Java を使用する皆さん、普段のコーディング プロセスで、開発効率を向上させるために Java フレームワークを作成することを考えたことはありますか? しかし、フレームワークを書くときに途方に暮れたり、どこから始めればよいのかわかりません。アイデアがあってもその機能の技術的な詳細が理解できないか、アイデアがあっても実現できないかのどちらかです。これらの問題が発生した場合は、この記事を読んだ後、ChatGPT を使用して簡単な JAVA フレームワークを作成することもできます。
明確なアイデア
まず最初に、フレームワークがどのような問題を解決するのか、またどのような機能を備えているのかを明確にする必要があります。これは、ChatGPT がニーズをよりよく理解するのに役立ちます。
例: フロントエンドとバックエンドの分離の要件において、フロントエンドに返す必要がある列挙型クラスの記述が多すぎることがわかりました。従来の方法では、バックエンドが列挙型クラスのマッピングに基づいて各列挙値を説明にマッピングし、それをフロントエンドに返します。しかし今回は、フロントエンドによって返される必要がある列挙記述が多すぎます。このことで私も小さな友達も無力感を感じました。そこで、これらの列挙型クラスを自動的にスキャンしてキーと説明マップを生成し、最後にそれをコンテナーに配置するアノテーションを作成できないか考えました。
問題の解決: フロントエンドとバックエンドの分離プロセス中に、列挙キーの記述をフロントエンドにマップするコードを手動で記述する必要性を解決します。
特徴: フレームワークには、列挙型クラスで修飾された 3 つのフィールド name、key、desc を持つアノテーションがあります。フレームワークは、列挙マップを外部から取得するためのインターフェイスを提供する必要があります。
