1. 分散トランザクションを使用する必要があるのはなぜですか?
分散環境でのビジネスには複数のモジュール間の呼び出しが含まれる場合がありますが、操作のアトミック性を確保するには、分散トランザクションが最適なソリューションです。
2. 地方事情
システムに分散トランザクションを導入する前に、やはりローカルトランザクションを見直す必要があります。サービス内で有効となるトランザクションをローカルトランザクションと呼びます。
1. 取引の特徴
トランザクションの概念: トランザクションは、操作の論理グループです。この操作グループを構成する論理ユニットは、一緒に成功するか、一緒に失敗します。
トランザクションの 4 つの特性 (ACID):
- アトミック性: 「アトミック」の本来の意味は、「再度分割できない」という意味であり、トランザクションのアトミック性は、トランザクションに含まれる複数の操作が論理的に不可欠であるという事実に現れます。トランザクションの原子性には、トランザクション内のすべての操作が実行されるか、何も実行されないかのいずれかが必要です。
- 一貫性:
一致データの一貫性を指します。具体的には、すべてのデータがビジネス ルールを満たす一貫した状態にあります。一貫性の原則では、トランザクションに含まれる操作の数に関係なく、トランザクションの実行前にデータが正しいこと、およびトランザクションの実行後もデータが正しいことが保証されなければなりません。トランザクションの実行中に 1 つまたは複数の操作が失敗した場合、他のすべての操作を元に戻し、データをトランザクションの実行前の状態に復元する必要があります。これをロールバックと呼びます。 - 分離: アプリケーションの実際の操作中、トランザクションは同時に実行されることが多いため、多くのトランザクションが同じデータを同時に処理する可能性が非常に高いため、データの破損を防ぐために各トランザクションを他のトランザクションから分離する必要があります。分離原則では、複数のトランザクションが同時実行中に相互に干渉しないことが必要です。
- 耐久性: 耐久性の原則では、トランザクションの完了後、データへの変更が永続的に保存され、さまざまなシステム エラーやその他の予期せぬ状況の影響を受けないことが要求されます。通常、データに対するトランザクションの変更は永続ストレージに書き込まれる必要があります。
2. トランザクション分離レベル
トランザクションの同時実行により、いくつかの読み取り問題が発生します。
- ダーティ リード トランザクションは別のトランザクションのコミットされていないデータを読み取ることができます
- 反復不可能な読み取り。あるトランザクションは別のトランザクションによって送信されたデータを読み取ることができます。単一のレコードは前後で一致しません。
- 仮想読み取り (ファントム読み取り): あるトランザクションが別のトランザクションの送信されたデータを読み取ることができ、前後に読み取られるデータは多少異なります。
同時書き込み: mysql のデフォルトのロック機構 (排他的ロック) を使用します。
読み取りの問題を解決する: トランザクション分離レベルを設定する
- コミットされていない読み取り(0)
- コミットされた読み取り(2)
- 反復可能な読み取り(4)
- シリアル化可能(8)
分離レベルが高くなるほど、パフォーマンスは低下します。
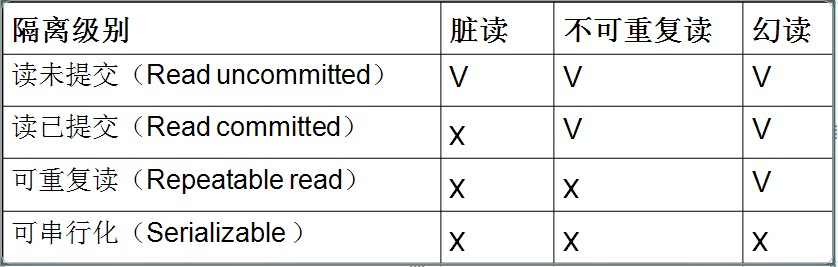
通常の状況では、ダーティ読み取りは許可されませんが、非反復読み取りとファントム読み取りは適切に許可されます。
3. トランザクションの送信特性
Spring の 7 つのトランザクション伝播動作:
| トランザクション動作 | 説明する |
|---|---|
| PROPAGATION_REQUIRED | 現在のトランザクションがないことを前提として、現在のトランザクションをサポートします。新しいトランザクションを作成するだけです |
| PROPAGATION_SUPPORTS | 現在のトランザクションをサポートします。現在のトランザクションがない場合は、非トランザクション モードで実行されます。 |
| PROPAGATION_MANDATORY | 現在のトランザクションをサポートします。現在のトランザクションがない場合は、例外がスローされます。 |
| PROPAGATION_REQUIRES_NEW | トランザクションが現在存在すると仮定して、新しいトランザクションを作成します。現在のトランザクションを一時停止します |
| PROPAGATION_NOT_SUPPORTED | 操作を非トランザクション モードで実行します。現在トランザクションが存在すると仮定して、現在のトランザクションを一時停止します。 |
| PROPAGATION_NEVER | 現在のトランザクションがあると仮定して、非トランザクション モードで実行され、例外がスローされます。 |
| PROPAGATION_NESTED | トランザクションが現在存在する場合、そのトランザクションはネストされたトランザクション内で実行されます。現在のトランザクションがない場合は、PROPAGATION_REQUIRED と同様の操作を実行します。 |
例えば
サービスA
ServiceA {
void methodA() {
ServiceB.methodB();
}
}
サービスB
ServiceB {
void methodB() {
}
}
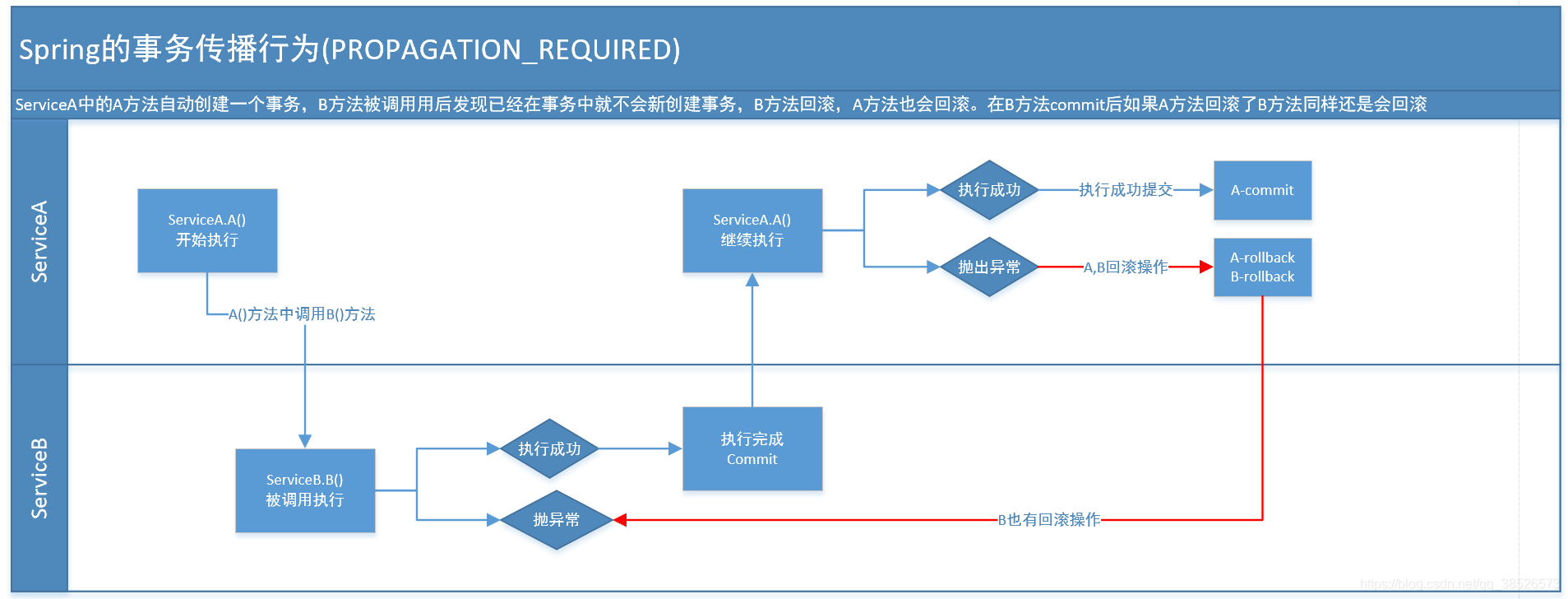
1.PROPAGATION_REQUIRED
