1. クラウドデータベース製品
1.1. クラウドデータベースベンダーの概要
クラウド データベース プロバイダーは主に 3 つのカテゴリに分類されます。
① 従来のデータベースベンダー(Teradata、Oracle、IBM DB2、Microsoft SQL Server など)
② データベース市場に関わるクラウドプロバイダー(Amazon、Google、Yahoo!、Alibaba、Baidu、Tencent など)
③ Vertica、LongJump、EnterpriseDBなどの新興ベンダー
市場で一般的なクラウド データベース製品を表 6-3 に示します。
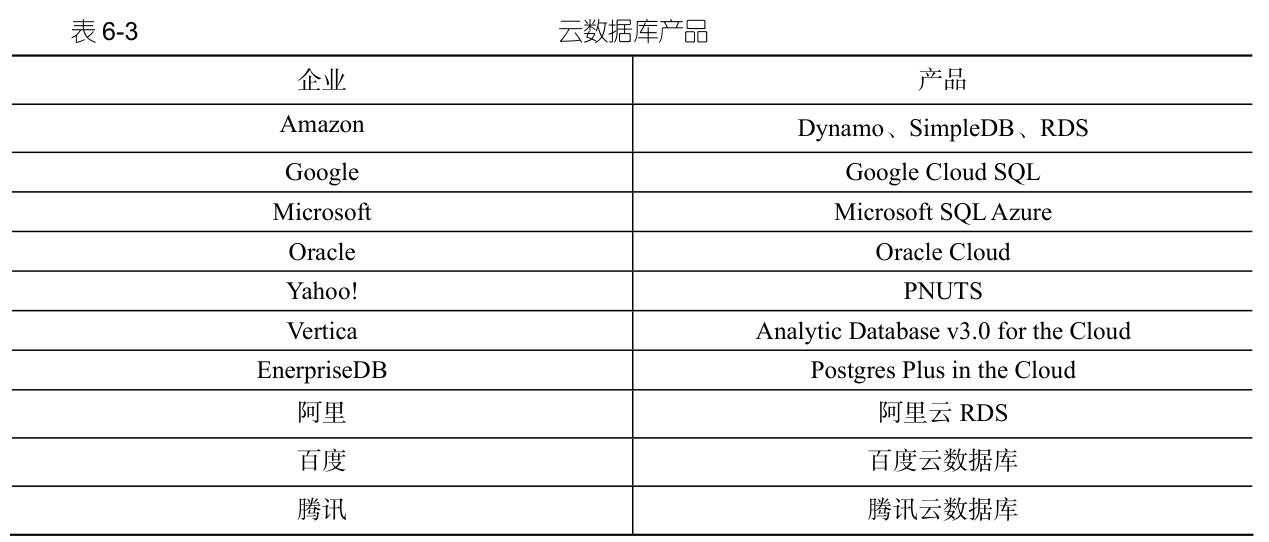
1.2. Amazon のクラウド データベース製品
Amazon はクラウド データベース市場のパイオニアです。Amazon は、よく知られている S3 ストレージ サービスと EC2 コンピューティング サービスに加えて、クラウドベースのデータベース サービス SimpleDB と Dynamo も提供しています。
SimpleDB は、Amazon が開発したクエリ可能な分散データ ストレージ システムであり、AWS (Amazon Web Service) 上の初の NoSQL データベース サービスであり、Amazon の AWS インフラストラクチャの大部分を統合しています。名前が示すように、SimpleDB は単純なデータベースとして使用することを目的としており、その記憶要素 (属性と値) は行の位置を決定する id フィールドによって決定されます。この構造は、ユーザーの基本的な読み取り、書き込み、クエリ機能を満たすことができます。SimpleDB は、データを迅速に保存してアクセスするための使いやすい API を提供します。ただし、SimpleDB はリレーショナル データベースではありません。従来のリレーショナル データベースは行ストレージを使用しますが、SimpleDB は「キー/値」ストレージを使用します。主にリレーショナル データベースを必要としない Web 開発者にサービスを提供します。ただし、SimpleDB には、単一テーブルの制限、不安定なパフォーマンスなど、明らかな欠陥がいくつかあり、結果整合性しかサポートできません。
Dynamo は、SimpleDB やその他の NoSQL データベース設計のアイデアの本質を吸収し、スケーラブルなデータ ストレージとより高度なデータ管理機能を必要とする、より要求の厳しいアプリケーション向けに設計されています。Dynamo は「キー/値」ストレージを使用します。保存されるデータは非構造化データであり、構造化データは認識されません。ユーザーは値の解析を自分で完了する必要があります。Dynamo システムのキーは文字列としてではなく、md5_key (md5 アルゴリズムによる変換後に取得) として保存されるため、キーに基づいてのみアクセスでき、クエリはサポートされません。DynamoDB は、ソリッド ステート ドライブを使用して一定の低レイテンシの読み取りおよび書き込み時間を実現し、より厳密なクエリ モデルを使用しながらも、一貫したパフォーマンスを維持しながら大容量に拡張できるように設計されています。
Amazon RDS (Amazon Relational Database Service) は、Amazon が開発した、クラウド環境でリレーショナル データベースを構築・運用できる Web サービスです (MySQL や Oracle などのデータベースに対応)。ユーザーは、面倒なデータベース管理作業にあまり時間を費やすことなく、アプリケーションおよびビジネスレベルのコンテンツに集中する必要があります。
さらに、Amazon は他のデータベース ベンダーとの良好な協力関係を構築しており、Amazon EC2 アプリケーション ホスティング サービスは、SQL Server、Oracle 11g、MySQL、IBM DB2 などの主流のデータベース プラットフォームや他のデータベース製品を含む、多くの種類のデータベース製品をすでに展開できます。 、EnterpriseDB など。スケーラブルなホスティング環境として、開発者は EC2 環境で独自のデータベース アプリケーションを開発してホストできます。
1.3. Google のクラウド データベース製品
