1. C++の基本構文
型変換
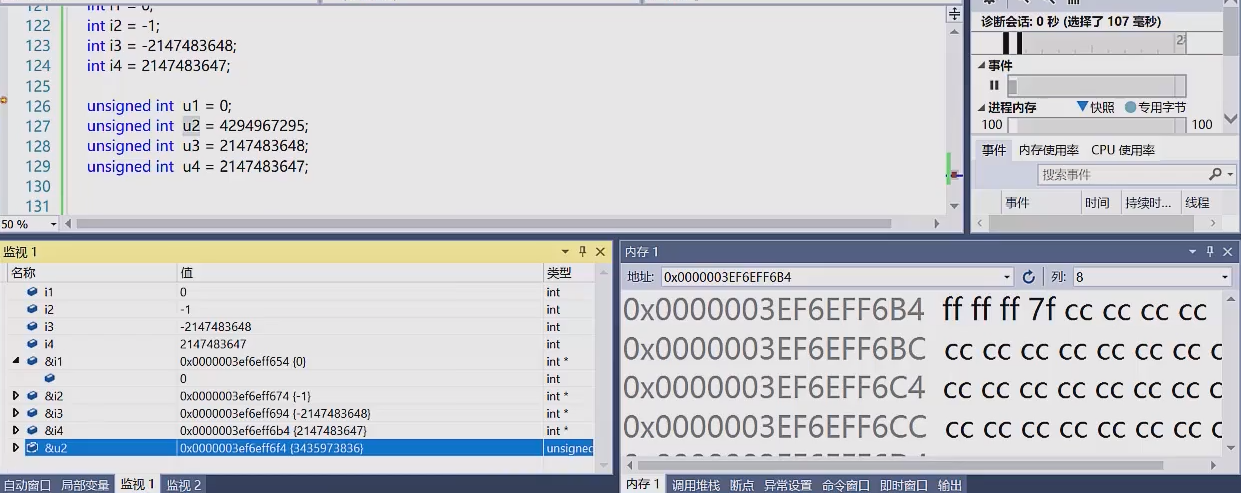
unsigned 型と signed 型を決して混合しないでください
。式に両方が含まれる場合、signed 型は unsigned 型に変換され、値が負の場合は予期しない結果が発生します。
unsigned a = 1; int b = -1; cout<<a*b;//输出 4294967295
//详解: b的源码:100...1 负数转补码按位取反加1后为:1111...0 无符号类型把该值读出为4294967295 (结果视所在机器位数而定)
ループに符号なし型を使用する場合は、それらが 0 より小さくなることはないという事実に注意してください。
エスケープシーケンスと指定されたタイプ


注: "\1234" 最初の 3 つは、エスケープ シーケンスの対応する 8 進数の値を構成します。
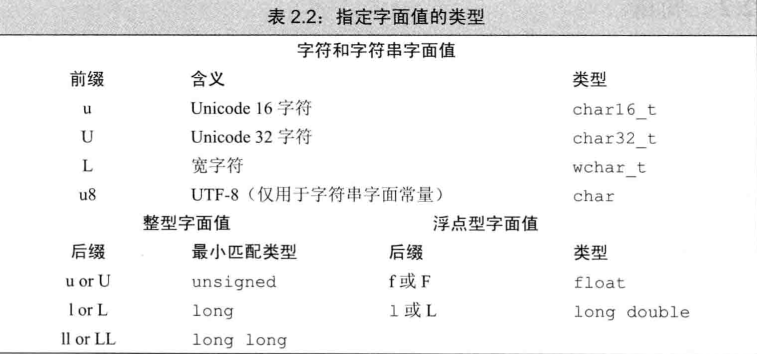
注: 長整数型を表す場合は、小文字の l の代わりに L を使用してください。1 と混同されやすいためです。
接尾辞はリテラル値のデータ型を明確に示すために存在し、それによってコンパイラによる暗黙の型変換や曖昧さを回避します。ただし、データ型はリテラルの形式から自動的に推測できるため、すべてのデータ型にサフィックスが必要なわけではありません。さらに、間違ったサフィックスを使用すると、コンパイル エラーや実行時エラーが発生する可能性があるため、注意して使用する必要があります。無言。

