序文
TDSQL-C for MySQL (TDSQL-C for MySQL) は、Tencent Cloud によって開発された新世代のクラウドネイティブ リレーショナル データベースです。従来のデータベース、クラウド コンピューティング、新しいハードウェア テクノロジの利点を統合し、柔軟性が高く、パフォーマンスが高く、大容量のストレージ、安全で信頼性の高いデータベース サービスをユーザーに提供します。TDSQL-C MySQL バージョンは、MySQL 5.7 および 8.0 と 100% 互換性があります。100 万 QPS を超える高スループットと最高の PB レベルのインテリジェント ストレージを実現し、データのセキュリティと信頼性を保証します。
TDSQL-C MySQL バージョンは、ストレージとコンピューティングを分離するアーキテクチャを採用しています。すべてのコンピューティング ノードは 1 つのデータを共有し、第 2 レベルの構成ダウングレードと第 2 レベルの障害回復を提供します。単一ノードは百万レベルの QPS をサポートし、データとバックアップを自動的に維持できます。最大 GB/秒の並列バックファイル。
TDSQL-C MySQL バージョンは、商用データベースの安定性、信頼性、高性能、拡張性の特性を兼ね備えているだけでなく、オープンソース クラウド データベースのシンプルさ、オープン性、効率的な反復という利点も備えています。TDSQL-C MySQL バージョン エンジンはネイティブ MySQL と完全な互換性があり、アプリケーションのコードや構成を変更することなく、MySQL データベースを TDSQL-C MySQL バージョン エンジンに移行できます。
