Didi では、観察可能なプラットフォームのメトリクス データにはいくつかのリアルタイム コンピューティング要件があり、これらのリアルタイム コンピューティング要件は Flink タスクのセットによって実行されます。Flink タスクのセットが複数ある理由は、各サービスがビジネスの観察に応じて異なる指標の計算を必要とし、これが異なるデータ処理トポロジにも対応するためです。私たちは、ユーザーの同じコンピューティング ニーズを抽象化するために最善を尽くしていますが、Flink のリアルタイム コンピューティング タスク開発モデルとリアルタイム コンピューティング フレームワークの制限により、これらの観察指標コンピューティング タスクの設計は十分に普遍的ではありません。メトリクス インジケーターのリアルタイム計算に Flink を使用すると、複数の Flink タスク セットを維持すると、次の問題に直面します。
抽象化されるべき一般的なメトリクス コンピューティング機能は繰り返し構築されており、品質がまちまちであり、蓄積することができません。
処理ロジックはストリーミング タスクのコードにランダムにハードコーディングされており、更新や保守が困難です。
Flink のリリース、拡張、縮小にはタスクを再起動する必要があり、これによりインジケーター出力の遅延、ブレークポイント、エラーが発生します。
Flink プラットフォームは比較的高価であり、社内コストの大部分を占めており、一定のコスト圧力があります。
これらの問題を解決するために、私たちは一連のリアルタイム コンピューティング エンジン、observed-compute (略して OBC) を開発しました。次に、OBC の実装について説明します。
設計目標
プロジェクトの開始時に、OBC によって決定された設計目標は次のとおりでした。
1.メトリクス指標計算の分野で汎用リアルタイム計算エンジンを作成します。このエンジンには次の特性があります。
業界標準に準拠:ストリーム処理タスクの記述言語として PromQL を使用
柔軟なタスク管理と制御:戦略が構成され、コンピューティング タスクがリアルタイムで有効になり、実行計画を手動で介入できます。
計算リンクトレーサビリティ:計算結果のポリシーレベルのトレーサビリティを実現可能
クラウド ネイティブ コンテナ化:エンジン コンテナ化のデプロイメントにより、ダウンタイムなしで動的な拡張と縮小が可能になります。
2. この製品は、観測可能なプラットフォームのすべてのメトリクス指標計算のニーズを満たし、繰り返しの計算タスクを置き換え、コストを削減して効率を向上させ、観測の収集、送信、および計算のリンクを再構築することができます。
現在、リンク トレーサビリティを計算する機能を除いて、他のすべてのエンジン機能が実装されています。OBC は数か月以上オンラインで安定して実行されています. オブザーバブル プラットフォームの中核となる Flink コンピューティング タスクのいくつかのセットが OBC に移行されました. 移行されたタスクにより、オブザーバブルの累積コスト 100 万元が節約されることが期待されています年末までにプラットフォームを完成させます。
エンジンのアーキテクチャ