現在実行中のトランザクションが別のトランザクションにない場合は、新しいトランザクションを開始します。たとえば、ServiceB.methodB のトランザクション レベルは PROPAGATION_REQUIRED を定義しているため、ServiceA.methodA が実行されると、ServiceA.methodA はすでにトランザクションを開始しています。このときServiceB.methodBが呼び出され、ServiceB.methodBはServiceA.methodAのトランザクション内で実行されたことを認識します。新たな出来事は起こらないだろう。そして、ServiceA.methodA の実行時にトランザクション内にないことが判明した場合は、それ自体にトランザクションを割り当てます。このように、ServiceA.methodA または ServiceB.methodB の任意の場所で例外が発生します。トランザクションはロールバックされます。ServiceB.methodB のトランザクションがコミットされていても、次に失敗すると ServiceA.methodA がロールバックされ、ServiceB.methodB もロールバックされます。
2.PROPAGATION_SUPPORTS
現在トランザクション中であると仮定します。つまり、トランザクションの形式で実行されます。現在トランザクション中でないと仮定すると、非トランザクション方式で実行されます。
3.PROPAGATION_MANDATORY
トランザクション内で実行する必要があります。つまり、親トランザクションによってのみ呼び出すことができます。それ以外の場合、彼は例外をスローします
4.PROPAGATION_REQUIRES_NEW
これはもう少し複雑です。たとえば、ServiceA.methodA のトランザクション レベルを PROPAGATION_REQUIRED に、ServiceB.methodB のトランザクション レベルを PROPAGATION_REQUIRES_NEW に設計します。その後、ServiceB.methodB を実行すると、ServiceA.methodA が配置されているトランザクションが一時停止されます。ServiceB.methodB は新しいトランザクションを開始します。ServiceB.methodB のトランザクションが完了するまで待ってから、実行を続行します。
トランザクションと PROPAGATION_REQUIRED の違いは、トランザクションのロールバックの程度です。ServiceB.methodB は新しいトランザクションであるため、2 つの異なるトランザクションが存在します。ServiceB.methodA が送信され、ServiceA.methodA が失敗してロールバックするとします。ServiceB.methodB はロールバックされません。ServiceB.methodA が失敗してロールバックし、ServiceB.methodA がスローする例外が ServiceA.methodA によってキャッチされたと仮定すると、ServiceA.methodA トランザクションは引き続き送信される可能性があります。
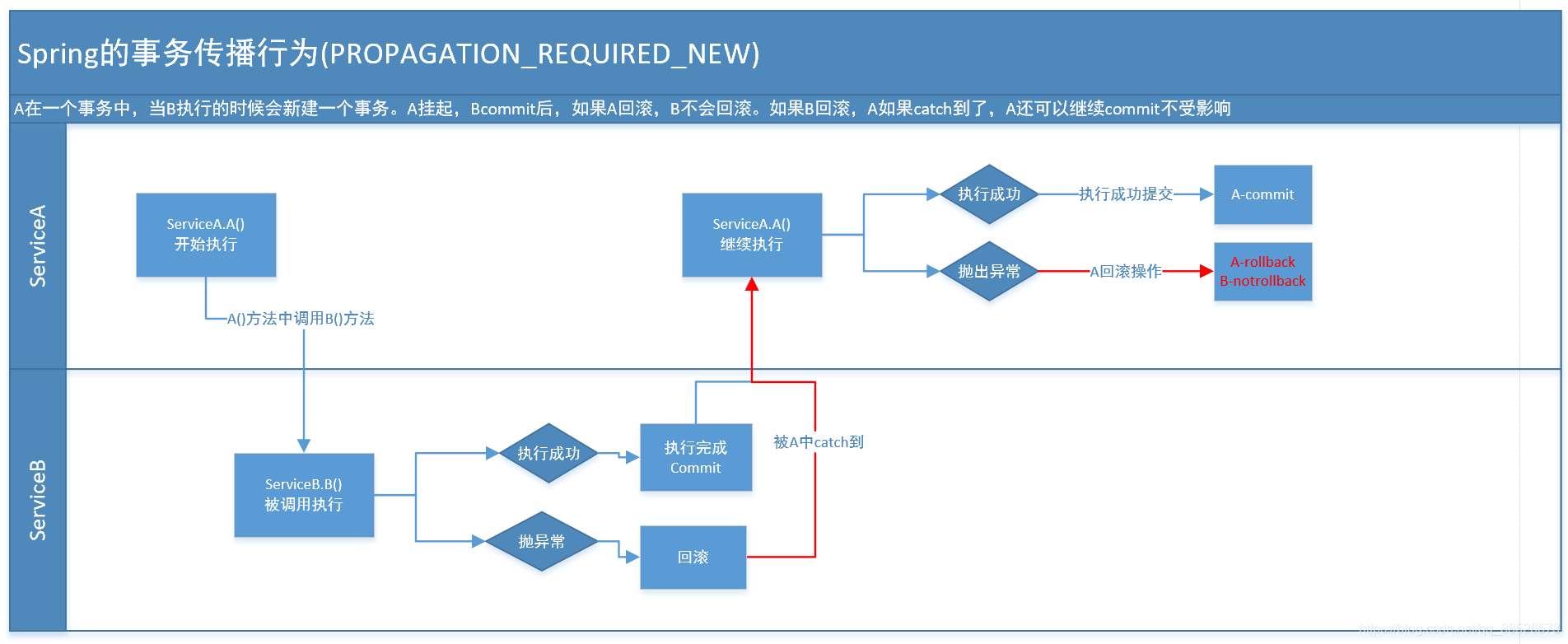
5.PROPAGATION_NOT_SUPPORTED
現在、トランザクションはサポートされていません。たとえば、ServiceA.methodA のトランザクション レベルは PROPAGATION_REQUIRED です。ServiceB.methodB が実行されるとき、ServiceB.methodB のトランザクション レベルは PROPAGATION_NOT_SUPPORTED です。ServiceA.methodA のトランザクションは保留中です。そして、非トランザクション状態で実行を終了し、ServiceA.methodA のトランザクションを継続します。
6.PROPAGATION_NEVER
トランザクション内では実行できません。
ServiceA.methodA のトランザクション レベルが PROPAGATION_REQUIRED の場合。ServiceB.methodB のトランザクション レベルが PROPAGATION_NEVER の場合、ServiceB.methodB は例外をスローします。
7.PROPAGATION_NESTED
トランザクションが現在存在する場合、そのトランザクションはネストされたトランザクション内で実行されます。現在のトランザクションがない場合は、PROPAGATION_REQUIRED と同様の操作を実行します。
@Transactional(propagation=Propagation.REQUIRED)
トランザクションが存在する場合はトランザクションに参加し、存在しない場合は新しいトランザクションを作成します (デフォルト)
@Transactional(propagation=Propagation.NOT_SUPPORTED)
コンテナはこのメソッドのトランザクションを開きません
@Transactional(propagation=Propagation.REQUIRES_NEW )
トランザクションが存在するかどうかに関係なく、新しいトランザクションが作成されます。元のトランザクションは一時停止されます。新しいトランザクションが実行された後、古いトランザクションは実行され続けます。 @Transactional(propagation=Propagation
. MANDATORY)
は既存のトランザクションで実行する必要があります。そうでない場合は、例外がスローされます。 Exception
@Transactional(propagation=Propagation.NEVER) は、
存在しないトランザクションで実行する必要があります。そうでない場合は、例外がスローされます (Propagation.MANDATORY の反対)
@ Transactional(propagation=Propagation.SUPPORTS)
他の Bean がこのメソッドを呼び出す場合、他の Bean でトランザクションが宣言されている場合はトランザクションを使用し、他の Bean がトランザクションを宣言していない場合はトランザクションを使用しません。
4.SpringBootトランザクションプロキシオブジェクト
Spring Boot では、オブジェクト内で複数のトランザクション メソッドが相互に呼び出している場合、トランザクションの伝播が失敗します。主な理由は、現在のオブジェクトがプロキシ オブジェクトの処理をバイパスして、自身のオブジェクトのメソッドを直接呼び出しているため、トランザクションの伝播が失敗することです。 。次に、対応する解決策は、spring-boot-stater-aop呼び出すプロキシ オブジェクトを明示的に取得することです。
