記事ディレクトリ
序文
CRUD が多すぎると、取得されるデータ フィールドとエンティティ クラスの属性が 1 対 1 に対応するというある種の考え方が形成されます。テーブル内のフィールドは常にクラス内の属性に対応しますか? 上記は、フィールドと属性が 1 対 1 に対応する、
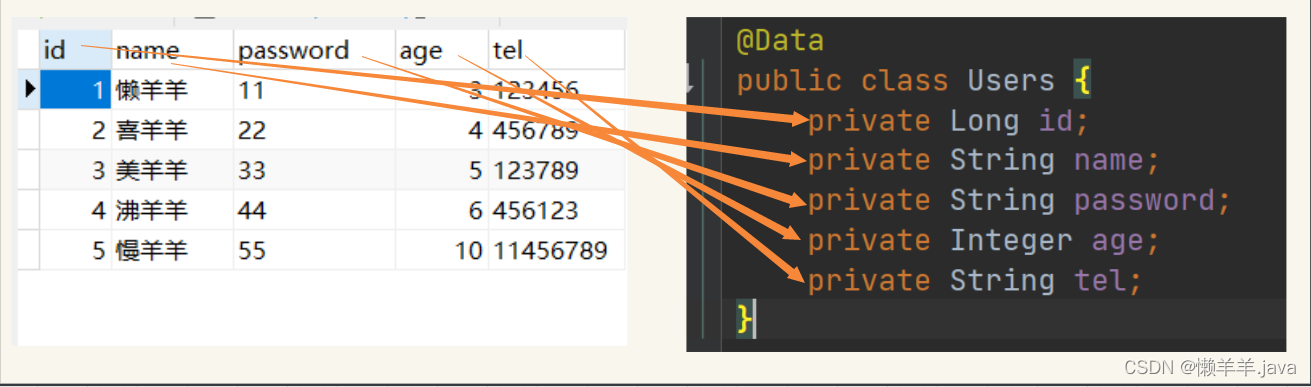
いわゆる理想的な状況です
。最初に考えられる問題を検討してみましょう。
1.フィールドと属性値が異なる
通常のクエリを実行したときにどのような結果が報告されるかを確認するために、エンティティ クラスの属性を変更しました。
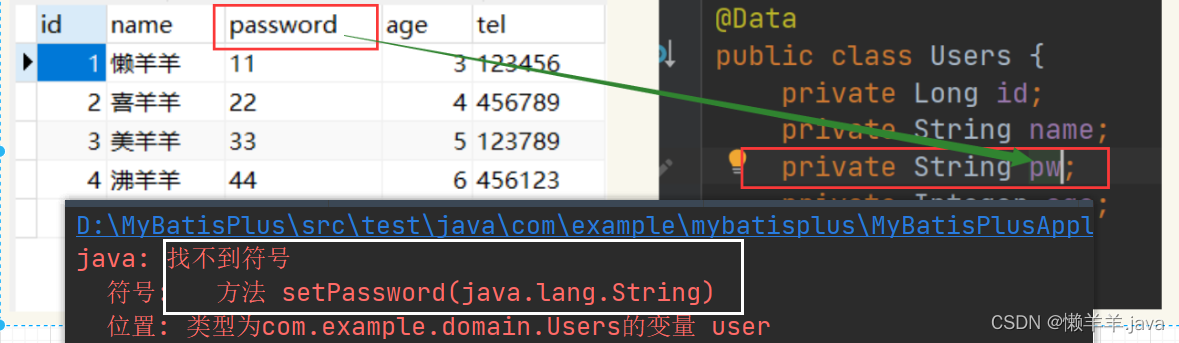
クエリは失敗しました。
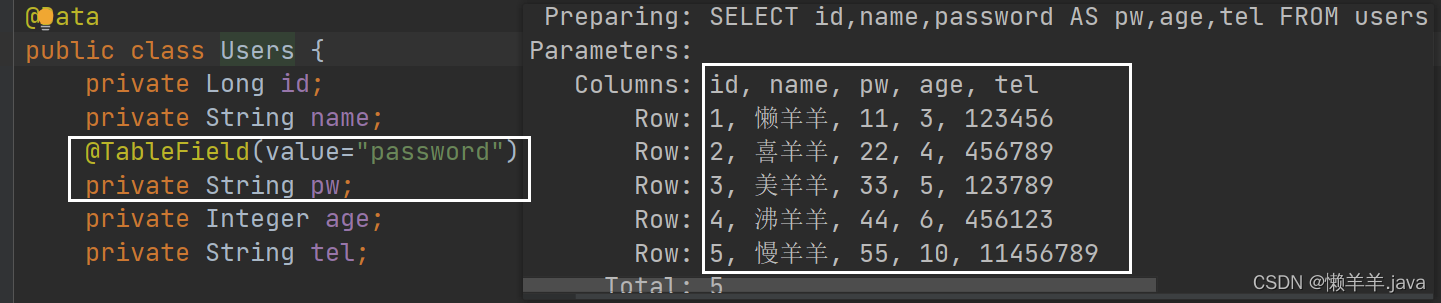
そのため、テーブルのカラム名とモデルクラスの属性名が一致しない場合、データはモデルオブジェクトにカプセル化されないため、どちらか一方が変更を加える必要があります。 MP からは、この問題の解決に役立ちました。MP は、次のように、モデル クラスの属性名とテーブルの列名の間のマッピング関係を実現するために使用できるアノテーション
が提供されました。@TableField@TableField(value = "password")
2. テーブルに存在しない属性
データベース テーブルに存在しないフィールドがエンティティ クラスに表示されると、生成された SQL ステートメントは、選択時にデータベースに存在しないフィールドをクエリします。特定のソリューションでは、引き続き注釈が使用されます。この注釈には、と呼ばれる属性があります。, フィールドがデータベース テーブルに存在するかどうかを設定します。false に設定すると、フィールドは存在しません。SQL ステートメント クエリを生成するときに、フィールドは再度クエリされません。
