Whale Optimization Algorithm (WOA) は、近年出現している群知能最適化アルゴリズムであり、ザトウクジラのバブルネット採餌戦略に基づいて 2016 年にオーストラリアの学者 Mirjalili ら [36] によって開発されました。最大の特徴はザトウクジラの泡網攻撃機構を模したスパイラルです。このアルゴリズムには、獲物を囲む、バブルネット攻撃モード (ローカル検索動作)、およびザトウクジラがランダムに泳いで狩りをする (グローバル検索動作) という 3 つの検索メカニズムが含まれています。比較的単純なアルゴリズム構造と良好な収束のため、軌道計画 [37]、画像セグメンテーション [38]、故障検出 [39] など、多くの分野の最適化問題に適用されて成功しています。
4.1 クジラ最適化アルゴリズムの原理
ザトウクジラはその性質上、水中に丸い泡を吹き付けて水網を作り、獲物をその泡の中に閉じ込めるという非常に賢い狩り方をします。ザトウクジラは水深約15メートルで螺旋状の姿勢で上向きに泳ぎ、大小の泡を多数吐き出し、最後の泡と最初の泡が同時に水面に到達し、円筒状または管状の形状を形成します。バブルネット、これらの網は獲物をしっかりと取り囲み、中央領域に向かって押し込みます。ここで、ザトウクジラは網に集中した獲物をほぼ直立した姿勢で飲み込みます。ザトウクジラの狩猟行動を図 4.1 に示します。
4.2 アルゴリズムの数学モデル
Mirjalili らは、ザトウクジラのバブルネットの狩猟行動にヒントを得て、ザトウクジラの狩猟プロセスを大まかに 3 つの段階に分け、クジラのアルゴリズムの各部分の最適化戦略を形成しました。WOA アルゴリズムには、獲物の探索、獲物の囲い込み、バブルネット攻撃の 3 つの段階が含まれます。
4.2.1 獲物を探すフェーズ
クジラが獲物を取り囲むと、クジラの最適な位置、または集団内のランダムなクジラの位置に向かって泳ぎます。最適化問題に対応する場合、個々のクジラの位置が問題の実行可能な解決策であり、アルゴリズムの各反復の後、現在の反復数で検索された集団内の最適解が全体最適解に最も近いものになります。解決。この段階では、個々のクジラは位置を更新するために集団内の他のクジラの位置情報をランダムに選択します。また、この方法により、アルゴリズムに特定のグローバル最適化機能を持たせることもできます。t 回目の反復で得られたクジラ個体群内のすべての位置情報によると、∣A∣>1 の場合、個体群内の i 番目のクジラがグローバル検索を実行します [41]。数式は次のとおりです。