関連する依存関係を導入する
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-aop</artifactId>
<version>2.4.12</version>
</dependency>
aspectj アノテーションを追加する
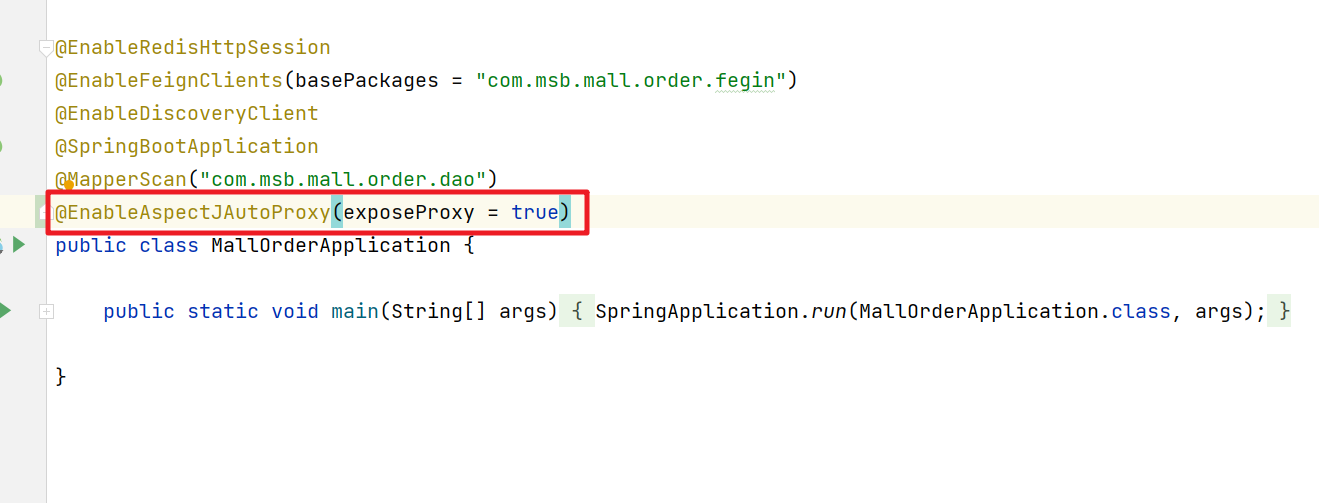
次に、呼び出す必要がある場所でAopContext現在のプロキシ オブジェクトを取得します。
/**
* 在service中调用自身的其他事务方法的时候,事务的传播行为会失效
* 因为会绕过代理对象的处理
*
*/
@Transactional // 事务A
public void a(){
OrderServiceImpl o = (OrderServiceImpl) AopContext.currentProxy();
o.b(); // 事务A
o.c(); // 事务C
int a = 10/0;
}
@Transactional(propagation = Propagation.REQUIRED)
public void b(){
}
@Transactional(propagation = Propagation.REQUIRES_NEW)
public void c(){
}
3. 分散トランザクション
1. 分散トランザクションの基本
CAP定理
分散ストレージ システムの CAP 原則 (分散システムの 3 つの指標):
-
一貫性: 分散システム内のすべてのデータ バックアップが同時に同じ値を持つかどうか。
異なるノードに分散したデータにおいて、あるノードでデータが更新され、他のノードで最新のデータを読み込むことができる場合を強整合性と呼び、ノードがデータを読み込まない場合を強整合性と呼びます。取得されている場合は、分散不整合となります。
-
可用性: クラスター内の一部のノードに障害が発生した後でも、クラスター全体がクライアントの読み取りおよび書き込み要求に引き続き応答できるかどうか。(データのバックアップが必要です)
-
パーティション耐性: ほとんどの分散システムは複数のサブネットワークに分散しています。各サブネットワークはパーティションと呼ばれます。パーティションのフォールト トレランスとは、ゾーン間の通信が失敗する可能性があることを意味します。
CAP理論とは、分散ストレージシステムではせいぜい上記2点しか実現できないことを意味します。また、現在のネットワーク ハードウェアでは遅延やパケット損失などの問題が確実に発生するため、パーティション トレランスを避けることはできません。したがって、一貫性と可用性の間でトレードオフを行うことしかできず、これら 3 つの点を同時に保証できるシステムはありません。CPかAPのどちらかを選択します。

BASE定理
BASE は、CAP における一貫性と可用性の間のトレードオフの結果です。BASE は、大規模なインターネット システムの分散実践の結論から生まれ、CAP 定理に基づいて徐々に進化しています。その中心的な考え方は、たとえ強一貫性であっても、結果整合性を実現することはできませんが(強整合性)、各アプリケーションは自らのビジネス特性に応じて適切な方法を採用し、システムとして結果整合性を実現することができます(結果整合性)。次に、BASE の 3 つの要素を見てみましょう。
-
基本的に利用可能_
基本的な可用性とは、分散システムで障害が発生した場合、部分的な可用性が失われることが許容される、つまりコアの可用性が保証されることを意味します。
電子商取引のプロモーション中、トラフィックの急増に対応するために、一部のユーザーがダウングレード ページに誘導され、サービス層がダウングレード サービスのみを提供する場合があります。これは、一部の可用性が失われたことを反映しています。 -
ソフトな状態
ソフト状態とは、システム全体の可用性に影響を与えない中間状態をシステムに許可することを指します。分散ストレージでは、通常、1 つのデータに少なくとも 3 つのコピーがあり、異なるノード間でのコピーの同期を可能にする遅延は、ソフト ステートの具体化です。mysql レプリケーションの非同期レプリケーションもその現れです。
-
最終的には一貫性のある
最終的な整合性とは、システム内のすべてのデータ コピーが、一定期間後に最終的に整合性のある状態に到達できることを意味します。弱い整合性は強い整合性の反対であり、結果整合性は弱い整合性の特殊なケースです。
BASE モデルは、従来の ACID モデルの逆です。ACID とは異なり、BASE は可用性を得るために高い一貫性を犠牲にすることに重点を置いています。最終的に一貫性がある限り、データは一定期間不整合であっても許容されます。
2. 分散トランザクションのソリューション
https://www.processon.com/view/link/62a1ddce0791293ad1a552c0
分散トランザクションは、エンタープライズ統合における技術的な問題であり、あらゆる分散システム アーキテクチャに関係しており、特にマイクロサービス アーキテクチャではほぼ避けられない問題と言えます。
主流のソリューションは次のとおりです。
- XA プロトコルに基づく 2 フェーズ コミット (2PC)
- 柔軟なトランザクション - TCC トランザクション
- 柔軟なトランザクション - 結果整合性
2.1 2 フェーズコミット (2PC)
2PC は、トランザクション プロセス全体を準備フェーズとコミット フェーズの 2 つのフェーズに分割する 2 フェーズ コミット プロトコルです。2 は 2 つのフェーズを指し、P は準備フェーズ、C はコミット フェーズを指します。
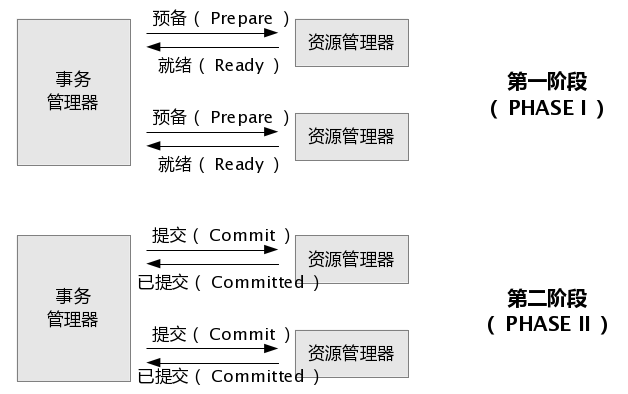
第 1 段階: トランザクション コーディネーターは、トランザクションに関与する各データベースにこの操作を事前コミットし、送信できるかどうかを反映するよう要求します。
フェーズ 2: トランザクション コーディネーターは、各データベースにデータを送信するように要求します。