ChatGPTで通信する
ChatGPT を開始して、ビジョンとニーズを伝えます。初期コードを生成したり、構造を提案したり、一部のロジックを処理したりすることもできます。
フレームワークで解決すべき問題点とフレームワークの特徴を考えたら、次はフレームワークで解決すべき問題点と特徴を段落にまとめてChatGPTに送信します。
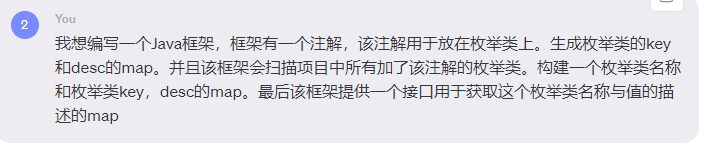
Chatgpt はおそらく私のニーズに応じてフレームワークのデモ バージョンを生成しました。想像していたものとまだ若干の違いがあることがわかりますが、列挙をクラスに乗せることだと思います。次に、列挙された属性は、name、key、および desc です。
name: 最も外側のマップの列挙マップのキーを表します。
key: 列挙のキーまたは値フィールドを表します。
desc: 列挙型の説明フィールドを表します。
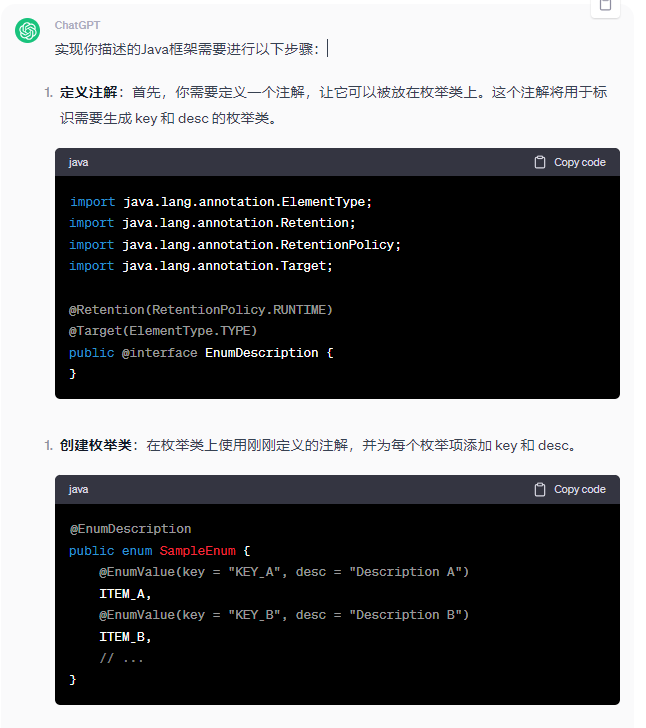
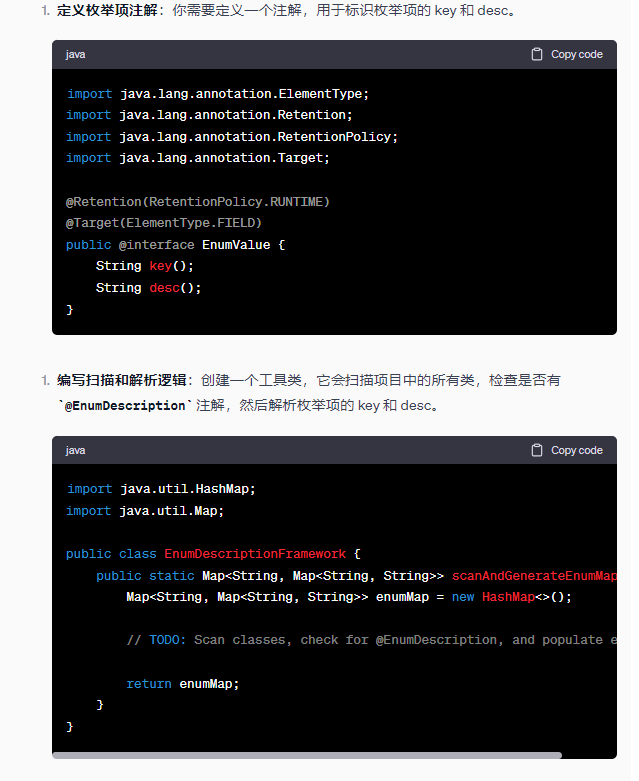
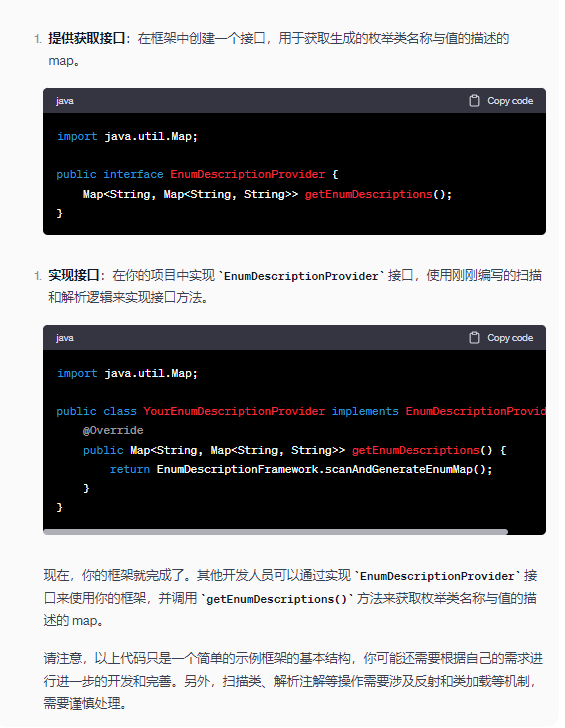
綿密なインタラクション
ChatGPT とさらに深く会話し、コードの最適化、例外処理などについてアドバイスを求めてください。より良い解決策を見つけるのに役立ちます。
次に、ChatGPT とさらに通信して、ChatGPT が以前に生成したコードを最適化できるようにする必要があります。
最適化前の EnumInfo アノテーション:
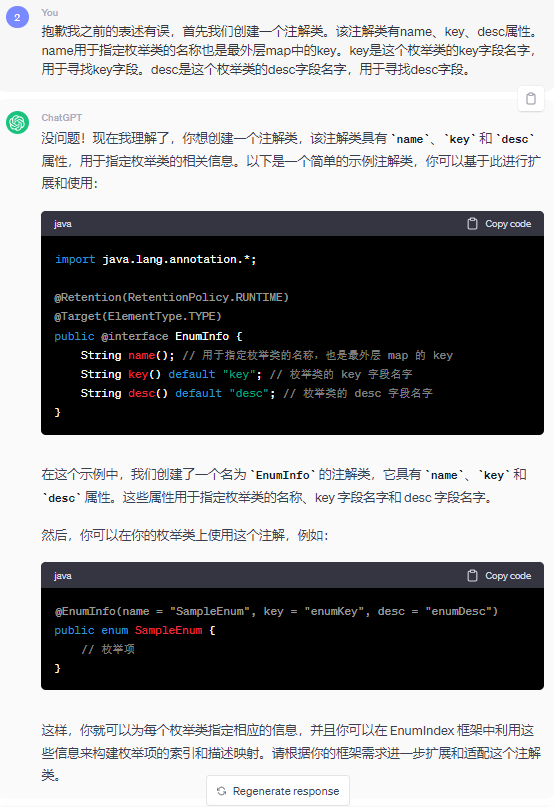
最適化:
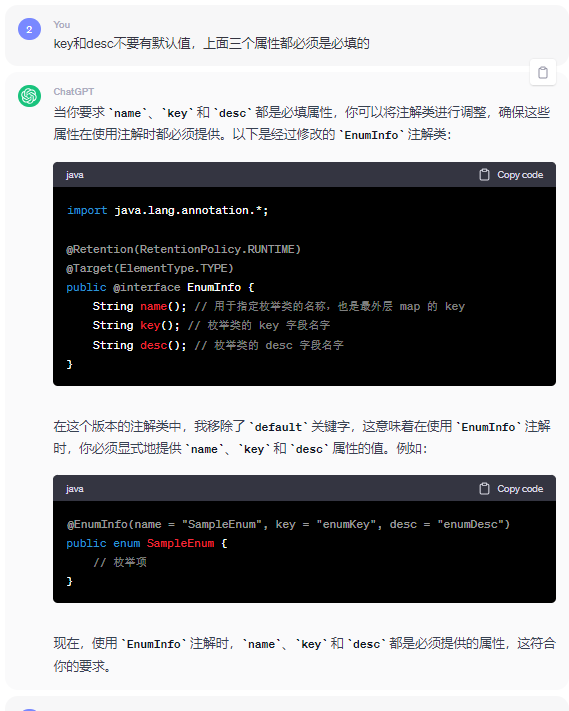
徐々に改善
chatgpt を段階的にガイドしてフレームワークを改善する
ChatGPT の助けを借りて、フレームワークを徐々に改善してください。コーディングに実際に取り組み、ChatGPT であらゆる詳細について話し合います。
最後に、ChatGPT と段階的に通信して、完全なフレームワークの構築に役立てることができます。
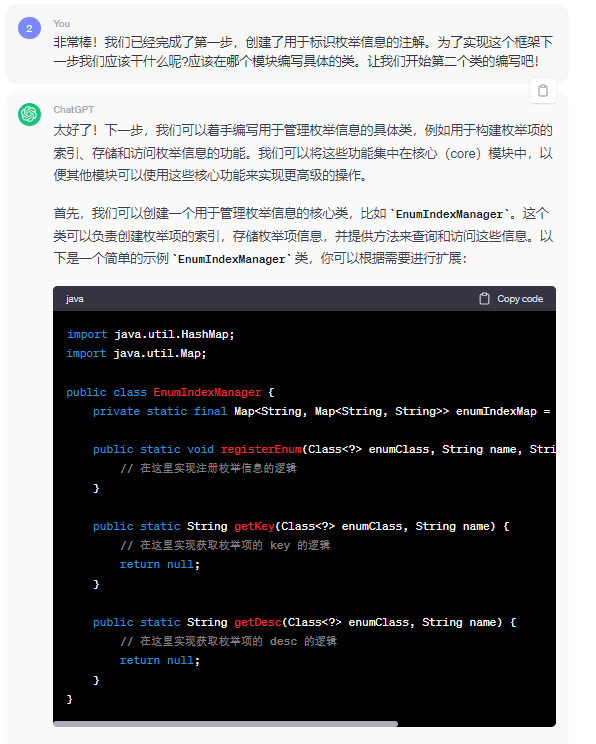
結局、ChatGPTでゆっくり対話して反復処理を行うと、フレームワークのコアクラスが生成されるのですが、反復処理は長すぎるので省略します。
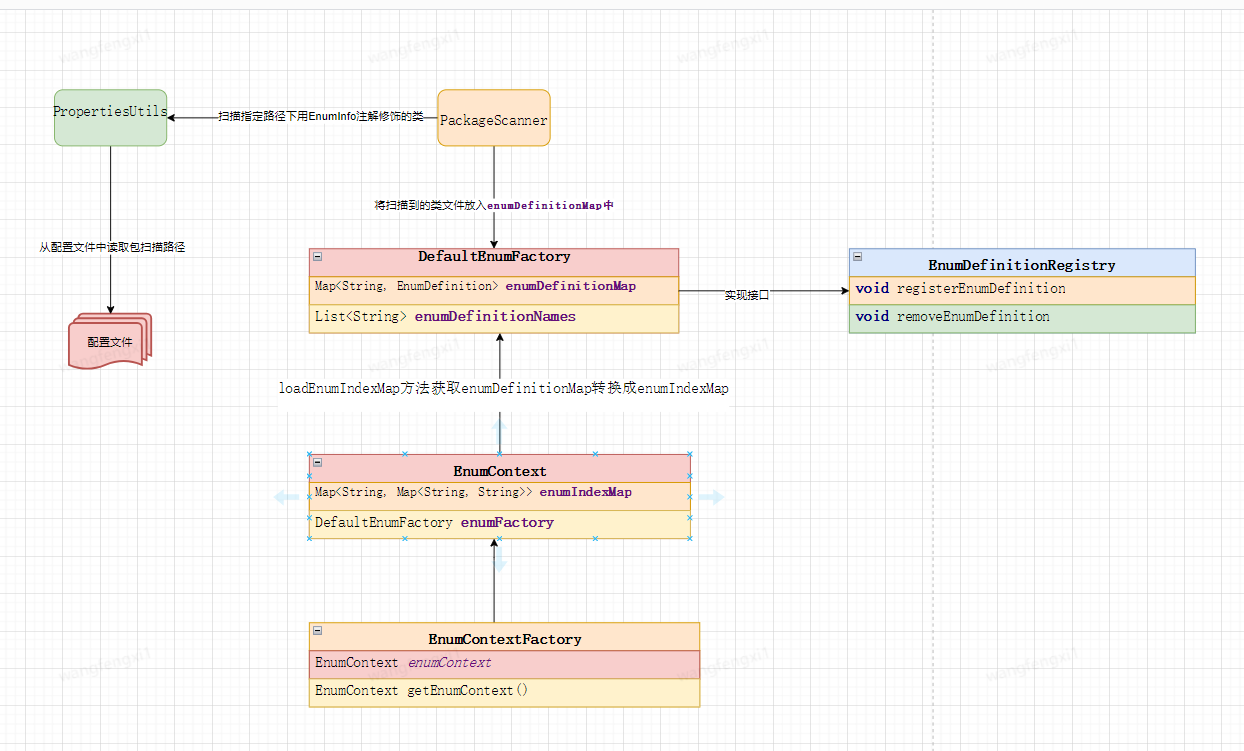
フレームワークのコアクラスの説明
ChatGPT がコア コードを提供した後、Spring モジュールを参照して、次のようにフレームワーク クラスの最終的な最初のバージョンを設計します。
PackageScanner: 指定されたアノテーションを持つクラスの特定のパッケージをスキャンするユーティリティ クラス。
PropertiesUtils: プロパティ ファイルを操作するためのユーティリティ メソッドを提供するツール クラス。
EnumInfo: 列挙型クラスの注釈をマークし、列挙型項目の名前、キー フィールド、および記述フィールドの情報を指定するために使用されます。このアノテーションを列挙型クラスに追加することで、列挙型項目のインデックス マップを確立し、キーと記述子を検索するために使用されるフィールド名を指定できます。
