0 はじめに
今日は先輩がマシンビジョン、QRコード/バーコードの検出と認識に関する最終プロジェクトを紹介します。
機械学習に基づく QR コードの認識と検出 - opencv QR コードの認識と検出マシン ビジョン
1 QRコード検出
オブジェクト検出は、デジタル画像内の特定の種類のオブジェクトの位置を自動的に検出します。2 つの基本的な検出フレームワークがあります。
1 つは、スライディング ウィンドウ単位で画像をスキャンし、スキャンされた各サブ画像から特徴を抽出し、学習された分類器を使用して特徴を分類し、サブ画像が検出されている特定のオブジェクトであるかどうかを判断することです。物体検出に関する問題の 1 つは、画像内の物体の位置とスケールが不明であることです。このアルゴリズムには、さまざまな位置や大きさの物体を検出できることが求められ、このような特性を位置非依存性、スケール非依存性と呼びます。このような特性を実現するための一般的な方法は、マルチスケール フレームワークを使用することです。つまり、元の画像をスケーリングしてさまざまなサイズの画像シーケンスのセットを生成し、固定サイズ W×H のスライディング ウィンドウを使用します。シーケンスの各画像において、検出アルゴリズムは、スライディング ウィンドウによってキャプチャされた画像サブウィンドウ内にターゲット オブジェクトがあるかどうかを毎回判断します。スライディング ウィンドウは位置の独立性を解決し、画像シーケンスには少なくとも 1 つの画像が存在し、それに含まれる対象オブジェクトのスケールはスライディング ウィンドウのスケールに一致する、このような画像ピラミッド シーケンスはスケールの独立性を解決します。
もう一つは、画像全体から特徴点を抽出し、抽出した特徴点のみを分類する方法である。
したがって、上級クラスメートは、オブジェクト検出方法を 2 つのカテゴリに分類します。スライディング ウィンドウに基づくオブジェクト検出と、特徴点に基づくオブジェクト検出です。
どの方法を使用する場合でも、プロセス全体は、特徴抽出と特徴分類という 2 つの主要な段階に分けることができます。つまり、物体検出における主な問題は、どの機能を使用するか、どの分類子を使用するかということです。
物体検出の難しさは、限られたトレーニング セットを使用して、堅牢でさまざまな状況に適用できる分類器を学習する方法にあります。ここで言及されるさまざまな状況には、画像内のオブジェクトのサイズの違い、照明条件の違いによる画像の明暗の違い、画像内のオブジェクトの回転や遠近の可能性、類似したオブジェクト間の違いが含まれます。
ここでは、先輩が位置決め QR コード/バーコードを例として、機械学習に基づくオブジェクト検出の一般的なアルゴリズム プロセスを簡単に説明します。
2 アルゴリズム実装プロセス
アルゴリズムのフローチャートを以下に示します。
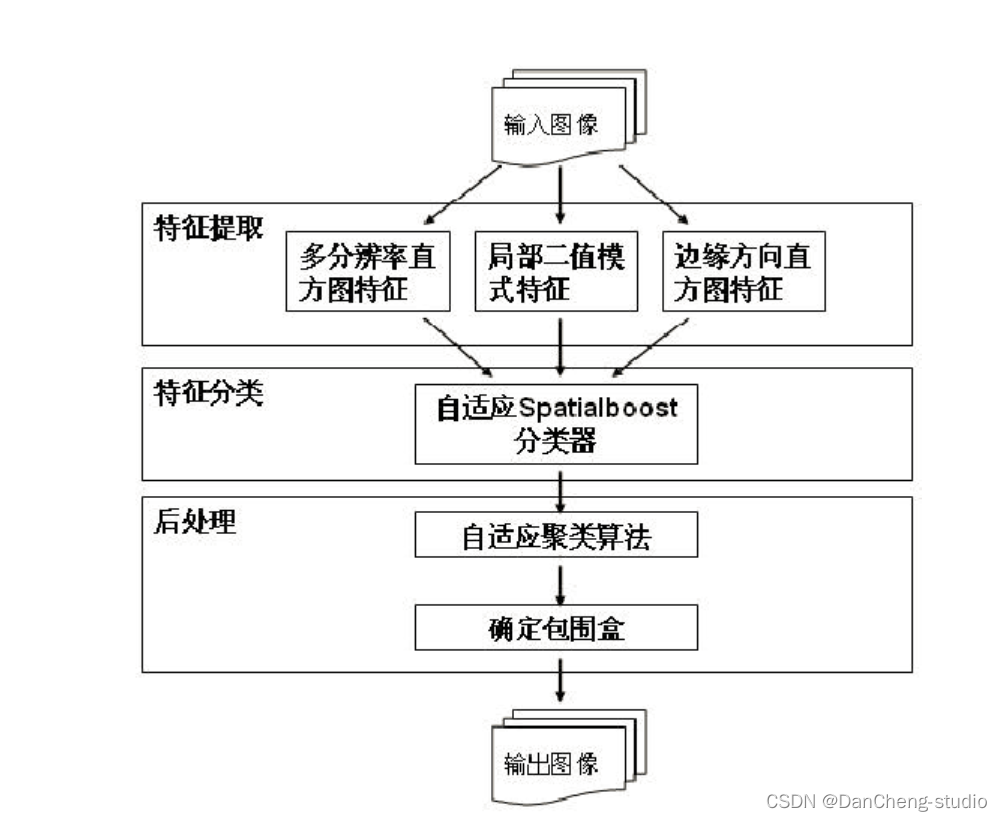
まず、入力画像を 25×25 の画像サブブロックに分割します。画像サブブロックは、特徴抽出と特徴分類の 2 つのモジュールの基本的な処理オブジェクトとして使用され、つまり、画像サブブロックからテクスチャ特徴が抽出されます。ブロックは 2 次元バーコードの一部です。