その中で、いずれかのデータベースがこのコミットを拒否した場合、すべてのデータベースはこのトランザクション内の情報の一部をロールバックする必要があります。
現在、すべての主流データベースは 2PC [2 フェーズ コミット] をサポートしています。
XA は 2 フェーズ コミット プロトコルであり、XA トランザクションとも呼ばれます。
MySQL はバージョン 5.5 からサポートされ、SQL Server 2005 がサポートされ、Oracle 7 がサポートされています。
一般に、XA プロトコルは比較的単純であり、商用データベースが XA プロトコルを実装すると、分散トランザクションの使用コストは比較的低くなります。ただし、XA には致命的な欠点もあります。つまり、そのパフォーマンスが理想的ではないということです。特にトランザクション注文リンクでは、同時実行量が非常に多くなる場合が多く、XA は同時実行性の高いシナリオには対応できません。
- 2 フェーズ コミットにはノード間で複数のネットワーク通信が含まれるため、通信時間が長すぎます。
- トランザクション時間が相対的に長くなり、リソースがロックされている時間も長くなり、リソースの待ち時間も大幅に増加しています。
- 現在、XA は商用データベースで理想的にサポートされていますが、mysql データベースでは理想的にサポートされていません。mysql の XA 実装では準備ステージのログが記録されず、マスター/スタンバイ スイッチによりマスター データベースとスタンバイ データベースの間でデータの不整合が発生します。また、多くの nosql は XA をサポートしていないため、XA のアプリケーション シナリオは非常に限られています。
2.2 TCC補償取引
TCC は、プログラムによる分散トランザクション ソリューションです。
TCC は実際に採用されている補償メカニズムであり、その中心的な考え方は、各操作に対して、対応する確認および補償 (キャンセル) 操作を登録する必要があるということです。TCC モードでは、スレーブ サービスが Try、confirm、および Cancel の 3 つのインターフェイスを提供する必要があります。
- 試行: 主に業務システムの検出とリソースの確保を目的とします。
- 確認: ビジネスは実際にはビジネスチェックなしで実行されます。試行フェーズで予約されたビジネスリソースのみが使用されます。確認操作は冪等性を満たします。
- キャンセル: 試行フェーズで予約されたビジネス リソースを解放します。キャンセル操作は冪等性を満たします。
TCC ビジネス全体は 2 つの段階で完了します。

第 1 段階: メイン ビジネス サービスは、すべてのスレーブ ビジネスの try 操作をそれぞれ呼び出し、すべてのスレーブ ビジネス サービスをアクティビティ マネージャーに登録します。ビジネス サービスからのすべての試行操作が正常に呼び出されるか、特定のビジネス サービスからの試行操作が失敗すると、第 2 フェーズに入ります。
フェーズ 2: アクティビティ マネージャーは、最初のフェーズの実行結果に基づいて確認またはキャンセル操作を実行します。最初のフェーズのすべての試行操作が成功すると、アクティビティー・マネージャーはすべてのスレーブ・ビジネス・アクティビティーの確認操作を呼び出します。それ以外の場合は、すべてのスレーブ ビジネス サービスのキャンセル操作が呼び出されます。
たとえば、ボブがスミスに 100 元を送金したい場合、考えはおそらく次のようになります。
ネイティブ メソッドがあり、それが次に呼び出されます。
- まず、Try ステージでは、Bob に十分なお金があるかどうかを確認し、100 元をロックし、Smith のアカウントを凍結する必要があります。
- 確認ステージでは、リモートで呼び出された転送操作が実行され、転送は正常に解凍されます。
- 2 番目のステップの実行が成功すると転送は成功し、2 番目のステップの実行が失敗した場合は、リモート凍結インターフェイスに対応する凍結解除メソッド (Cancel) が呼び出されます。
欠点:
- Canfirm と Cancel の冪等性を保証するのは困難です。
- この方法には多くの欠点があるため、ロールバック キャンセルが非常に簡単で、依存するサービスが非常に少ない非常に単純なシナリオでない限り、複雑なシナリオでは一般に推奨されません。
- この実装方法では、コード量が多くなり、結合度が高くなります。また、簡単にロールバックできないビジネスが多数あるため、それは非常に限られており、シリアル サービスが多数ある場合、ロールバックのコストが高くなりすぎます。
実際、多くの大企業は独自の TCC 分散トランザクション フレームワークを開発し、それを社内のみで使用しています。国内オープンソース: ByteTCC、TCC トランザクション、Himly。
2.3 メッセージトランザクション + 最終整合性
メッセージ ミドルウェアに基づく 2 段階コミットは、分散トランザクションをメッセージ トランザクション (システム A のローカル操作 + メッセージ送信) + システム B のローカル操作 (システム B の操作が構成される) に分割するために、同時実行性の高いシナリオでよく使用されます。メッセージの数 ドライバーは、メッセージ トランザクションが成功している限り、A 操作は成功し、メッセージを送信する必要があります。このとき、B はローカル操作を実行するためにメッセージを受信します。ローカル操作が失敗した場合、メッセージはB のオペレーションが成功するまで再投資されることを偽装し、A と B 間の分散取引が効果的に実現されます。
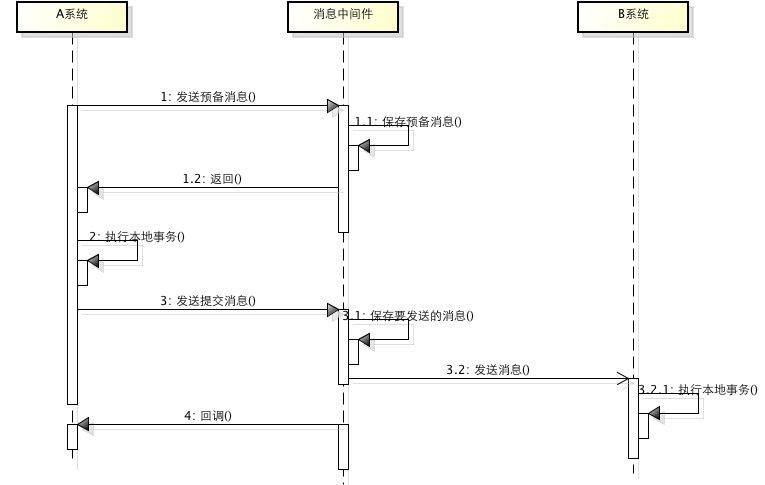
上記のスキームでは A と B の操作を完了できますが、A と B は厳密には一貫性がありませんが、最終的には一貫性があるため、パフォーマンスの大幅な向上と引き換えに一貫性を犠牲にしています。もちろん、この遊び方にもリスクがあり、B の実行に失敗した場合には整合性が崩れてしまいます。
高い同時実行性と最終的な一貫性の実現に適しています
低同時実行性は基本的に同じです: 2 フェーズ送信