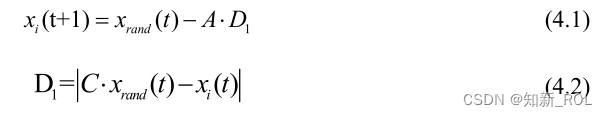
式中、xrand(t)はt世代クジラ群における任意のクジラの位置を表し、D1は選択されたクジラ個体と探索個体との間のユークリッド距離を表し、tは現在の反復番号を表し、xi(t+1) ) は、t+1 世代における i 番目のクジラ個体の位置を表します。A と C は係数ベクトルであり、計算式は次のとおりです。

式中、1r と 2r は区間 [0,1] の乱数で、a はアルゴリズムの収束係数 [42] です。その表現は次のとおりです。
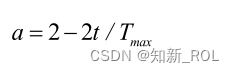
式中の Tmax は最大反復回数です。
4.2.2 周囲の獲物ステージ
∣A∣≦1 のとき、アルゴリズムは獲物を取り囲む段階に入り、このとき個体は集団内で最も優秀なクジラの個体情報を通じて自分の位置を更新します。最初の探索では獲物の位置情報が曖昧であるため、WOA アルゴリズムは、現時点でクジラのグループ内で最も適合度の高い解が獲物の位置であるか、目標の獲物の位置に近づいていると仮定し、他のクジラが位置を更新します。現在の最適解の位置情報をもとに獲物に近づき、徐々に周囲を囲み縮んでいくことで位置を特定します。
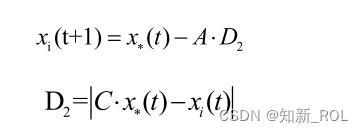
式中、xtはt世代のクジラ群における最適なクジラ個体の位置を表し、D2は最適なクジラ個体と集団のi番目の個体とのユークリッド距離を表す。
4.2.3 バブルネット攻撃ステージ
バブルネット攻撃段階では、ザトウクジラは縮小を続けて獲物の包囲を減らしながら、狩りのために上向きの螺旋運動を行います。その行動モデルによると、WOA アルゴリズムは、包囲の縮小メカニズムとこの時点での螺旋位置の更新を設計しました。ステージ。
(1) 収縮と周囲のメカニズム
このメカニズムは主に式 4.5 の a によって実現されます。a は反復回数が増加するにつれて 2 から 0 まで直線的に減少します [43]. A は [a, a] の範囲の乱数であり、a が減少するにつれてその変動範囲は減少します。アルゴリズム反復の初期段階では検索がより多く行われますが、中期および後期段階ではローカル検索のみが実行されます。収縮周囲機構では、探索された個体の位置は、元の位置と最適な個体位置との間の領域にある。2 次元問題の収縮とエンベロープのメカニズムを図 4.2 に示します。これは、2 次元問題の解空間における (X, Y) から (X*, Y*) までの可能な位置を表しています。