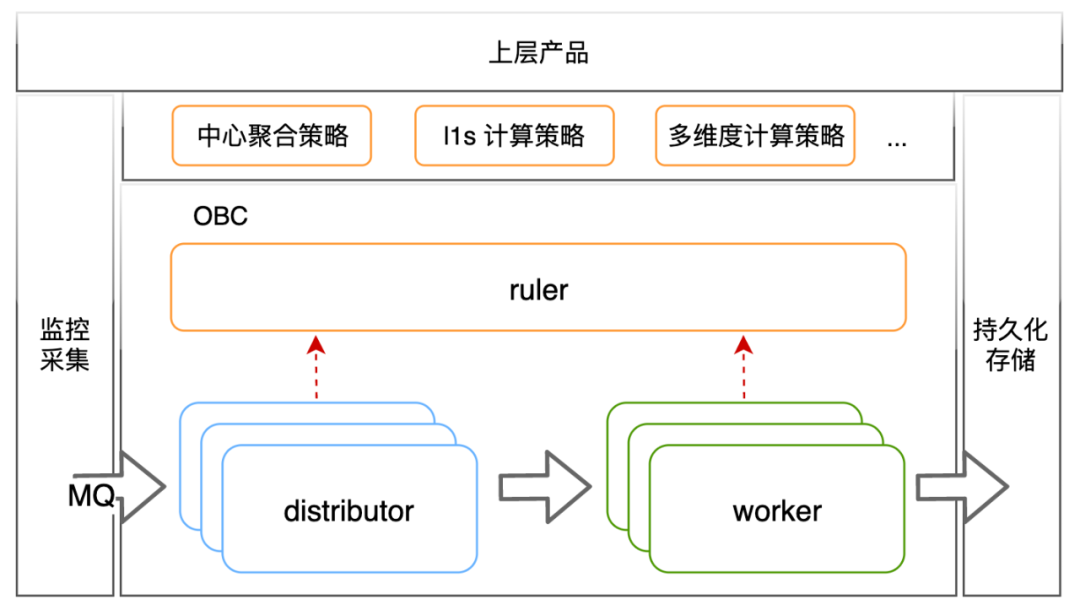
エンジン アーキテクチャは上の図に示されており、3 つのコンポーネントに分かれています: obc-ruler はエンジン内の制御コンポーネントであり、エンジン内の他のコンポーネントにサービス登録および検出機能を提供します。また、外部へのアクセスも担当します。コンピューティング戦略と実行計画の制御。obc-distributor は、メトリクス メッセージ キューからメトリクス インジケーターを取り込み、計算戦略と照合し、戦略の実行計画に従ってデータを obc-worker に転送します。obc-worker は、実際に計算を担当するエンジン内のコンポーネントであり、実行計画に従ってインジケーターの計算を完了し、計算結果を外部の永続ストレージに配信する役割を果たします。
ユーザビリティに関するディスカッション
各コンポーネントのコア ロジックを詳しく紹介する前に、まず、ユーザビリティに関する私たちの考えと妥協点、およびユーザビリティの目標を達成するために導入されたいくつかの概念を紹介します。この部分の説明は、各コンポーネントのコア ロジックを理解するのに役立ちます。
ユーザビリティの考え方
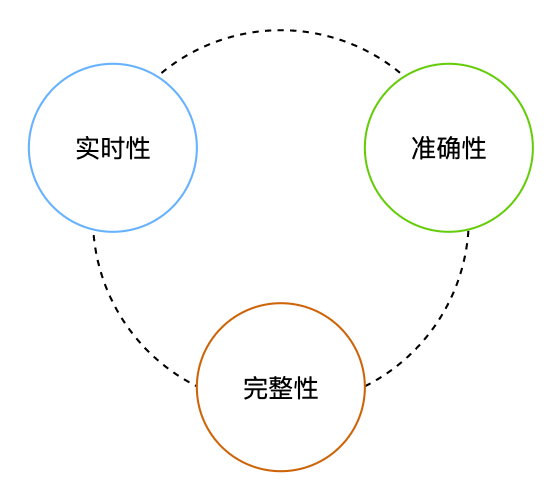
リアルタイム コンピューティング シナリオにおけるデータ可用性の要件は、リアルタイム要件と精度要件に分けられます。これらの要件には、低遅延で高精度のデータが必要です。精度とは、データが良好で損失がないことを意味します。データが良好であるという要件を私は精度要件と呼び、データが失われていないという要件を完全性要件と呼んでいます。
ビジネス観測データについては、最終的な出力結果の観点から、上記の 3 つの観点から可用性を議論することも適しています。
リアルタイム: データがストレージに入るまでに大きな遅延があってはならない
精度: ストレージにドロップされたデータは、システムの状態を正確に反映する必要があります。
整合性: ストレージにドロップされたデータには、欠落ポイントやブレークポイントがあってはなりません。
単純な観測データの処理プロセスは、収集 => 保存と単純化できます。そのようなプロセスで収集されるものは収集されるものであり、データの正確性について議論する必要はありません。リアルタイム性と整合性という 2 つの要件のうち、実装の複雑さとシステムの運用オーバーヘッドを軽減するために、リアルタイム性を確保し、整合性を犠牲にするのが一般的なアプローチです。
観測データがリアルタイム計算に参加するシナリオは通常のシナリオよりも複雑になるため、データの精度についてはさらに議論する必要があります。obc-worker に到達する同じ計算ウィンドウ内のデータの遅延分布が前提条件として、コレクションエンドから obc-worker までの少なくとも 1 回のセマンティクスが保証されている必要があり、正確な結果を保証するために、データ重複排除のロジックと計算ウィンドウの整合性が obc-worker に実装されている必要があります。私たちの場合、設計と実装のコストと、精度を確保するための追加のコンピューティング リソースのコストの両方が若干高くなります。また、Flink を使用してメトリクス指標を計算する場合、最終的な出力データが正確であることは保証できません。そのため、OBC はソリューションの設計においても必要な妥協を行っています。計算結果については、計算結果を保証するために最善を尽くしますが、ポイントを破る (完全性) だけであり、間違い (精度) はありませんが、生成されたデータが正確であることを保証するものではありません。