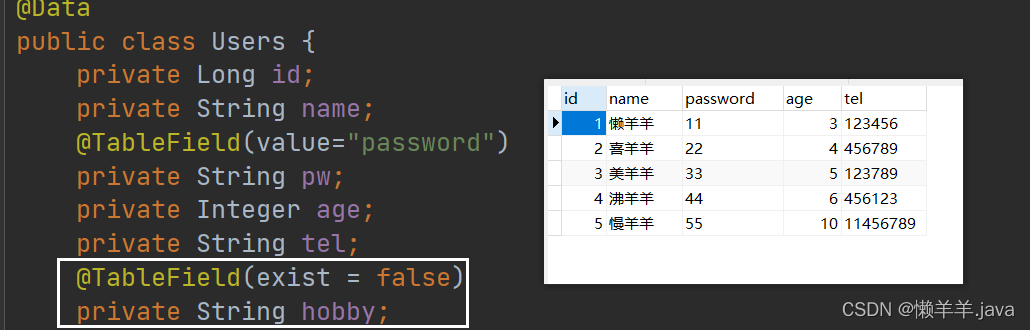
@TableFieldexist
3. テーブルに存在しない属性
操作後、一部の機密データがクエリされ、フロントエンドに返される可能性があります。このとき、デフォルトでクエリを実行しないフィールドを制限する必要があります。常識によれば、パスワードなどの個人情報を一緒にクエリするべきではありません。これらのフィールドを非表示にするにはどうすればよいでしょうか? または @TableField アノテーション経由:
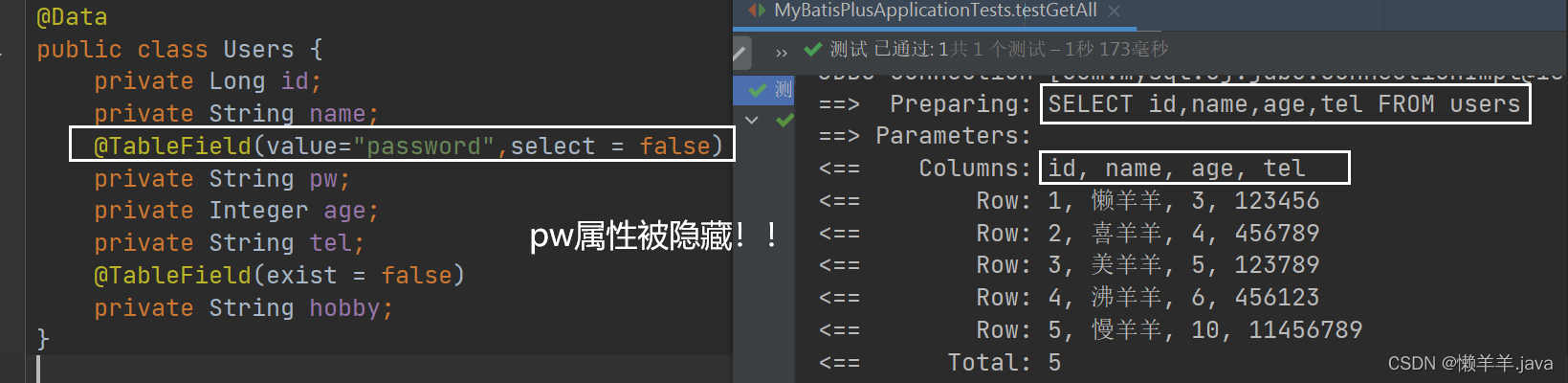
@TableFieldアノテーションの属性の 1 つが呼び出されますselect。この属性は、フィールドの値をデフォルトでクエリする必要があるかどうかを設定します。true (デフォルト値) はフィールドがデフォルトでクエリされることを意味し、false はフィールドがクエリされることを意味しますフィールドはデフォルトではクエリされないことを示します。
| 名前 | @TableField |
|---|---|
| タイプ | プロパティの注釈 |
| 位置 | モデルクラス属性定義の上 |
| 効果 | 現在の属性に対応するデータベース テーブル内のフィールド関係を設定します。 |
value (デフォルト): データベース テーブルのフィールド名を設定します。exist:
データベース テーブルのフィールドに属性が存在するかどうかを設定します。デフォルトは true です。この属性は value と組み合わせることはできません。選択: 属性が
