Flask をベースとした疫病データ管理および可視化システム
1. プロジェクトの紹介
このプロジェクトは、Python + Echarts + Flask + Layui + MySQL に基づく、新型コロナウイルス感染症のリアルタイム監視システムです。関連する主要なテクノロジには、パンダのワンクリック インポート、関連データ ストレージ機能への MySQL の使用、MySQL データベースとの対話のための Python の使用、Web プロジェクトの構築のための Flask の使用、Echarts に基づくデータ視覚化表示マップの作成、および Layui の使用が含まれます。バックグラウンド データ管理視覚化フレームワーク。開発プラットフォームとして pycharm を使用します。
2. プロジェクト機能
① 国内の新型コロナウイルス流行の全体状況の統計と表示、
② Echarts を使用して全国の新型コロナウイルス流行マップを作成し、各省の感染者数を表示、
③ Layui フレームワークを使用してバックエンド データ管理を作成システムを構築し、管理者ログイン機能を作成する;
④ 全国の新型コロナウイルス感染症流行における累計人数の推移を曲線グラフで表示;
⑤ 国内の新型コロナウイルス流行における新規感染者数の推移を曲線グラフで表示;
⑥ 湖北省以外の都市の感染者数TOP5の棒グラフランキング;
⑦ 管理者ユーザーはワンクリックでデータをインポート可能;
⑧ 管理者ユーザーはバックグラウンドの流行関連情報を閲覧可能 データの変更・削除操作が可能。
3. プロジェクト機能

4. アップデート手順
国家の疫病政策の緩和により、すべてのウェブサイトでの疫病データのメンテナンスが停止され、ほとんどの疫病データチャネルが閉鎖されました。したがって、クローラを介してデータを取得する方法はもう実現できませんが、プロジェクトは学習と参照のみを目的として以前のクローラ コードを引き続き保持しています。
同時に、サポートレポートもバージョンとは異なり、レポートは参考のみです。
更新内容:
- 新しいデータを追加し、一部のデータをワンクリックでインポートして、プロジェクトをすばやくインポートします
- 流行データインターフェースの停止によって引き起こされるページエラーリマインダーを修正
- コードディレクトリ構造全体を最適化する
5. プロジェクトのデモンストレーション
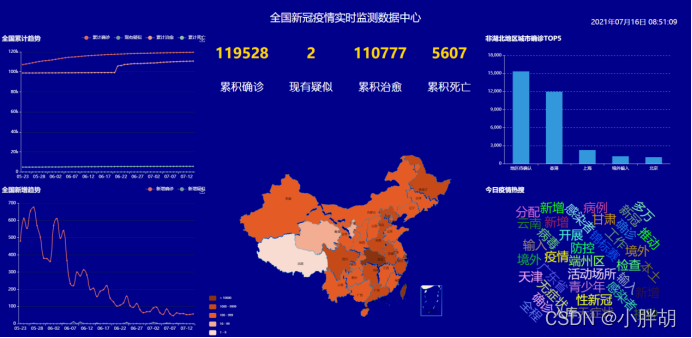
システムフロントエンドデータ表示ページ
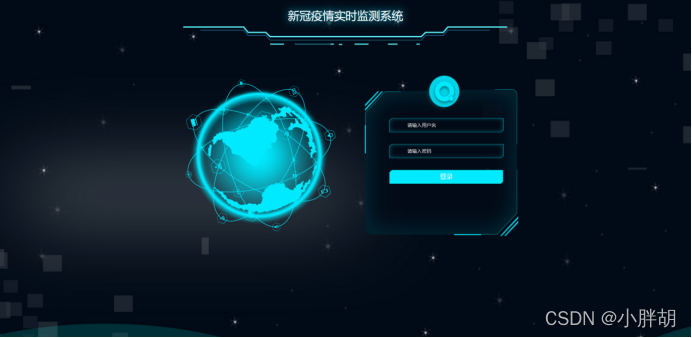
システムのバックグラウンドログインインターフェース
システム バックエンド ホームページ (クローラーの開始とデータ ダッシュボードへのジャンプを含む)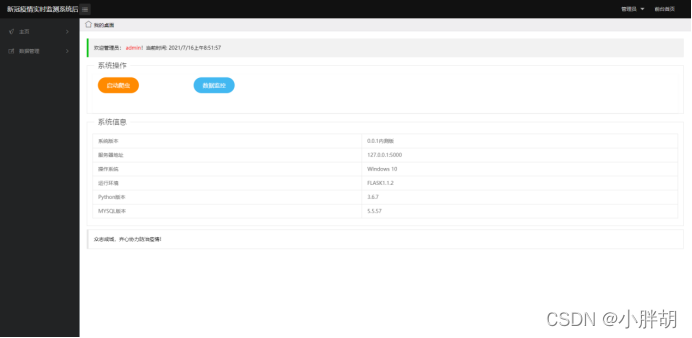
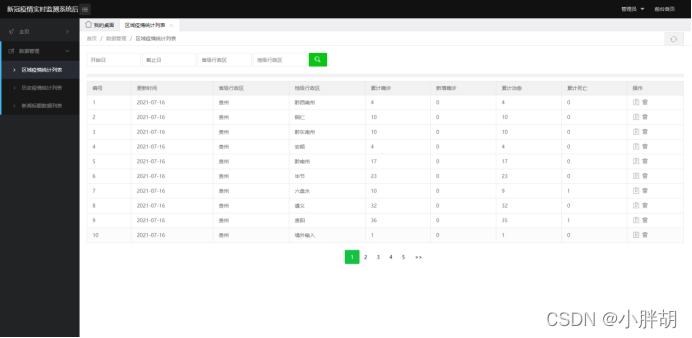
地域の流行統計リスト(削除、変更、クエリ、ページング機能を含む)
地域の流行統計修正ページ
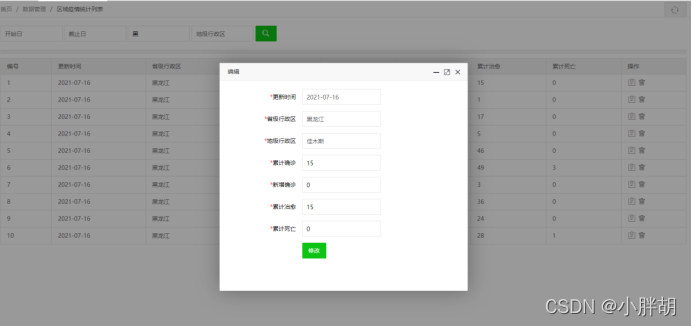
過去の疫病統計リスト(削除、変更、クエリ、ページング機能を含む)
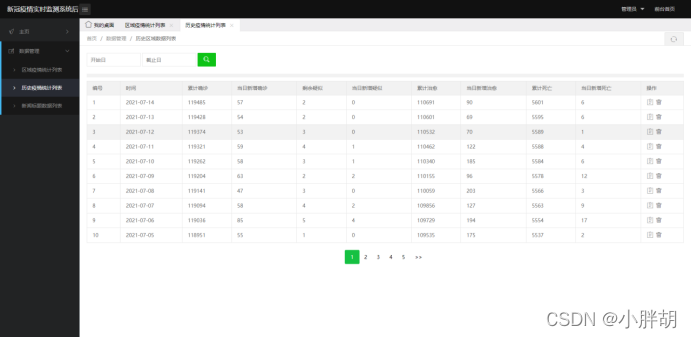
過去の疫病統計の

インポート テンプレートのインポート

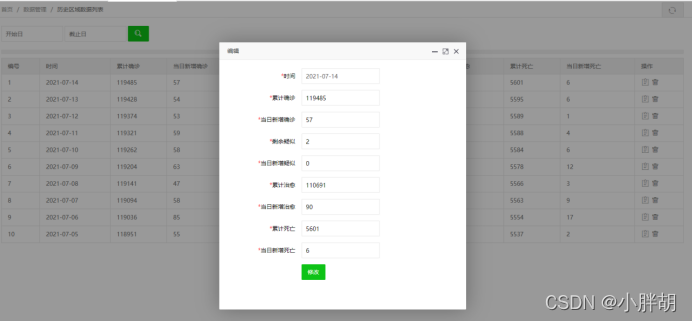
過去の疫病統計修正ページ
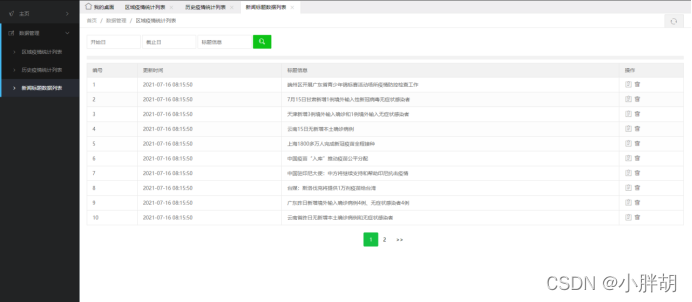
ニュースタイトル統計リスト(削除、変更、クエリ、ページング機能を含む)
ニュースタイトル変更ページ
6. プロジェクトのソースコード
爬虫類のソースコード
import time
import datetime
from selenium.webdriver.common.by import By
import pymysql
import json
import traceback
import requests
from selenium.webdriver import Firefox, FirefoxOptions
from bs4 import BeautifulSoup
import re
def get_conn():
# 建立数据库连接
conn = pymysql.connect(host="127.0.0.1", user="root", password="123456", db="cov", charset="utf8")
