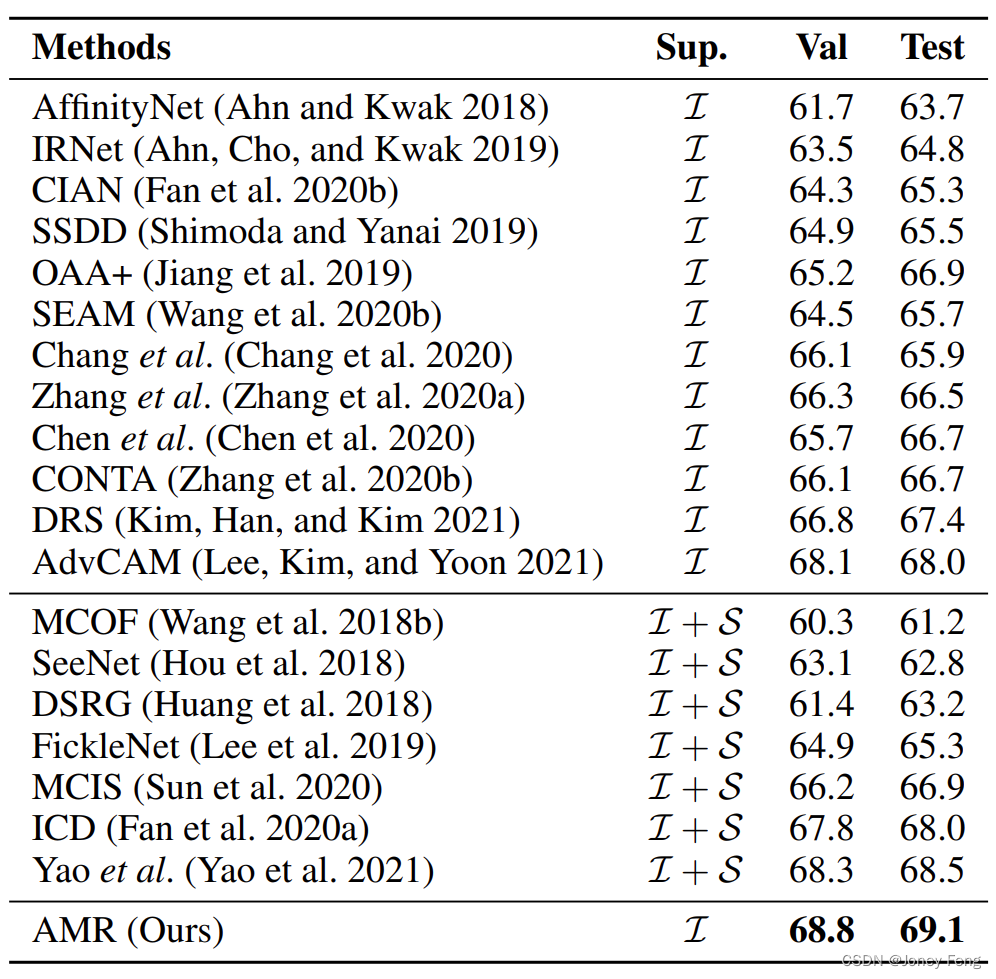
トレーニング プロセス中に、グローバル平均プーリング操作と全結合層を使用して、すべてのカテゴリのカテゴリ確率を表す予測値 Y を取得します。最後に、マルチラベルのソフトエッジ損失関数をトレーニングに使用します。  表 1: PASCAL VOC2012 検証およびテスト セットに関する最先端の手法との比較。すべての結果は mIoU (%) で評価されます。 I は画像レベルのラベルを表し、S は顕著性ラベルを表します。
表 1: PASCAL VOC2012 検証およびテスト セットに関する最先端の手法との比較。すべての結果は mIoU (%) で評価されます。 I は画像レベルのラベルを表し、S は顕著性ラベルを表します。
4. 実験
4.1. データセットと評価戦略
PASCAL VOC2012 データセット (Everingham et al. 2015) でメソッドを評価します。このデータセットには、20 の前景オブジェクト カテゴリと 1 つの背景カテゴリが含まれています。一般的な方法 (Wei et al. 2017; Wang et al. 2020b) に従って、トレーニングに 10,582 枚の画像、検証に 1,449 枚の画像、テストに 1,456 枚の画像を使用します。トレーニング プロセス全体を通じて、監視のために画像レベルのクラス ラベルのみを使用します。各画像には複数のカテゴリ ラベルが含まれる場合があります。実験のパフォーマンスを評価するために、すべてのカテゴリにわたる平均交差対和集合 (mIoU) の比率を計算します。
4.2. 実装の詳細
AMR のバックボーン ネットワークとして ResNet50 (He et al. 2016) を使用します。バッチサイズ 16 のトレーニング データを使用して 8 エポックのトレーニングを行います。初期学習率は 0.01 に設定され、運動量は 0.9 に設定されます。ネットワークの最適化には確率的勾配降下法アルゴリズムを使用し、重み減衰を 0.0001 に設定します。また、ランダム スケーリングや水平反転など、トレーニング画像に対していくつかの典型的なデータ拡張操作も実行しました。 CAM を取得した後、ランダム ウォーク アルゴリズムを使用して擬似ラベルを最適化します。セグメンテーション用の最終的な擬似ラベルを取得した後、DeepLab-v2 (Chen et al. 2017) と ResNet101 (He et al. 2016) をトレーニング用のバックボーン ネットワークとして使用します。これは ImageNet (Russakovsky et al. 2015) でトレーニングされます。 。
4.3. 現在の最先端の手法との比較