クエリに参加するかどうかを設定します。属性が select() マッピングで構成されていません。
4. クラス名とテーブル名が一致しません
Lazy Yangyang が少し前にバグを解決したことを覚えています。

つまり、エンティティ クラスのクラス名がデータベース内のテーブル名と一致しないため、MP をマップできずテーブルに関連付けることができませんでした。予期せぬことに、後で問題を解決するためにアノテーションを使用できることを学びました。MP は、テーブルとエンティティ クラス間の対応関係を設定するための
別のアノテーション@TableNameを提供します。

この方法では、テーブル名に従ってエンティティ クラスを意図的に記述する必要はなくなりました。
| 名前 | @テーブル名 |
|---|---|
| タイプ | クラスのアノテーション |
| 位置 | モデルクラス定義の上 |
| 効果 | データベーステーブルのリレーションシップに対応するように現在のクラスを設定します。 |
| 関連するプロパティ | 値 (デフォルト): データベーステーブル名を設定します。 |
5. ID 自己インクリメント戦略
1.type = IdType.AUTO
MP を使い始めたときに追加メソッドを書いたのですが、不思議なのは、追加されたデータの主キー ID が順番に増加するのではなく、次のような非常に奇妙な数字になることです。 追加が成功すると、主キー ID

がは非常に長い内容の文字列です。さらに必要なのは、データベース テーブルのフィールドに従って自動インクリメントすることであり、異なるテーブルには次のような異なる ID 生成戦略が適用されます。 log: auto-increment (1, 2, 3, 4, ...