(a) 字符 宽字符型字符(wchar_t类型) 字符串 宽字符型字符串
(b) 整数 无符号数 长整数 无符号长整数 八进制数 十六进制数
(c) 浮点型 单精度浮点型 long double类型的扩展精度浮点型
(d) 整数 无符号整数 浮点数 科学计数法表示的浮点数
変数の初期化は代入と同じではありません (初期化は変数を作成して初期値を代入することであり、代入は現在の値を消去して新しい値に置き換えることです)。変数宣言では変数の型と名前を指定します
。定義では、ストレージ領域にも適用され、初期値を割り当てることもできます。(組み込み型の各変数は初期化することを推奨します)
extern int i; //声明 i
int j;//声明并定义 j
extern int k = 3; //赋初始值抵消了extern的作用变成了定义,且如果是在函数内部初始化extern标记的变量会报错
変数はファイル内で 1 回のみ定義する必要があり、また定義することもできます。他のファイルで使用される変数は宣言する必要がありますが、繰り返し定義することはできません。(変数は 1 回のみ定義できますが、複数回宣言できます)
識別子の命名規則は
文字、数字、アンダースコアで構成され、文字またはアンダースコアで始める必要があります。
識別子を指定できません
- if、int、false など、C++ 言語で使用されるいくつかのキーワード。
- C++ 標準ライブラリの一部の予約語には、連続して 2 回下線を引いたり、大文字で始まる下線を付けることができません。
- 関数の外で定義された識別子をアンダースコアで始めることはできません。
推奨される識別子の仕様
- 名前を見て意味が分かり、実際の意味を反映し、理解しやすい
- インデックスなどの変数名の小文字
- クラス名は大文字で始まります (例: Index)
- 複数の文字で構成される識別子は、アンダースコアで区切るか、student_loan_up やstudentLoanUp のように大文字で始める必要があります。
スコープ
グローバル スコープとブロック
スコープはネストされています。外側のスコープは名前を宣言し、そのネストされたスコープ、つまり内側のスコープはその名前にアクセスでき、内側のスコープは外側のスコープを再定義できます。ドメインにはすでに名前。
参照とポインタの主な違い
- 参照は作成時に初期化する必要があります (ポインターはいつでも初期化できます)。
- NULL 参照は存在できず、参照は正当な記憶場所に関連付けられている必要があります (ポインターは NULL であっても構いません)。
- 参照が初期化されると、参照関係を変更することはできません (ポインターは、参照するオブジェクトをいつでも変更できます)。
https://www.runoob.com/w3cnote/cpp-difference-between-pointers-and-references.html
初期化されていないポインタを使用すると、簡単にエラーが発生する可能性があるため、次のような特定のオブジェクトを指すときにポインタが nullptr に初期化されるかどうかは不明です: int *p = nullptr; したがって、ポインタが正当なアドレスを指しているかどうかを判断するには、
単にnullptr であるか、初期化されていないかを判断します。 ポインターの場合は、エラーがあるかどうかを try...catch できます。
void* は、任意のオブジェクトのアドレスを格納できる特別なポインター型です。
int* p と int *p の問題は、基本型が int である p が int へのポインタであるため、2 番目の記述方法である int *p1, *p2; を使用することをお勧めします。
ポインターへのポインターは、元のオブジェクトにアクセスするために 2 回逆参照する必要があります。
ポインターへの参照、参照自体はオブジェクトではないため、参照へのポインターは定義できませんが、ポインターはオブジェクトであるため、ポインタへの参照です。
int i = 33;
int *p;//int 类型的指针p
int *&r = p;//从右往左看,r 是 对指针p的引用
r = &i;//r是指向p的引用,给r赋值&i 就是让p指向i
*r = 0;//解引用 r 得到 i,也就是p指向的对象,改i的值为0
複雑なポインターまたは参照宣言ステートメントに直面した場合、右から左に読むと、本当の意味を明確にすることができます。
const 変数を定義し、それを複数のファイルで宣言する方法は、定義されているか宣言されているかに関係なく、 extern キーワードを追加することです。
extern const int bufsize = fcn();//1.cc定义并初始化一个常量,并让该常量能被其他文件访问
** 最下位レベルの定数と最上位レベルの定数? **
定数式: 値が変化せず、コンパイル中に計算結果が取得できる式。
たとえば、 const Staff_size = get_size(); は実行時まで取得できないため、そうではありません。 Const int limit = 20; は定数です表現。
C++11: 変数が定数式であると判断した場合は、それを constexpr 型として宣言します。
自動型導出
1. 初期値として参照を使用する場合、参照オブジェクトの型を auto の型として使用します;
int i = 0, &r = i;
auto a = r; //型は int
2. auto最上位の const は無視され、基礎となる const は保持されます;
auto &h = 42; //非 const 参照は変更可能なオブジェクトにバインドされる必要があります;
const auto &j = 42;
すべてはできるだけシンプルにする必要がありますが、シンプルにする必要はありません
クラスはオブジェクトの抽象的かつ集合的な名前であり、オブジェクトはクラスのインスタンスです。
浅いコピー: ポインター アドレスのみをコピーします。C++ の既定のコピー
コンストラクターと代入演算子のオーバーロードは浅いコピーです。
スペースは節約されますが、複数のリリースが発生しやすくなります。
深いコピー: ヒープ メモリを再割り当てし、
ポインターが指す内容をコピーします。
スペースを無駄にしますが、複数のリリースにはつながりません。
コピーオンライト
2. C++ ポインター
初期化されておらず不正なポインタであるため、ポインタの間接参照を使用するときは、ポインタが適切に初期化され割り当てられていることを確認するために細心の注意を払う必要があります。
1. 最初にポインタがどこを指しているかわからない場合、または使用しない場合は、ポインタを null に初期化できます
2. ポインタを間接参照する前に、ポインタの値が null かどうかを確認します。
int *a;//未初始化化
*a = 12//非法访问
運が良ければ、不正なアドレスを見つけて、プログラムがエラーで終了します。運が悪いと、アクセス可能なアドレスを見つけて変更します。エラーを見つけるのは難しく、引き起こされるエラーはまったく予期しないものである可能性があります。
左辺値と右辺値

= 記号の左側が左辺値、= 記号の右側が右辺値です。左の値は上に示すように cp+1 のメモリ空間を取得し、右の値はメモリ空間の値を取得します。
char ch = 'a';
char *cp = &ch;
++++、----、その他の演算子について:
コンパイラプログラムをシンボルに分解する方法は次のとおりです: 1 文字ずつ読み取ります
文字がシンボルを形成する可能性がある場合は、読み込まれるまで次の文字を読み取ります 入力された文字は
ありませんより長くは意味のあるシンボルを形成します。このプロセスは「貪欲法」と呼ばれます。
例: int a=1,b=2;c;
c=a++b;/∥ は a+++b と同等
d=a++++b;/∥ は af+++ と同等b、エラー
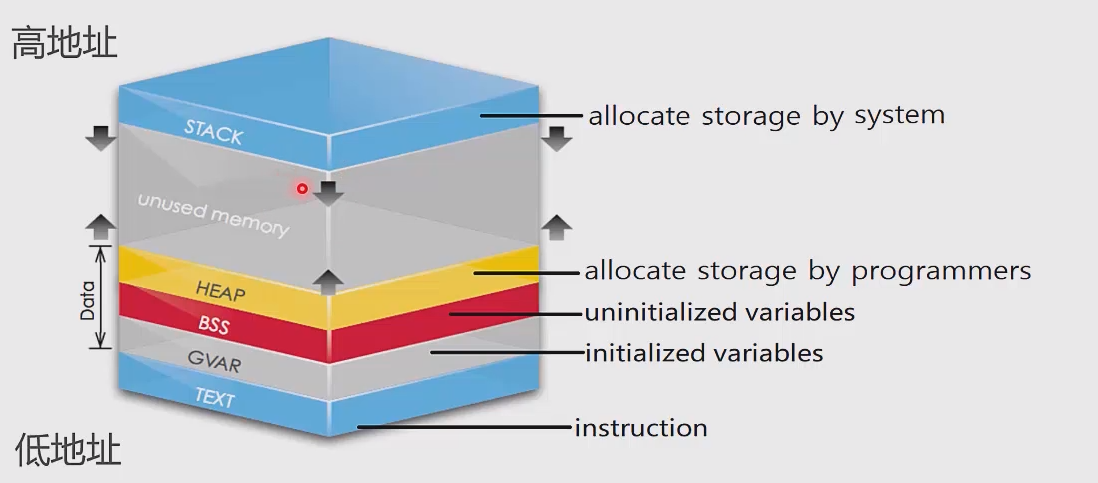
C++ プログラム内のコードとデータの保管。


RAlI (Resource Acquisition Is Initialization) :
C++ 独自のリソース管理方式。Rust など、他のいくつかの言語でも RAII が採用されていますが、主流のプログラミング言語の中でリソース管理に RAII に依存しているのは C++ だけです。RAlI は、スタックとデストラクターに依存して、ヒープ メモリを含むすべてのリソースを管理します。
RAll を使用すると、Java のようなガベージ コレクション メソッドを必要とせずに、C++ でメモリを効果的に管理できるようになります。RAll の存在は、ガベージ コレクションが理論的には C++ で使用できるにもかかわらず、実際には普及していない主な理由でもあります。
RAll には、std:auto_ptr や boost:shared_ptr など、比較的成熟したスマート ポインターの代表的なものがいくつかあります。