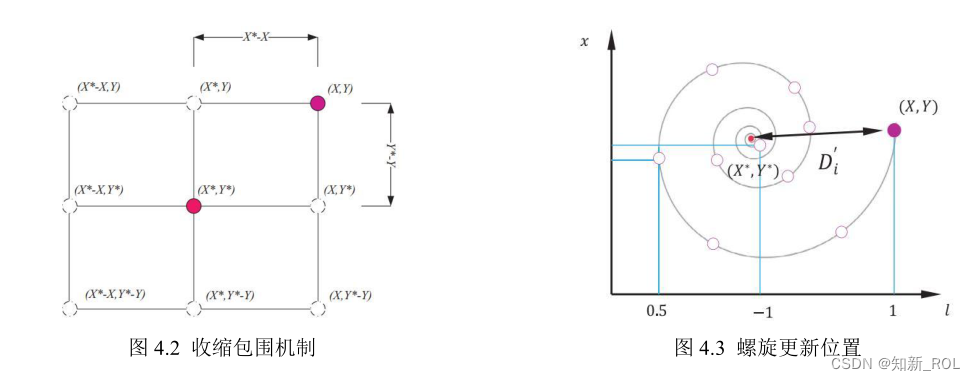
泡網攻撃を行うクジラの行動特性から、泡を吐き出すと同時に上向きに螺旋を描きますが、クジラと獲物の間には螺旋方程式が成立します。螺旋位置更新方法を図 4.3 に示します。数学モデルは次のように表現されます。
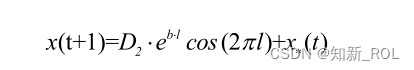
式中、b はスパイラル方程式の定数係数で値は 1、D2 は最適なクジラ個体と探索個体間のユークリッド距離を表し、l は区間 [-1,1] の乱数です。
包囲縮小とバブルネット攻撃を同時に行うクジラの狩猟行動をシミュレートするために、位置更新方法を選択するランダム戦略が設計されています。ランダム確率 p ≥ 0.5 の場合、クジラはバブルネットスパイラル内で位置を更新し、p < 0.5 の場合、クジラは現在の最適な個体の位置情報に基づいて位置を更新します。常に目標に近づく反復過程において、|A|は減少し続け、|A|=0でアルゴリズムの反復は終了し、最後の反復で求められた最適個別位置情報が理論上の最適値に対応する実現可能解となる。数学では次のように説明されます。
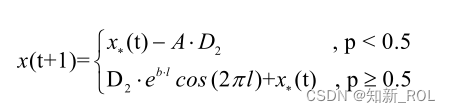
4.3 混合戦略ベースのクジラ最適化アルゴリズム (MSWOA)
クジラ最適化アルゴリズムは現在広く使用されていますが、解の精度が不十分、収束速度が遅い、反復期間の後半で局所最適から飛び出す操作がないなどのいくつかの欠点がまだあります。したがって、上記の問題に応えて、本論文では混合戦略クジラ最適化アルゴリズム (Mixed Strategy Whale Optimizaition Algorithm、MSWOA) を提案します。まず、ケント マッピングを使用して母集団を初期化し、初期解が解空間内に均等に分布するようにし、反復の初期段階で優れた解に遭遇する可能性を高めます。次に、線形関数を置き換えるために動的双子グループ収束係数が構築されます。元のアルゴリズムに収束係数を追加しながら、グローバル検索とローカル検索の能力のバランスをとるために慣性重みに自動適応を追加し、最後に適応エリート突然変異戦略を導入して、局所最適から飛び出すアルゴリズムの能力を向上させます。改良されたアルゴリズムのパフォーマンスを検証するために、一定数の典型的なテスト関数が選択され、非常に成熟したアプリケーションのアルゴリズムと多次元で比較されます。