)
注文: 特別ルール (FQ77948AK3982)
持ち帰り注文: 関連する地域の日付およびその他の情報 (50 22 24765314 87 44)
例として自己インクリメントを見てみましょう: @TableId アノテーション
| 名前 | @テーブルID |
|---|---|
| タイプ | プロパティの注釈 |
| 位置 | 主キーを表すために使用されるモデル クラスの属性定義の上 |
| 効果 | 現在のクラスの主キー属性の生成戦略を設定します。 |
| 関連するプロパティ | value (デフォルト): データベーステーブルの主キー名を設定します。 type: 主キー属性の生成戦略を設定します。値は IdType の列挙値に基づきます。 |
idType 列挙クラスには多くの戦略があります。
@Getter
public enum IdType {
/**
* 数据库ID自增
* <p>该类型请确保数据库设置了 ID自增 否则无效</p>
*/
AUTO(0),
/**
* 该类型为未设置主键类型(注解里等于跟随全局,全局里约等于 INPUT)
*/
NONE(1),
/**
* 用户输入ID
* <p>该类型可以通过自己注册自动填充插件进行填充</p>
*/
INPUT(2),
/* 以下2种类型、只有当插入对象ID 为空,才自动填充。 */
/**
* 分配ID (主键类型为number或string),
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(雪花算法)
*
* @since 3.3.0
*/
ASSIGN_ID(3),
/**
* 分配UUID (主键类型为 string)
* 默认实现类 {@link com.baomidou.mybatisplus.core.incrementer.DefaultIdentifierGenerator}(UUID.replace("-",""))
*/
ASSIGN_UUID(4);
private final int key;
IdType(int key) {
this.key = key;
}
}
次に別の戦略を見ていきます
2.type = IdType.INPUT
自分自身を登録することで自動的に
データを入力する データベースの自動インクリメントをオフにし、この戦略を使用して追加操作を実行する場合:
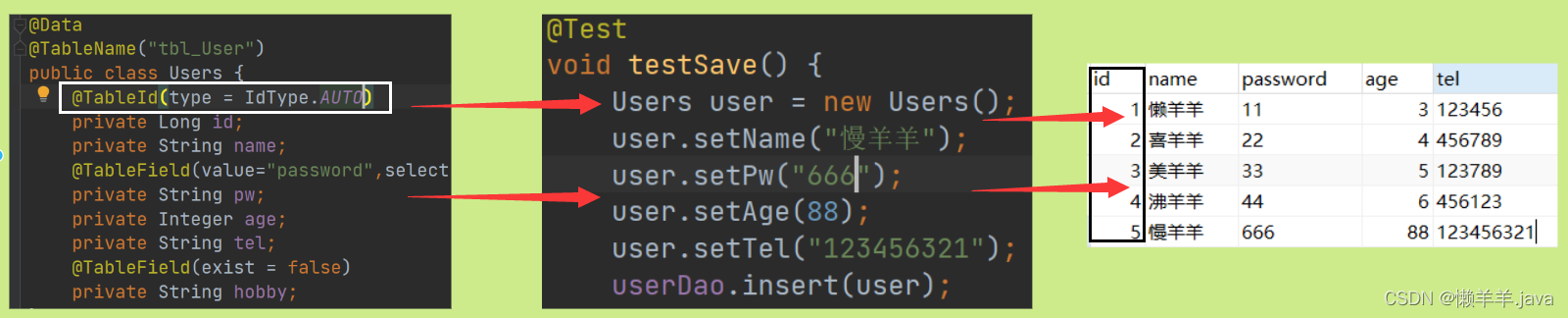
@TableId(type = IdType.INPUT)
@Test
void testSave() {
Users user = new Users();
user.setName("暖羊羊");
user.setPw("777");
user.setAge(11);
user.setTel("26262665");
userDao.insert(user);
}

明らかにデータを追加できません。ID は生成された SQL に表示されますが、メソッドには渡されないため、自分で入力する必要があります。
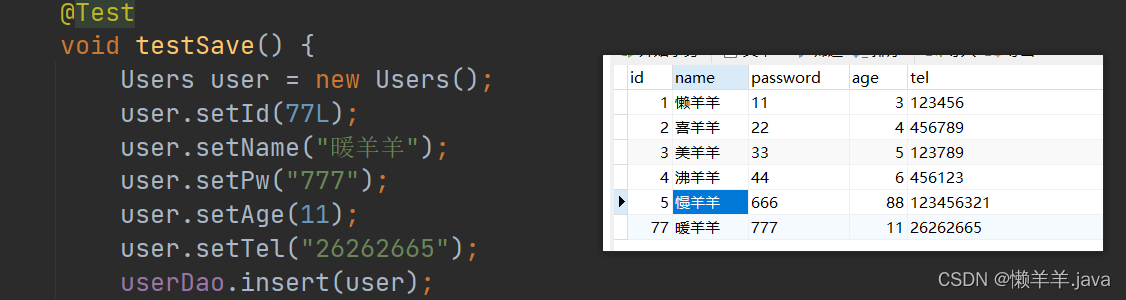