メモリ リーク (メモリ リーク) 問題
メモリ リーク問題とは:
プログラム内で動的に割り当てられたヒープ メモリが解放されない、または何らかの理由で解放できないため、
システム メモリが無駄に消費され、プログラムの速度が低下することを指します。その結果、ダウンしたり、システムがクラッシュしたりすることもあります。
メモリ リークの原因とトラブルシューティング方法:
1. メモリ リークは主にヒープ メモリの割り当て方法、つまり「メモリの構成後、
メモリを指すすべてのポインタが失われる」方法で発生します。言語のようなガベージ コレクション メカニズムがなければ、そのようなメモリ
スライスをシステムに返すことはできません。
2. メモリ リークはプログラムの実行中に発生する問題であり、コンパイルでは特定できないため、
プログラムの実行中にのみ特定および診断できます。
C++ では、一般的に使用される 4 つのスマート ポインターが導入されています:
unique_ptr、shared_ptr、weak_ptr、
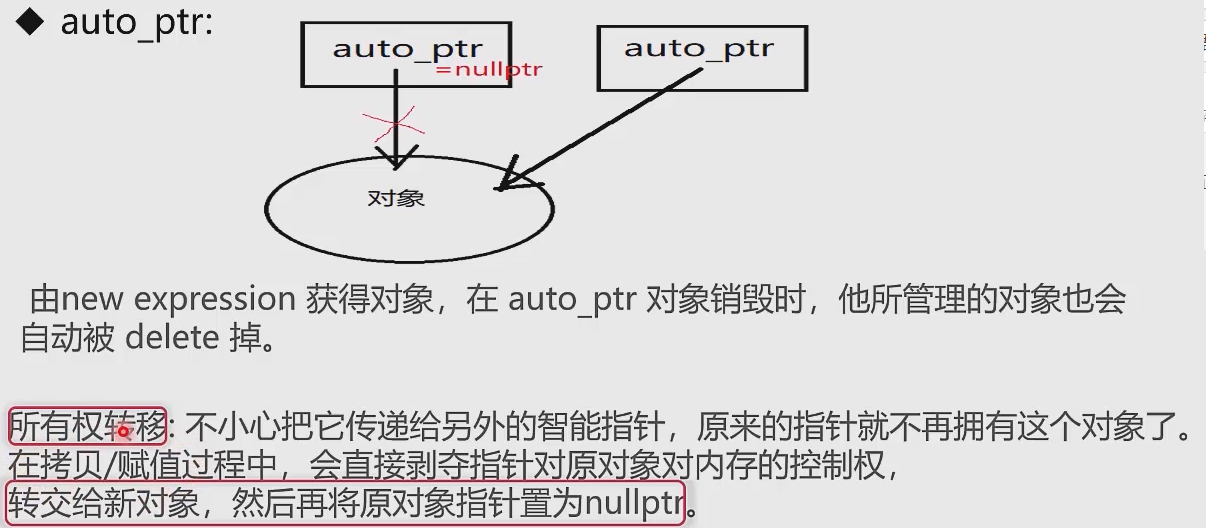
auto_ptr: C++11 で非推奨となり、C++17 で正式に削除されました。

使用法の問題
所有権の問題
循環参照: 参照カウントによって循環参照の問題が発生し、ヒープ メモリが正常にリサイクルできなくなり、メモリ リークが発生します。
C++ リファレンス

関数の基本型の場合は値による受け渡しがより効率的であり、カスタム型の場合は const への参照による受け渡しがより効率的です。
「ワイルド」ポインタを削除し、
「ジャンク」メモリを指すポインタを削除します。NULL が設定されていないため、if やその他の判断が機能しない場合は、
一般的に次の 3 つの状況があります:
1. ポインタ変数が初期化されていない、
2. 削除および削除後のポインタなど、解放されて未使用になっているポインタが NULL に設定されていない無料;
3. ポインタ操作が変数の範囲を超えます。
ポインタの使用に関する注意:
初期化されていない、未使用、または範囲外のポインタの場合は、値を NULL に設定してください。(難しいです。ポインターは複数の場所で使用されており、いつ不要になったかを判断するのは困難です。解決策: スマート ポインター)
null ポインタは null へのポインタであり、メモリ初期化ポインタ変数に使用されます。メモリ番号 0 ~ 255 は、システムによって占有されているメモリであり、アクセスできません。ワイルド ポインタは、不正なメモリ空間を指すポインタです。どちらのアクセスも必要です
。エラーを報告しますが、Dev での実行は次のとおりです コード: 正しくコンパイルされ、引き続き実行できますが、出力がありません。一定時間実行するとウィンドウが自動的に閉じます。これはなぜですか?
#include <bits/stdc++.h>
using namespace std;
int main(){
int a = 10;
int *p = NULL;
cout << *p <<endl;
int *q = (int *)0x1110;
cout << *q <<endl;
return 0;
}
構文は正しく、コンパイラを通過できますが、null ポインターやワイルド ポインターの参照解除によってメモリ アクセス違反が発生するため、オペレーティング システムはシステムを保護するためにプログラムの実行を終了します。
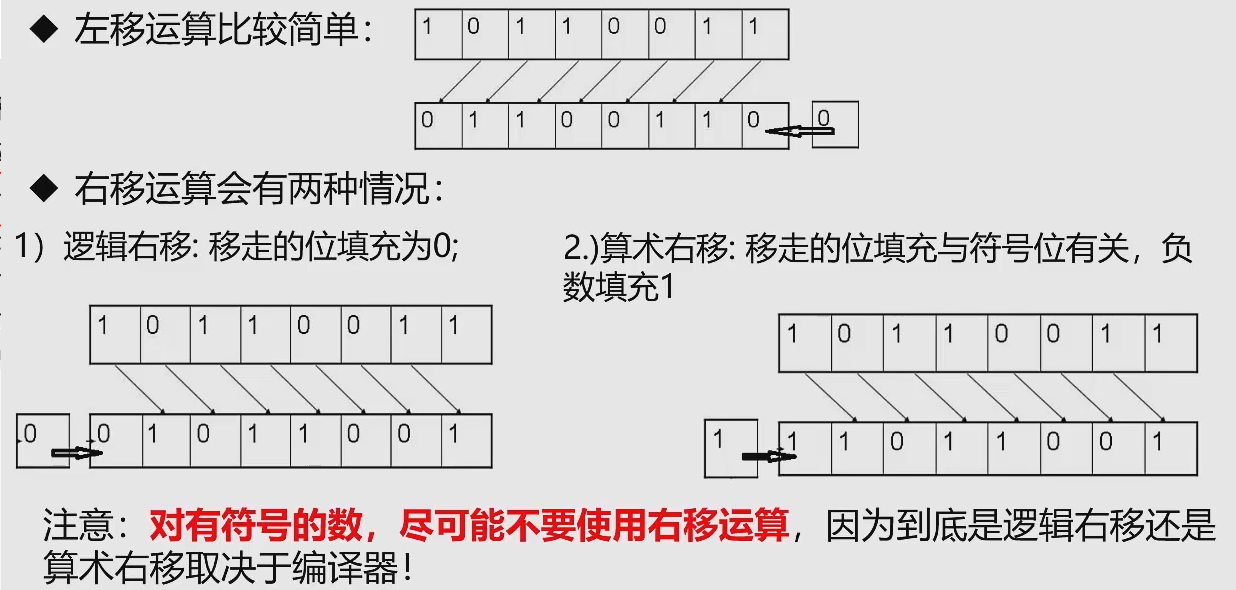
マシンの実際の格納方法: 正の数値は直接格納され、負の数値は符号ビットを保持し、ビット単位の +1 を反転します。ビッグ
エンディアンはインターネットで一般的に使用され、人間の読書習慣に準拠しており、リトル エンディアンはほとんどの場合に使用されます。個人の PC およびマシンに準拠します。