Google Cloud SQL は、Google が立ち上げた MySQL に基づくクラウド データベースです。Cloud SQL を使用する利点は明白です。すべてのトランザクションはクラウドにあり、Google によって管理されます。ユーザーは、設定やエラーのトラブルシューティングを行う必要がなく、信頼するだけで済みます。自分たちの仕事を遂行するために。データは Google の複数のデータセンターに複製されるため、いつでも利用できます。Google は、ユーザーがデータベースをクラウドに出入りできるようにするためのインポートまたはエクスポート サービスも提供します。Google は、非常に使い慣れた MySQL を使用しています。これは、JDBC サポート (Java ベースの App Engine アプリケーション用) と DB-API サポート (Python ベースの App Engine アプリケーション用) を備えた従来の MySQL データベース環境であるため、ほとんどのアプリケーションはこの環境を通過する必要がありません。複数のデバッグで実行でき、データ形式はほとんどの開発者や管理者にとって非常に馴染みのあるものです。Google Cloud SQL のもう 1 つの利点は、Google App Engine との統合です。
1.4. Microsoft のクラウド データベース製品
2008 年 3 月、Microsoft は SQL Data Service (SDS) を通じて SQL Server のリレーショナル データベース機能を提供し、クラウド データベース市場における最初の大手データベース ベンダーとなりました。それ以来、Microsoft は SDS 機能を拡張し、SQL Azure という名前に変更しました。Microsoft の Azure プラットフォームは、ユーザーがネットワークを介してクラウドで SQL Server データベースを作成、クエリ、および使用できるようにする Web サービスのコレクションを提供します。クラウド内の SQL Server サーバーの場所はユーザーには透過的です。これはクラウド コンピューティングにとって重要なマイルストーンです。SQL Azureには以下のような特徴があります。
- ①リレーショナルデータベースです。クラウド データベースの管理、作成、運用のための TSQL (Transact Structured Query Language) の使用をサポートします。
- ②ストアドプロシージャをサポートします。そのデータ型とストアド プロシージャは従来の SQL Server と非常に似ているため、アプリケーションをローカルで開発してからクラウド プラットフォームに展開できます。
- ③ 多数のデータ型をサポートします。ほぼすべての典型的な SQL Server 2008 データ型が含まれています。
- ④クラウド上での取引をサポートします。ローカル トランザクションはサポートされていますが、分散トランザクションはサポートされていません。
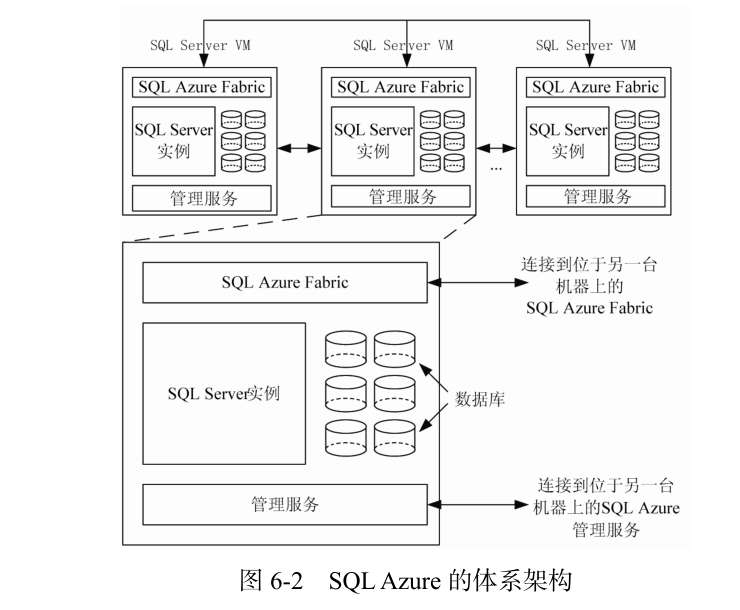
SQL Azure のアーキテクチャには、図 6-2 に示すように、ワークロードの変化に応じて仮想マシンの数を動的に増減できる仮想マシン クラスターが含まれています。各仮想マシン SQL Server VM (仮想マシン) には、リレーショナル モデルにデータを保存するために SQL Server2008 データベース管理システムがインストールされます。通常、データベースは 3 ~ 5 つの SQL Server VM に分散して保存されます。各 SQL Server VM には SQL Azure Fabric と SQL Azure Management Services がインストールされており、後者はデータベースのデータ レプリケーションを担当して、SQL Azure の基本的な高可用性要件を確保します。SQL Azure Fabric とさまざまな SQL Server VM の管理サービスは、相互に監視情報を交換して、サービス全体の監視可能性を確保します。
1.5. その他のクラウドデータベース製品