ユーザビリティデザイン
まず、カットオーバー時間と呼ばれる概念を導入します。カットオーバーの意味は切り替えです。この概念は m3aggregator から借用したものです。OBC では、カットオーバー時刻は、構成の実際の有効時刻として構成が変更される時刻よりも遅い時刻に設定されるため、obc-distributor と obc-worker は変更前の同じ構成に同期する機会が複数あります。設定が実際に有効になります。ここでカットオーバー時間の概念が最初に導入されるのは、obc-distributor がデータを obc-worker に転送するときに、obc-worker によって形成されたハッシュ リング上でどのワーカー インスタンスを転送する必要があるかを選択するためです。構成されたハッシュが変更されると、問題が発生します。変更がすぐに有効になると、obc-distributor はハッシュ変更のプロセスが順次であると認識し、ディストリビューター クラスター内で有効になるワーカー ハッシュ リングが不整合になります。構成はカットオーバーによって構成されます。実際の有効時間を遅らせると、ディストリビュータが構成の変更を感知するための時間がより多くなる可能性があります。より具体的なユーザビリティデザインは以下のポイントに分かれます。
1. Obc ワーカーがクラッシュ、ドリフト、および再起動するため、エラー ポイントはなく、いくつかの曲線で最大 3 つのブレークポイントが発生します。
ワーカーとルーラーの間にはハートビート同期メカニズムがあり、3 秒ごとに同期されます。
ディストリビュータは、ルーラーからのワーカー ハッシュを 3 秒の呼び出し頻度で同期します。
ルーラーは、ワーカーのステータスに基づいてハッシュ リングのバージョン更新ロジックを完了します。カットオーバーはバージョンであり、履歴バージョンは最大 10 分間保持されます。
ワーカーの死亡に対するルーラーの判断: ハートビートが 8 秒間更新されていないか、ルーラーが積極的にインターフェイスを呼び出して自身からログアウトします。
ハッシュリングの伝播遅延時間: 8秒

2. obc-distributor のドリフトと再起動によって、カーブ ブレークポイントや間違ったポイントが発生することはありません。
obc は社内クラウド プラットフォームにデプロイされており、社内クラウド プラットフォームにはグレースフル リスタートのためのいくつかのサポート機能があり、コンテナのドリフトとリスタートはビジネス プロセスに SIGTERM シグナルを送信します。ディストリビュータはこの信号をリッスンし、信号を受信した後に 2 つのことを行います。
MQ からの消費をやめる