これは非常に重要なので注意してください。!!

Redis で設計された sdshdr 構造には、文字列の長さを格納する len 変数があり、計算するためにトラバースする必要はありません。残りの容量を自由に管理できます。容量が十分でない場合は、自動的に拡張および変更されます。レンズサイズ。
ポインタと参照

ポインターの配列。この配列内のそれぞれがポインターです。T *t[ ]
配列ポインター (配列へのポインター)、このポインターは配列を指します。T (*t) [ ]

3 番目の例では、最初に最初の const 変更の左側の文字を確認します。これは、ポインタの値を変更できないことを意味します。次に、2 番目の * の const 変更を確認します。これは、ポインタのポインティングが変更できないことを意味します。
const がポインターを変更する場合には 3 つの状況があります。
- const 変更されたポインター - 定数ポインター (指すポインターは変更できますが、指す値は変更できません)
- const 変更定数 - ポインター定数 (ポインター ポインターは変更できませんが、ポインター値は変更できます)
- const はポインタと定数を変更します (どちらも変更できません)
const の右辺がポインタか定数かを見て、ポインタであれば定数ポインタ、定数であればポインタ定数です。
const は誤用を防ぐためによく使用されます
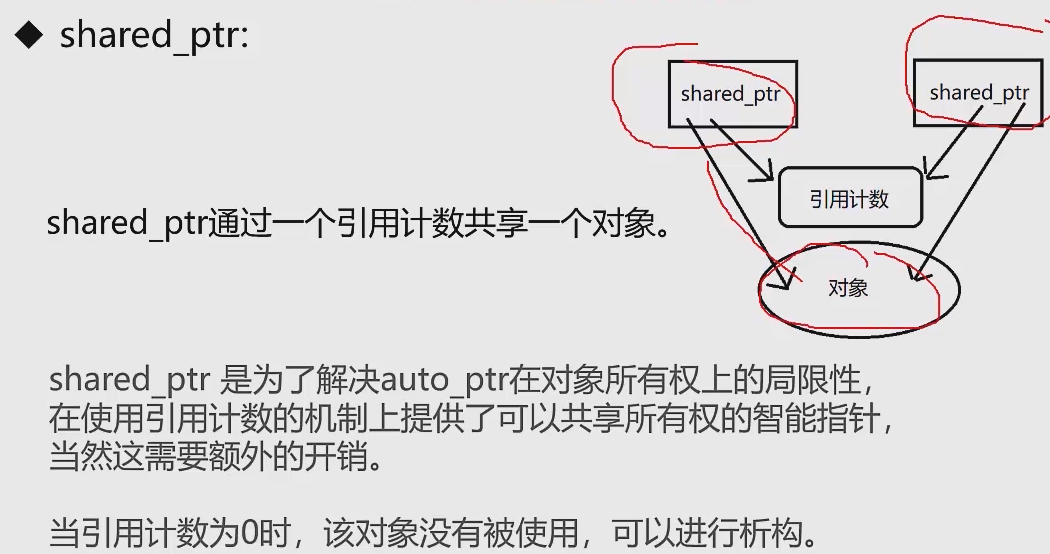
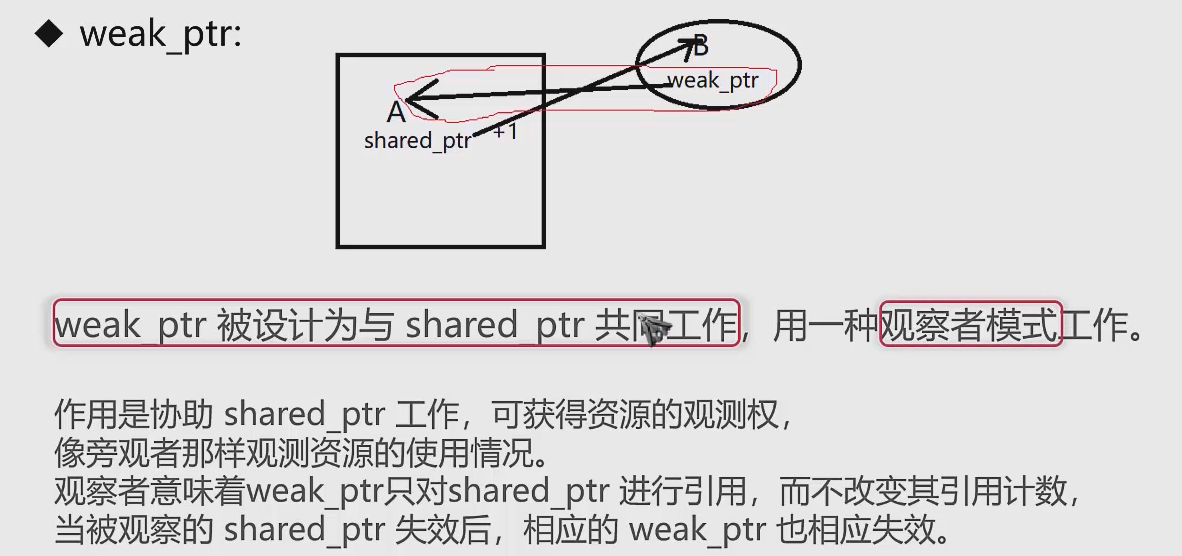
スマートポインター
ヒープ領域のメモリは手動で解放する必要があります。解放しないとメモリ リークが発生します。
解決策: スマート ポインタはクラス テンプレートです。スタック上にスマート ポインタ オブジェクトを作成し、通常のポインタをスマート ポインタ オブジェクトに渡し、スマート ポインタ オブジェクトの有効期限が切れたら、デストラクタを呼び出して通常のポインタのメモリを解放します。
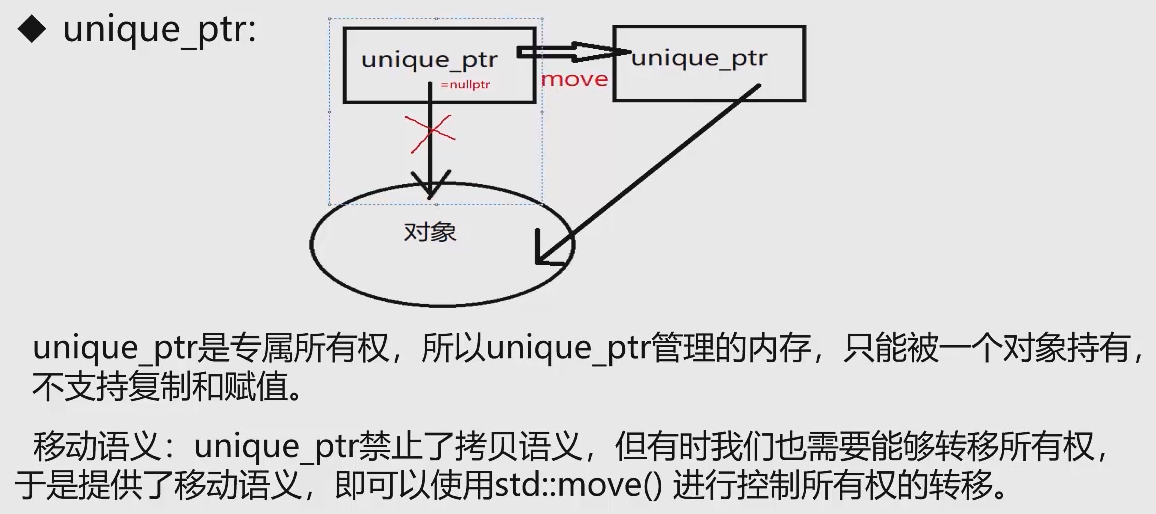
unique_ptr: 排他的に指すオブジェクト
shared_ptr:
wear_ptr:

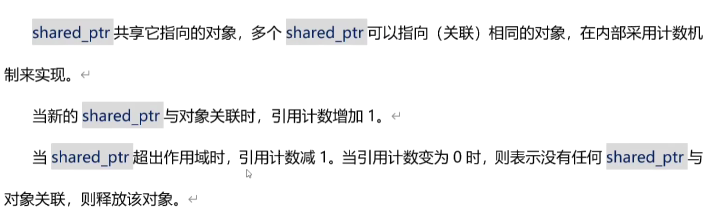




3. C++STL ライブラリ
stl ライブラリの
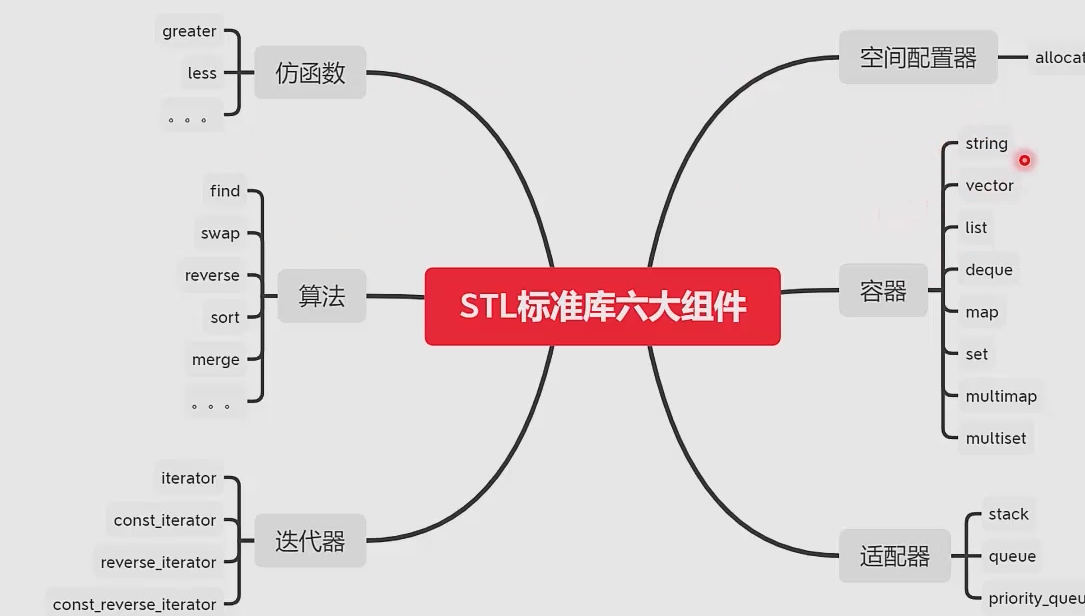
6 つの主要コンポーネント間の関係
容器
コンテナはデータの保存に使用されます。STL
コンテナは 2 つのカテゴリに分類されます:
シーケンスコンテナ:
コンテナ内の要素はすべて並べ替え可能 (順序付け可能)。STL はベクトル、リスト、デック、およびその他のシーケンス コンテナを提供します。スタック、キュー、優先キューはコンテナです。アダプター、
連想コンテナー:
各データ要素はキー (キー) と値 (値) で構成されます。要素がコンテナーに挿入されるとき、何らかの方法でそのキーを押します。特定のルールが適切な場所に配置されます。共通 STL関連するコンテナー: set、multiset、map、multimap など。
#include <bits/stdc++.h>
using namespace std;
struct Display{
void operator()(int i){
cout << i << " ";
}
};
int main(){
int arr[4] = {
1, 2, 3, 4};
vector<int> vec(arr, arr+4);//动态数组
list<int> lis(arr, arr+4);//链表
deque<int> deq(arr, arr+4);//双端队列
queue<int> que(deq);//队列
stack<int> sta(deq);//栈
priority_queue<int> prique(arr, arr+4);//优先队列
for_each(vec.begin(), vec.end(), Display());
for_each(deq.begin(), deq.end(), [](int i){
cout<< i << " ";
});
while(!que.empty()){
cout << que.front() << " ";
que.pop();
}
while(!sta.empty()){
cout << sta.top() << " ";
sta.pop();
}
cout<<endl;
map<string, int> studentlevel;
studentlevel["level1"] = 1;
studentlevel["..."] = 3;
studentlevel["level6"] = 6;
studentlevel.insert(pair<string, int>("level4", 4));
for_each(studentlevel.begin(), studentlevel.end(), [](pair<string, int> i){
cout<<i.first<<":"<<i.second<<endl;
});
map<string, int>::iterator iter = studentlevel.find("level6");
if(iter != studentlevel.end()){
cout<<"level6 超能力者人数:"<<iter->second<<endl;
}
return 0;
}
**注意することが非常に重要です: ** iter =studentlevel.earse(''cc''); キー cc で値を削除し、次の位置で反復子を返します; (*it) などの反復子の失敗の問題に注意してください
。 empty(); 簡略化しました->empty();
イテレータを使用するループ本体では、イテレータが属するコンテナに要素を追加しないでください。
たとえば、push_back により、ベクトル オブジェクトのイテレータが無効になる可能性があります。
たとえば、範囲 for ループによりベクトルに要素が追加されます。 。
ファンクタ
- ファンクターは通常、単独で使用されることはなく、主に STL アルゴリズムで使用されます。
- 関数ポインタは STL の抽象化要件を満たすことができず、ソフトウェア ビルディング ブロックの要件を満たすことができず、STL の他のコンポーネントと一致させることもできません。
- 本質は、クラスがoperator()をオーバーロードし、関数のように動作するオブジェクトを作成することです。
関数ポインター -> ジェネリック -> ファンクター -> ファンクター テンプレートから; 遅延
bool MySort(int a, int b){
return a ‹ b;
}
void Display(int a){
cout << a <<" ";
}
int main(){
//C++方式
int arr[] = {
4,3, 2, 1,7};
sort(arr, arr + 5, MySort);
for_each(arr, arr + 5, Display);
}
データ型が変わると多くの関数をオーバーロードする必要があり面倒なのでジェネリックが出てきました
template<class T>
bool MySort(T const& a, T const& b){
return a ‹ b;
}
template<class T>
void Display(T const& a){
cout << a <<" ";
}
int main(){
//C++泛型
int arr[] = {
4,3, 2, 1,7};
sort(arr, arr + 5, MySort<int>);