この記事では、 Python を使用して読み取りデータを TDSQL-C に追加し、ワード クラウド グラフを実装する手順を段階的に実装します。
何を学びましたか
- TDSQL データベースの申請方法: Tencent Cloud へのログイン、構成の購入、ページの購入と管理、およびその他の関連手順が含まれます。
- プロジェクト エンジニアリングの作成、TDSQL データベースへの接続、データベースの作成など。
- Excel の単語頻度の読み取り、テーブルの作成、TDSQL へのデータの保存、TDSQL データの読み取り、およびその他の関連コードの説明が含まれます。
- Python関連の知識など
準備
TDSQLデータベースを申請する
1. クリックして Tencent Cloud にログインします
2. 以下に示すように、「今すぐ購入」をクリックします。
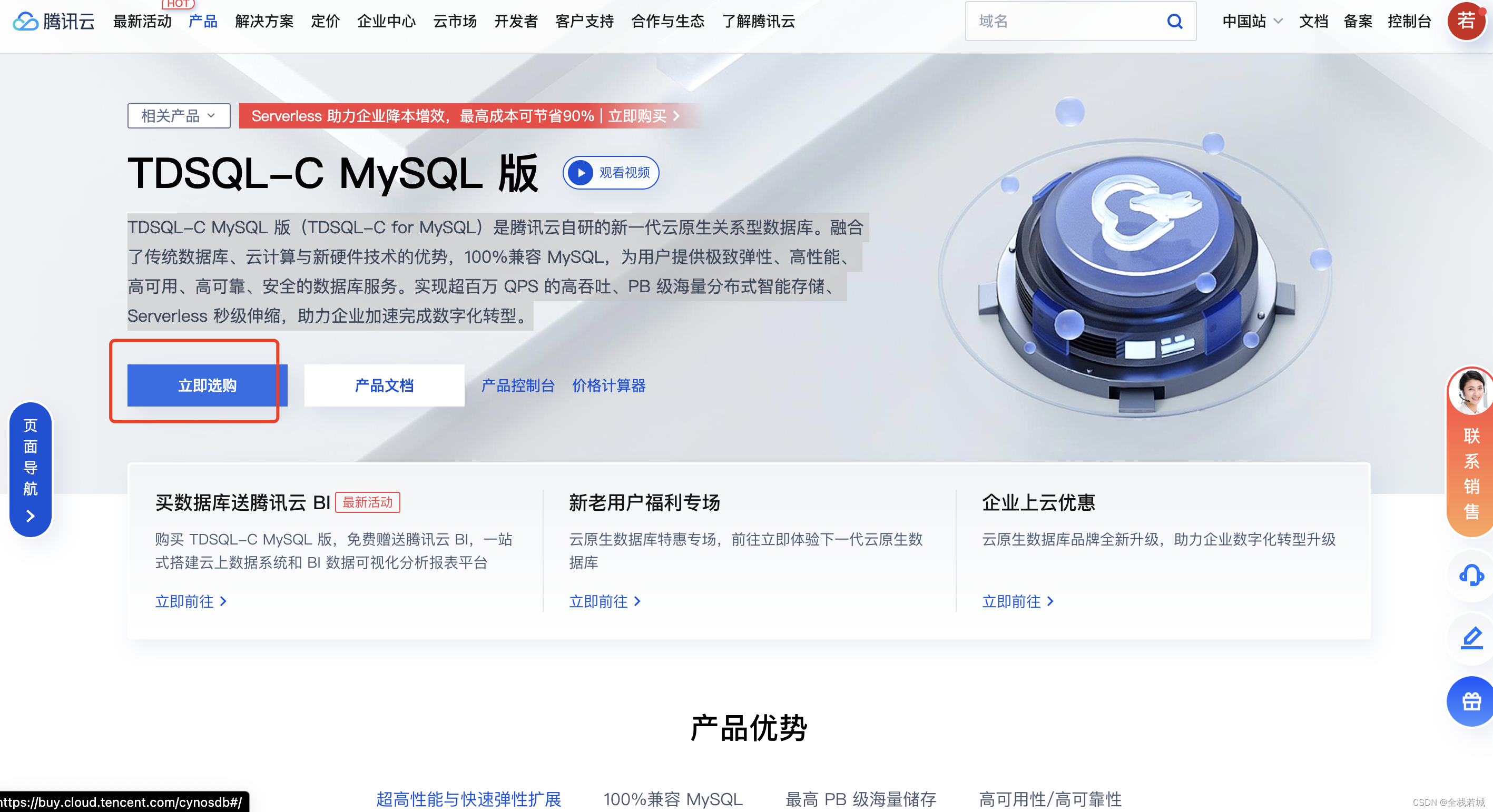
3. 購入ページのデータベース構成オプションは次のとおりです。
**注意**: ここではインスタンス フォームを選択します
Serverless
- 实例形态 **(Serverless)**
- 数据库引擎 **(MYSQL)**
- 地域 **(北京)** *地域这里根据自己的实际情况选择即可*
- 主可用区 **(北京三区)** *主可用区这里根据自己的实际情况选择即可*
- 多可用区部署 **(否)**
- 传输链路
- 网络
- 数据库版本 **(MySQL5.7)**
- 算力配置 **最小(0.25) , 最大(0.5)**
- 自动暂停 **根据自己需求配置即可**
- 计算计费模式 **(按量计费)**
- 存储计费模式 **(按量计费)**
私の構成のスクリーンショットは次のとおりです。