4.3.1 ケントカオスマップに基づく集団の初期化
(1) ロジスティックマッピングとケントマッピング
最適化の分野では、カオス マッピングは擬似乱数発生器を置き換えて、0 から 1 までのカオス数を生成できます。多数の研究と実験により、カオス シーケンスを使用してアルゴリズムを改善すると、多くの場合、擬似乱数よりも優れた結果が得られることが示されています [44]。メタヒューリスティック アルゴリズムの分野では、多くの学者がカオス システムを導入してアルゴリズムを改良し、アルゴリズム内の変数の分布のエルゴード性を高め、アルゴリズムの収束を高速化しました。それらの中で最もよく引用され、効果的なのはロジスティック マッピングです。ロジスティック カオス マッピングは、カオス システムにおいて非常に古典的で広く研究されている動的システムです [45]。同時に、多くの既存のカオス最適化アルゴリズムは、ロジスティック マッピングを使用して初期化母集団を生成します。ロジスティック写像のシステム方程式:
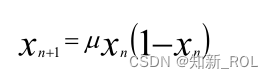
式中の u は制御パラメータで、値の範囲は 0 ~ 4 です。

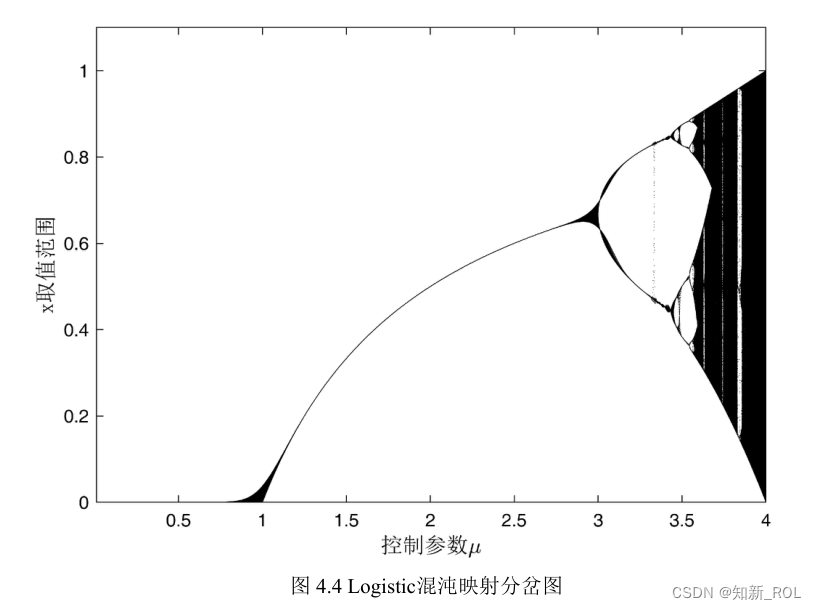
ロジスティックマッピングに対するμの値の影響を明確に示すために、図 4.5 に示すように、μ を 2.5 および 4 に設定したときに生成される対応するシーケンスの特定の状況を取得します
。
動的システムの分岐およびカオス運動特性を研究する場合、リアプノフ指数はシステムの動的特性を測定するための非常に重要な定量的指標であり、位相空間内の隣接する軌道間のシステムの収束または発散の平均比を表します。
インデックスは次のように計算されます。
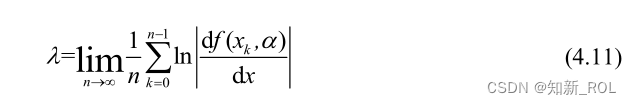

計算によると、ロジスティック マップでは、μ=4 の場合、このマップのリアプノフ指数は最大となり、その値は約 0.6931 になります。ロジティック マッピングのリアプノフ指数プロットを図 4.6 に示します。
