
皆さんこんにちは、イハンです!
2 日前、インターフェイス パラメーターの問題のため、フロントエンド エンジニアと意見の相違がありましたが、要件は非常に単純でした。
数値タイプに従ってデータをクエリします (タイプ値の範囲は 1、2、3)。そのような値がない場合は、すべてのデータがクエリされます。
この要件は非常に一般的です。しかし、「そのような値は存在しない」という問題に関しては、考え方が異なります。
-
私が定義した仕様は、値が無い場合は型を渡さない、バックエンドで取得するのはnullですが、MyBatisの設定ではifタグを通して型に応じて直接nullを判定していますが、そしてそれはすべてに対するクエリになります:
<select id="query" parameterType="java.lang.Integer" resultMap="BaseResultMap"> select <include refid="Base_Column_List" /> from order_info where 1 = 1 <if test="type != null"> AND TYPE = #{type,jdbcType=INTEGER} </if> </select> -
フロントエンド エンジニアが意味するのは、値がない場合はデフォルト値を渡すということです。数値型のデフォルト値は 0 であり、バックエンドは型が 0 であるかどうかに応じてすべてをクエリする必要があります。 ;
したがって、MyBatis の型は 0 より大きいと判断する必要があります。
<if test="type != null and type > 0"> AND TYPE = #{type,jdbcType=INTEGER} </if>
確かにフロントエンドに従ってこれを行うことは可能ですが、0 自体が特定の値であり、type の値の範囲に準拠していないため、この記述は説得力がありません。コントローラー層でのパラメーターの検証は強制終了される必要があります。ある日、需要調整により0も特定の型で表現されるようになり、ここのコードを調整する必要があり、すべてのクエリと新しく追加された0の型のクエリが混乱し、フロントエンドの表示にも影響が出ます。 ;
0 オブジェクトと null オブジェクトの間には、性質上依然として大きな違いがあります。
それぞれが自分の意見を持っているという状況の中で、私は技術交流グループの偉い人たちと簡単にコミュニケーションを取りましたが、私のしつこいせいで他の人に影響を与えたくなかったのです。
ほとんどの偉い人のやっていることは、私の考えと一致しています。最終的に、フロントエンドは私の要件に従って調整されました。
この問題の根本原因は依然として数値型のデフォルト値にあります。さらに、いくつかの関連する問題については過去数日間グループ内で何度か議論されてきたため、ここで要約します。
Alibaba Java Development Manual にはそのような仕様があり、これは今日話している問題にも関連しています。

- [必須] すべての POJO クラス属性はラップされたデータ型を使用する必要があります。
- [必須] RPC メソッドの戻り値とパラメーターはラップされたデータ型を使用する必要があります。
- [推奨] すべてのローカル変数に基本データ型を使用します。
最新の Alibaba Java 開発マニュアル (黄山版) が 2022 年 2 月 3 日にリリースされました。必要な友達は WeChat (mbb2100) を追加して私に問い合わせることができます。
詳細な例を使用して、アリババの開発マニュアルになぜそのような制約があるのかを説明しましょう。
Javaの基本型とラッパークラスの関係
まず、Java の基本データ型に対応するラッパー クラスと基本型のデフォルト値を理解する必要があります。
ラッパークラスがインスタンス化されていないことを前提として、デフォルト値は
null
| 基本タイプ | 包装 | バイト数 | 桁数 | 最小値 | 最大値 | 基本型のデフォルト値 |
|---|---|---|---|---|---|---|
| バイト | バイト | 1 | 8 | -2^7(-128) | 2^7 - 1(127) | (バイト)0 |
| 短い | 短い | 2 | 16 | -2^15 | 2^15 - 1 | (短い)0 |
| 整数 | 整数 | 4 | 32 | -2^31 | 2^31 - 1 | 0 |
| 長さ | 長さ | 8 | 64 | -2^63 | 2^63 - 1 | 0L |
| 浮く | 浮く | 4 | 32 | 1.4E - 4 (2^-149) | 3.4028235E38(2^128 - 1) | 0.0f |
| ダブル | ダブル | 8 | 64 | 4.9E - 324(2^-1074) | 1.7976931348623157E308(2^1024-1) | 0.0d |
| 文字 | キャラクター | 2 | 16 | \u0000 | \uFFFF | '/uoooo'(null) |
| ブール値 | ブール値 | 1 | 8 | 0(偽) | 1(真) | 間違い |
POJO クラス、RPC メソッド、戻り値ではラッパー クラスの使用が強制される
POJO クラス、RPC メソッドの戻り値およびパラメーターでは、ラッパー クラスを使用することが必須です。基本的なデータ型を使用する場合、インスタンス化されたオブジェクトはデフォルト値に初期化されます。値が割り当てられていない場合、ユーザーはわかりません。それはデフォルト値によるものなのか、それとも作成者によって設定されたものであり、その後一連の問題を引き起こすことになります。
例えば
-
ユーザーオブジェクト