for_each(arr, arr + 5, Display<int>);
}
次にファンクターです
struct mySort{
bool operator()(int a, int b){
return a ‹ b;
}
}
struct Display{
void Display(int a){
cout << a <<" ";
}
}
int main(){
//C++仿函数
int arr[] = {
4,3, 2, 1,7};
sort(arr, arr + 5, mySort());
for_each(arr, arr + 5, Display());
}
次にファンクターテンプレートですが、基本型は追加する必要はありませんが、オブジェクトの消費量が比較的多い場合には追加してもよいでしょう。
template<class T>
struct mySort{
bool operator()(T const& a, T const& b){
return a ‹ b;
}
}
template<class T>
struct Display{
void Display(T const& a){
cout << a <<" ";
}
}
int main(){
//C++仿函数
int arr[] = {
4,3, 2, 1,7};
sort(arr, arr + 5, mySort<int>();
for_each(arr, arr + 5, Display<int>();
}
アルゴリズム
STL のアルゴリズムは大きく 4 つのカテゴリに分類されます: に含まれる
1. 非変数シーケンス アルゴリズム: 操作するコンテナの内容を直接変更しないアルゴリズムを指します; 2.
変数シーケンス アルゴリズム: コンテナの内容を変更できるアルゴリズムを指しますアルゴリズム;
3. 並べ替えアルゴリズム: シーケンスの並べ替えとマージ、検索アルゴリズム、および順序付けされたシーケンスの集合演算のアルゴリズムを含む;
4. 数値アルゴリズム: コンテナの内容に対して数値計算を実行する;
最も一般的なアルゴリズムには次のものがあります。 :
検索、ソートおよび一般的なアルゴリズム、順列および結合アルゴリズム、数値アルゴリズム、集合アルゴリズムおよびその他のアルゴリズム
変換(); コンテナ計算関数; カウント統計関数; binary_search(); 二分探索;
int main(){
int arr[] = {
1, 1, 1, 2, 2, 3, 4, 5, 5, 6};//父序列
vector<int> zi(arr+2, arr+6); //子序列
int len = sizeof(arr)/sizeof(arr[0]);
cout << count(arr, arr+len, 1) << endl;
cout << count_if(arr, arr+len, bind2nd(less<int>(), 4)) << endl;
cout << binary_search(arr, arr + len, 6)<<endl;
cout<< *search(arr, arr+len, zi.begin(), zi.end()) << endl;
return 0;
}
手書きの完全整理の実施
重複する文字を含まない完全な文字列を入力し、文字列内の文字の完全な配置を出力します
。たとえば、「123 = 3 2 1 = 3!」と入力します。
全体状況を出力
123
132
213
231
312
321
#include <bits/stdc++.h>
//f(123)=1+f(23),f(23)=2+f(3),f(3)=3递归
using namespace std;
void swap(char*a, char *b){
char tmp = *a;
*a = *b;
*b = tmp;
}
void permutation(char *ptr, char* postion){
if(*postion == '\0'){
//基准点,退出
cout << ptr <<endl;
}
for (char* pChar = postion; *pChar != '\0'; pChar++){
swap(*pChar, *postion);//依次和后面的字符交换,比如123,定1位,依次交换2,3
permutation(ptr, postion + 1);//递归下去
swap(*postion, *pChar);//别忘了换回来
}
}
int main(){
char test[] = "321";
permutation(test, test);
return 0;
}
配列の順序は保証されなければなりません。たとえば、next は小さいものから大きいものへの順です。自分で実装すると配置が崩れることはありません。Prev は大きいものから小さいものの順です。完全な配置関数 next_permutation() と
prev_permutation stl 内の ();
sort
STLのソートアルゴリズムは、
データ量が多い場合にはQuickSort(クイックソート)を使用し、セグメントごとにマージしてソートします。
分割されたデータの量が一定のしきい値 (16) を下回ると、QuickSort の再帰呼び出しによる過度の余分な負荷を避けるために、代わりに InsertSort (挿入ソート) が使用されます。
再帰レベルが深すぎる場合は、代わりに HeapSort (ヒープ ソート) が使用されます。
イテレータ
スマート ポインターと同様に、小さな手書きの gc ケースではイテレーター メソッドが使用されます。
オープンソースコード MyGC