セマンティック セグメンテーション タスクにおける の比較。 DeepLab v2 (Chen et al. 2017) とトレーニング セットの疑似ラベルを使用して実験を行います。表 1 に示すように、PASCAL VOC2012 検証セットとテスト セットの結果を報告します。一方で、AMR は画像レベルの弱い監視に基づく方法を大幅に上回り、最先端のパフォーマンスを達成します。 AMR の mIoU は検証セットで 68.8%、テスト セットで 69.1% に達し、DRS よりそれぞれ 2.0% と 1.7% 高かった (Kim, Han, and Kim 2021)。一方、AMR は、よりきめの細かい監視キューを使用しても、より良い、または同等の結果を達成します。たとえば、AMR は (Yao et al. 2021) を検証セットで 0.5%、テストセットで 0.6% 上回っていますが、後者は追加の顕著性監視を使用しています。これは心強い結果であり、私たちの方法が大規模で安価なアノテーションから学習することで印象的な結果を達成できることを明らかにしており、実際のアプリケーションにとって非常に有益です。
CAM と擬似タグの比較。 私たちの方法は、セグメンテーション固有の CAM を提供して擬似ラベルの品質を向上させることを目的としています。 CAM および擬似ラベルの生成における私たちの方法の有効性を検証するために、PASCAL VOC2012 トレーニング セットに関するいくつかの競合する方法の CAM および擬似ラベルの結果を要約します (表 2 を参照)。結果は、AMR が CAM および擬似ラベルでそれぞれ 56.8% および 69.7% の mIoU を達成したことを示しています。私たちの方法は、CAMでは最先端のSEAM法(Wang et al. 2020b)を1.4%上回り、擬似標識ではCONTA法(Zhang et al. 2020b)を1.8%上回ります。 SEAM 手法 (Wang et al. 2020b) はバックボーン ネットワークとして Wide ResNet38 (Wu、Shen、および Van Den Hengel 2019) を使用し、その作業で ResNet50 よりも優れたパフォーマンスを達成したことは注目に値します。実験結果は、補正された CAM が初期 CAM と擬似ラベルの品質を効果的に改善できることを示しています。 AMR がどのように擬似ラベルの品質を向上させるかを説明するために、AMR によって生成された CAM を図 4 に示します。この図から、次のことがわかります。 i) スポットライト ブランチによって生成されたスポットライト CAM は、主に識別領域に焦点を当てています。 ii) 補正された CAM は、ターゲットにとって重要だが見落とされやすい領域を強調表示します。これは、AMM がアクティベーション マップを調整して二次的な機能を強調するのに役立つためです。 iii) 加重 CAM には、スポットライト CAM よりも完全な領域が含まれており、これはセマンティック セグメンテーション タスクの性質と一致しています。 
図 4: VOC2012 トレーニング セットに対する私たちの方法によって生成された CAM の視覚化結果。 (a) 入力画像。 (b) スポットライト ブランチによって生成されたスポットライト CAM。 (c) 補償ブランチによって生成された補償 CAM。 (d) 2 つの相補的な CAM を結合することによって得られる重み付けされた CAM。