# 创建游标
cursor = conn.cursor()
return conn, cursor
def close_conn(conn, cursor):
if cursor:
cursor.close()
if conn:
conn.close()
##################爬虫独立模块######################
# 功能说明:
# ①爬取并插入各个地区历史疫情数据
# ②爬取并插入全国历史疫情统计数据
# ③爬取并插入百度新闻标题最新数据
# 文件说明:
# ①可独立运行呈现结果
# ②调用online方法运行
####################################################
def get_tx_history_data():
url2 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_other"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
r2 = requests.get(url2, headers)
res2 = json.loads(r2.text)
try:
data_all2 = json.loads(res2["data"])
except:
return [], []
history = {
}
for i in data_all2["chinaDayList"]:
ds = i["y"] + "." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
history[ds] = {
"confirm": confirm, "suspect": suspect, "heal": heal, "dead": dead}
for i in data_all2["chinaDayAddList"]:
ds = i["y"] + "." + i["date"]
tup = time.strptime(ds, "%Y.%m.%d") # 匹配时间
ds = time.strftime("%Y-%m-%d", tup) # 改变时间格式
confirm = i["confirm"]
suspect = i["suspect"]
heal = i["heal"]
dead = i["dead"]
if ds in history:
history[ds].update({
"confirm_add": confirm, "suspect_add": suspect, "heal_add": heal, "dead_add": dead})
return history
def get_tx_detail_data():
url1 = "https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
headers = {
'user-agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Mobile Safari/537.36'
}
r1 = requests.get(url1, headers)
res1 = json.loads(r1.text)
print(res1["data"])
data_all1 = {
}
try:
data_all1 = json.loads(res1["data"])
except:
return []
details = []
update_time = data_all1["lastUpdateTime"]
data_country = data_all1["areaTree"]
data_province = data_country[0]["children"]
for pro_infos in data_province:
province = pro_infos["name"]
for city_infos in pro_infos["children"]:
city = city_infos["name"]
confirm = city_infos["total"]["confirm"]
confirm_add = city_infos["today"]["confirm"]
heal = city_infos["total"]["heal"]