@Test
void testSave() {
Users user = new Users();
user.setId(77L);
user.setName("暖羊羊");
user.setPw("777");
user.setAge(11);
user.setTel("26262665");
userDao.insert(user);
}
最後に追加です
| なし | ID 生成戦略を設定しないでください |
|---|---|
| 入力 | ユーザーが手動でIDを入力 |
| ASSIGN_ID | Snowflake アルゴリズムによる ID の生成 (数値型および文字列型と互換性あり) |
| ASSIGN_UUID | ID 生成戦略として UUID 生成アルゴリズムを使用する |
また、さまざまな戦略の長所と短所も調べました。
- NONE: ID 生成戦略が設定されておらず、INPUT とほぼ等しい MP が自動生成されないため、どちらの方法でもユーザーが手動で設定する必要がありますが、手動設定の最初の問題は、同じ ID が発生しやすいことです。主キーが競合しないようにするには、多くの判断が必要となり、実装がより複雑になります。
- AUTO: データベース ID は自動的に増加します。この戦略は、データベース サーバーが 1 台しかない場合の使用に適しています。分散 ID としては使用できません。
- ASSIGN_UUID: 分散状況で使用でき、一意性を保証できますが、生成される主キーは 32 ビット文字列であり、長すぎて領域を占有し、並べ替えることができません。また、クエリのパフォーマンスも遅くなります。
- ASSIGN_ID: 分散状況で使用できます。Long 型の数値を生成します。これはソート可能で、パフォーマンスが高いです。ただし、生成された戦略はサーバー時間に関連します。システム時間が変更されると、プライマリが重複する可能性があります。キー。
3. スノーフレークアルゴリズムの概要
グローバルに一意な ID として 64 ビット長の数値を使用します。これは分散システムで広く使用されており、ID はタイムスタンプを導入します。基本的に、自己増加
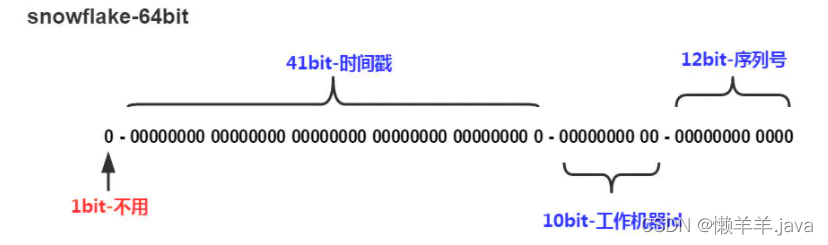
スノーフレーク アルゴリズムは 64 ビット バイナリです。ビット 1 は符号ビットであり、最上位ビットであり、常に 0 であり、意味がありません。 , なぜなら、コンピューターの 2 の補数が負の数だけである場合、0 は正の数であるからです。41 ビットはミリ秒に固有のタイムスタンプです。41 ビットのバイナリは 69 年間使用できます。時間は理論的には永遠に増加するため、これに従ってソートすることが可能です
4. 主キー戦略を統一する
将来のプロジェクトでは、各エンティティ クラスの主キー戦略を個別に構成しないように、次のように統合された方法で段階的な戦略を設定できます。
mybatis-plus:
global-config:
db-config:
id-type: assign_id
これにより、どこでも構成を統一できるようになります。