EnumContext: 列挙コンテキスト クラス。列挙定義情報を管理し、列挙情報を取得するメソッドを提供するために使用されます。
EnumContextFactory: シングルトン列挙コンテキスト オブジェクトの作成と取得に使用される列挙コンテキスト ファクトリ クラス。
EnumDefinition: 列挙型クラスの情報を格納するために使用される、列挙型によって定義されたクラスを表します。
EnumDefinitionRegistry: 列挙定義の登録、クエリ、および管理に使用される列挙定義登録インターフェイス。
DefaultEnumFactory: EnumDefinitionRegistry インターフェイスを実装する、デフォルトの列挙定義ファクトリ クラス。
ChatGPT を使用したフレームワークの作成については、すでに完了しているこのセクションを参照してください。大規模な部分では、chatgpt を使用して独自の JAVA フレームワークを開発できます。ただし、フレームワークを実際に運用に適用するには、いくつかの仕上げプロセスを実行する必要があります。
フレームワークの使用テスト
ChatGPT通信では、フレームワークを記述した後、そのフレームワークを実際のプロジェクトに適用する必要があります。
著者のビジネス システム管理エンドのフロントエンドとバックエンドを分離する過程で、研究開発スタッフは、フロントエンドに返す必要がある列挙型クラスに対応する列挙型記述が多数あることを発見しました。
1) 当初は、各列挙クラスがフロントエンド パッケージがテキストを返すコードを作成することが想定されていました。しかし、作成者は業務システムの構成項目が多すぎるため、構成項目ごとにコードを書くのが面倒です。
