前の 2 つの記事では、keras 深層学習フレームワークを使用して、単純なニューラル ネットワークと畳み込みニューラル ネットワークを構築し、手書きの数字認識実験を実装しました。この記事では、手書き数字認識を実装するために LeNet5 モデルに基づいて構築した畳み込みニューラル ネットワークを共有します。
この実験は LeNet5 モデルに基づいて畳み込みニューラル ネットワークを構築するもので、LeNet5 モデルの概略図は次のとおりです。
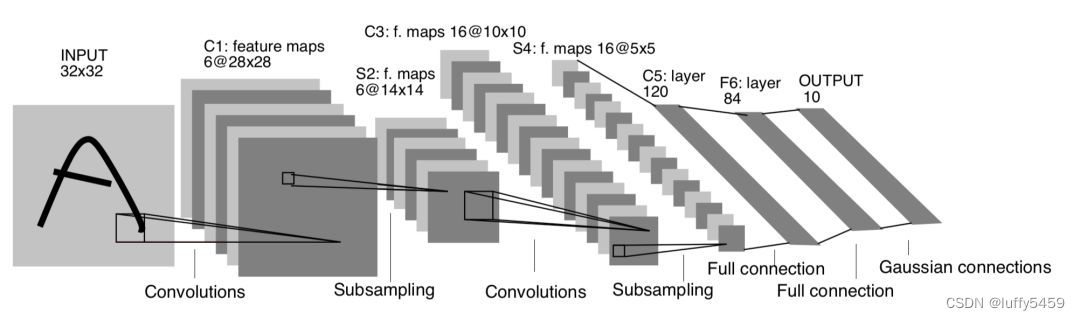
このモデルはさまざまな場所で目にしたことがあると思いますが、実際には、多くのコードは実験においてこのモデルに厳密に従っていません。なぜ?主な手書き数字認識モデルのデータ mnist 仕様は 28*28 で、この LeNet5 モデルで必要なデータ入力は 32*32 です。これを解決するために、全員がこのモデルのパラメータを非公開で変更し、最終的な入力は 28*28 になりました。その後、最初の畳み込みの後、特徴マップは 6@24*24 になり、ダウンサンプリングにより半分に減りました: 6@12 ※12.全結合層になると、特徴マップは 16@4*4 になります。
実際、この変更には何も問題はなく、最終的に実験の目的は達成され、モデルをトレーニングした後のテスト精度は 98% 以上に達します。
この LeNet5 モデルに実際に従うには、32*32 の入力形状が必要ですが、現在では、KNN 手書き数字認識実験だけが、トレーニング データ セット trainingDigits とテスト データ セット testDigits の仕様が 32*32=1024 であるようです。データ量が比較的少ないこと、学習データが 2,000 個、テストデータが 900 個以上あること、もう 1 つはデータがテキストであること、そのデータを取得するにはテキスト変換を読み取る必要があることです。
妥協点はありますが、opencv が提供するサイズ変更メソッドを使用して、mnist データ セットの 28*28 形状を 32*32 形状に変換できます。これにより、精度がいくらか失われる可能性があり、テスト データと予測に使用される画像データも変更されるため、精度の問題は相殺されると考えられます。
実際、モデル自体にはいくつかのあいまいさがあり、ダウンサンプリング層の具体的な方法、最大サンプリングと平均サンプリングのどちらを使用するか、畳み込み層の活性化関数がこの図には示されていません。紙で知ることができますか?
そのため、実装では畳み込み層の活性化関数はtanhを使用するのが一般的ですが、reluを使用しても問題ありませんし、ダウンサンプリング層のSubSamplingも同様にMaxPool2DまたはAveragePooling2Dを使用します。
このモデルについて簡単に説明しましょう。
入力画像の行列形状 (32,32)
最初の畳み込み層: 6 つの畳み込みカーネル、畳み込みカーネルのサイズは 5*5 であるため、出力特徴マップ (特徴マップ) のサイズは 6@(32-5+1) * (32-5+1) になります。 = 6 @28*28
サブサンプリングの 2 番目の層 (SubSampling): 2*2 サイズ。その結果、特徴マップのサイズは引き続き半分になります 6@14*14
3 番目の畳み込み層: 16 畳み込みカーネル、畳み込みカーネルのサイズは 5*5、出力特徴マップ サイズ: 16@(14-5+1)*(14-5+1)=16@10*10
ダウンサンプリングの 4 番目の層: 2*2 サイズ、特徴マップは半分の 16@5*5 に縮小されます。
5 番目の平坦化層: 120 ニューロン
6 番目の完全に接続された層: 84 個のニューロン
7 番目の出力層: 10 ニューロン
次に、mnist データセットと LeNet5 データ モデルに基づいてニューラル ネットワークを構築し、トレーニングしてテストします。コードは次のとおりです。
from keras.models import Sequential
from keras.layers import Conv2D, MaxPool2D, AveragePooling2D
from keras.layers import Dense, Flatten
import keras
from keras.datasets import mnist
from keras.utils import np_utils
from keras.utils.vis_utils import plot_model
import numpy as np
import cv2
# 加载数据
(X_train, y_train), (X_test, y_test) = mnist.load_data()
input_shape = (32, 32, 1)