@Data public class User { /** * 姓名 */ private String name; /** * 年龄 */ private Integer age; /** * 0:女 1:男 */ private byte gender; }age はパッケージング クラスを使用し、gender は性別の基本データ型です (0 は女性を意味し、1 は男性を意味します)
-
インターフェース
/** * 添加用户 * * @param user * @return */ @PostMapping("/add") private User add(@RequestBody User user) { log.info("添加的用户:{}", user); return user; } -
テスト
次の 2 つの方法でパラメータを渡します。
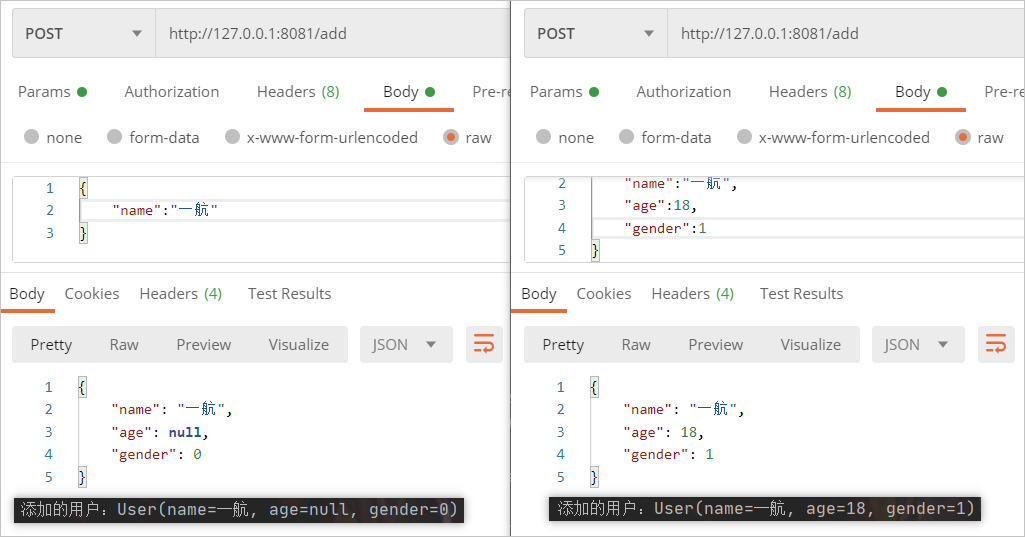
すべてのリクエスト パラメーターを渡す必要がある場合 (右側のパラメーター渡しの例)、属性がラッパー クラスであっても基本データ型であっても問題はありません。
左側のパラメータ渡しメソッドの場合、名前のみを渡す必要があり、その他には値はありません。性別にはバイト基本データ型が使用されます。User オブジェクトの作成後、デフォルト値: 0 が割り当てられます。 ; 0 は女性を意味します。この時点では、理由もなく女の子になった美男子かもしれません。
RPC メソッドと戻り値パラメーターでラッパー クラスの使用が強制される理由は上記と同様です。
ORM リレーショナル マッピング オブジェクトはラッパー クラスを使用する必要があります
NPE(空指针)异常データベース クエリのマッピング オブジェクトが基本的なデータ型を使用している場合、 、对象构建异常、 など数据错误の問題が発生する可能性があります。
引き続き例を見てみましょう。
-
マッピングオブジェクト
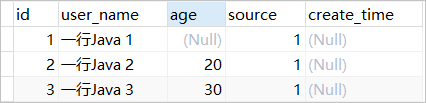
データベーステーブル:
マッピングオブジェクト:
@TableName(value = "user_info") @Data @AllArgsConstructor public class UserInfo implements Serializable { @TableField(exist = false) private static final long serialVersionUID = 1L; /** * 主键ID */ @TableId(value = "id", type = IdType.AUTO) private Integer id; /** * 用户名 */ @TableField(value = "user_name") private String userName; /** * 年龄 */ @TableField(value = "age") private int age; /** * 来源 */ @TableField(value = "source") private Byte source; } -
クエリ方法
@Test void getById() { UserInfo userInfo = userInfoService.getById(1); log.info("根据ID查询用户信息:{}", userInfo); } -
問題 1:オブジェクト構築の例外
マッピング オブジェクトに @AllArgsConstructor (Lombok のアノテーション) が含まれている場合、すべての属性を持つコンストラクターが自動的に生成されます。
public UserInfo(final Integer id, final String userName, final int age, final Byte source) { this.id = id; this.userName = userName; this.age = age; this.source = source; }ID 1 のデータをクエリする場合、age は null であるため、オブジェクトが上記の構築方法でインスタンス化され、null オブジェクトが基本データ型に割り当てられると、例外が発生します
IllegalArgumentException。org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.reflection.ReflectionException: Error instantiating class com.ehang.mysql.mybatis.plus.generator.user.demain.UserInfo with invalid types (Integer,String,int,Byte) or values (1,一行Java 1,null,1). Cause: java.lang.IllegalArgumentException -
問題 2:データエラー
オブジェクトに @AllArgsConstructor アノテーションがなく、@Data アノテーションのみがある場合、すべてのプロパティの Getter メソッドと Setter メソッドが生成され、クエリ結果は各プロパティの Setter メソッドに基づいて割り当てられます。
==> Preparing: SELECT id,user_name,age,source FROM user_info WHERE id=? ==> Parameters: 1(Integer) <== Columns: id, user_name, age, source <== Row: 1, 一行Java 1, null, 1 <== Total: 1 Closing non transactional SqlSession [org.apache.ibatis.session.defaults.DefaultSqlSession@1152bcd] 2022-10-30 12:57:09.308 INFO 504100 --- [ main] com.ehang.mysql.mybatis.plus.GetTest : 根据ID查询用户信息:UserInfo [Hash = 1795612732, id=1, userName=一行Java 1, age=0, source=1, serialVersionUID=1]上記のログから、ID 1 の年齢データベースは null であり、値を割り当てるためにオブジェクトの Setter メソッドは呼び出されないことがわかりますが、オブジェクト内の年齢は int 基本データ型であるため、オブジェクトの作成後に初期値 0 が割り当てられますが、これは最終的にユーザーが取得した UserInfo オブジェクトとデータベース内の結果との間に不整合を引き起こしますが、これは絶対に許可されません。