メタヒューリスティックアルゴリズムの母集団初期化の改善では、カオスマッピングを通じて母集団のより優れた多様性の初期位置を取得したいため、マッピングのエルゴーディシティにも焦点を当てる必要があり、エルゴーディシティは確率密度をマッピングすることで決定できます。生成されたシーケンスを反映します。ロジスティック写像の確率密度を図 4.7 に示します。
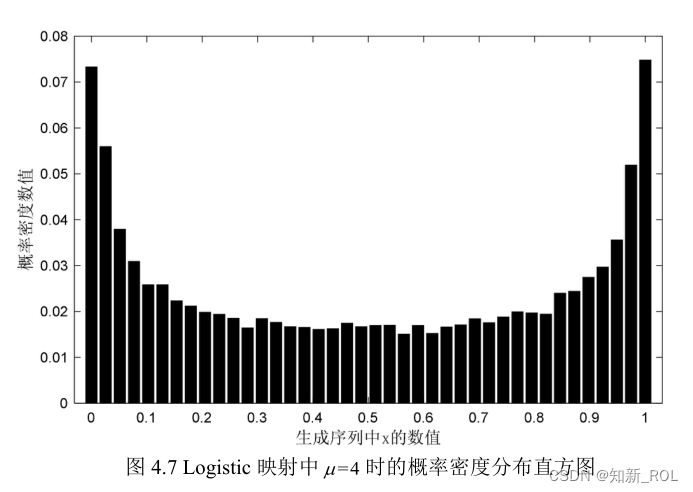
図 4.7 からわかるように、ロジスティック写像の確率密度分布は中央で緩やかで、両側の端で確率密度が急激に増加するため、ロジスティック写像の走査均一性は悪くなります。ロジスティック マッピングと同様に、ケント マッピングにもトポロジカル共役の特性があるため、ケント マッピングは群知能アルゴリズムにおける集団初期化の改善にも適しています。
ケントマップのシステム方程式:
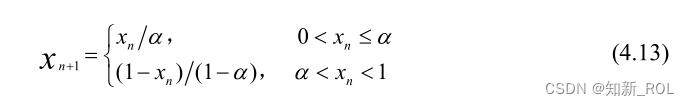

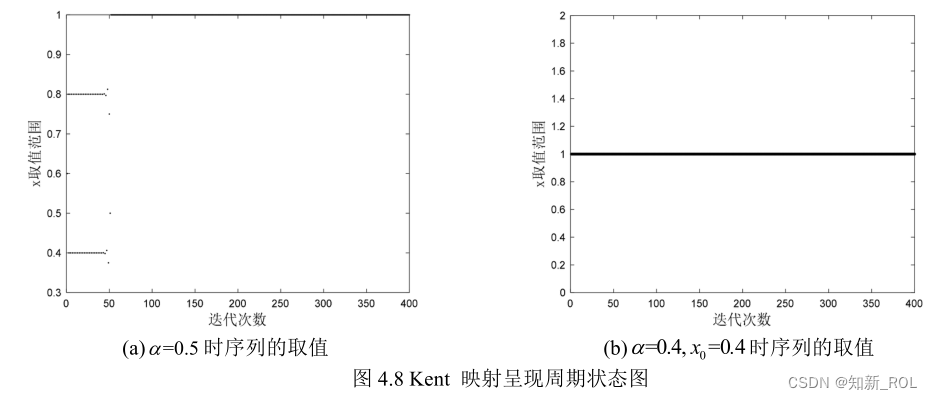

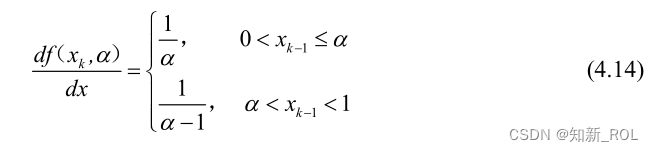 計算によると、ケント マッピング制御パラメーター =0.489 の場合、リアプノフ指数は最大となり、数値は 0.6934 になります。ケント マップのリアプノフ指数プロットを図 4.10 に示します。
計算によると、ケント マッピング制御パラメーター =0.489 の場合、リアプノフ指数は最大となり、数値は 0.6934 になります。ケント マップのリアプノフ指数プロットを図 4.10 に示します。
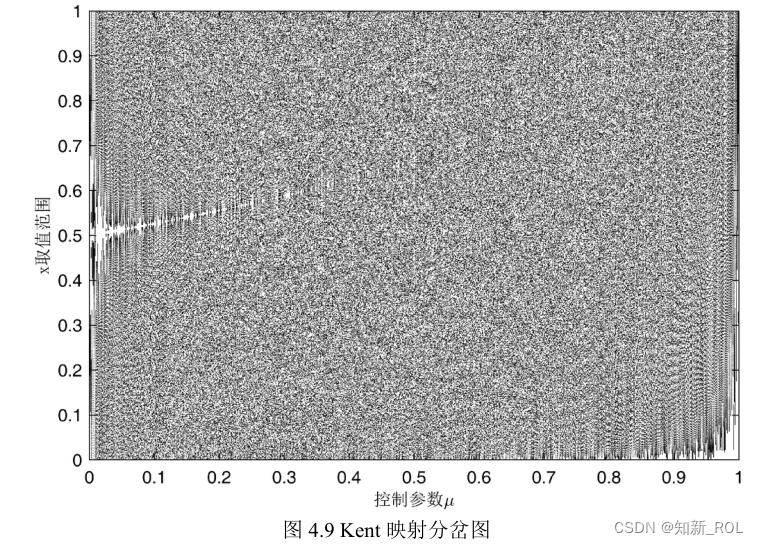
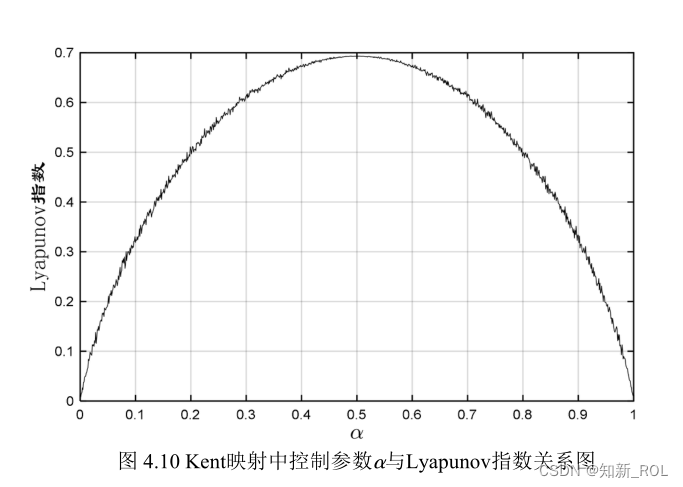
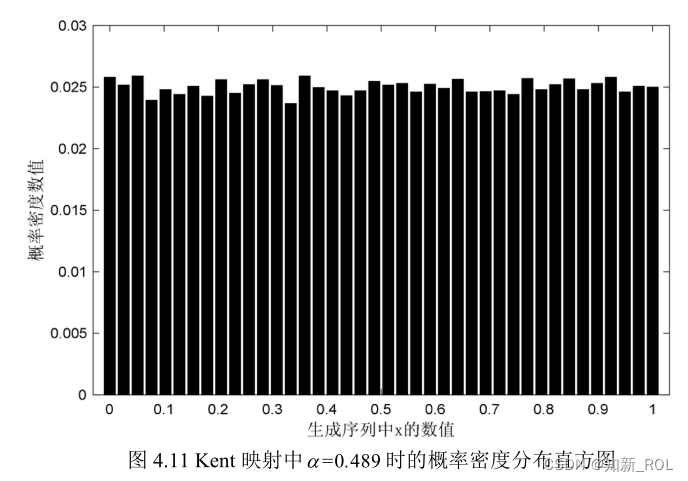
図 4.11 に示すように、ケント マップ内の最良のカオスに対応する制御パラメーター、つまり最大リアプノフ指数に対応する制御パラメーターを選択し、カオス系列を反復生成して確率密度マップを取得します。
(2) 母集団の初期化の改善

 4.3.2 動的双子グループ収束係数
4.3.2 動的双子グループ収束係数
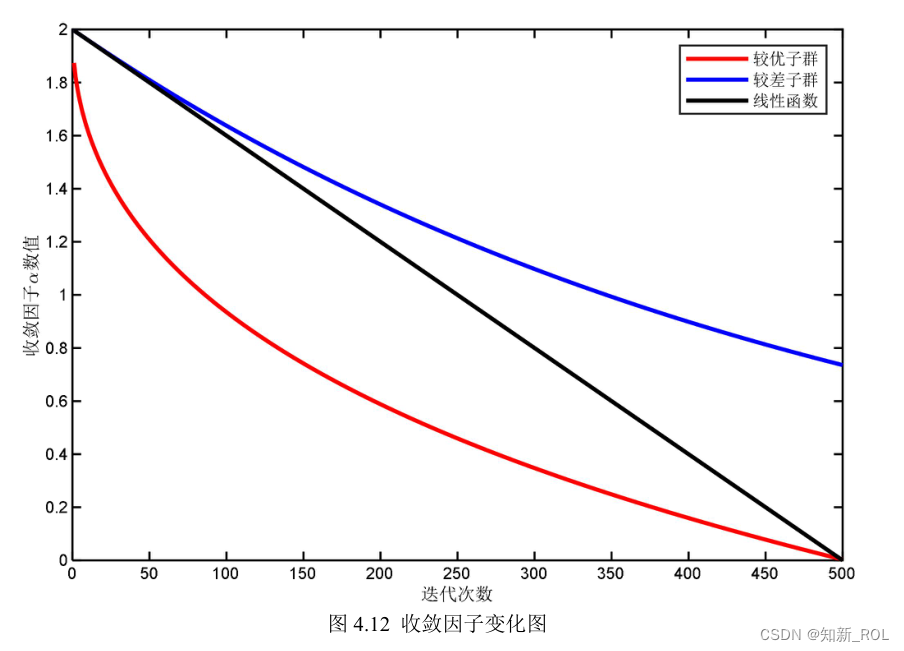