Yahoo! PNUTS は、Web アプリケーション用に開発された大規模並列の地理的に分散されたデータベース システムであり、Yahoo! クラウド コンピューティング プラットフォームの重要な部分です。Vertica Systems は 2008 年にクラウド データベースをリリースしました。10Gen の Mongo および AppJet の AppJet データベースも、対応するクラウド データベース バージョンを提供します。IBM が投資した EnterpriseDB も、Amazon EC2 上で実行されるクラウド データベースを提供します。LongJump は Salesforce と競合する新しい会社で、オープンソース データベース PostgreSQL をベースにしたクラウド データベース製品を発売しました。Intuit QuickBase は、独自のクラウド データベース ファミリも提供します。MIT によって開発されたリレーショナル クラウドは、負荷の種類を自動的に識別し、同様の種類の負荷を同じデータ ノードに割り当てることができ、グラフベースのデータ分割戦略も採用しており、複雑なトランザクション負荷にも非常に優れています。暗号化されたデータに対する SQL クエリの実行をサポートします。Alibaba Cloud RDS は、Alibaba Cloud が提供するリレーショナル データベース サービスで、物理サーバー上で直接動作するデータベース インスタンスをユーザーにレンタルします。Baidu Cloud Database は、分散リレーショナル データベース サービス (MySQL ベース)、分散非リレーショナル データベース ストレージ サービス (MongoDB ベース)、およびキー/値非リレーショナル データベース サービス (Redis ベース) をサポートできます。
2. クラウドデータベースシステムアーキテクチャ
クラウドデータベース製品によって採用されるシステムアーキテクチャには大きな違いがありますが、以下ではアリババグループの基幹システムデータベースチームが開発したUMP(Unified MySQL Platform)システムを例に挙げます。
2.1. UMPシステムの概要
UMP システムは、低コストで高性能な MySQL クラウド データベース ソリューションであり、主要なモジュールは Erlang 言語で実装されています。開発者はネットワークを介してプラットフォームから MySQL インスタンス リソースを申請し、プラットフォームはデータにアクセスするための単一の入り口を提供します。UMP システムは、さまざまなサーバー リソースをリソース プールに分割し、リソース プールに基づいて MySQL インスタンスにリソースを割り当てます。このシステムには、マスター/スレーブ ホット バックアップ、データ バックアップ、移行、災害復旧、読み取り/書き込み分離、データベースとテーブルのシャーディングなどの一連のサービスをユーザーに透過的に提供するために連携する一連のコンポーネントが含まれています。システムは、データ量やトラフィックが少ないユーザー、中規模のユーザー、データベースやテーブルを分割する必要があるユーザーの 3 つのタイプのユーザーに分類されます。複数の小規模ユーザーが同じMySQLインスタンスを共有したり、中規模ユーザーが1つのMySQLインスタンスを排他的に使用したり、データベースやテーブルを分割する必要があるユーザーの複数のMySQLインスタンスが同じ物理マシンを共有したりすることで、リソースの仮想化を実現します。全体のコストが削減されます。UMP は、「Cgroup を使用して MySQL プロセス リソースを制限する」と「プロキシ サーバー側で QPS (Query Per Second) を制限する」という 2 つの方法を通じて、CPU、メモリ、IO リソースのリソース分離、オンデマンド割り当て、制限を実装します。また、データサービスの提供に影響を与えることなく、ユーザーのビジネスの発展に応じて容量を動的に拡張および縮小することもできます。また、SSL データベース接続、データ アクセス IP ホワイトリスト、ユーザー操作ログ記録、SQL インターセプトなどのテクノロジーを包括的に使用して、ユーザー データのセキュリティを効果的に保護します。
一般に、UMP システム アーキテクチャの設計は次の原則に従います。
- ① システムへの単一の外部入口を維持し、システム内で単一のリソース プールを維持します。
- ② 単一障害点を排除し、サービスの高可用性を確保します。