表 2: VOC2012 トレーニング画像の擬似ラベルの品質結果 (mIoU)。 「CAM」列は、分類ネットワークによって生成された最初の CAM シードを表します。 「擬似」は、教師ありセグメンテーション用の洗練された擬似ラベルを表します。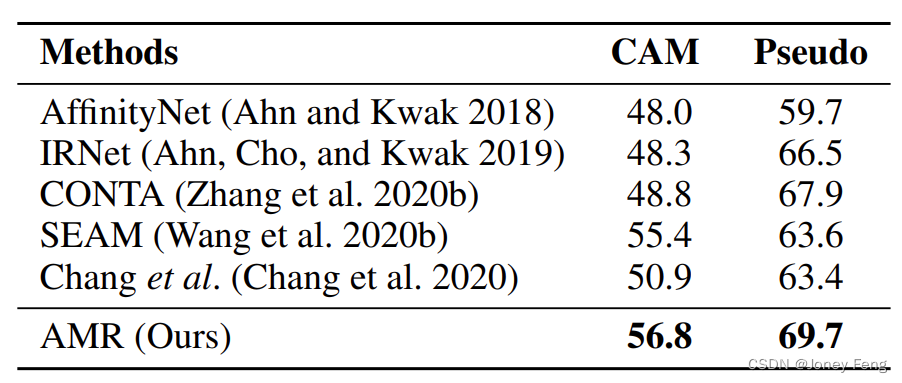
表 3: 私たちのアプローチにおける各コンポーネントのさまざまな効果の比較。 「ベースライン」は、単一の分類ネットワークを表します。 「AMMc」と「AMMs」は、それぞれ提案されたチャネル AMM と空間 AMM を表します。 Lcps はセマンティック正則化の略です。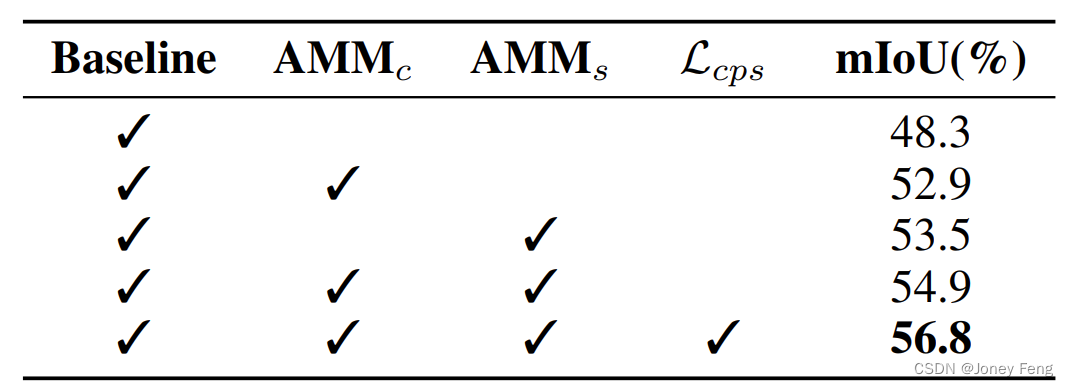
表 4: さまざまな変調関数の比較。 VOC2012 トレーニング画像の CAM を使用した mIoU の評価。
4.4. アブレーション研究
コア コンポーネントの可用性。 アプローチのコア コンポーネントの有効性を検証するために、スポットライト ブランチ (「ベースライン」と呼ばれる) のみを含む単一の分類ネットワークに基づいて各キー コンポーネントを徐々に追加します。さまざまなコンポーネントのパフォーマンスを表 3 のバリアント「ベースライン」と比較します。表 3 に示すように、AMMc と AMMs は CAM の mIoU をそれぞれ 52.9% と 53.5% に増加させます。 AMM 全体では 54.9% の mIoU を達成しました。さらに、クロス擬似教師あり LCP により、パフォーマンスが 1.9% 向上します。フレームワーク全体で 56.8% という最高のパフォーマンスを達成しました。これらのアブレーション実験は、私たちのアプローチの各コアコンポーネントの有効性を実証しています。
変調機能の有効性。 表 4 では、図 3 に示したさまざまな変調関数の結果を比較しています。 「しきい値」変調機能は、しきい値を超えた場合にアクティベーションを 1 に設定し、しきい値を下回った場合にアクティベーションを 0 に設定します。これにより、最も重要な機能を維持し、その他の機能の一部を強化するため、ベースラインと比較して 1.8% の改善を達成できます。重要な機能、小さなアクティベーション。 「Gauss」関数は 56.8% の mIoU を達成し、すべての候補関数の中で 1 位にランクされました。これは、ガウス関数がアクティベーション マップを適切に再分配して、見落とされやすいいくつかの重要な概念を明らかにできるためであると考えられます。
再校正係数の有効性。 最適な再校正係数 (ξ) を調べるために、結果を表 5 に報告します。 ξ は、重み付き CAM に対するスポットライト CAM の寄与を表します。 ξ を 0.5 に設定すると、56.8% という最良の結果が得られることがわかります。 ξ の値を増減すると、おそらく 2 つの CAM 間の領域補償のバランスが崩れるため、パフォーマンスが大幅に低下します。係数が 0.1 または 0.9 に近づくと、フレームワークは単一の分岐に近似するため、パフォーマンスが大幅に低下します。
4.5. 一般的な議論