クジラ最適化アルゴリズムでは、位置情報を更新するときに個人がグローバル探索を行うかローカル開発を行うかは主にパラメータ A に影響され、A は主に a によって決定され、反復回数が増加するにつれて徐々に減少します。このような変更により、アルゴリズムの開発能力と人口の多様性が大幅に低下します。アルゴリズムの反復プロセス中、大域的な最適解は通常、局所的な最適解に近いため、母集団内でより高い適応度値を持つ個人に依存するアルゴリズムは、局所的な探索をより適切に実行でき、適応度の低い個人に依存します。値を大きくすると、アルゴリズムはより適切なグローバル検索を実行できるため、集団の進化の程度は遅れている個体によって大きく影響されます。動的双子グループ戦略 [49] と組み合わせて、この論文は、クジラ最適化アルゴリズムに適した動的双子グループ収束係数を提案します。母集団内の現在の個体と最良の個体および最悪の個体とのユークリッド距離をそれぞれ Dbest および Dworst として定義し、Dbest≦(Dworst/4) を基準として、個体を位置で幾何中心に分割します。幾何学的な中心としての現代の最適なクジラ個体の位置を中心とするより良いサブグループ、そうでない場合、個体は現代の最悪のクジラ個体の位置を中心とするより悪いサブグループに分割されます。2 つのサブグループの特性に従って、ローカル検索能力とグローバル検索能力のバランスをとるために、異なる非線形収束係数が採用されます。良好なサブグループの収束係数 a1 と不良サブグループの収束係数 a2 は次のとおりです。
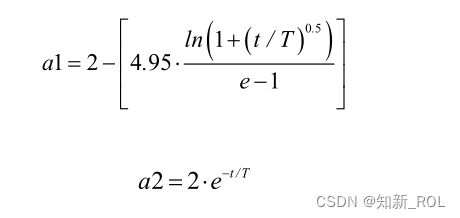
より良いサブグループの場合、現在の反復で得られた最適な個体の位置に近いため、できるだけ早く縮小包囲メカニズムに入り、現在の最適な個体に素早く近づく必要があるため、a1 は初期の反復で急速に減少するはずです。アルゴリズムが局所的な最適値に陥るのを防ぐために、a1 はゆっくりと減少できるようにする必要があります。不良サブグループについては、現在の反復で得られた最適な個々の位置から遠く離れているため、より良い値をできるだけ早く見つけられるようにするには、それがより大きな値内にあることを確認する必要があります。グローバル検索は範囲内で実行されるため、a2 はゆっくりと減らす必要があります。後の反復では、a2 を維持します。 a2 の値を大きくすると、設定された反復回数内で最適化結果が収束しない場合でも、後の段階で母集団がより大きな値を達成できるようになります。最適解を求めるステップ長探索。元のアルゴリズムにおける収束係数と改良後に追加された動的ツイングループ収束係数の反復回数による変化を
図 4.12に示します。