dead = city_infos["total"]["dead"]
details.append([update_time, province, city, confirm, confirm_add, heal, dead])
return details
def get_dx_detail_data():
url = 'https://ncov.dxy.cn/ncovh5/view/pneumonia?from=timeline&isappinstalled=0'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36'
}
# 省级正则表达式
provinceName_re = re.compile(r'"provinceName":"(.*?)",')
provinceShortName_re = re.compile(r'"provinceShortName":"(.*?)",')
currentConfirmedCount_re = re.compile(r'"currentConfirmedCount":(.*?),')
confirmedCount_re = re.compile(r'"confirmedCount":(.*?),')
suspectedCount_re = re.compile(r'"suspectedCount":(.*?),')
curedCount_re = re.compile(r'"curedCount":(.*?),')
deadCount_re = re.compile(r'"deadCount":(.*?),')
cities_re = re.compile(r'"cities":\[\{(.*?)\}\]')
# 爬虫爬取数据
datas = requests.get(url, headers=headers)
datas.encoding = 'utf-8'
soup = BeautifulSoup(datas.text, 'lxml')
data = soup.find_all('script', {
'id': 'getAreaStat'}) # 网页检查定位
data = str(data)
data_str = data[54:-23]
# print(data_str)
# 替换字符串内容,避免重复查找
citiess = re.sub(cities_re, '8888', data_str)
# 查找省级数据
provinceShortNames = re.findall(provinceShortName_re, citiess)
currentConfirmedCounts = re.findall(currentConfirmedCount_re, citiess)
confirmedCounts = re.findall(confirmedCount_re, citiess)
suspectedCounts = re.findall(suspectedCount_re, citiess)
curedCounts = re.findall(curedCount_re, citiess)
deadCounts = re.findall(deadCount_re, citiess)
details = []
current_date = datetime.datetime.now().strftime('%Y-%m-%d')
for index, name in enumerate(provinceShortNames):
# 备用历史区域获取接口,只获取省份的累计确诊、现有确诊、累计治愈、累计死亡
details.append([current_date, name, name, confirmedCounts[index], currentConfirmedCounts[index], curedCounts[index], deadCounts[index]])
return details
# 插入地区疫情历史数据
# 插入全国疫情历史数据
def update_history():
conn, cursor = get_conn()
try:
# li = get_tx_detail_data() # 1代表最新数据
li = get_dx_detail_data() # 1代表最新数据
if len(li) == 0:
print(f"[WARN] {
time.asctime()} 接口暂时异常,数据未获取到或解析地区历史疫数据异常...")