Int main0
GCPtr<int> p;
try{
p = new int;
catch (bad_alloc exc)X
cout << "Allocation failure!\n";
return 1;
3
*p =88;
*p+=1;
cout << "Value at p is:* << *p << endl;
GCPtr<int> p1 =p;
cout << "p's list size;: " << p.gclistSize() << endl;
p.showlist(0;
GCPtr<int, 10> pA = new int[10];
Iter<int> it = pA.beginO;
int index = 1;
for ( it != pA.end); it++)
7it = index++;
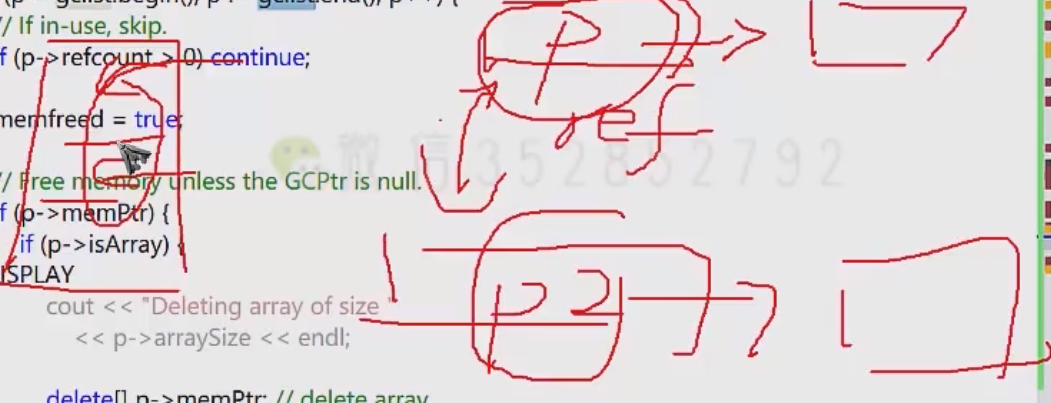
オブジェクトを指すポインタには ref 参照カウントが含まれていますが、リストを使用してポインタを記録し、最後にリスト上のすべてのポインタを解放して循環参照の問題を解決します。

コンテナアダプター
stack stack:
「先入れ先出し」コンテナ、基礎となるデータ構造は deque;
queue キュー:
「first in first out」コンテナ、基礎となるデータ構造は deque;
priority_queue 優先キュー:
ソート可能な特別なキューキュー (ヒープ ソート) では、基礎となる実装構造は Vector または DEQUE です。
優先キュー
priority_queue<int> a;//默认大根堆,升序排列
priority_queue<int, vector<int>, greater<int>> b;//升序排列大根堆
priority_queue<int, vector<int>, less<int>> c;//降序排列小根堆
greater和less是仿函数,就是一个类中重载operator()的实现,类就有了类似函数的行为即仿函数,当涉及自定义类型当然可以自己重载;
struct cmp{
bool operator(type a, type b){
return a.x < b.x;//大顶堆
}
}
スペースアロケータ
- 「STL ソース コード分析」Hou Jie、SGI STL バージョンはさらに読みやすくなっています。
- アロケータは、使い方の観点からは他のコンポーネントに隠れて静かに動作するため意識する必要はありませんが、STL 実装を理解するという観点からは、最初に解析する必要があるコンポーネントです。
- アロケータの分析は、パフォーマンスとリソース管理における C++ の最適化アイデアを反映できます。
STL の概要
STL の 6 つの主要コンポーネントは、ソフトウェア プログラミングに新しいポリモーフィズムと再利用をもたらし、最新の C++ 言語効率の本質です。ジェネリックと
STL の学習パスは非常に険しく、初心者はまず基本的な使用法と簡単な使い方を学ぶことをお勧めします。拡張機能;
特定の基礎を習得した後、ソース コードをさらに研究および分析し、独自のコンポーネントを作成することで、能力を向上させることができます。
その他の図書館
boost ライブラリ
Boost ライブラリは、C++ 言語標準ライブラリへの拡張機能を提供するいくつかの C++ ライブラリの一般名です。Boost コミュニティ組織によって開発および保守されています。Boost ライブラリは C++ 標準ライブラリと完全に連携し、その拡張機能を提供します。 ; C++ 標準ライブラリもその機能の一部を徐々に吸収;
Boost は、文字列およびテキスト処理ライブラリ、コンテナ ライブラリ、アルゴリズム ライブラリ、関数オブジェクトおよび高階プログラミング ライブラリ、包括的なクラス ライブラリなど、20 以上のカテゴリに大別できます。 .;
公式ウェブサイト: https://www.boost.org/
ミラー: https://dl.bintray.com/boostorg/release/
C++14/17 ベースのHTTP アプリケーション フレームワークDrogon (「ゲーム オブ スローンズ」のドラゴン (Drogon) の名前): https://github.com/drogonframework/drogon/blob/master/README.zh- CN .md
grpc によって翻訳された中国語ドキュメント: https://doc.oschina.net/grpc?t=58008 (クロスプラットフォーム RPC フレームワーク)、説明: https://juejin.cn/post/7047885453336248327
Tencent のオープンソース RPC フレームワーク phxrpc: https://gitee.com/mirrors/PhxRPC# https://gitee.com/link?target=https%3A%2F%2Fgithub.com%2FTencent%2Fphxrpc%2Fwiki
https:// github.com/Tencent/phxrpc
4. C++ 設計パターン
ソフトウェアには 23 の共通のオブジェクト指向で再利用可能な設計パターンがあり、これまでの経験に基づいていくつかの一般的な問題に対する一般的な解決策を提供します。
デザインパターンにもコストと適用可能なシナリオがありますが、万能ではなく、実際にはこの 23 種類は拡張性が高く、将来的に変更を加えながら多くのシナリオで繰り返し使用されるシナリオに適しています。
シングルトンパターン
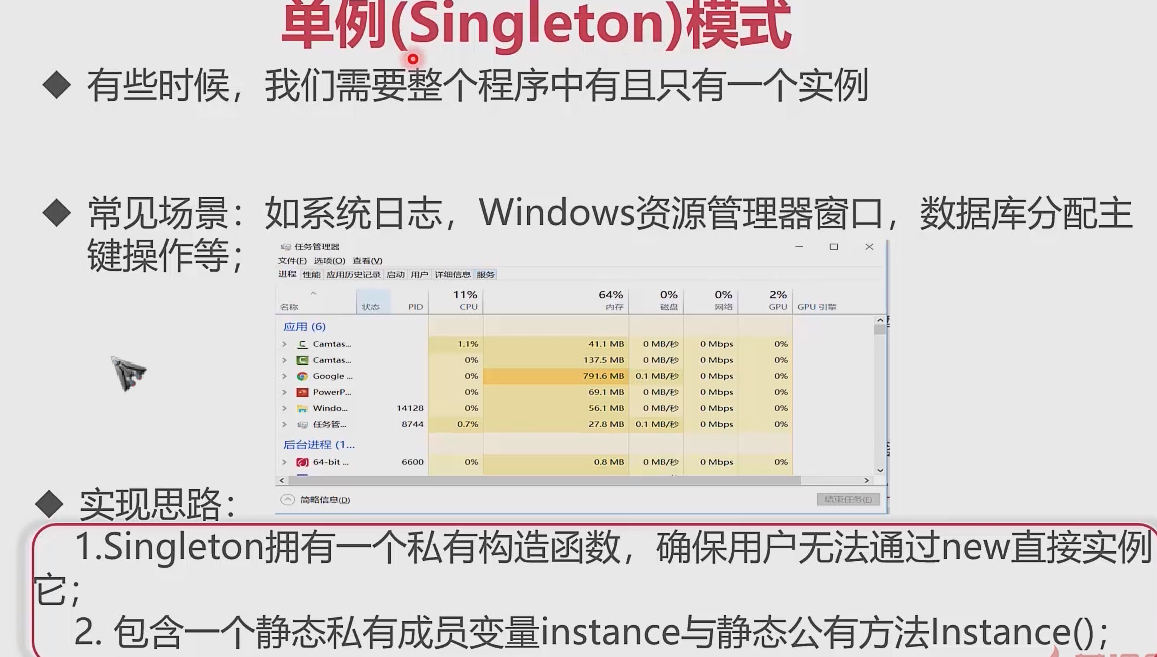
オブザーバーパターン