高い同時実行性と強力な一貫性: 解決策なし
3.セット
分散トランザクション ソリューション Seata
公式ウェブサイト:https://seata.io/zh-cn/docs/overview/what-is-seata.html
GitHub: https://github.com/seta/seta
3.1 Seataサービスのインストール
まず、seata の依存関係をインポートし、依存バージョンに基づいて対応する Seata インストール ファイルをダウンロードします。
https://github.com/seata/seata/releases
ダウンロード後、解凍して conf フォルダーに入り、registration.conf ファイルを通じて構成センターと登録センターの情報を更新します。
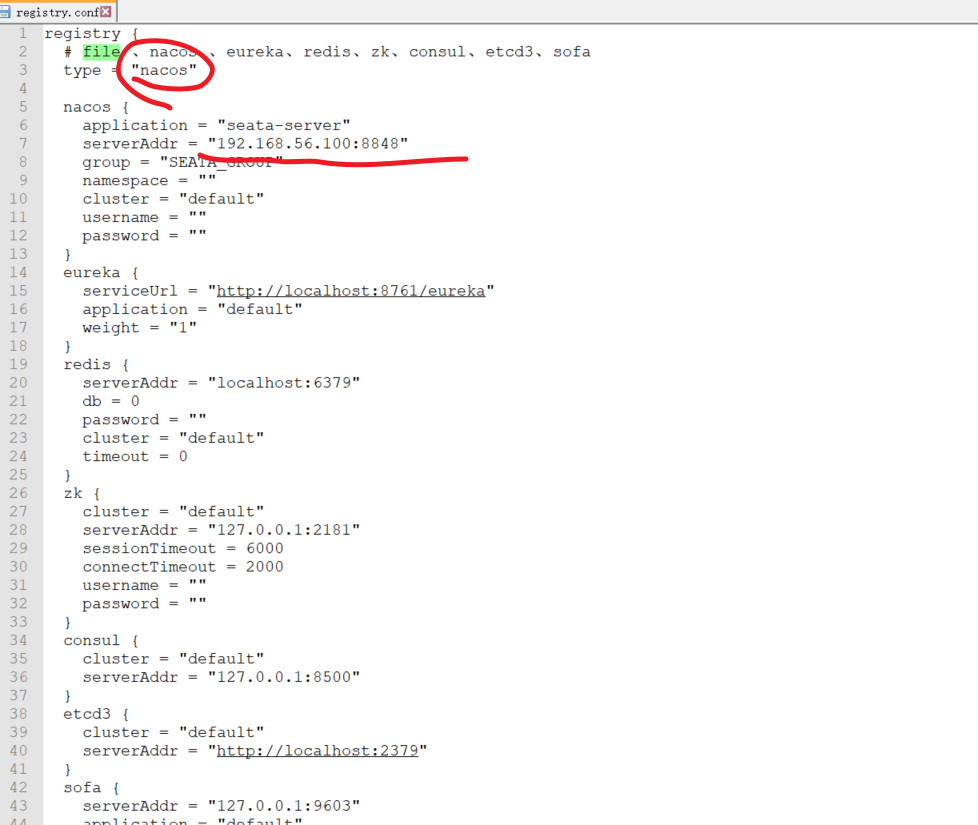
次に、bin ディレクトリに入り、seata-server.bat ファイルを通じてサービスを開始します。
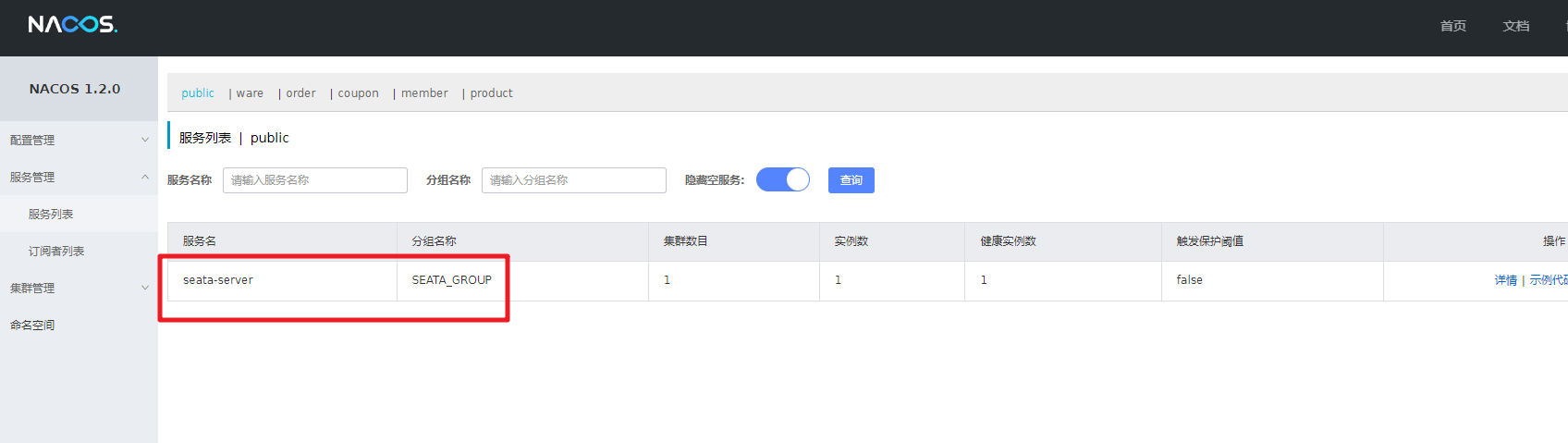
次に、nacos 登録センターに入り、対応するサービスを確認します。これは OK を意味します。
3.2 プロジェクト統合 Seata
次に、Seata をモール プロジェクトに統合する方法を見てみましょう。最初は file.conf ファイルです。
ネットワーク送信設定:
transport {
# tcp udt unix-domain-socket
type = "TCP"
#NIO NATIVE
server = "NIO"
#enable heartbeat
heartbeat = true
#thread factory for netty
thread-factory {
boss-thread-prefix = "NettyBoss"
worker-thread-prefix = "NettyServerNIOWorker"
server-executor-thread-prefix = "NettyServerBizHandler"
share-boss-worker = false
client-selector-thread-prefix = "NettyClientSelector"
client-selector-thread-size = 1
client-worker-thread-prefix = "NettyClientWorkerThread"
# netty boss thread size,will not be used for UDT
boss-thread-size = 1
#auto default pin or 8
worker-thread-size = 8
}
}
トランザクション ログ ストレージ構成: 構成のこの部分は、seata-server でのみ使用されます。db を選択した場合は、seata.sql で使用してください。
## transaction log store, only used in seata-server
store {
## store mode: file、db
mode = "file"
## file store property
file {
## store location dir
dir = "sessionStore"
}
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
driver-class-name = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
}
}
※ seataサーバーに登録されている現在のマイクロサービスの情報構成:
service {
# 事务分组,默认:${spring.applicaiton.name}-fescar-service-group,可以随便写
vgroup_mapping.${spring.application.name}-fescar-service-group = "default"
# 仅支持单节点,不要配置多地址,这里的default要和事务分组的值一致
default.grouplist = "127.0.0.1:8091" #seata-server服务器地址,默认是8091
# 降级,当前不支持
enableDegrade = false
# 禁用全局事务
disableGlobalTransaction = false
}
クライアント関連の作業の仕組み
client {
rm {
async.commit.buffer.limit = 10000
lock {
retry.internal = 10
retry.times = 30
retry.policy.branch-rollback-on-conflict = true
}
report.retry.count = 5
table.meta.check.enable = false
report.success.enable = true
}
tm {
commit.retry.count = 5
rollback.retry.count = 5
}
undo {
data.validation = true
log.serialization = "jackson"
log.table = "undo_log"
}
log {
exceptionRate = 100
}
support {
# auto proxy the DataSource bean
spring.datasource.autoproxy = false
}
}
まず、2 つの構成ファイル registry.conf と file.conf を、対応するプロジェクトのプロパティ ファイル ディレクトリにコピーする必要があります。
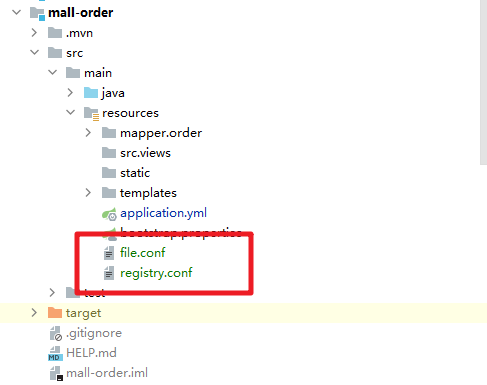
次に、プロパティ ファイルで tx-service-group 情報を定義します。
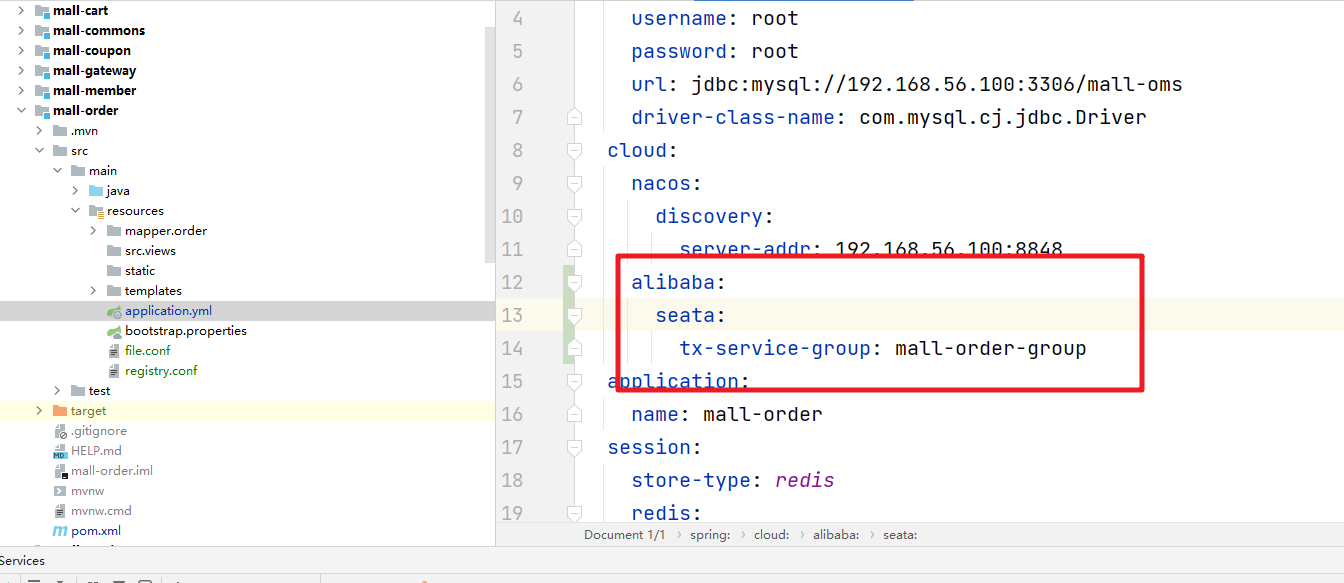