- ③ システムに優れたスケーラビリティがあり、コンピューティング ノードとストレージ ノードを動的に追加および削除できることを確認します。
- ④ ユーザーに割り当てられるリソースも弾力性と拡張性があり、アプリケーションとデータのセキュリティを確保するためにリソースが互いに分離されていることを確認します。
2.2. UMP システムアーキテクチャ
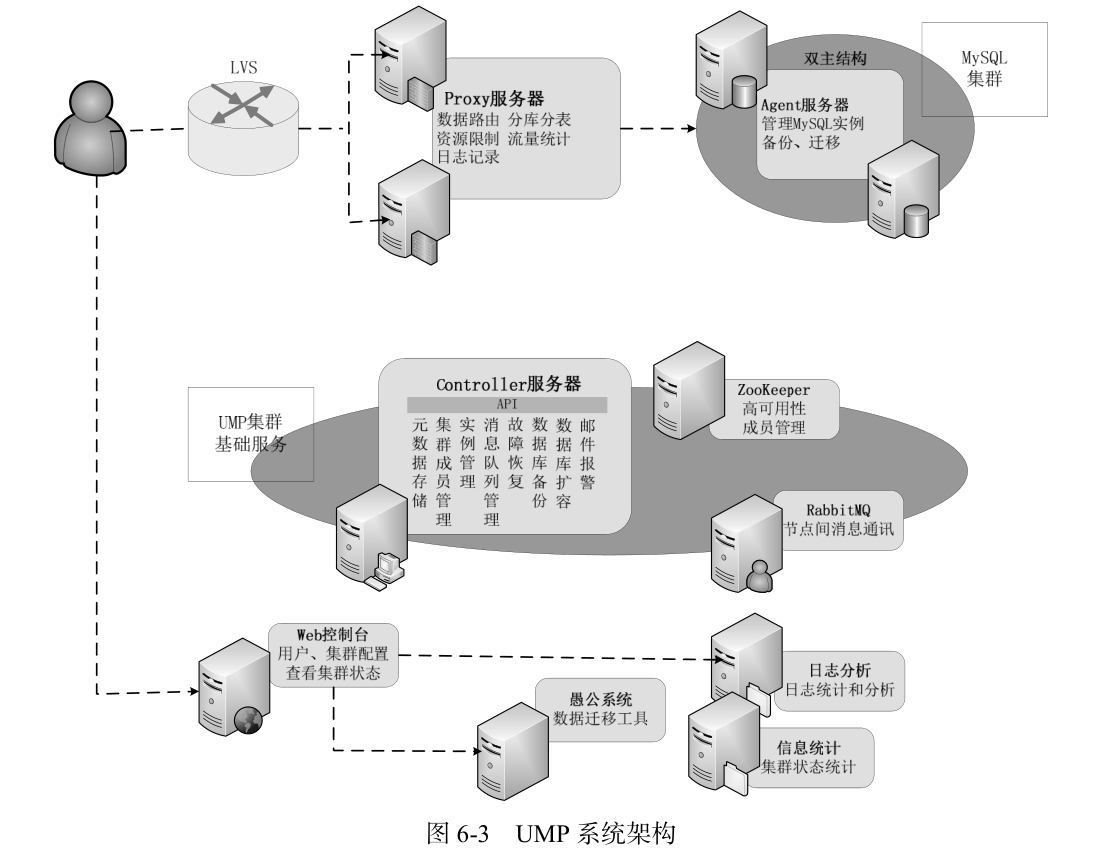
UMP システム アーキテクチャを図 6-3 に示します。UMP システムの役割には、コントローラ サーバー、プロキシ サーバー、エージェント サーバー、Web コンソール、ログ分析サーバー、情報統計サーバー、および Yugong システムが含まれます。依存するオープン ソース コンポーネントには Mnesia が含まれます。 、LVS、RabbitMQ、Zookeeper。
2.2.1. 記憶喪失
Mnesia は、連続動作とソフト リアルタイム特性を必要とする電気通信およびその他の Erlang アプリケーションに適した分散データベース管理システムであり、電気通信アプリケーションを構築するための制御システム プラットフォームである Open Telecom Platform (Open Telecom Platform OTP) の一部です。Erlang は、並列コンピューティングのサポートが組み込まれた構造化された動的型付けプログラミング言語であり、分散型ソフト リアルタイム並列コンピューティング システムの構築に非常に適しています。Erlang で書かれたアプリケーションは通常、実行時に数千の軽量プロセスで構成され、メッセージ パッシングを通じて相互に通信します。Erlang のプロセス間コンテキスト スイッチングは C プログラムよりもはるかに効率的です。Mnesia と Erlang プログラミング言語は密接に連携しており、最大の利点は、データを操作する際に、データベースとプログラミング言語で使用されるデータ形式の違いによって引き起こされるインピーダンス不整合の問題が発生しないことです。Mnesia はトランザクションをサポートし、透過的なデータ シャーディングをサポートし、2 フェーズ ロックを使用して分散トランザクションを実装し、少なくとも 50 ノードまで線形に拡張できます。Mnesia のデータベース スキーマは実行時に動的に再構成でき、テーブルを複数のノードに移行またはコピーしてフォールト トレランスを向上できます。Mnesia のこれらの特性により、クラウド データベースを開発する際の分散データベース サービスの提供に使用されます。
2.2.2.RabbitMQ
RabbitMQ は、Erlang で開発された産業用メッセージ キュー製品 (IBM のメッセージ キュー製品 IBM WEBSPHERE MQ と同様の機能) であり、信頼性の高いメッセージ送信を実現するメッセージ送信ミドルウェアとして使用されます。UMP クラスタ内のさまざまなノード間の通信には特別な接続を確立する必要はなく、キュー メッセージの読み取りと書き込みによって実現されます。
2.2.3. 飼育員
Zookeeper は、分散ロック (統合ネーミング サービス、ステータス同期サービス、クラスター管理、分散アプリケーション構成アイテムの管理など) などの基本サービスを提供する効率的で信頼性の高い共同作業システムであり、分散アプリケーションの構築に使用されます。分散アプリケーションによって実行される調整タスクを軽減します (Zookeeper の動作原理については、関連する書籍またはオンライン資料を参照してください)。UMP システムでは、Zookeeper は主に 3 つの役割を果たします。
(1) グローバル設定サーバーとして。UMPシステムは複数のサーバを稼働させる必要があり、稼働するアプリケーションシステムの一部の設定項目は同一であるため、同じ設定項目を変更したい場合は、複数のサーバで同時に変更する必要があり、面倒なだけではありません。 , しかし、間違いも起こりやすいです。したがって、UMP システムは、この種の構成情報の管理を Zookeeper に完全に任せ、構成情報を Zookeeper のディレクトリ ノードに保存し、変更が必要なすべてのサーバーをこのディレクトリ ノードを監視するように設定します。つまり、ステータスを監視します。構成情報が変更されると、各サーバーは Zookeeper から通知を受け取り、Zookeeper から新しい構成情報を取得します。