4.3.3 適応エリート不均一突然変異 (AENM)
クジラ最適化アルゴリズムの母集団が進化すると、各粒子の探索ポテンシャルは異なりますが、有利な粒子のポテンシャルを最大限に発揮するためには、アルゴリズムが局所最適化に陥ることを回避し、アルゴリズムの効率をさらに向上させる必要があります [50] 、この論文は、エリート戦略と不均一戦略を組み合わせたものです。突然変異戦略に基づいて、突然変異コンポーネントを動的に調整するための新しい適応オペレーターも導入されており、より良い適合値とより悪い適合値を持つ一部の粒子に、より多くの進化の機会を与えます。突然変異操作を通じて新しい粒子が得られた場合、有利な点が見つかった場合、それは集団内の元の選択された個体と置き換えられます。本稿では、エリート戦略と適応動的演算子を統合したこの不均一変異法[51]を「適応エリート不均一変異戦略(AENM、Adaptive Elite non-uniformmutation Strategy)」と呼ぶ。
エリート戦略では、選択されるエリート粒子の割合を決定することが問題を解決するために非常に重要です。一方では、この割合が大きすぎると、進化の過程が進むにつれて個体群の多様性は大幅に減少しますが、他方では、いくつかの理論的分析では、最終収束の前に個体群探索の全体的な最適位置は常に次の位置にあることが示されています。既知のいくつかの位置 候補解の間を行き来します [50]。そこで、本アルゴリズムでは、集団内のgbestのみをエリート粒子とし、その位置情報に基づいて、適応演算により不均一変異に必要な適応変異オペレータを計算する。
AENM 変異操作では、まず変異シード xm と変異異常 C が適応的に生成され、これら 2 つを組み合わせて適応変異オペレーターが生成され、適応変異オペレーターと不均一な突然変異コンポーネント。このうち、xm は選択した個体からエリート粒子までのユークリッド距離 r と反復回数 t により総合的に決まり、式 1.17 と式 1.18 により、各次元における pbest から gbest までの距離が計算できます。距離が小さいほどグループ間の類似度が大きくなり、距離が小さいほどグループ間の類似度が大きくなり、式 1.19、つまり適合度標準偏差 st_d の異なる値に従って、対応する変動異常 C が適応的に計算されます。を取得し、式 1.20 演算子 F(xm) に従って適応突然変異を生成し、式 1.21 および 1.22 に従って特定の実突然変異量を取得し、突然変異ビット gbest* を取得します。 