-
解決
基本データ型をラッパー クラスに置き換えるだけです。
ローカル変数には基本的なデータ型を使用することをお勧めします
[推奨] すべてのローカル変数に基本データ型を使用します。
基本的なデータ型には常に問題があるため、全員がラッパー クラスを使用できれば素晴らしいと思いませんか? しかし、ここでローカル変数に基本的なデータ型を使用することが推奨されるのはなぜでしょうか? 操作が関与すると、基本的なデータ型によってアンボックス化とボックス化の必要がなくなり、操作効率が向上するためです。
-
ボックス化とアンボックス化とは何ですか?
-
パッキング
これは、基本データ型をラッパー型に自動的に変換するためのものであり、原則として、ラッパー クラスの valueOf メソッドを呼び出すことです
Integer.valueOf(1)。Boolean.valueOf(true) -
開梱する
これは、ラッパー型を基本データ型に自動的に変換するためのものであり、原則として、次のようにラッパー クラスの xxxValue メソッド (xxx は型を表します) を呼び出すことです。
public boolean booleanValue() { return value; }
-
例として、先週友人がグループで開梱と梱包の効率について質問したとします。

ソース コードとその要件がないため、この問題を実証するためにここに新しいテスト ケースを作成しました。
-
サンプルコード
public class Main { public static void main(String[] args) { int[] nums = new int[]{ 1000, 1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010}; long start = System.currentTimeMillis(); for (int n = 0; n < 10000000; n++) { for (int i = 0; i < nums.length; i++) { nums[i] = nums[i] + 1; nums[i] = nums[i] + 2; nums[i] = nums[i] + 3; } } System.out.printf("int 遍历10000000的耗时:%sms\n",System.currentTimeMillis()-start); start = System.currentTimeMillis(); Integer[] nums2 = new Integer[]{ 1000, 1001, 1002, 1003, 1004, 1005, 1006, 1007, 1008, 1009, 1010}; for (int n = 0; n < 10000000; n++) { for (int i = 0; i < nums2.length; i++) { nums2[i] = nums2[i] + 1; nums2[i] = nums2[i] + 2; nums2[i] = nums2[i] + 3; } } System.out.printf("Integer 遍历10000000的耗时:%sms\n",System.currentTimeMillis()-start); } }コードのロジックは非常に単純です。それぞれ int 配列と Integer 配列があり、それらの初期値は同じです。トラバースすると、
10000000配列内の各値は個別に+1、+2、そして+3毎回配列に戻されます。 -
試験結果
int 遍历10000000的耗时:194ms Integer 遍历10000000的耗时:1965ms消費時間によると、int 配列の効率は Integer 配列のほぼ 10 倍であることがわかります。
-
原因分析
当然初期値も同じで計算結果も同じなのに、なぜ10倍も効率が悪くなるのでしょうか?
主な理由は、次の 3 行のコードにあります。
nums[i] = nums[i] + 1; nums[i] = nums[i] + 2; nums[i] = nums[i] + 3;int 配列の場合、すべての値はスタックに格納されます。アンパックやボックス化のアクションはありません。値の取得、計算、再割り当てのプロセスは一度に実行され、非常にスムーズです。
ただし、
nums[i] = nums[i] + 1;このコード行が整数配列の場合、計算プロセスは次のようになります。1. 在 nums[i] 中取出 Integer; 2. 将取出的值拆箱;`intValue`方法; 3. 拆箱后的 int 与 1 做相加运算,得到计算结果; 4. 将计算结果的 int 装箱生成 Integer 对象(主要耗时的地方); 5. 将结果放到 nums[i] 中。3 つの操作が実行されるため、各サイクルで上記のステップが 3 回繰り返され、3 回のアンボックス化アクションと 3 回のボックス化アクションが実行され、このプロセスによりパフォーマンスが確実に消費されます。
したがって、ローカル変数では、基本型を合理的に使用すると効率が効果的に向上します。
さて、これを見ればこのアリの制約がよく分かると思います、3連続ありがとうございます…。