(2) 分散ロックを提供します。UMP クラスターには複数のコントローラー サーバーがデプロイされており、システムが正しく動作することを保証するために、一部の操作は特定の時間に 1 台のサーバーでのみ実行でき、同時に実行することはできません。たとえば、MySQL インスタンスに障害が発生した後、マスター/スレーブの切り替えが必要となり、現在障害が発生しているサーバーを別の通常のサーバーに置き換えます。この時点ですべてのコントローラ サーバーが追跡してマスター/スレーブの切り替えプロセスを開始すると、システム全体が混乱状態に入るでしょう。したがって、同時に、クラスター内の複数のコントローラー サーバーから「ゼネラル マネージャー」を選出する必要があり、この「ゼネラル マネージャー」がさまざまなシステム タスクを開始する責任を負います。Zookeeper の分散ロック機能は、クラスターを管理する「ゼネラル マネージャー」の選択に役立ちます。
(3) すべての MySQL インスタンスを監視します。クラスタ内で MySQL インスタンスを実行しているサーバーに障害が発生した場合、それを時間内に検出する必要があり、その後、他の通常のサーバーを使用して障害が発生したサーバーを置き換えることができます。UMP システムは、Zookeeper を使用してすべての MySQL インスタンスを監視します。各 MySQL インスタンスは、起動時に Zookeeper 上に一時ディレクトリ ノードを作成します。MySQL インスタンスがハングすると、この一時ディレクトリ ノードも削除されます。バックグラウンド監視プロセスは、この変更をキャプチャできます。これにより、この MySQL インスタンスが使用できなくなったことを認識できます。
2.2.4.LVS
LVS(Linux Virtual Server)は、Linuxの仮想サーバーであり、仮想サーバークラスタシステムです。LVS クラスターは、IP ロード バランシング テクノロジとコンテンツ ベースのリクエスト分散テクノロジを使用します。スケジューラは、LVS クラスタ システムの唯一のエントリ ポイントです。スケジューラは、非常に優れたスループット レートを備え、実行のためにリクエストをさまざまなサーバに均等に転送します。スケジューラは、サーバの障害を自動的に保護し、サーバのグループを高性能クラスタに形成します。 . 高性能、高可用性の仮想サーバー。サーバー クラスター全体の構造はクライアントに対して透過的であり、クライアントとサーバーのプログラムを変更する必要はありません。UMP システムは、LVS を使用してクラスター内の負荷分散を実現します。
2.2.5. コントローラーサーバー
コントローラーサーバーは、UMP クラスターにさまざまな管理サービスを提供し、クラスターメンバー管理、メタデータストレージ、MySQL インスタンス管理、障害回復、バックアップ、移行、拡張などの機能を実現します。Mnesia 分散データベース サービスのセットは、コントローラー サーバー上で実行されます。コントローラー サーバーには、主にクラスター メンバー、ユーザーの構成およびステータス情報、ユーザー名とバックエンド MySQL インスタンス アドレス (または「ルーティング」と呼ばれる) のマッピング関係などのさまざまなシステム メタデータが保存されます。テーブル」など)他のサーバー コンポーネントがユーザー データを取得する必要がある場合、コントローラー サーバーにリクエストを送信してデータを取得できます。単一障害点を回避し、システムの高可用性を確保するために、複数のコントローラー サーバーが UMP システムに展開され、Zookeeper の分散ロック機能は、システムのスケジューリングと監視を担当する「ゼネラル マネージャー」の選択に役立ちます。さまざまなシステムタスク。
2.2.6.Webコンソール
Web コンソールは、ユーザーにシステム管理インターフェイスを提供します。
2.2.7.プロキシサーバー