メトリクス データ ポイント、キャッシュ内のまだワーカーに送信されていないデータ ポイントは、できるだけ早く送信されます。
3. Obc ディストリビュータがパニックを起こし、それが配置されている物理ノードでブレークポイントやエラーが発生する可能性があります。
この場合、ディストリビュータは事後対応ができず、メモリにキャッシュされワーカーに送信されていないデータの一部が失われ、計算結果に誤差が生じます。
この状況がユーザーに与える影響は何ですか? 私たちの古いメトリクス計算リンクobserve-agent (収集終了) => mq => router => kafka => flink. リンク内のルーターモジュールはディストリビューターと同様の作業の一部を引き受けます. これも同じ問題を抱えており、実行されていますユーザーの認識は明らかではないようです
4. インジケーター出力の精度要件は、60 秒以内に戦略を更新するときにブレークポイントやエラーがないことです。
クラスタでポリシーの更新が有効になった後、ポリシーが同期されていないと短期エラーが発生します。この問題を解決するために、カットオーバー時間の概念もポリシーに導入されています。カットオーバー時間は 60 秒に調整されています。 。
各コンポーネントの紹介
obc-定規
次の図に示すように、ルーラー モジュールには、サービスの登録/検出とポリシー管理という 2 つの主要な機能があります。
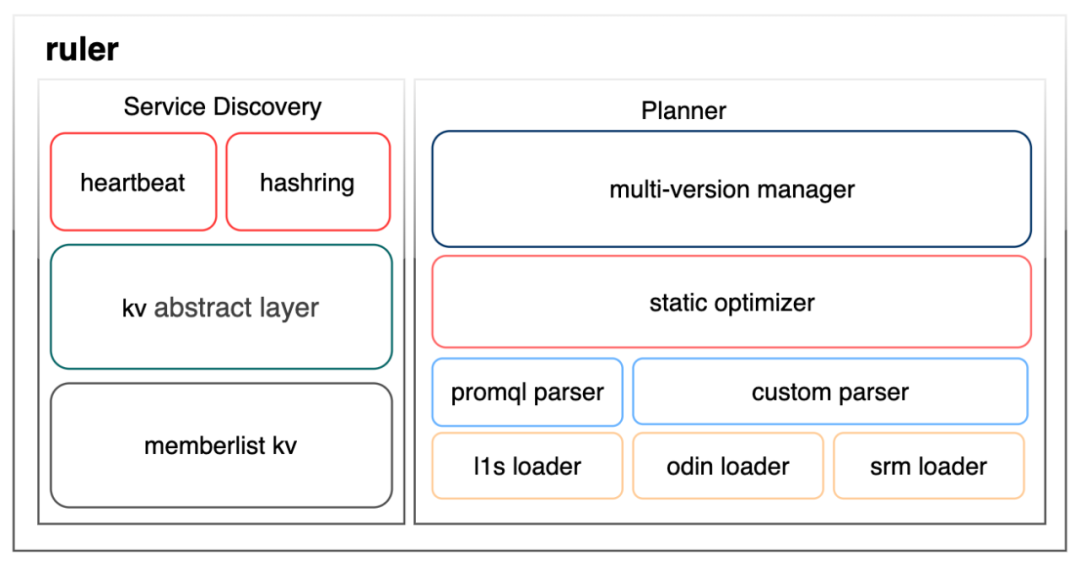
サービス登録/検出機能の構築は 3 つの層に分かれており、kv 抽象層とメンバーリスト kv 層では、サードパーティ製のライブラリ grafana/dskit を使用します。このライブラリは、kv 抽象層の下で consul や etcd などのさまざまな kv をサポートしています。ゴシッププロトコルによって提供されるデータ同期機能に基づいて、メンバーリスト kv を使用して最終的な整合性 kv を構築することを選択しました。その理由は、オブザーバブル自体が外部コンポーネントに依存することを避けるために、外部依存関係を可能な限り削減する必要があるからです。これらの外部コンポーネントは、安定性を確保するために当社の監視機能に依存しています。これが循環依存の問題です。上位層のハートビートとハッシュリングの直接の説明は、kv ストアに登録された 2 つのキーと、それらをサポートする競合マージ ロジックです。ハートビート キーには、ワーカーのアドレス、登録時間、最新のハートビート時間、ワーカーに割り当てられたハッシュ トークンなどの情報が保存され、ハッシュ キーには、カットオーバーの複数のバージョンのワーカー ハッシュ リングが保存されます。
ポリシー管理モジュールは 4 つのレイヤーに分かれています。最下位レイヤーは、外部ポリシー ソースから構成をロードする役割を担うさまざまなローダーです。図には、当社の最もコアな製品のいくつかのコンピューティング ポリシー ローダーがリストされています。既存のコンピューティング タスクについては、OBC を移行するためにパーサーをカスタマイズしてコンピューティング戦略を変換します。新しいコンピューティング タスクについては、コンピューティング要件を記述し、PromQL パーサー分析を使用するために PromQL を統合して使用する必要があります。パーサーによって生成される実行計画はツリーであり、オプティマイザーは実行計画に対して何らかの最適化を行いますが、実際には、現時点ではいくつかの演算子の単純なマージにすぎません。マルチバージョン マネージャーは、ポリシー更新の全体的なスケジュールを設定し、異常なポリシーを禁止します。