train_x = []
test_x = []
for val in X_train:
img = cv2.resize(val, (input_shape[0], input_shape[1]))
train_x.append(img.reshape(input_shape))
for val_ in X_test:
img = cv2.resize(val_, (input_shape[0], input_shape[1]))
test_x.append(img.reshape(input_shape))
# 数据预处理
X_train = np.array(train_x) / 255.0
X_test = np.array(test_x) / 255.0
# to_categorical()将类别向量转换为二进制(只有0和1)的矩阵类型表示
y_train = np_utils.to_categorical(y_train, num_classes=10)
y_test = np_utils.to_categorical(y_test, num_classes=10)
model = Sequential()
model.add(Conv2D(6, kernel_size=(5, 5), activation='tanh', input_shape=input_shape))
model.add(AveragePooling2D(pool_size=(2, 2)))
model.add(Conv2D(16, kernel_size=(5, 5), activation='tanh'))
model.add(AveragePooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(120, activation='tanh'))
model.add(Dense(84, activation='tanh'))
model.add(Dense(10, activation='softmax'))
# 模型编译
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
model.summary()
# 训练
model.fit(X_train, y_train, batch_size=128, epochs=10)
# 评估模型
score = model.evaluate(X_test, y_test)
print('acc', score[1])
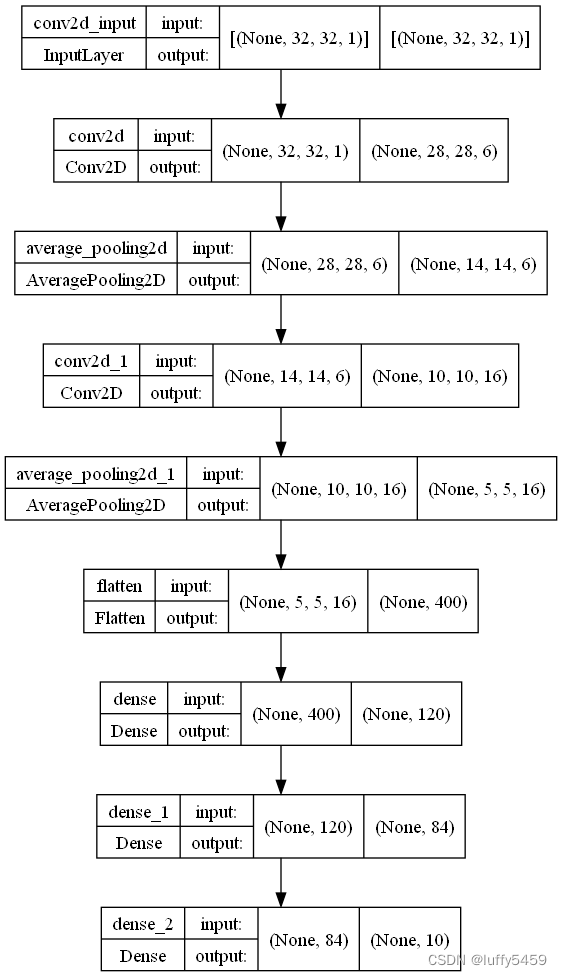
plot_model(model, to_file='model.png', show_shapes=True)
model.save("lenet5.h5")
次のようにコードを実行し、モデル パラメーター情報を出力します。
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 28, 28, 6) 156
average_pooling2d (AverageP (None, 14, 14, 6) 0
ooling2D)
conv2d_1 (Conv2D) (None, 10, 10, 16) 2416
average_pooling2d_1 (Averag (None, 5, 5, 16) 0
ePooling2D)
flatten (Flatten) (None, 400) 0
dense (Dense) (None, 120) 48120
dense_1 (Dense) (None, 84) 10164
dense_2 (Dense) (None, 10) 850
=================================================================
Total params: 61,706
Trainable params: 61,706
Non-trainable params: 0トレーニングとテストのプロセスは次のとおりです。
Epoch 1/10
2023-08-30 22:04:32.166768: I tensorflow/stream_executor/cuda/cuda_dnn.cc:368] Loaded cuDNN version 8800
469/469 [==============================] - 8s 12ms/step - loss: 0.3042 - accuracy: 0.9110
Epoch 2/10
469/469 [==============================] - 5s 10ms/step - loss: 0.1113 - accuracy: 0.9664
Epoch 3/10
469/469 [==============================] - 5s 10ms/step - loss: 0.0709 - accuracy: 0.9784