次に、file.conf にサービス属性を追加し、設定した tx-service-group 情報を関連付けます。バージョン 1.1 以降、プロパティはキャメルケースの名前に更新されたことに注意してください。
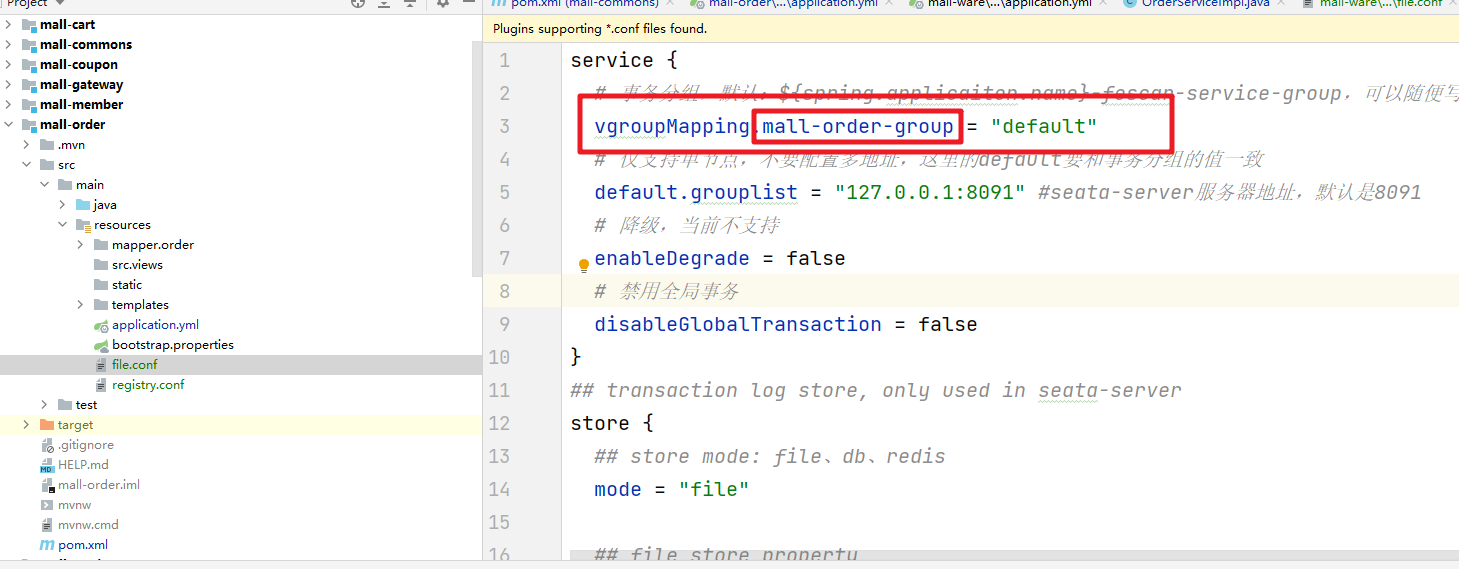
file.conf を完成させる
service {
# 事务分组,默认:${spring.applicaiton.name}-fescar-service-group,可以随便写
vgroupMapping.mall-order-group = "default"
# 仅支持单节点,不要配置多地址,这里的default要和事务分组的值一致
default.grouplist = "127.0.0.1:8091" #seata-server服务器地址,默认是8091
# 降级,当前不支持
enableDegrade = false
# 禁用全局事务
disableGlobalTransaction = false
}
## transaction log store, only used in seata-server
store {
## store mode: file、db、redis
mode = "file"
## file store property
file {
## store location dir
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
maxBranchSessionSize = 16384
# globe session size , if exceeded throws exceptions
maxGlobalSessionSize = 512
# file buffer size , if exceeded allocate new buffer
fileWriteBufferCacheSize = 16384
# when recover batch read size
sessionReloadReadSize = 100
# async, sync
flushDiskMode = async
}
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "mysql"
driverClassName = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
## redis store property
redis {
host = "127.0.0.1"
port = "6379"
password = ""
database = "0"
minConn = 1
maxConn = 10
queryLimit = 100
}
}
完全なregistry.conf
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "192.168.56.100:8848"
group = "SEATA_GROUP"
namespace = ""
cluster = "default"
username = ""
password = ""
}
eureka {
serviceUrl = "http://localhost:8761/eureka"
application = "default"
weight = "1"
}
redis {
serverAddr = "localhost:6379"
db = 0
password = ""
cluster = "default"
timeout = 0
}
zk {
cluster = "default"
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
consul {
cluster = "default"
serverAddr = "127.0.0.1:8500"
}
etcd3 {
cluster = "default"
serverAddr = "http://localhost:2379"
}
sofa {
serverAddr = "127.0.0.1:9603"
application = "default"
region = "DEFAULT_ZONE"
datacenter = "DefaultDataCenter"
cluster = "default"
group = "SEATA_GROUP"
addressWaitTime = "3000"
}
file {
name = "file.conf"
}
}
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "file"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
}
consul {
serverAddr = "127.0.0.1:8500"
}
apollo {
appId = "seata-server"
apolloMeta = "http://192.168.1.204:8801"
namespace = "application"
}
zk {
serverAddr = "127.0.0.1:2181"
sessionTimeout = 6000
connectTimeout = 2000
username = ""
password = ""
}
etcd3 {
serverAddr = "http://localhost:2379"
}
file {
name = "file.conf"
}
}
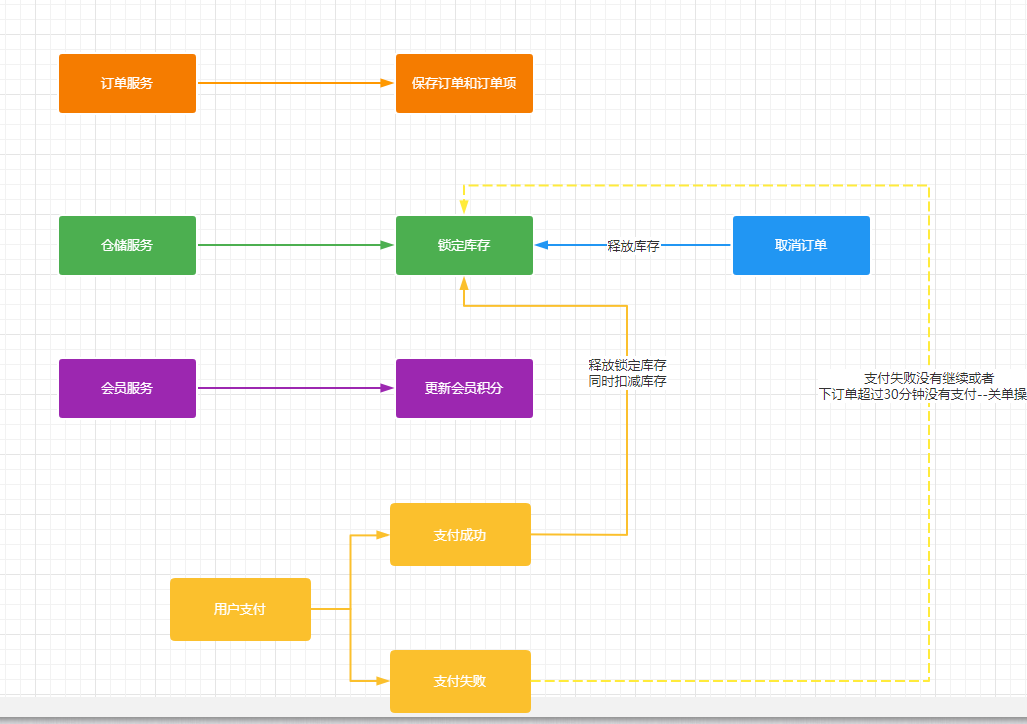
3.3 ケースデモンストレーション
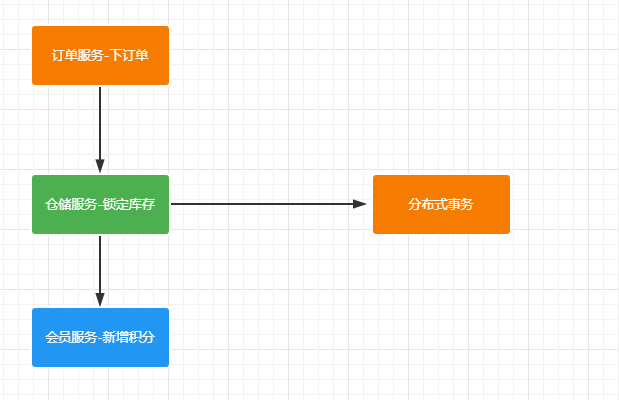
発注業務では、これまでの発注書の生成や在庫に固定されている商品の発注業務に加え、ポイントを調整するサービスを追加しました。算術例外の例として[1/0]を示します。在庫のロックは成功したが、会員ポイントの調整に失敗した場合、分散トランザクション管理のロジックにより、在庫のロック操作はロールバックされます。Seata 分散トランザクション管理は@GlobalTransactional