obc-ディストリビュータ
ディストリビュータ モジュールの中核となる機能は、計算戦略とメトリクス データ ポイントの転送を関連付けることです。
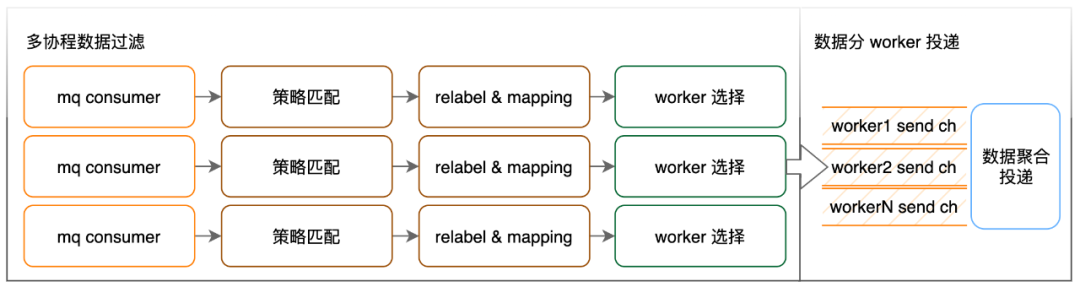
ここでの戦略マッチングで行われる作業は、指定されたラベルに従ってデータ ポイントをフィルター処理し、フィルター処理されたデータ ポイントに対応する戦略の ID でラベルを付けることです。当社の大規模なオンライン OBC コンピューティング クラスターの 1 つは、入力量がほぼ 1,000w/s で、有効なコンピューティング ポリシーの数は 1.2w です。確かにデータ量が多すぎるため、スクリーニング効率を向上させるために、有効なポリシーにいくつかの制限を加えました: ポリシー スクリーニングは 2 つのラベル、__name__ と __ns__ を含む必要があり、これら 2 つのラベルは通常の一致を使用できません。__name__ はインジケーターの名前で、__ns__ はネームスペースを意味し、インジケーターが報告されるサービス クラスターを表します。これら 2 つのラベルを利用して 2 レベルのインデックスを構築し、ポリシー照合の効率を向上させます。
ラベルの再設定アクションは、ポリシーの要件に従ってデータ ポイントのラベルを追加/削除/変更することです。設定構文に関しては、説明を統一するために、これらのルールを PromQL 関数に処理し、これらの関数のベクトル パラメーターをセレクターまたはその他の再ラベル関数のみに制限します。マッピング アクションは、他のストリーミング コンピューティングのディメンション テーブル結合に似ており、既存のコンピューティング タスクにアクセスするための妥協の産物であるため、詳細は説明しません。
労働者を選択するプロセス:
データポイントのevent_timeアライメント時間: align_time =event_time -event_time %解像度、ここで解像度は、戦略で指定された予想される出力インジケーターの精度です。
ワーカー ハッシュ リングの選択: align_time を使用して、カットオーバーが align_time を超えない最新のワーカー ハッシュ リングをハッシュ リング リストから検索します。
ワーカー インスタンスの選択: planid + align_time + 指定された一連のラベルの値をキーとして使用してハッシュ値を計算し、そのハッシュ値を使用してワーカー ハッシュ リング内のワーカー インスタンスを見つけます。指定された一連のラベルは、戦略の分析後にルーラーによって生成され、少量のデータの処理を必要とする戦略の場合は通常は空です。
obc-ワーカー
ワーカーのコア機能はメトリクス インジケーターの計算です