AMR の一般化を検証するために、提案された AMR を 2 つの最先端の方法、すなわち IRNet (Ahn, Cho and Kwak 2019) と SEAM (Wang et al. 2020b) に拡張します。彼らの論文の元のトレーニング設定を保持し、最初の CAM の結果を比較します。表 6 に示すように、私たちの方法は IRNet で 8.5% の mIoU 改善を達成しました。ベースライン SEAM では、分類バックボーン ネットワークを SEAM と同じ Wide ResNet38 (Wu、Shen、および Van Den Hengel 2019) に変換します。結果は、AMR が CAM の品質を 2.5% 向上させることを示しています。これは、セグメンテーション ベースの CAM の一般化と堅牢性を向上させるために、私たちの方法と他の方法を組み合わせることが実証されています。
4.6. セグメンテーション結果の視覚化
図 5 に示すように、PASCAL VOC2012 (Everingham et al. 2015) の検証セットについて、私たちの方法のセグメンテーション結果を IRNet (Ahn、Cho、Kwak 2019) と比較します。図からわかるように、IRNet (Ahn, Cho and Kwak 2019) の結果は、いくつかの曖昧な領域で誤った判断を引き起こすことがよくあります。それどころか、私たちの方法はターゲットオブジェクトに属するより多くの領域をマイニングすることに成功し、それによってより良いセグメンテーションパフォーマンスを達成します。
図 5: PASCAL VOC2012 検証セットの定性的結果。 (a) 入力画像。 (b) 実際のラベル。 (c) IRNet のセグメンテーション結果 (Ahn、Cho、Kwak 2019)。 (d) 私たちの方法によるセグメンテーションの結果。
表 5: さまざまな再校正係数との比較。 mIoU は、VOC2012 トレーニング画像の CAM で評価されます。
表 6: IRNet (Ahn、Cho、および Kwak 2019) および SEAM (Wang et al. 2020b) での AMR の一般化結果。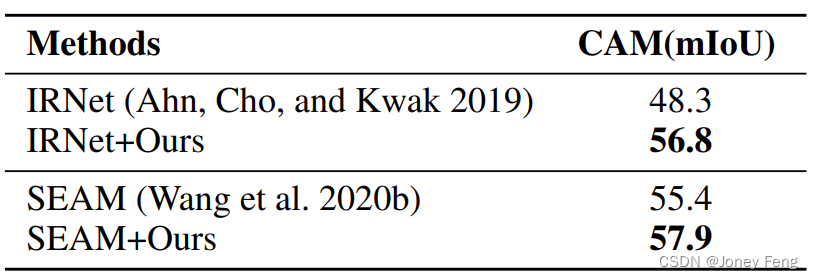
5。結論
この論文では、弱教師セマンティック セグメンテーション (WSSS) のための新しいアクティベーション レギュレーションとキャリブレーション (AMR) スキームを提案します。このスキームは、スポットライト ブランチとプラグ アンド プレイ補償ブランチを利用して重み付き CAM を取得し、よりセマンティック セグメンテーション指向を提供します。概念。 AMM モジュールは、チャネル空間順序の観点から特徴量の重要度の分布を再配置するように設計されており、セグメンテーション タスクにとって重要であるにもかかわらず見落とされやすいいくつかの領域を強調するのに役立ちます。 PASCAL VOC2012 データセットに対して広範な実験が行われ、その結果、AMR が弱教師セマンティック セグメンテーションにおいて最先端のパフォーマンスを達成することが示されました。