によって変更する必要があるため、メソッドにアノテーションを追加して、カスタム算術例外がスローされた後、中間のリモート呼び出しサービスのロック インベントリ操作もロールバックされるようにする必要があります。
@GlobalTransactional
@Transactional()
@Override
public OrderResponseVO submitOrder(OrderSubmitVO vo) throws NoStockExecption {
...}

4. 注文をキャンセルする
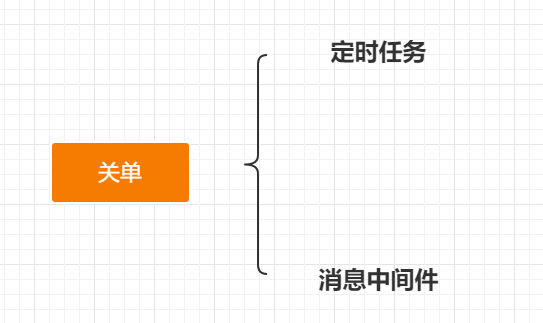
注文をキャンセルする場合の状況:
- 注文後 30 分以上支払われない場合は、注文クローズ操作をトリガーする必要があります。
- 支払いに失敗しました。同じように注文を閉じる必要があります
実装方法: スケジュールされたタスクとメッセージ ミドルウェア スケジュールされたタスクは、システムのパフォーマンスに確実に影響を与えます。
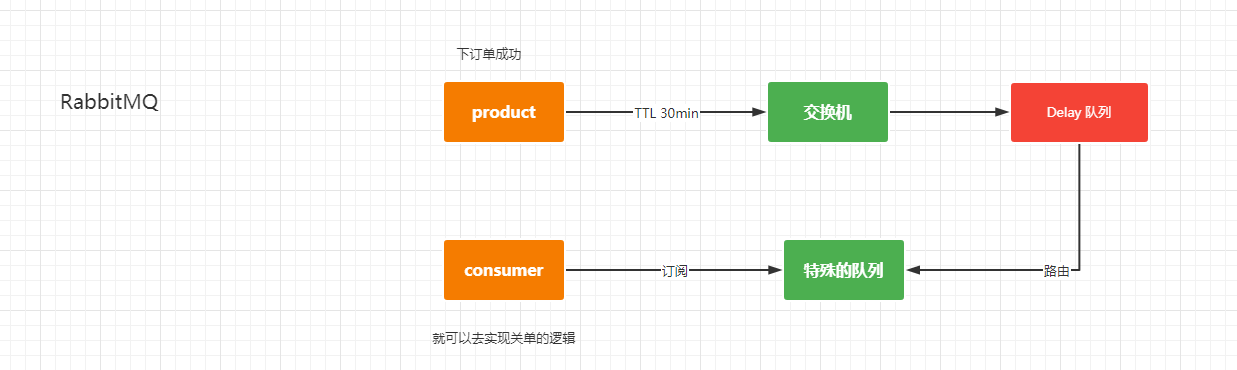
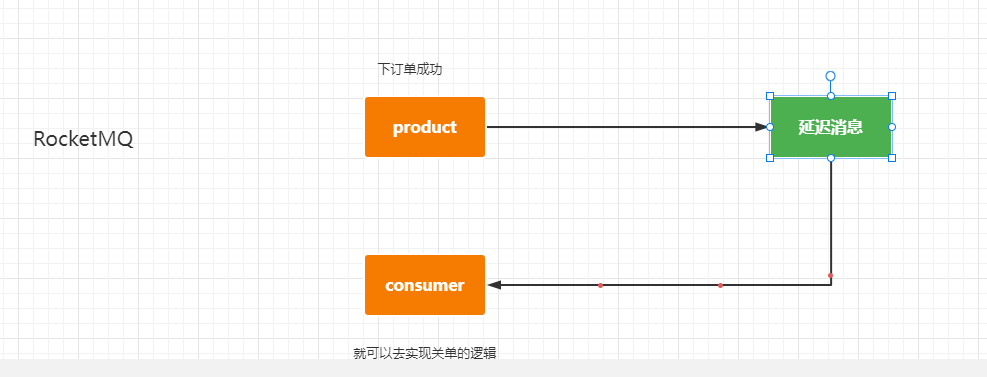
RocketMQ:https://github.com/apache/rocketmq/tree/master/docs/cn
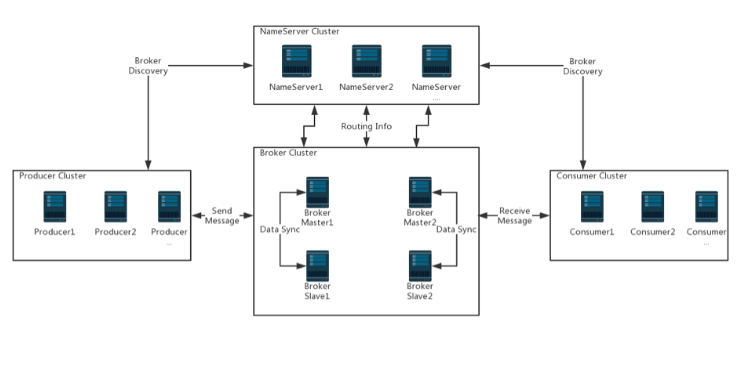
RocketMQ: Docker のインストール
ネームサーバーのインストール
docker pull rocketmqinc/rocketmq
保存ディレクトリを作成する
mkdir -p /mydata/docker/rocketmq/data/namesrv/logs /mydata/docker/rocketmq/data/namesrv/store
それからインストールします
docker run -d --restart=always --name rmqnamesrv --privileged=true -p 9876:9876 -v /docker/rocketmq/data/namesrv/logs:/root/logs -v /docker/rocketmq/data/namesrv/store:/root/store -e "MAX_POSSIBLE_HEAP=100000000" rocketmqinc/rocketmq sh mqnamesrv
関連パラメータの説明
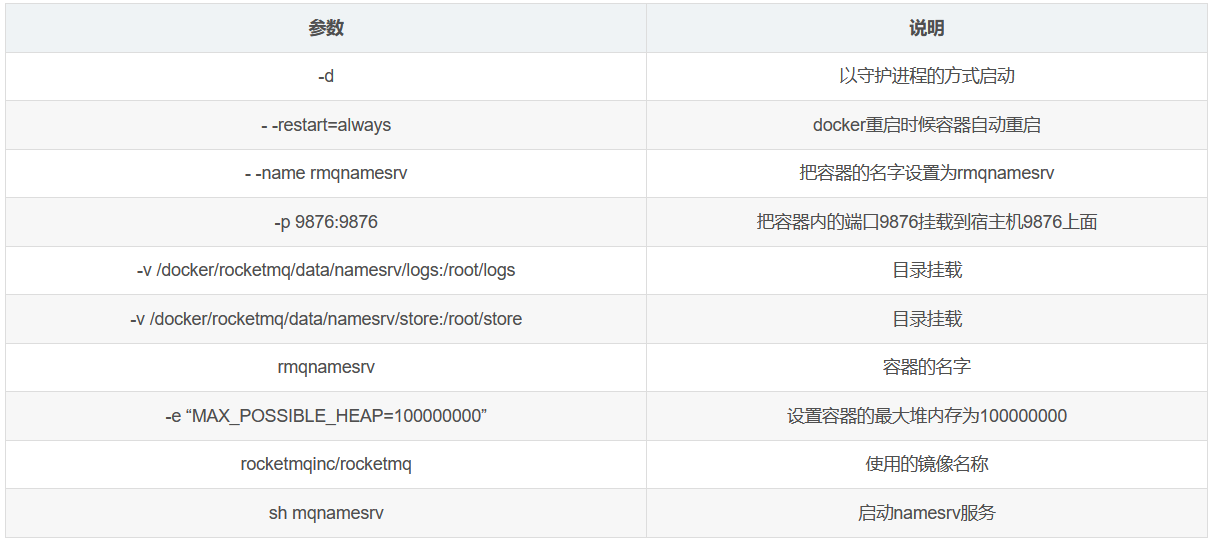
ブローカーのインストール
ボーダー構成: /mydata/rocketmq/conf/broker.conf で、broker.conf 構成ファイルを作成します。構成は次のとおりです。
# 所属集群名称,如果节点较多可以配置多个
brokerClusterName = DefaultCluster
#broker名称,master和slave使用相同的名称,表明他们的主从关系
brokerName = broker-a
#0表示Master,大于0表示不同的
slave brokerId = 0
#表示几点做消息删除动作,默认是凌晨4点
deleteWhen = 04
#在磁盘上保留消息的时长,单位是小时
fileReservedTime = 48
#有三个值:SYNC_MASTER,ASYNC_MASTER,SLAVE;同步和异步表示Master和Slave之间同步数据的机 制;
brokerRole = ASYNC_MASTER
#刷盘策略,取值为:ASYNC_FLUSH,SYNC_FLUSH表示同步刷盘和异步刷盘;SYNC_FLUSH消息写入磁盘后 才返回成功状态,ASYNC_FLUSH不需要;
flushDiskType = ASYNC_FLUSH
# 设置broker节点所在服务器的ip地址
brokerIP1 = 192.168.100.130
#剩余磁盘比例
diskMaxUsedSpaceRatio=99
インストール:
docker run -d --restart=always --name rmqbroker --link rmqnamesrv:namesrv -p 10911:10911 -p 10909:10909 --privileged=true -v /docker/rocketmq/data/broker/logs:/root/logs -v /docker/rocketmq/data/broker/store:/root/store -v /docker/rocketmq/conf/broker.conf:/opt/rocketmq-4.4.0/conf/broker.conf -e "NAMESRV_ADDR=namesrv:9876" -e "MAX_POSSIBLE_HEAP=200000000" rocketmqinc/rocketmq sh mqbroker -c /opt/rocketmq-4.4.0/conf/broker.conf
関連するパラメータの説明:
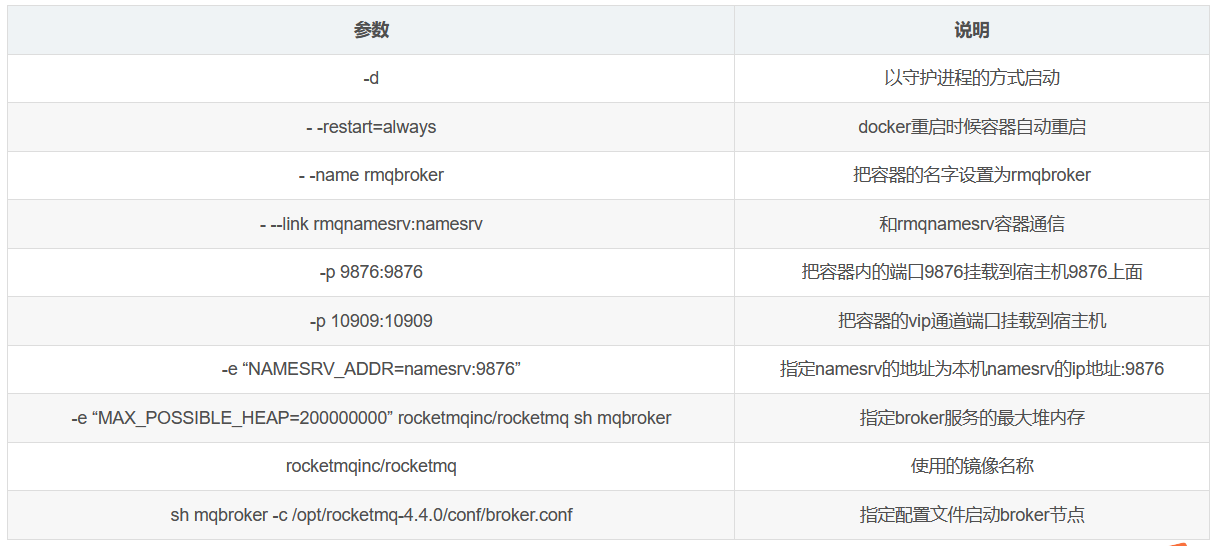
コンソールをインストールします。
イメージをプルする
docker pull pangliang/rocketmq-console-ng
コンソールのインストール:
docker run -d --restart=always --name rmqadmin -e "JAVA_OPTS=-Drocketmq.namesrv.addr=192.168.56.100:9876 -Dcom.rocketmq.sendMessageWithVIPChannel=false" -p 8080:8080 pangliang/rocketmq-console-ng
テストにアクセス: http://192.168.56.100:8080
5. 在庫のリリース
在庫をリリースする必要がある状況:
- 注文後に手動で注文をキャンセルするか、注文の超過料金を支払う
- 支払いが成功すると在庫が解放され、在庫が更新されます。
SpringBoot は RocketMQ を統合します
対応する依存関係を追加する必要があります