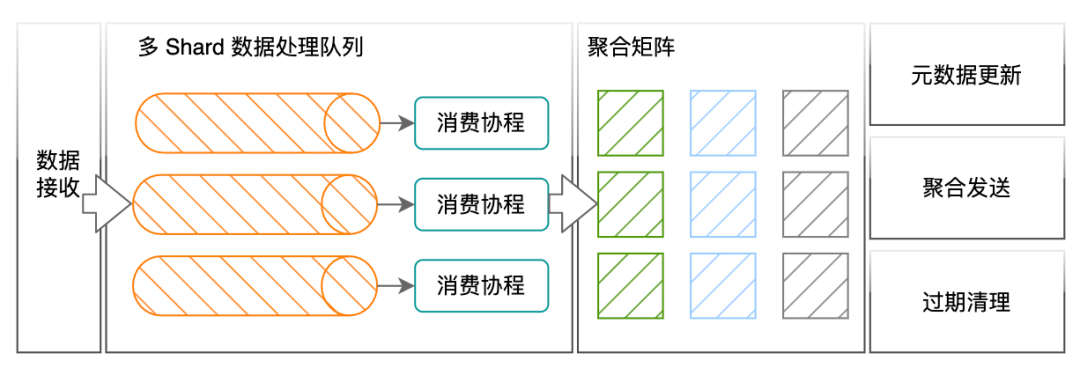
ディストリビューターは、同じポリシー、同じ集計ディメンション、および同じ計算ウィンドウのメトリクス ポイントが同じワーカーに転送されるようにします。ワーカーが受信したメトリクス データ ポイントにはポリシー ID 情報が含まれており、ワーカーはこれを使用してポリシーの内容を検索および計算します。戦略を計算するための最小の論理演算単位はアクションであり、PromQL の関数、二項演算、および集計演算はすべてアクションに変換されます。ワーカーの集計行列では、各アクションの下に、解像度に従って整列された一連の時間ウィンドウがあり、時間ウィンドウ内で、一緒に計算する必要がある一連のデータが同じコンピューティング ユニットに書き込まれます。ワーカー内の最小の物理コンピューティング ユニット。同じ計算ユニットに追加されたデータはキャッシュされず、必要な場合を除いてリアルタイムで計算に使用されます。
わかりにくいかもしれませんが、例として、(呼び出し元, 呼び出し先) (rpc_counter) による合計の計算ルールを取り上げます。 rpc_counter 本来のインジケーターのフィルタリングはディストリビュータ内で完了し、(呼び出し元) による合計のアクションは実行されます。 、呼び出し先) はアクションとして処理されます。アクションのタイプは集計操作です。集計タイプは合計です。集計後のデータ出力の次元は呼び出し元と呼び出し先です。データ ポイントを処理するとき、ワーカーはデータを呼び出し元と呼び出し先の 2 つのラベルの同じ値。ポイントは同じ集約ユニットに送信されます。集約ユニットはポイントを受け取るたびに、sum += point.value などのアクションを実行します。
バイナリ操作や集計操作を処理するときにワーカーが注意を払う必要がある問題の 1 つは、ウィンドウを開く時間の設定です。ウィンドウは、必要なすべてのデータが到着するまでどれくらいの時間待機しますか? この値は、リアルタイム性と精度に直接影響します。インジケータ出力。リンク送信における独自のメトリクスの遅延分布に基づいて、次のデフォルト ポリシーを設定しました。
元のインジケーターのステップ値が 10 以下の場合、ウィンドウの開始時間は 25 秒に設定されます。
元のインジケーターのステップ値が 10 より大きい場合、ウィンドウの開始時間は 2*step + 5 に設定されます。ウィンドウの開始時間が 120 秒より大きい場合、ウィンドウの開始時間は 120 に設定されます。
このパートでは、各コンポーネントの実装を比較的簡単に紹介します。コア プロセスのみを紹介します。パフォーマンスや機能に関して行ったトレードオフや最適化の多くについては、機会があれば個別に紹介します。
補足内容
皆様の理解を容易にするために、ここにはいくつかの追加コンテンツが追加されています。
計算戦略の例
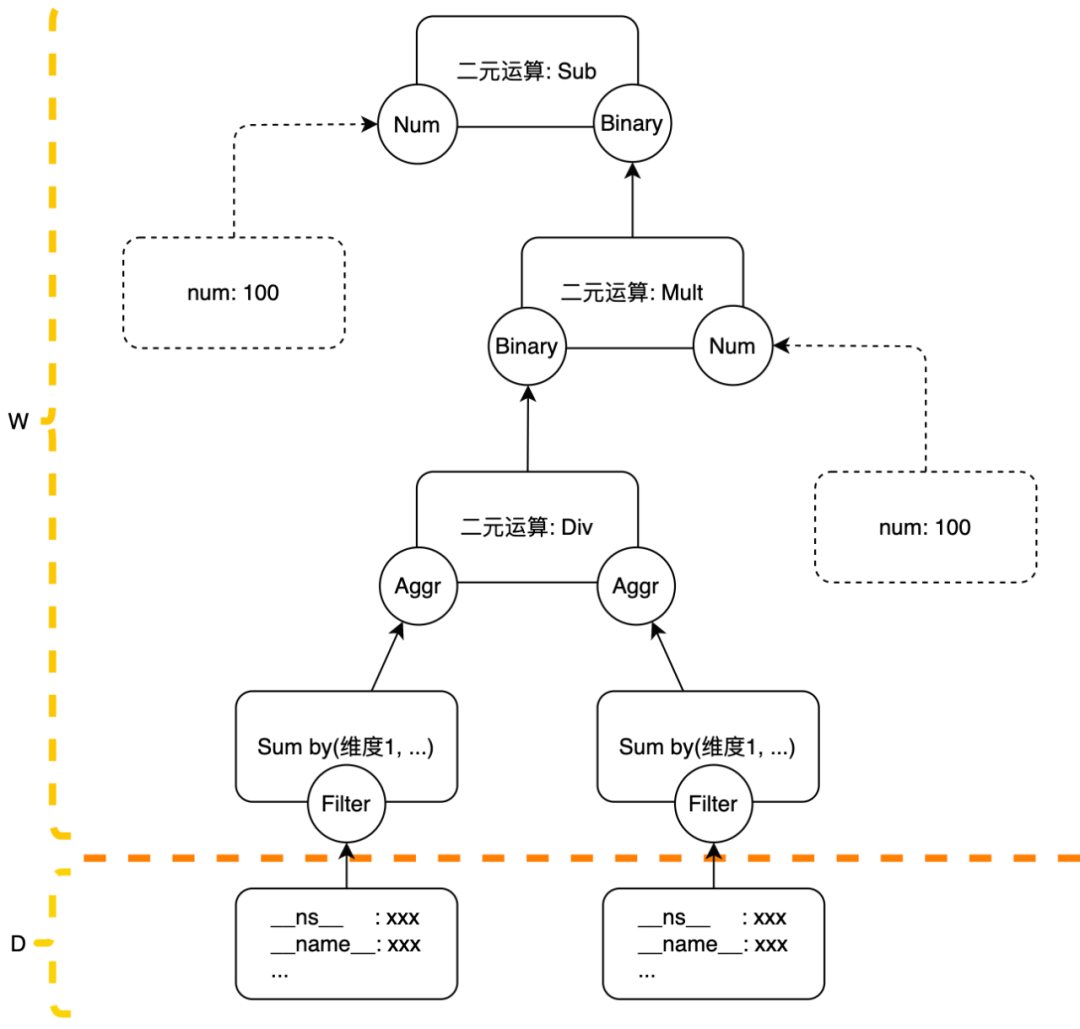