2) そこで、開発者は、統合インターフェイスを使用して、列挙型クラスの対応する記述をフロントエンドに返すことができないか考えました。フロントエンドは、列挙型クラスの名前を入力するだけで、対応する列挙型クラス間のマッピング関係を取得できます。列挙キーと説明。
そこで、インターフェイスを作成し、列挙型クラスのキーと説明の対応関係をフロントエンドに返す Map オブジェクトを定義しました。しかし、著者の業務システムのチャネル構成がまだ多すぎるためです。このようにして、マップを初期化する必要があります。初期化マップのコードは次のとおりです。
public HashMap<String, Map<Integer, String>> initEnumMap() {
enumMap = new HashMap<>();
enumMap.put("前端获取枚举map的key", XXXEnum.getEnumMap());
enumMap.put("前端获取枚举map的key", XXXEnum.getEnumMap());
enumMap.put("前端获取枚举map的key", XXXEnum.getEnumMap());
...
return enumMap;
}
新しい列挙クラスがそれぞれ追加されていることがわかります。私たちは皆、マッピング関係を静的コード ブロックのマップに組み込む必要があります。また、列挙型クラスには、キーと説明を取得するためのマッピング関係メソッドを追加する必要があります。これでもまだ大変です。そして、このクラスのコードは、後続の新しいマッピング関係のために変更する必要があります。
マップの初期化と列挙型クラスの作成の手順は省略できますか?