特徴抽出モジュールでは、テクスチャ特徴抽出アルゴリズムを用いて、元の入力画像から多重解像度ヒストグラム特徴、ローカルバイナリパターン特徴、エッジ方向ヒストグラム特徴を抽出しますが、これら3つのテクスチャ特徴の表現形式はいずれも1次元です。配列。これら 3 つの配列を、後続の分類モジュールの入力として 1 次元配列に接続します。
特徴を分類するとき、背景に属するすべての画像サブブロックを削除しながら、2D バーコードに属するすべての画像サブブロックを保持したいと考えています。このモジュールでは、適応型 Spatialboost アルゴリズムを使用します。
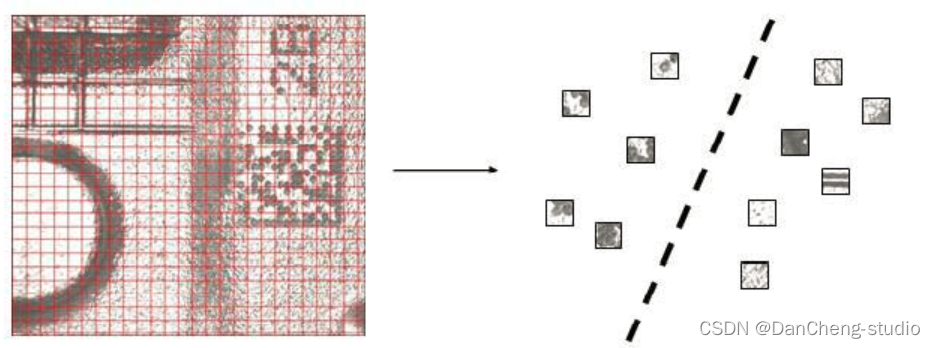
以下の図は、このステップの処理後の理想的な出力結果を示しています。図内でマークされた小さな四角は、それらが 2 次元バーコードの一部であることを示しています。

3 特徴抽出
画像のテクスチャ特徴は、オブジェクトの固有の属性を記述し、他のオブジェクトと区別することができます。テクスチャの特徴は一般に、空間領域と周波数領域の 2 つのカテゴリに分類できます。この記事のアルゴリズムで使用するテクスチャ特徴はすべて空間ドメイン テクスチャ特徴であり、局所特徴でもあり、多重解像度ヒストグラム特徴、ローカル バイナリ パターン特徴、およびエッジ方向ヒストグラム特徴です。
多重解像度のヒストグラム機能は回転に依存しません。このテクスチャ フィーチャは、グレースケール ヒストグラム フィーチャの簡単な計算と便利な保存という特性を保持しています。同時に、テクスチャの局所的な情報を記述することができ、従来のグレースケール ヒストグラム機能の欠点を補うことができます。
ローカルバイナリパターン特徴量は、明暗や回転に依存しない特徴を有する、計算量の少ない局所特徴量である。エッジ方向ヒストグラム機能は、グローバル照明の変化とは無関係であり、2 次元バーコード テクスチャの幾何学的特徴を抽出できます。
4つの特徴分類
先輩が開発したアルゴリズムで使用される分類器は、Spatialboost アルゴリズムを改良した適応型 Spatialboost アルゴリズムです。この分類子の使用は、2D バーコードの特性とアルゴリズム フレームワークの特性によって決まります。元の入力画像を多数の固定サイズの画像サブブロックに分割するため、2 次元バーコードに属する画像サブブロックには強い空間相関があるか、または 2 次元バーコードに属するこれらの画像サブブロックが存在します。コードが隣接しています。同時に、画像サブブロックのサイズが小さいため、そこに含まれる情報量は比較的少なく、場合によっては、二次元バーコードに属する画像サブブロックと画像サブブロックを区別することが困難になる場合があります。背景に属するブロック (特徴空間内にあります。重複する可能性があります)。サブブロックの空間的接続を利用して、分類器に空間情報を追加できれば、分類器の精度の向上に役立ちます。
適応型 Spatialboost アルゴリズムは、テクスチャ特徴とサブブロックの空間的接続を同時に利用することができ、トレーニング プロセス中に、テクスチャ特徴と空間情報を適応的に組み合わせて分類器をトレーニングします。このように、現在処理されているサブブロックの分類結果は、それ自体のテクスチャ特徴に依存するだけでなく、周囲のサブブロックの分類結果とも密接に関連しています。背景に属する画像サブブロックのテクスチャ特徴が 2 次元バーコードに属する画像サブブロックに非常に近い場合でも、隣接する背景サブブロックを信頼して正確に分類できます。