実装のアイデア:
問題の責任、抽象的な Observable とオブザーバーを切り離し、抽象化とエンティティを区別します。
class Observer
public:
Observer();
virtual ~Observer();
//当被观察对象发生变化时,通知被观察者调用这个方法
virtual void Update(void* pArg) = 0;
}
class User1:public Observer{
virtual void Update(void* pArg)
cout <<"User1 Got News:" << endl;
}
class User2 :public Observer{
virtual void Update(void* pArg)
cout <<"User2 Got News:" << endl;
}
void、NULL、nullptrとは何ですか?
void* は、あらゆる種類のデータを指すことができる一般的なポインター型です。これは特定のデータ型に直接関連していないため、逆参照できず、明示的な型変換を使用する必要があります。例えば:
void* ptr = nullptr; // ptr は null ポインター
int* intPtr = static_cast<int*>(ptr); // voidポインターを intポインターに変換する
古い C++ バージョンでは、NULL は整数 0 として定義されていました。これは、null 値へのポインタとして使用できることを意味します。ただし、0 は他の整数型の値にもなり得るため、整数 0 を使用すると、曖昧さが生じる可能性があります。最新の C++ では、NULL の代わりに nullptr を使用することをお勧めします。例えば:
int* ptr = nullptr; // ptr は null ポインター
nullptr は、null ポインターを表すために C++11 で導入されたキーワードです。nullptr は、NULL と比較して型安全性が優れています。これは暗黙的に任意のポインター型に変換可能であり、他の整数型と混同することはできません。例えば:
int* ptr = nullptr; // ptr は null ポインタです
ポインタはメモリ アドレスを格納するために使用される変数であり、指すデータには逆参照演算子 * を介してアクセスできます。null ポインタは、ポインタが有効なメモリ アドレスを指していないことを意味します。C++ では、これらの概念を使用して、ポインターが null の状況を簡単に処理し、未定義の動作やエラーを回避できます。

23 のオブジェクト指向デザイン パターンは、創造的パターン、構造的パターン、動作パターンに大別されます。
デザイン パターンは全能ではなく、システムの変更点に基づいており、変更があればどこでも使用できます。
デザイン パターンは分離されており、展開する、通常は進化しており、正確に
位置付けるためには進化が必要である;
デザイン パターンはソフトウェア設計手法であり、標準ではない 現在、現在のフレームワークのほとんどには、すでに
多数のデザイン パターンのアイデアが含まれています。
汎用プログラミング

オブジェクト指向が抽象化と引き換えに間接層を介して関数を呼び出す方法である場合、ジェネリック プログラミングはより直接的な抽象化であり、間接層のために効率が失われることはありません。オブジェクト指向の動的ポリモーフィズムとは異なり、ジェネリック プログラミング
は静的ポリモーフィズムの一種で、コンパイル時にコンパイラを通じて最も直接的なコードを生成します。
ジェネリック プログラミングでは、アルゴリズムを特定の型や構造から分離し、コードを可能な限り再利用できます。
template<class T>
T max(T a, T b){
return a > b ? a : b;
}
//特化
template<class T1, class T2>
int max(T1 a, T2 b){
return static_cast<int>(a > b ? a : b);
}
int main(){
cout << max(1, 3) << endl;
cout << max(3.5, 1.5) << endl;
cout << max('a', 'b') << endl;
cout << max(10, 3.5) << endl;
}
コンパイラは、関数に渡された実際のパラメータの型に基づいて、対応するテンプレート関数インスタンスをインスタンス化します。
ジェネリックス、ポリモーフィズム、オーバーロードの関係: ジェネリックスはコードの再利用性を向上させますが、ポリモーフィズムやオーバーロードの概念には直接関係しません。ポリモーフィズムは、異なるクラスのオブジェクトが同じメッセージに応答できるようにする機能を指します。一方、オーバーロードは、同じスコープ内で同じ名前で異なるパラメーター リストを持つ複数の関数を許可することを指します。ジェネリックスはコードの再利用性を向上させますが、これらの概念には直接影響しません。
この例では、ジェネリック関数を示します。max 関数は型を繰り返し変更する必要はありません。代わりに、コンパイラは、渡されたパラメータとテンプレートに基づいて関数呼び出しを生成します。ただし、ジェネリック関数がニーズを満たさない場合は、特殊化する必要があります。デバッグを中断して、どの関数が実行されているかを確認できます。
一般的なプログラミングで一度間違いを犯すと、初心者にとってそれを修正するのは困難です。コンパイラは多くのことを自動的に実行するためです。
関数型プログラミング。
static_cast

//C++ const转ẽ
const int a = 10;
//int* pA = &a;
int* pA = const_cast<int*>(&a);
*pA = 100:
cout<<a<<endl;可能任然是10,内存模型问题
return O;

アダプターパターン
元のコードの関数を再利用し、変更せずに新しい関数を作成します。多重継承は非常に悪質です。これは C++、ダイヤモンド継承の問題、仮想継承と
関係があります。
1 つ目: 多重継承を使用する
2 つ目: 組み合わせを使用して、元のクラスのオブジェクトを新しいクラスのメンバー変数としてインスタンス化します。