3) そこで、アノテーションを定義することを想像します。このアノテーションが付けられたクラスは、フレームワークによってスキャンされます。そして、列挙キーと説明の間のマッピング関係を取得するメソッドを生成します。最後に、マップの初期化プロセスを完了します。総列挙マップを取得するメソッドのみが外部から提供されます。ユーザーはマップがどのように構築されているかを気にする必要はありません。このフレームワークを使用した後の、著者のビジネス システムのインターフェイスのコードは次のようになります。
/**
* 获取枚举
*
* @param enumKey 枚举key
* @return 返回值 Map<Integer,String>;code,描述
*/
@RequestMapping("/getEnum")
public Result<Map<String, Map<String, String>>> getEnum(String enumKey) {
try {
// 获取枚举上下文对象
EnumContext enumContext = EnumContextFactory.getEnumContext();
// 获取枚举map
newEnumMap = enumContext.getEnumIndexMap();
// buid映射从ducc中获取,所以需要手动设置
newEnumMap.put(BUID.getKey(), getBuIdMap());
} catch (Exception e) {
log.error("获取枚举map出错!enumKey:{}", enumKey, e);
return Result.createFail(e.getMessage());
}
// 如果枚举key为空则返回全部
if (StringUtils.isBlank(enumKey)) {
return Result.createWithSuc(newEnumMap);
}
// 如果枚举key不为空则返回指定值
Map<String, Map<String, String>> resultMap = new HashMap<>();
resultMap.put(enumKey, newEnumMap.get(enumKey));
return Result.createWithSuc(resultMap);
}
4) アノテーションクラスのコードは次のとおりです。
これはテスト列挙クラスの例です。
@EnumInfo(name = "StatusEnum", key = "code", desc = "description")
public enum StatusEnum {
SUCCESS(200, "Success"),
ERROR(500, "Error");
private final int code;
private final String description;
StatusEnum(int code, String description) {
this.code = code;
this.description = description;
}
public int getCode() {
return code;
}
public String getDescription() {
return description;
}
}
今後列挙型クラスを追加するには、@EnumInfo(name = "StatusEnum", key = "code", desc = "description") をマークするだけで済みます。列挙クラスの名前、キー フィールド名、説明フィールド名を指定するだけです。列挙のキーと説明の間のマッピング関係は、インターフェイスのコードを変更せずにフロントエンドに返すことができます。研究開発共同デバッグ時間とテスト回帰時間が大幅に短縮されました。
フレームワーク性能圧力テスト
フレームワークを実際の運用プロジェクトに適用する場合は、ChatGPT を活用したフレームワークを十分にテストして検証する必要があります。同時に、フレームワークのボトルネックを知るためにフレームワークのパフォーマンスをテストすることも必要です。一般的なインターフェイス圧力テスト ツールには、LoadRunnerやApache JMeter などがあります。圧力測定ツールを選択して圧力測定を行うことができます。
著者は、このフレームワークをプロジェクトに適用し、インターフェースを外部に公開しました。4C4G マシン構成では、単一マシンは最大1000 QPS をサポートできます。1000QPS 未満では、単一マシンの CPU 使用率は30%に達し、システムは負荷は0.9に近く、メモリ使用率と圧力はテスト前に大きな変化はありませんでした。
マルチ環境開発をサポートする国内初のIDE——CEC-IDE MicrosoftがPythonをExcelに統合、グイおじさんがフレームワーク策定に参加 中国プログラマーらギャンブルプログラム作成を拒否、歯14本抜かれ88%の身体損傷 オープンソースのSongフォントを模倣したPodman Desktop、 ダウンロード数50万件を突破 オープニング画面の広告を自動的に 無期限に更新停止 「Li Tiao Tiao」が スキップ Xiaomiがmios.cnウェブサイトのドメイン名を申請著者: JD Retail 王鳳熙
出典: JD Cloud 開発者コミュニティによる転載。出典を明記してください