5 後処理
特徴抽出と特徴分類の 2 つのモジュールの後、画像サブブロックの分類結果が得られますが、最終的に得られると期待されるのは 2 次元バーコードの境界ボックスです。私たちの設定では、適応型 Spatialboost 分類器は背景サブブロックの分類において非常に厳密であるため、この時点で、2D バーコードに属する画像サブブロックに対していくつかの検出漏れが発生します。

したがって、後処理モジュールでは、最初に適応クラスタリング アルゴリズムを使用して分類結果をさらに改善し、2 次元バーコード全体を正確にカバーします。特徴分類後に配置されたサブブロックのサイズは 25×25 で、これらのサブブロックを 10×10 の小さな正方形に分割します。次に、取得した 10×10 サブブロックをシードとして使用し、サブブロックのグレー値の分散を基準としてクラスタリングを実行します。クラスタリング時のしきい値は次のように設定されます。
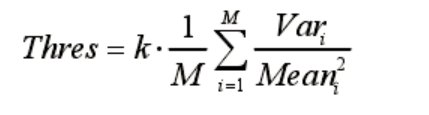
ここで、M はクラスタリングの開始時にシードとして使用されるサブブロックの数、k は調整係数、このアルゴリズムでは k は 0.5 に設定され、Var と Mean はそれぞれサブブロックのグレー値の平均と分散を表します。式 (3-1) から、各画像のクラスタリング閾値が適応的に計算されることがわかります。クラスタリングの開始時には、まずシードサブブロックから開始し、その周囲のサブブロックの濃淡値の分散を計算し、それがクラスタリングの閾値よりも大きい場合に、2次元バーコードに属するものとして識別します。を繰り返します。クラスター条件に適合する周囲のサブブロックがなくなるまでこのプロセスを繰り返します。図 3-5 は、クラスタリング アルゴリズムの結果の一部です。最初の行の画像は、特徴分類の結果です。2D バーコードの一部を正確に特定していますが、2D バーコード全体を完全にはカバーしていないため、役に立ちません。最終的な位置決めの境界ボックスの出力に。2行目はクラスタリングの結果ですが、小さなブロックが2次元バーコード全体をほぼ完全に覆っていることが分かりますが、このときこの小さなブロックを併合して平行四辺形にするのが非常に便利です。

クラスタリング後に配置された小さなブロックは基本的に 2 次元バーコード全体をカバーするため、最終的には配置された小さな境界ボックスを大きな境界ボックスにマージして、最終的な位置決め結果を出力するだけです。後処理プロセス全体を図に示します。

6 コードの実装
以下はバーコード検出効果のデモンストレーションです。
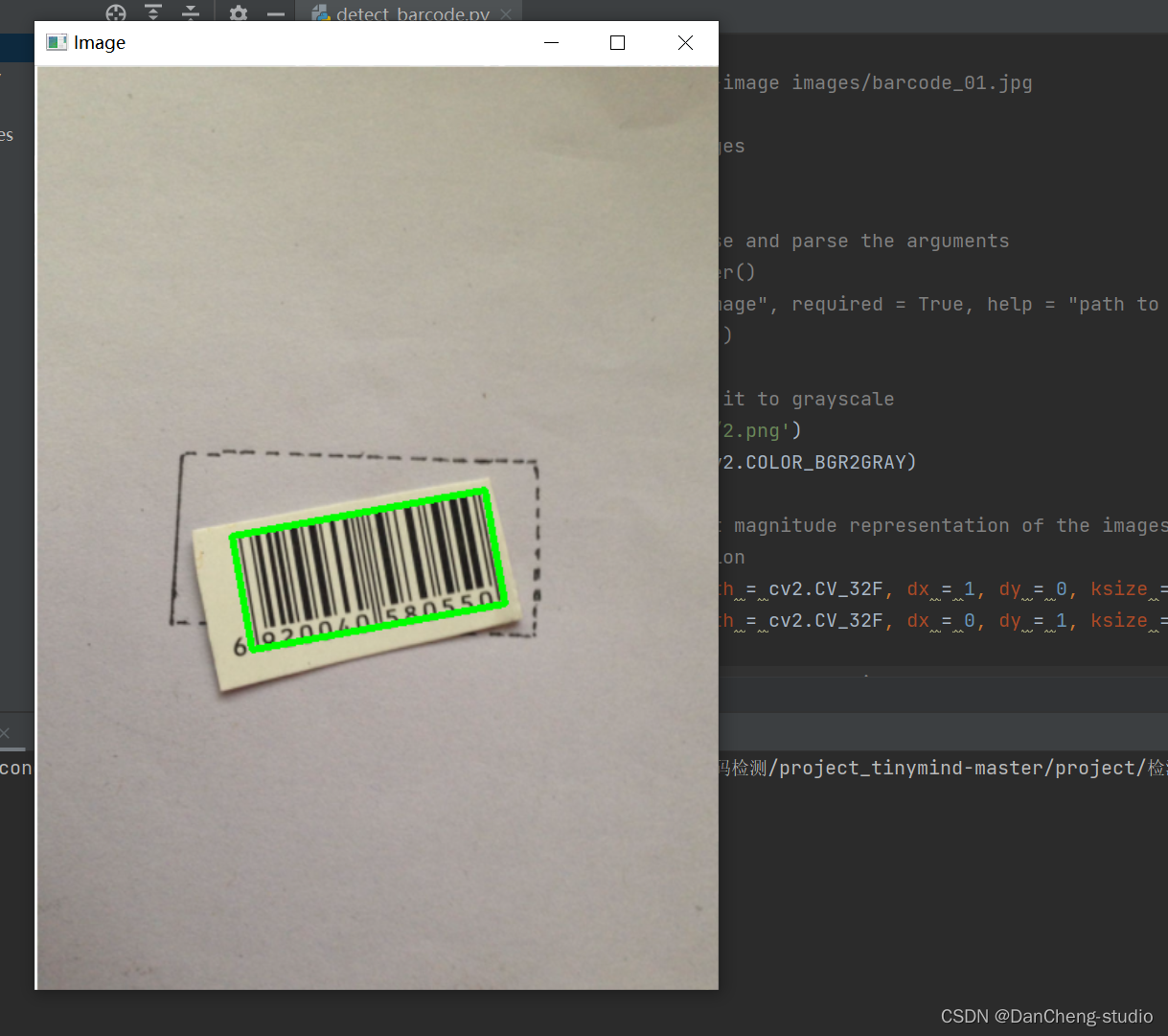
コード実装の重要な部分:
# import the necessary packages
import numpy as np
import argparse
import cv2