f(gbest*) よりも大きい場合、母集団内の gbest は gbest* replace になります。同時に、アルゴリズムの最適化プロセスを高速化する必要性を考慮して、母集団内のより良い粒子の 20% と悪い粒子の 20% が突然変異操作のために選択されました。AENM 突然変異では、各次元間の距離の計算式は次のとおりです。
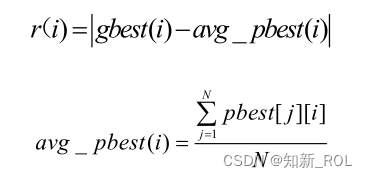
式中、r(i) は集団内の突然変異操作のために選択された N 個の個体、つまり N pbest の各次元における平均 avg_pbest(i) から gbest(i) までの距離を表し、gbest(i) は反復における最適値 粒子の i 次元の位置情報; pbest[j][i] は、母集団内の j 番目の粒子の i 次元の位置情報です。AENM 変異における変異シードの計算式は次のとおりです。
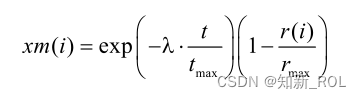
式では、i=1,2,3….D、 は値 10 の定数、rmax は rmax の各次元間の最大距離です。AENM 突然変異における適応突然変異オペレーターの計算式は次のとおりです。

AENM 変異における適応変異異常の計算式は次のとおりです。
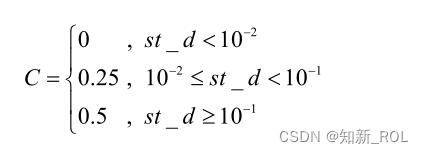


4.3.4 適応慣性重量
Shi らは、PSO アルゴリズムに慣性重み係数 w を初めて導入し、比較的理想的な結果を達成しました。その後の多くの研究でも、アルゴリズムのグローバル検索機能とローカル検索機能のバランスを取る上で w が重要であることが証明されました。
慣性重みを導入する場合、WOA アルゴリズムの初期段階では、一般に個人の適応度値が低く、位置が最適値から離れていると考えられます。このとき、母集団は全体の解を探索するのにより適しています。宇宙空間ではより高い慣性重みが必要となり、後期では慣性重みが必要となるため、個体群は適応度の高い個体に集中するが、このとき慣性重みが低いと個体群の発育能力が制限されるそして局所最適に陥りやすいのです。したがって、適応動的慣性重み係数を設計する基本的な考え方は、アルゴリズム進化の初期段階では、できるだけ早くより良い領域に到達するために解空間を包括的に探索する必要があり、後の反復段階では、慣性重量の計算式は次のとおりです。