OBC の内部戦略はツリー形式で表現されますが、ツリーの葉ノードはメトリクスのフィルタリング条件または定数である必要があり、葉ノードを定数にすることはできません (このような戦略はイベントドリブンでは意味がありません)メトリクスのフィルタリング この条件はポリシーではフィルタと呼ばれ、フィルタはディストリビュータで実行され、残りのアクションはワーカーで実行されます。ポリシーが特に設定されていない場合、同じウィンドウ内のポリシーに一致するメトリクスは同じワーカーに送信されます。後続のアクションの処理はこのワーカー上で完了します。異なるウィンドウからのデータは異なるワーカーに送信される場合があります。その理由つまり、ワーカー間の負荷分散は、単にポリシーの次元でワーカーを分散させるだけでは実現できないということです。
ここで特に注意すべき点があり、特定のポリシーの 1 つのウィンドウ内のデータ量が 1 人のワーカーで処理するには大きすぎる場合、何らかの集計計算に従ってポリシーを複数のワーカーに分散するための設定を手動で作成します。寸法。分解できない場合や、分解しても一人の労働者では対応できない場合は禁止を選択します。もちろん、計算ポリシーでフィルタリングされたデータは __ns__ ラベルを持つように制限しており、同じサービスのメトリクス データのみを計算に使用できるため、これまでのところ禁止ポリシーが必要な状況には遭遇していません。単一のワーカーが処理できない状況では、ワーカー間でカスケード コンピューティング機能を実装し、大規模なデータ タスクを統合して処理することも選択できます。その後の需要があれば、この機能を現在のアーキテクチャですぐに拡張できます。
PromQLのサポート
OBC は、コンピューティング戦略へのユーザー アクセス方法として PromQL を使用することで、ユーザーの戦略に対する理解とアクセス コストを削減できると考えています。この記事の執筆時点では、PromQL の構文と関数のサポートの完成度は高くありません。その主な理由は、使用されない操作が多く、オペレーター ストックへの戦略的アクセスがあるためです。需要に応じて段階的に実装する予定です。実装には、オフセット修飾子、@ 修飾子、サブクエリなど、リアルタイム計算での実装に適さないいくつかの PromQL 構文もあります。
前回の記事では、ディストリビュータが同じ計算戦略の同じ計算ウィンドウのデータが同じワーカーに転送されるようにすることを紹介しました。irate (http_request_total[10s]) などの操作の前後のウィンドウ内の 2 つのポイントが異なるワーカーに転送される場合、irate を計算するにはどうすればよいですか? もしあなたがそのような疑問を抱いているなら、私が以前に書いたことを注意深く読んで理解させてくれた自分を褒めるべきです。
範囲ベクトル セレクターと範囲ベクトル関数を含む範囲ベクトルは、現在のバージョンの OBC ではサポートされていません。サポートされていない理由は、当面使用できないためです。内部データはすべてゲージであると考えることができます。 Prometheus のタイプ. リクエストの場合、私たちの側のいわゆるカウンター インジケーターは、実際には 10 秒サイクルごとにリクエスト量をカウントします。カウンター データが報告される前に増加 (http_request_total) されたのと同様に、サイクル間のデータは蓄積されません。 [ 10秒])のような操作。もちろん、将来的には範囲ベクトル関連の構文サポートの実装を必ず検討しますが、いくつかの構文制限も設ける予定です。