# construct the argument parse and parse the arguments
# ap = argparse.ArgumentParser()
# ap.add_argument("-i", "--image", required = True, help = "path to the image file")
# args = vars(ap.parse_args())
# load the image and convert it to grayscale
image = cv2.imread('./images/2.png')
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# compute the Scharr gradient magnitude representation of the images
# in both the x and y direction
gradX = cv2.Sobel(gray, ddepth = cv2.CV_32F, dx = 1, dy = 0, ksize = -1)
gradY = cv2.Sobel(gray, ddepth = cv2.CV_32F, dx = 0, dy = 1, ksize = -1)
# subtract the y-gradient from the x-gradient
gradient = cv2.subtract(gradX, gradY)
gradient = cv2.convertScaleAbs(gradient)
# blur and threshold the image
blurred = cv2.blur(gradient, (9, 9))
(_, thresh) = cv2.threshold(blurred, 225, 255, cv2.THRESH_BINARY)
# construct a closing kernel and apply it to the thresholded image
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (21, 7))
closed = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, kernel)
# perform a series of erosions and dilations
closed = cv2.erode(closed, None, iterations = 4)
closed = cv2.dilate(closed, None, iterations = 4)
# find the contours in the thresholded image, then sort the contours
# by their area, keeping only the largest one
(cnts, _) = cv2.findContours(closed.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
c = sorted(cnts, key = cv2.contourArea, reverse = True)[0]
# compute the rotated bounding box of the largest contour
rect = cv2.minAreaRect(c)
box = np.int0(cv2.boxPoints(rect))