1 ストリームとパラレルストリームの違い
1. ストリームは Java8 の新機能であり、一般にストリームと呼ばれていますが、データ構造ではなくデータを格納せず、主にコレクションの論理処理に使用されます。
2. ストリームは、コレクション要素の関数モデルです。コレクションやデータ構造ではありません。それ自体は要素 (またはそのアドレス値) を格納しません。元のデータ セットに対する一連の操作を定義するだけです。
3. ストリーム ストリームはデータを保存せず、ストリーム操作は可能な限り遅延します。つまり、ストリーム内の要素がアクセスされるたびに、この一連の操作がこの要素に対して実行されます。
4. ストリームフローは元のデータを変更しないため、変更されたデータを取得したい場合は、オブジェクトを使用してそれを受け取る必要があります。
シリアル ストリーム: 非同期スレッドを生成せずにデータをシリアルに処理します。
パラレル ストリーム パラレルストリーム: パラレル ストリームは、ストリームのもう 1 つの重要な機能であるストリームの並列処理を提供します。その最下層は、Fork/Join フレームワークを使用して実装されます。簡単に理解すると、マルチスレッドの非同期タスクの実装となります。
提案: データ量が大きくない場合は、ストリームを使用することをお勧めします。並列ストリームはマルチスレッドで非同期であるため、やみくもに大量に使用しないでください。つまり、複数のスレッドが生成され、メモリが消費され、遅くなるのではなく、間違いなく速くなり、より良くなります。
2 一般的な方法の紹介
2.1 groupingByメソッド
主にデータをMapに変換するもので、valueは条件を満たす集合です。
List<Admin> adminList = adminMapper.selectList(null);
Map<Long, List<Admin>> adminMap = adminList.stream().collect(Collectors.groupingBy(Admin::getId));
2.2 toMap メソッド
主にデータをMapに変換します。valueはレコードまたはフィールドの値です。
List<Admin> adminList = adminMapper.selectList(null);
Map<Long, String> adminMap = adminList.stream().collect(Collectors.toMap(Admin::getId, Admin::getRealName, (key1, key2) -> key1));
2.3 フィルタ法
主にデータのフィルタリングに使用されます
List<Admin> adminList = adminMapper.selectList(null);
adminList = adminList.stream().filter(admin -> admin.getAdminState() != null).collect(Collectors.toList());
2.4 anyMatch メソッド
データを判定し、1 つの条件が満たされる限り true を返すために使用されます。
List<Admin> adminList = adminMapper.selectList(null);
boolean isAdmin = adminList.stream().anyMatch(admin -> admin.getAdminState() != null);
2.5 allMatch メソッド
データを判断するために使用され、true を返すにはすべてが満たされる必要があります
List<Admin> adminList = adminMapper.selectList(null);
boolean isAdmin = adminList.stream().allMatch(admin -> admin.getAdminState() != null);
2.6 noneMatch メソッド
データの判定に使用され、すべてを満たさない場合にのみ True が返されます。
List<Admin> adminList = adminMapper.selectList(null);
boolean isAdmin = adminList.stream().noneMatch(admin -> admin.getAdminState() != null);
2.7 マップメソッド
通常、属性値を取得するために使用されます
List<Admin> adminList = adminMapper.selectList(null);
List<Long> adminIdList = adminList.stream().map(Admin::getId).collect(Collectors.toList());
2.8 ピーク方法
通常はデータを変更するために使用されますが、公式には推奨されていません。
List<Admin> adminList = adminMapper.selectList(null);
adminList = adminList.stream().peek(admin -> admin.setAdminState(null)).collect(Collectors.toList());
3ParallelStream を使用する際の注意事項
1.ParallelStream はスレッドセーフではありません。
2. ParallelStream は、CPU を大量に使用するシナリオに適しています。CPU を無駄にしないでください。コンピュータの CPU 負荷が非常に高い場合、どこでも並列ストリームを使用しても効果的ではありません。I/O 集中型のディスク I/O とネットワーク I/O はすべて I/O 操作です。これらの操作では CPU リソースの消費が少なくなります。一般に、並列ストリームは、並列ストリームの使用など、I/O 集中型操作には適していません。大量の I/O を伴う大量のメッセージのバッチをプッシュするのが一般的ですが、並列ストリームを使用するとはるかに時間がかかります。
3. 並列ストリームを使用する場合、要素の順序は保証できません。つまり、同期コレクションを使用する場合でも、要素が正しいことを確認することはできますが、順序は保証できません。
4 実際の比較
4.1 コードは次のとおりです
/**
* parallelStream()和stream()执行速度测试
*/
@Test
public void test6() {
List<Integer> a = new ArrayList<>();
for (int i = 0 ; i < 1000 ; i++) {
a.add(i);
}
long b = System.currentTimeMillis();
a.parallelStream().forEach(obj->{
try {
Thread.sleep(100);
} catch (InterruptedException e) {
log.error("出错:", e);
}
System.out.println(obj);
});
long c = System.currentTimeMillis();
long d = System.currentTimeMillis();
a.stream().forEach(obj->{
try {
Thread.sleep(100);
} catch (InterruptedException e) {
log.error("出错:", e);
}
System.out.println(obj);
});
long e = System.currentTimeMillis();
System.out.println("并行耗时:" + (c-b));
System.out.println("串行耗时:" + (e-d));
}
4.2 実行結果
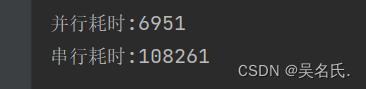
5。結論
上記の実行結果からわかるように、ParallelStream は時間のかかるメソッドを同時に実行すると、Stream よりも実行時間が短縮されますが、使用する際には注意が必要な点がいくつかあります。