プロキシ サーバーは、ユーザーに MySQL データベース サービスへのアクセスを提供します。プロキシ サーバーは、MySQL プロトコルを完全に実装します。ユーザーは、既存の MySQL クライアントを使用してプロキシ サーバーに接続できます。プロキシ サーバーは、ユーザー名を通じてユーザーの認証情報とリソース クォータ制限を取得します。 QPS、IOPS (I/O Per Second)、最大接続数など]、およびバックグラウンド MySQL インスタンスのアドレスを指定すると、ユーザーの SQL クエリ リクエストが対応する MySQL インスタンスに転送されます。データ ルーティングの基本機能に加えて、プロキシ サーバーは、MySQL インスタンスの障害のシールド、読み取りと書き込みの分離、データベースとテーブルのシャーディング、リソースの分離、ユーザー アクセス ログの記録など、多くの重要な機能も実装します。
2.2.8.エージェントサーバー
エージェント サーバーは、MySQL プロセスを実行しているマシンにデプロイされ、各物理マシン上の MySQL インスタンスの管理、マスター/スレーブの切り替え、作成、削除、バックアップ、移行などの操作の実行に使用されます。 MySQL プロセスの統計とスローダウンの分析、クエリ ログ (スロー クエリ ログ) およびバイナリ ログ。
2.2.9.ログ解析サーバー
ログ分析サーバーは、プロキシ サーバーから受信したユーザー アクセス ログを保存および分析し、低速ログのリアルタイム クエリと一定期間にわたる統計レポートをサポートします。
2.2.10.情報統計サーバー
情報統計サーバーでは、RRDtoolを使用してユーザーの接続数、QPS値、MySQLインスタンスのプロセス状況などの統計を定期的に収集しており、統計結果はWebインターフェース上で視覚的に表示することができ、統計結果を利用して柔軟なリソースを実現することもできます。将来の割り当てと自動化、MySQL インスタンスの移行の基礎。
2.2.11.ユゴン系
Yugong システムは、完全レプリケーションと増分レプリケーションのバイナリログ分析を組み合わせたツールで、ダウンタイムなしで動的な拡張、縮小、移行を実現できます。
2.3. UMPシステム機能
UMP システムは大規模なクラスタ上に構築されており、複数のコンポーネントの共同作業を通じて、システム全体が災害復旧、読み取り/書き込み分離、データベースとテーブルのサブデータベース、リソース管理、リソース スケジューリング、リソース分離、およびデータ セキュリティ機能を実現します。
2.3.1. 災害からの回復
クラウド データベースは、ユーザーに常に利用可能なデータベース接続を提供する必要があります。MySQL インスタンスに障害が発生した場合、システムは自動的に障害回復を実行する必要があります。すべての障害処理プロセスはユーザーに対して透過的であり、ユーザーはバックグラウンドで起こっていることをすべて認識することはありません。
災害復旧を実現するために、UMP システムはユーザーごとに 2 つの MySQL インスタンスを作成し、1 つはマスター データベース、もう 1 つはスレーブ データベースであり、2 つの MySQL インスタンスは相互にバックアップ マシンとして設定されます。相互にコピーされます。同時に、プロキシ サーバーは、データがメイン データベースにのみ書き込まれることを保証します。
メイン データベースとスレーブ データベースのステータスは Zookeeper によって維持されます。Zookeeper は各 MySQL インスタンスのステータスをリアルタイムで監視できます。メイン データベースがダウンすると、Zookeeper はすぐにそれを感知してコントローラー サーバーに通知します。コントローラー サーバーはマスター/スレーブ切り替え操作を開始し、ユーザー名とルーティング テーブル内のバックエンド MySQL インスタンス アドレスの間のマッピング関係を変更し、メイン データベースを使用不可としてマークします。メッセージ キュー ミドルウェア RabbitMQ は、名前からバックエンド MySQL インスタンス アドレスへのユーザー マッピング関係を変更するようにすべてのプロキシ サーバーに通知します。この一連の操作の後、マスターとスレーブの切り替えが完了し、通常使用できる新しい MySQL インスタンスにユーザー名が割り当てられます。これはすべて、ユーザー自身には完全に透過的です。