Epoch 4/10
469/469 [==============================] - 5s 11ms/step - loss: 0.0530 - accuracy: 0.9843
Epoch 5/10
469/469 [==============================] - 5s 11ms/step - loss: 0.0410 - accuracy: 0.9875
Epoch 6/10
469/469 [==============================] - 5s 11ms/step - loss: 0.0329 - accuracy: 0.9898
Epoch 7/10
469/469 [==============================] - 6s 12ms/step - loss: 0.0283 - accuracy: 0.9910
Epoch 8/10
469/469 [==============================] - 6s 12ms/step - loss: 0.0228 - accuracy: 0.9928
Epoch 9/10
469/469 [==============================] - 6s 12ms/step - loss: 0.0193 - accuracy: 0.9939
Epoch 10/10
469/469 [==============================] - 6s 13ms/step - loss: 0.0159 - accuracy: 0.9949
313/313 [==============================] - 2s 4ms/step - loss: 0.0406 - accuracy: 0.9871
acc 0.9871000051498413テスト精度は98.7%と高いです。
コードの最後では、plot_model を通じてモデル イメージも保存しました。
さらに、予測用にモデル ファイル lenet5.h5 も保存しました。
予測または祖先のコードは、画像の形状を 32*32 ピクセルに変更しました。これは、予測された画像がまだ 28*28 ピクセルで、背景が黒、テキストが白であるためです。










import keras
import numpy as np
import cv2
from keras.models import load_model
model = load_model("lenet5.h5")
def predict(img_path):
img = cv2.imread(img_path, 0)
img = cv2.resize(img, (32, 32))
img = img.astype("float32") / 255 # 0 1
img = img.reshape(1, 32, 32, 1) # 32 * 32 -> (1,32,32,1)
label = model.predict(img)
label = np.argmax(label, axis=1)
print('{} -> {}'.format(img_path, label[0]))
if __name__ == '__main__':
for _ in range(10):
predict("number_images/b_{}.png".format(_))実験結果:
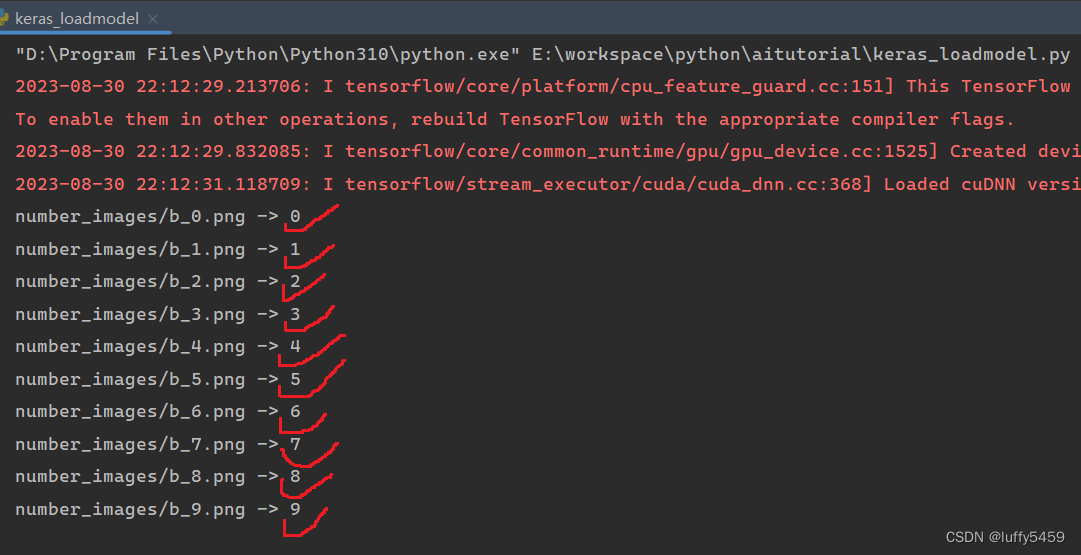
この結果は実際には予期せぬものではなく、このモデルが非常に強力で予測が 100% と高いためでもありません。実際、ここで予測された画像は 10 枚だけで、それほど多くはありません。多くの画像は私自身でテストされています。なので、非常に強力に見えます。
ここには多くの変数があります。1 つ目は、前述した入力サイズの問題です。32*32 を 28*28 に変更すると、mnist データセットを使用するときに形状を変更する必要がありません。ただし、最終的には高いテスト精度と予測精度で実行できるようになりますが、このモデルとは異なります。もう 1 つの変数は畳み込み層の活性化関数で、ここでは Tanh を使用します。実際には relu を使用しても問題ありません。もう 1 つはダウンサンプリングとして MaxPool2D を使用することです。モデルをコンパイルするときは、rmsprop オプティマイザーを使用しますが、adam を使用することもできます。
LeNet5 モデルは実際にはデジタル認識に非常に適していますが、デジタル認識に適したトレーニング データ セットがなく、cifar10 データ セットは 32*32 であるため、コーディングの観点からは、このモデルが画像分類に最も適しています。