正確なクラスター粒度リクエストのレイテンシー
Didi Observable Platform には、Prometheus Exporter の収集と PromQL データの取得をサポートする前は、データ型としてのヒストグラムの概念がありませんでした。サービスリクエスト遅延に関しては、収集側で t-digest アルゴリズムを使用して各サービスインスタンスのインターフェース遅延分布を近似し、デフォルトで 99 & 95 & 90 & 50 分位値の遅延データをレポートします。元の情報が不足しているため、クラスター粒度インターフェイスの遅延分位値の比較的正確な計算をユーザーに提供することは不可能であり、代わりに単一マシン粒度の遅延分位値インジケーターの平均値または最大値を使用することしかできません。
この問題をOBCでも解決しました.具体的な方法としては,OBCが収集側と連携し,収集側が遅延分位値指標を報告する際に,インタフェース遅延分布のバケット情報も併せて報告するという方法をとりました。バケット化された情報は永続ストレージに分類されませんが、オンデマンドでのみ OBC に取り込まれます。OBC は、関連する操作を PromQL 集計演算子に拡張します。この演算子の名前はパーセンタイルであり、そのアクションは単一のバケット化された情報をマージすることです。新しい遅延分布を取得するマシン。オンデマンドでこの分布の分位数を生成します。
概要と展望
これまでのところ、OBC は数か月以上にわたってオンラインで安定して実行されており、監視可能なプラットフォームのいくつかのコア メトリクス コンピューティング タスクが OBC に移行され、大幅なコスト上のメリットが達成されています。
その後のプロジェクト反復のアイデアに関しては、ここで核心点の 1 つを紹介します。収集と計算の統合を実現するために、このコンピューティング エンジンのセットに収集エンドを含めたいと考えています。ユーザーのコンピューティング ニーズに合わせて、次のように移動できます。取得端が完了し、取得端で事前計算を行うことができ、可能な限り取得端で事前計算を行うことができます。
計算エンジンによる計算後、元のデータと新たな計算結果を含むさらなる観測データが得られました。このデータは最終的にどこに保存されるのでしょうか? 行ストレージと列ストレージのどちらを選択するか、既存のソリューションを使用するか自己調査するか、大量のデータの問題を解決する方法など、次の記事では Didi での観測データの保存について説明します。
クラウドネイティブナイトトーク
実稼働環境で観察可能な指標の計算ニーズをどのようにサポートしますか? コメント エリアにメッセージを残してください。さらに連絡する必要がある場合は、プライベート メッセージをバックエンドに直接送信することもできます。
著者は最も意味のあるメッセージの 1 つを選択し、10 月 1 日の心配のない旅行を願って、Didi のカスタマイズされたスーツケースを送ります。抽選は9月26日午後9時に行われる。