ダウンしたメインデータベースは、回復処理後に再びオンラインになる必要があります。マスター データベースのダウンタイムとリカバリ中に、スレーブ データベースが複数回更新される可能性があります。したがって、マスター データベースが回復すると、スレーブ データベース内のすべての更新がそれ自体にコピーされます。マスター データベースのデータベース ステータスがスレーブ データベースと同じ状態に到達しようとすると、コントローラー サーバーはスレーブ データベースに次のように命令します。更新を停止し、書き込み不可能な状態となり、ユーザーはデータを書き込むことができなくなりますが、このときユーザーは短期間データを書き込めないと感じることがあります。マスター データベースがスレーブ データベースと同じ状態に更新されると、コントローラー サーバーはマスター/スレーブ切り替え操作を開始し、ルーティング テーブルでマスター データベースを使用可能としてマークし、書き込み操作を元に戻すようにプロキシ サーバーに通知します。ユーザーの書き込み操作は引き続き実行でき、その後、スレーブ ライブラリを書き込み可能な状態に変更できます。
2.3.2. 読み取りと書き込みの分離
各ユーザーには 2 つの MySQL インスタンス (マスター データベースとスレーブ データベース) があるため、マスター データベースとスレーブ データベースを最大限に活用して、ユーザーの読み取り操作と書き込み操作を分離し、負荷分散を実現できます。UMP システムは、ユーザーに対して透過的な読み取り/書き込み分離機能を実装しています。機能全体がオンになると、ユーザーに MySQL データベース サービスへのアクセスを提供する役割を担うプロキシ サーバーは、ユーザーが開始した SQL ステートメントを解析します。書き込み操作の場合は直接メイン ライブラリに送信され、読み取り操作の場合はメイン ライブラリとスレーブ ライブラリに送信され、均等に実行されます。ただし、状況が発生する可能性があります。つまり、ユーザーがメイン データベースにデータを書き込んだばかりで、データがスレーブ データベースにコピーされる前に、ユーザーがスレーブ データベースからデータを読み取るため、ユーザーがデータを読み取ること、またはスレーブ データベースからデータを古いバージョンのデータに読み取ることができます。この状況の発生を避けるために、UMP システムは、各ユーザーの書き込み操作後にタイマーを開始します。タイマーがオンになってから 300 ミリ秒以内にユーザーがデータを読み取ると、書き込まれたばかりのデータを読み取る場合でも、他のデータを読み取る場合でも、読み取り操作を実行するためにメイン ライブラリに強制的に配布されます。もちろん、実際のアプリケーションでは、UMP システムでは 300ms の設定値を変更できますが、一般的に、300ms あれば、データがマスター データベースに書き込まれた後、スレーブ データベースに確実にコピーされます。
2.3.3. サブライブラリとサブテーブル
UMP はユーザーに対して透過的なシャード/水平パーティションをサポートしていますが、ユーザーはアカウント作成時にタイプをマルチインスタンスとして指定し、インスタンス数を設定する必要があります。システムはユーザー設定に基づいて MySQL インスタンスの複数のグループを作成します。さらに、ユーザーはデータベースとテーブルをシャーディングするための独自のルールを設定する必要もあります。たとえば、パーティション フィールド、つまりデータベースとテーブルのシャーディングにどのフィールドを使用するか、フィールド内の値をどのように使用するかを決定する必要があります。パーティション フィールドはさまざまな MySQL インスタンスにマップされます。
サブデータベースとサブテーブルを使用する場合、システムは次のようにユーザー クエリを処理します: まず、プロキシ サーバーはユーザー SQL ステートメントを解析し、SQL ステートメントを書き換えて配布するために必要な情報を抽出します。次に、SQL ステートメントを書き換えて複数のクエリを取得します。対応する MySQL インスタンスのサブステートメントをターゲットにし、そのサブステートメントを対応する MySQL インスタンスに配布して実行します。最後に、各 MySQL インスタンスから SQL ステートメントの実行結果を受け取り、それらをマージして最終結果を取得します。
2.3.4. 資源管理