else:
sql = "insert into details(update_time,province,city,confirm,confirm_add,heal,dead) values(%s,%s,%s,%s,%s,%s,%s)"
sql_query = 'select %s=(select update_time from details order by id desc limit 1)'
# 对比当前最大时间戳
cursor.execute(sql_query, li[0][0])
if not cursor.fetchone()[0]:
print(f"[INFO] {
time.asctime()} 地区历史疫情爬虫已启动,正在获取数据....")
for item in li:
print(f"[INFO] {
time.asctime()} 已获取地区历史疫情数据:", item)
cursor.execute(sql, item)
conn.commit()
print(f"[INFO] {
time.asctime()} 地区历史疫情爬虫已完成,更新到最新数据成功...")
else:
print(f"[WARN] {
time.asctime()}地区历史疫情爬虫已启动,已是最新数据...")
except:
traceback.print_exc()
try:
dic = get_tx_history_data() # 1代表最新数据
if len(dic) == 0:
print(f"[WARN] {
time.asctime()} 接口暂时异常,数据未获取到或解析全国历史疫情数据异常...")
print(f"[INFO] {
time.asctime()} 全国历史疫情爬虫已启动,正在获取数据....")
conn, cursor = get_conn()
sql = "insert into history values (%s,%s,%s,%s,%s,%s,%s,%s,%s)"
sql_query = "select confirm from history where ds=%s"
for k, v in dic.items():
if not cursor.execute(sql_query, k):
print(f"[INFO] {
time.asctime()} 已获取全国历史疫情:",
[k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
cursor.execute(sql, [k, v.get("confirm"), v.get("confirm_add"), v.get("suspect"),
v.get("suspect_add"), v.get("heal"), v.get("heal_add"),
v.get("dead"), v.get("dead_add")])
conn.commit()
print(f"[INFO] {
time.asctime()} 全国历史疫情爬虫已完成,更新到最新数据成功...")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
# 爬取腾讯健康热搜数据
def get_tenxun_hot():
option = FirefoxOptions()
option.add_argument("--headless") # 隐藏游览器
option.add_argument("--no--sandbox")
browser = Firefox(options=option)
url = "https://feiyan.wecity.qq.com/wuhan/dist/index.html#/?tab=shishitongbao"
browser.get(url)
time.sleep(3)
c = browser.find_elements(By.XPATH,"//*[@id='app']/div/div[1]/div[3]/div[3]/div[2]/div/div[2]/div[1]/div/div[2]")
context = [i.text for i in c]
browser.close()
return context
def is_number(s):
try: # 如果能运行float(s)语句,返回True(字符串s是浮点数)
float(s)
return True
except ValueError: # ValueError为Python的一种标准异常,表示"传入无效的参数"
pass # 如果引发了ValueError这种异常,不做任何事情(pass:不做任何事情,一般用做占位语句)
try:
import unicodedata # 处理ASCii码的包
unicodedata.numeric(s) # 把一个表示数字的字符串转换为浮点数返回的函数
return True
except (TypeError, ValueError):
pass
return False
# 插入百度热搜实时数据
def update_hotsearch():
cursor = None
conn = None
try:
print(f"[INFO] {
time.asctime()} 新闻资讯爬虫已启动,正在获取数据...")
context = get_tenxun_hot()
conn, cursor = get_conn()
sql = "insert into hotsearch(dt,content) values(%s,%s)"
ts = time.strftime("%Y-%m-%d %X")
for i in context:
print(f"[INFO] {
time.asctime()} 已获取历史疫情:", [ts, i])
cursor.execute(sql, (ts, i))
conn.commit()
print(f"[INFO] {
time.asctime()} 新闻资讯爬虫已完成,更新到最新数据成功...")
except:
traceback.print_exc()
finally:
close_conn(conn, cursor)
def online():
update_history()
update_hotsearch()
return 200
if __name__ == "__main__":
update_history()
update_hotsearch()
7. ソースコードの取得
このプロジェクトは感染症流行後に終了したため、データは古いデータに基づいています。クローラー経由でデータを取得できません!
Yunyuan Practical Combat の公式 Web サイトには、ソース コード、インストール チュートリアル ドキュメント、プロジェクト紹介ドキュメント、およびその他の関連ドキュメントがアップロードされており、以下の公式 Web サイトからプロジェクトを入手できます。