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-spring-boot-starter</artifactId>
<version>2.2.2</version>
</dependency>
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-client</artifactId>
<version>4.9.1</version>
</dependency>
対応する構成情報を追加する必要があります
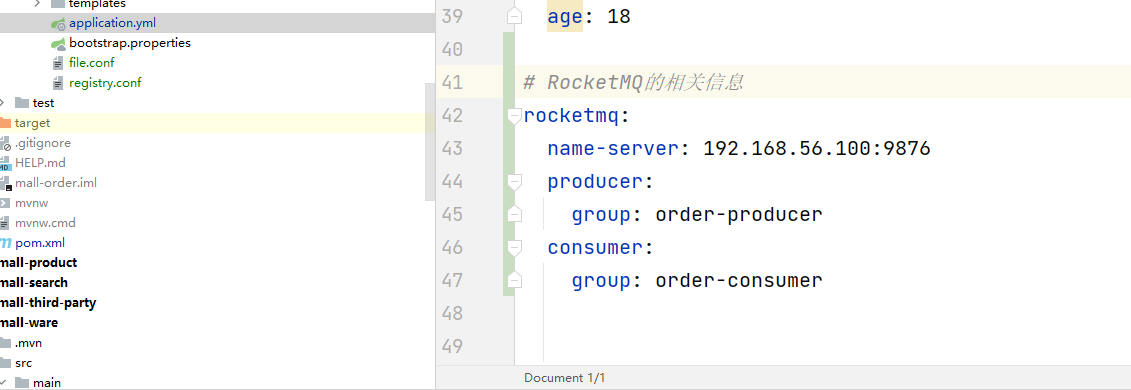
デモ例
シナリオ:フロントエンドは、クリックして注文を送信し、注文送信インターフェイス サービスを呼び出し、送信成功ページを返します。サービスでは、MQ メッセージ プロデューサを呼び出して、定期的に注文番号を送信します。送信を遅らせて、何秒後、何分後に指定します (レベルに応じた時間は次のとおりです、合計 18 レベル、詳細は MQ 公式 Web サイトを参照してください、最高は 2 時間です) トピックのトピックに配信されます、消費者の意見を聞いてから、完了できます。 30分が経過していない場合 ページ上で支払いが行われた場合、注文のキャンセルとクローズのビジネス ロジックが消費者サービスに必要であり、対応するトピックトピックからメッセージ、つまり注文番号を取得できます。注文番号を取得した後、関連する注文業務が実行されます。
次に、対応するメッセージプロデューサーを定義します
渡されるパラメータ: orderSN 注文番号
syncSend 同期送信メソッドのパラメータ: トピック要素テーマ、注文番号はメッセージにカプセル化され、タイムアウトは 5 秒、レベル 4 は、情報が 30 秒後にトピックに配信されることを意味します。
@Component
public class OrderMsgProducer {
@Autowired
private RocketMQTemplate rocketMQTemplate;
public void sendOrderMessage(String orderSN){
rocketMQTemplate.syncSend(OrderConstant.ROCKETMQ_ORDER_TOPIC, MessageBuilder.withPayload(orderSN).build(),5000,4);
}
}
次に、遅延メッセージのコンシューマーがあり、対応するリスナーを通じて処理する必要があります。
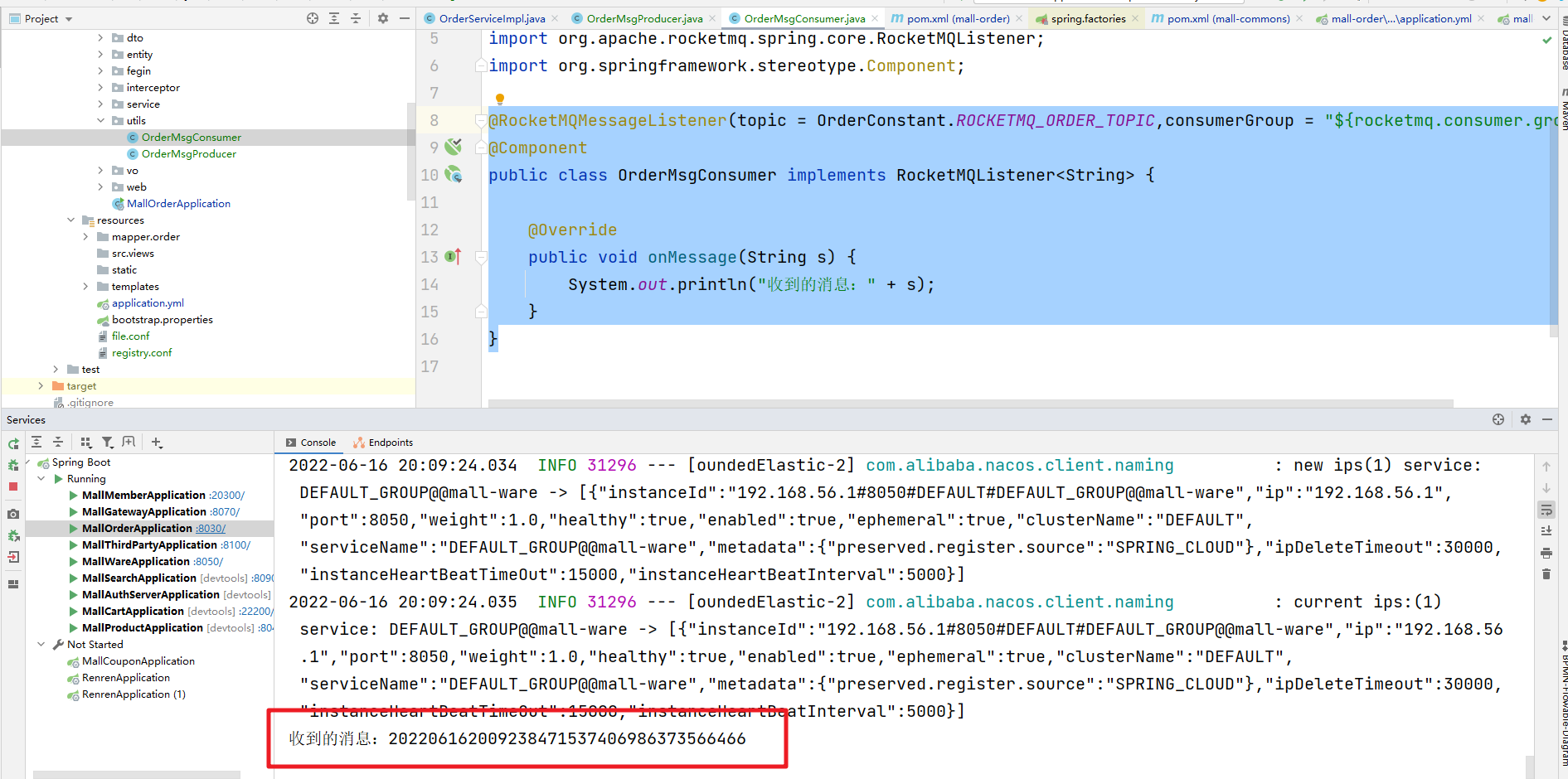
@RocketMQMessageListener(topic = OrderConstant.ROCKETMQ_ORDER_TOPIC,consumerGroup = "${rocketmq.consumer.group}")
@Component
public class OrderMsgConsumer implements RocketMQListener<String> {
@Override
public void onMessage(String s) {
System.out.println("收到的消息:" + s);
}
}
サービスインターフェース
情報を送信するための呼び出しを行います:
orderMsgProducer.sendOrderMessage(orderCreateTO.getOrderEntity().getOrderSn());
@Autowired
OrderMsgProducer orderMsgProducer;
@Transactional()
@Override
public OrderResponseVO submitOrder(OrderSubmitVO vo) throws NoStockExecption {
// 需要返回响应的对象
OrderResponseVO responseVO = new OrderResponseVO();
// 获取当前登录的用户信息
MemberVO memberVO = (MemberVO) AuthInterceptor.threadLocal.get();
// 1.验证是否重复提交 保证Redis中的token 的查询和删除是一个原子性操作
String key = OrderConstant.ORDER_TOKEN_PREFIX+":"+memberVO.getId();
String script = "if redis.call('get',KEYS[1])==ARGV[1] then return redis.call('del',KEYS[1]) else return 0 end";
Long result = redisTemplate.execute(new DefaultRedisScript<Long>(script, Long.class)
, Arrays.asList(key)
, vo.getOrderToken());
if(result == 0){
// 表示验证失败 说明是重复提交
responseVO.setCode(1);
return responseVO;
}
// 2.创建订单和订单项信息
OrderCreateTO orderCreateTO = createOrder(vo);
responseVO.setOrderEntity(orderCreateTO.getOrderEntity());
// 3.保存订单信息
saveOrder(orderCreateTO);
// 4.锁定库存信息
// 订单号 SKU_ID SKU_NAME 商品数量
// 封装 WareSkuLockVO 对象
lockWareSkuStock(responseVO, orderCreateTO);
// 5.同步更新用户的会员积分
// int i = 1 / 0;
// 订单成功后需要给 消息中间件发送延迟30分钟的关单消息
orderMsgProducer.sendOrderMessage(orderCreateTO.getOrderEntity().getOrderSn());
return responseVO;
}
次に、実行の効果があります