UMP システムでは、データベース サーバー上の CPU、メモリ、ディスクなどの計算リソースをリソース プール機構を使用して管理します。すべての計算リソースはリソース プールに配置され、一元的に割り当てられます。リソース プールは、リソースを割り当てるための基本単位です。 MySQL インスタンスに。クラスター全体のすべてのサーバーは、モデルやコンピューター室などの要素に基づいて複数のリソース プールに分割され、各サーバーは対応するリソース プールに追加されます。管理者は、特定の MySQL インスタンスごとに、アプリケーションがデプロイされるコンピューター ルーム、必要なコンピューティング リソース、システムのリソースなどの要素に基づいて、MySQL インスタンスのメイン データベースとスレーブ データベースが配置されるリソース プールを指定します。インスタンス管理サービスは負荷に基づいて行われ、バランスの原則に基づいてリソース プールから負荷の軽いサーバーが選択され、MySQL インスタンスが作成されます。また、UMP はリソースプール分割に基づいて、各サーバー内の Cgroup を使用してリソースをさらに絞り込むことで、各プロセス グループが使用するリソースの上限を制限し、プロセス グループ間の相互分離を確保します。
2.3.5. リソースのスケジュール設定
UMP システムには、データ量とトラフィックが比較的少ないユーザー、中規模のユーザー、データベースとテーブルを分割する必要があるユーザーの 3 つのタイプのユーザーが存在します。複数の小規模ユーザーが同じ MySQL インスタンスを共有できます。中規模ユーザーの場合、各ユーザーは専用の MySQL インスタンスを持ちます。ユーザーは、必要に応じてメモリ容量とディスク容量を調整でき、より多くのリソースが必要な場合は、空きリソースまたはより高い構成のサーバーに移行できます。サブデータベースとテーブルを持つユーザーは、複数の独立した MySQL インスタンスを持つことになります。これらのインスタンスは、同じ物理マシン上に共存することも、各インスタンスが物理マシンを排他的に占有することもできます。
UMP は、MySQL インスタンスの移行を通じてリソース スケジューリングを実装します。アリババ グループのミドルウェア チームが開発した Yugong システムの助けを借りて、UMP はダウンタイムなしで動的な拡張、縮小、移行を実現できます。
2.3.6.リソースの分離
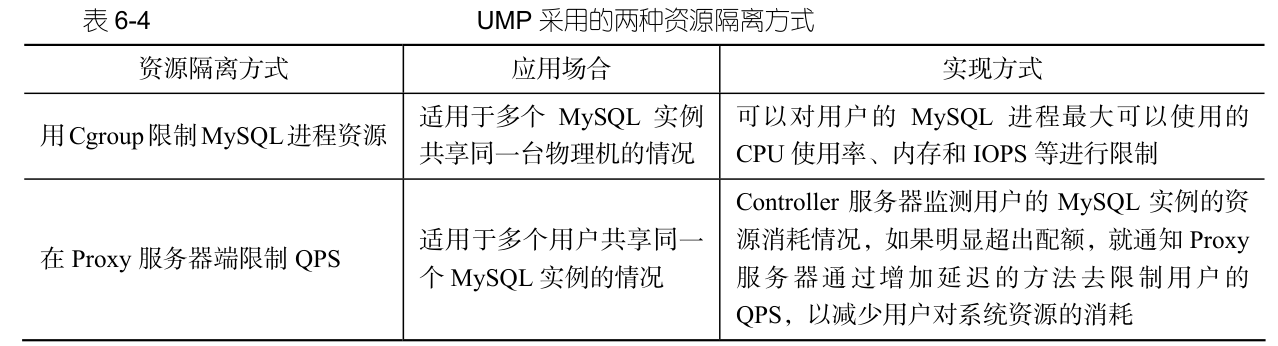
複数のユーザーが同じ MySQL インスタンスを共有する場合、または複数の MySQL インスタンスが同じ物理マシン上に共存する場合、ユーザーのアプリケーションとデータのセキュリティを保護するために、リソースの分離を実装する必要があります。そうしないと、ユーザーによるシステム リソースの過剰な消費が深刻な影響を及ぼします。他のユーザーの操作パフォーマンス。UMP システムでは、表 6-4 に示す 2 つのリソース分離方式が採用されています。
2.3.7.データセキュリティ
データ セキュリティは、クラウド データベース製品、特に企業ユーザーが安心して使用できるようにするための鍵です。データベースには、企業秘密を含む多くのビジネス データが保存されており、ひとたび漏洩すると、企業に損失が発生します。UMP システムは、データのセキュリティを確保するために複数のメカニズムを設計しました。
(1) SSL データベース接続。SSL (Secure Sockets Layer) は、ネットワーク通信のセキュリティとデータの整合性を提供するセキュリティ プロトコルで、トランスポート層でネットワーク接続を暗号化します。プロキシ サーバーは、完全な MySQL クライアント/サーバー プロトコルを実装し、クライアントとの SSL データベース接続を確立できます。
(2) データ アクセス IP ホワイトリスト。クラウドデータベースへのアクセスを許可するIPアドレスを「ホワイトリスト」に登録すると、ホワイトリストに登録されているIPアドレスのみがアクセスでき、それ以外のIPアドレスからのアクセスは拒否されるため、アカウントのセキュリティがより確保されます。
(3) ユーザーの操作ログを記録します。ユーザーの操作記録はすべてログ分析サーバーに記録され、ユーザーの操作記録を確認することで隠れたセキュリティ脆弱性を発見できます。
(4) SQL インターセプト。プロキシ サーバーは、フル テーブル スキャン ステートメント「select *」など、要件に応じてさまざまなタイプの SQL ステートメントをインターセプトできます。