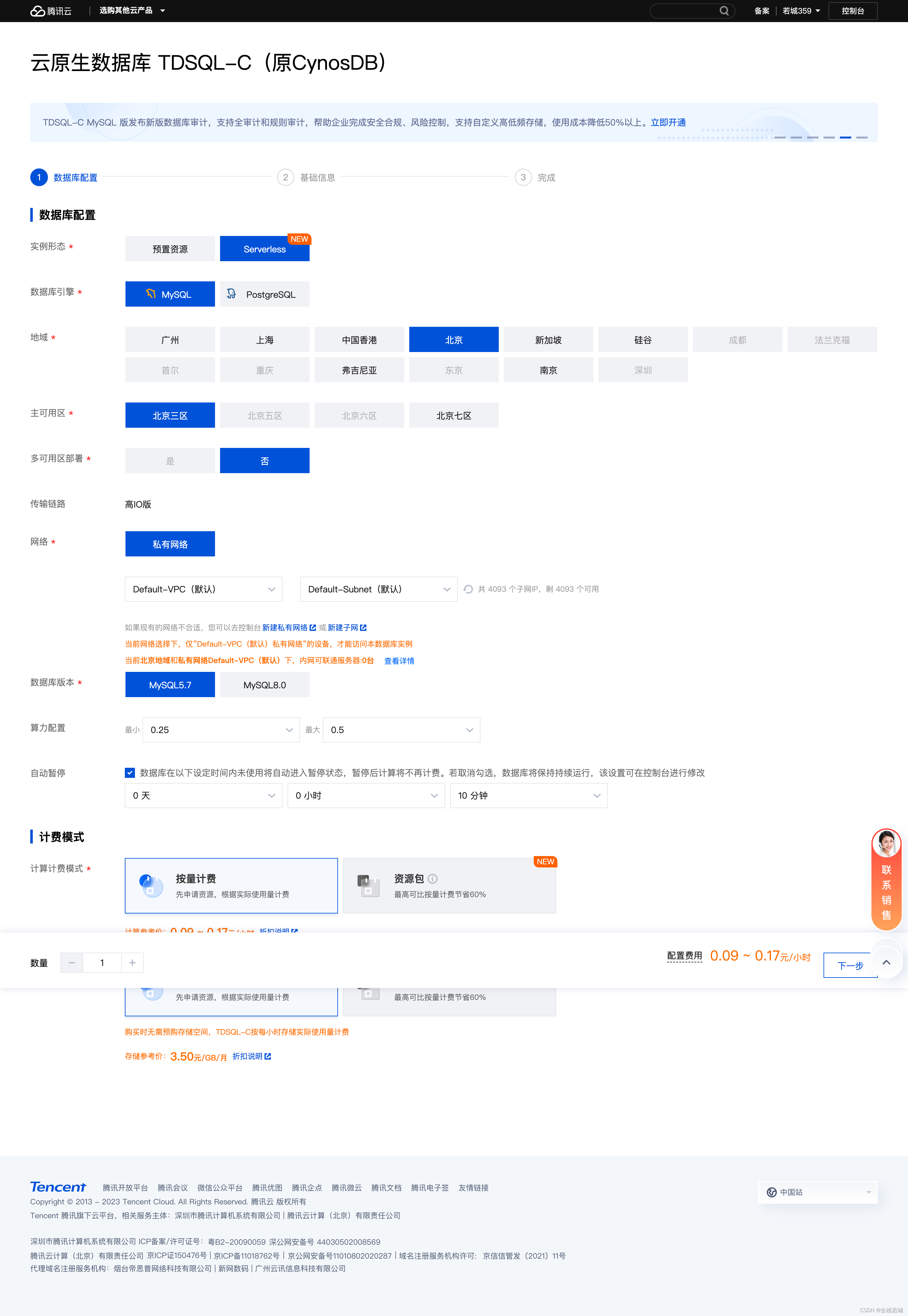
4. 基本情報
以下の図に示すように、ここで
设置自己的密码直接設定できます。表名大小写不敏感
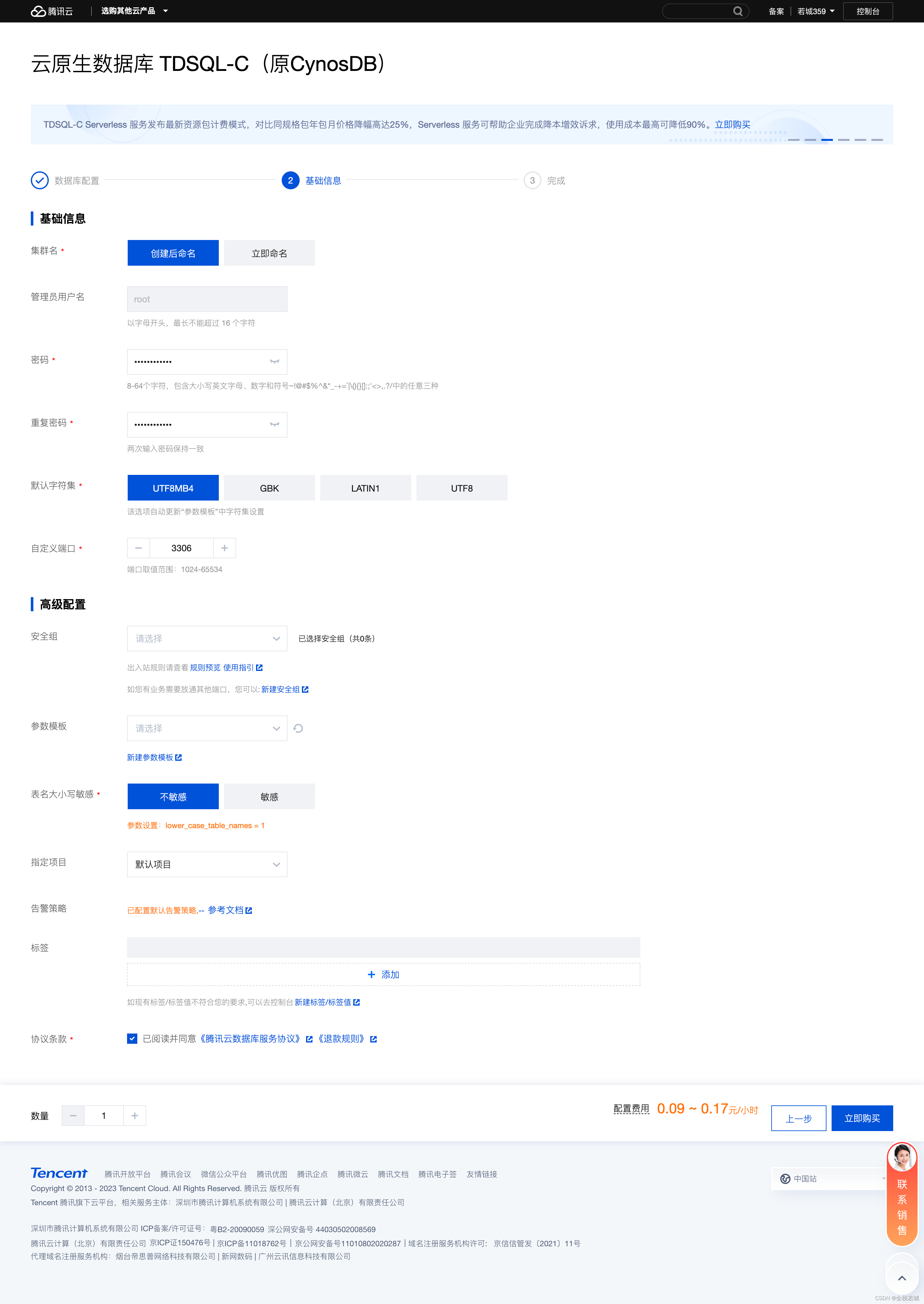
5. 設定が完了したら、右下隅にある「今すぐ購入」をクリックします。
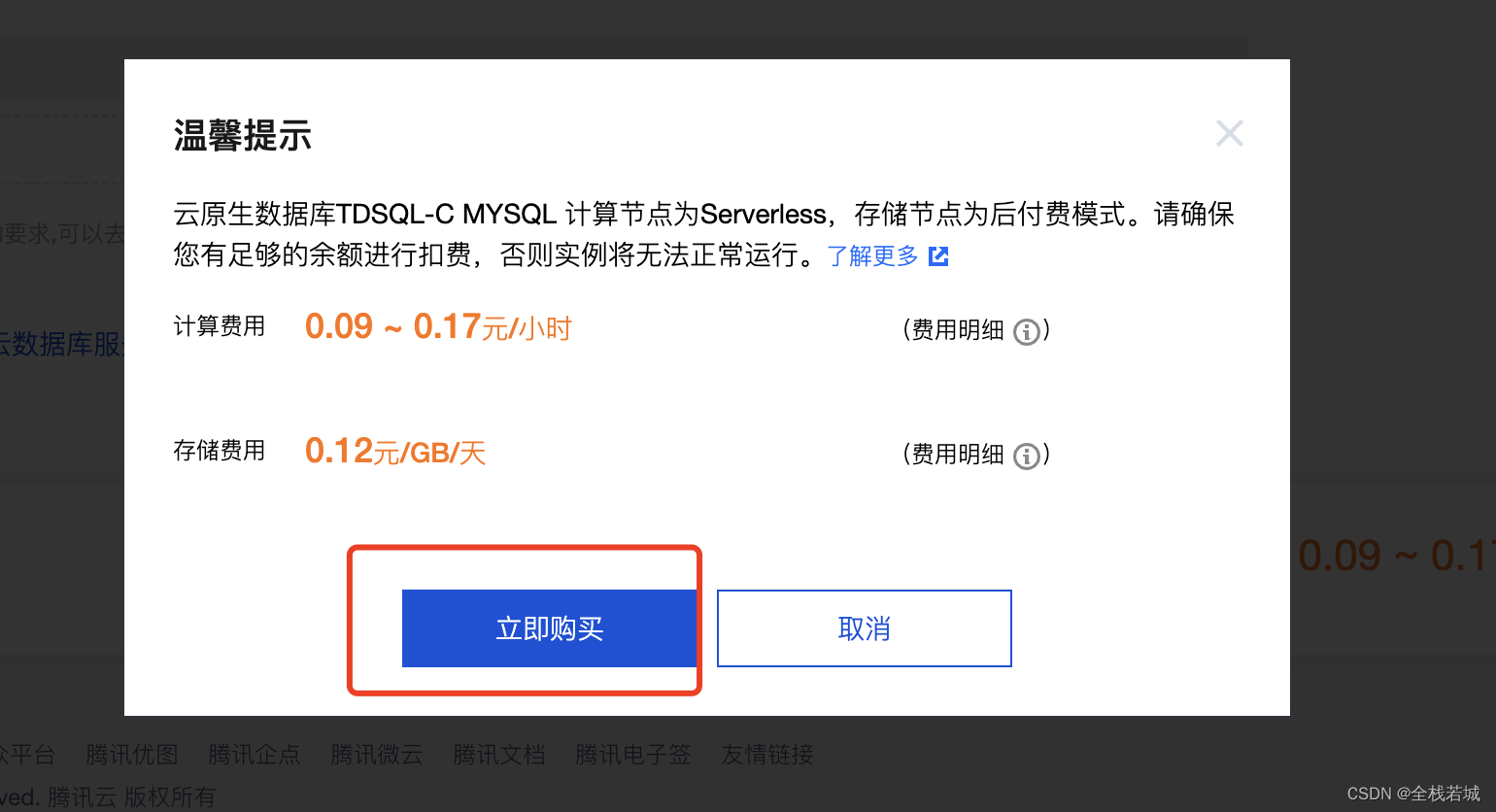
6. 「今すぐ購入」をクリックすると、次のようなポップアップウィンドウが表示されますので、もう一度クリックします。
7. 購入が完了すると、ポップアップウィンドウが表示されるので、クリックします。前往管理页面
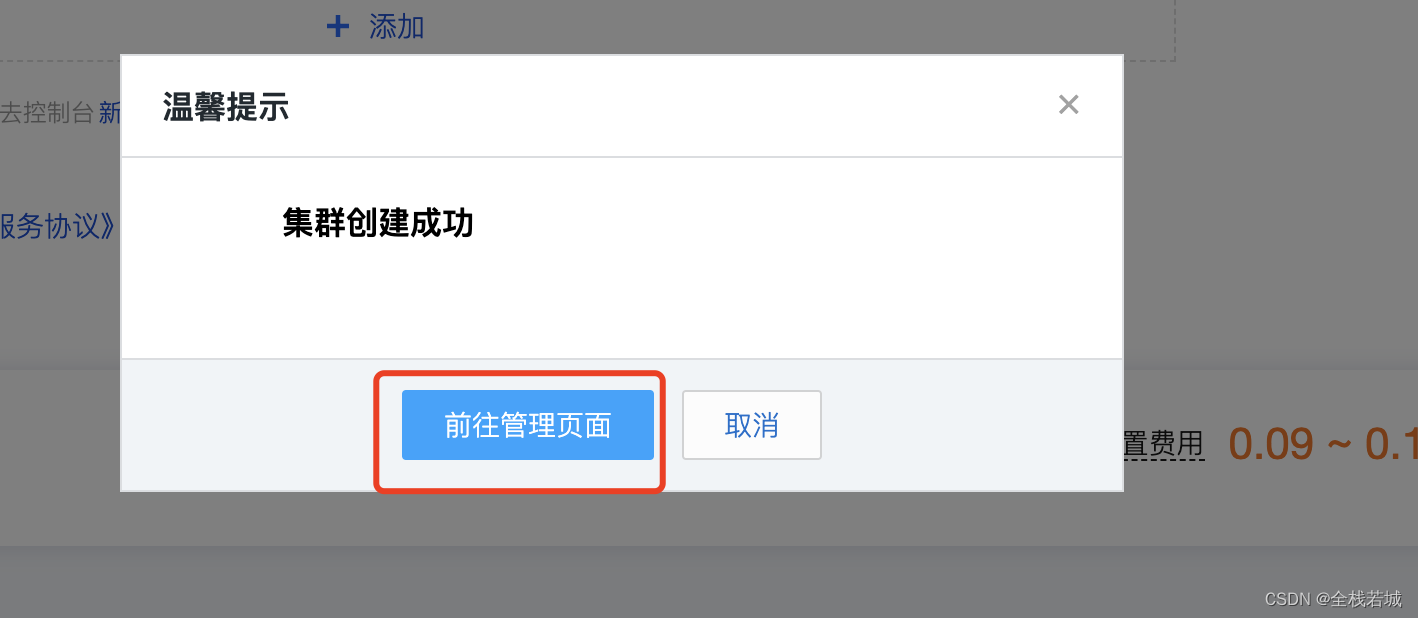
8. 読み取りと書き込みの例については、ここをクリックしてください开启外部
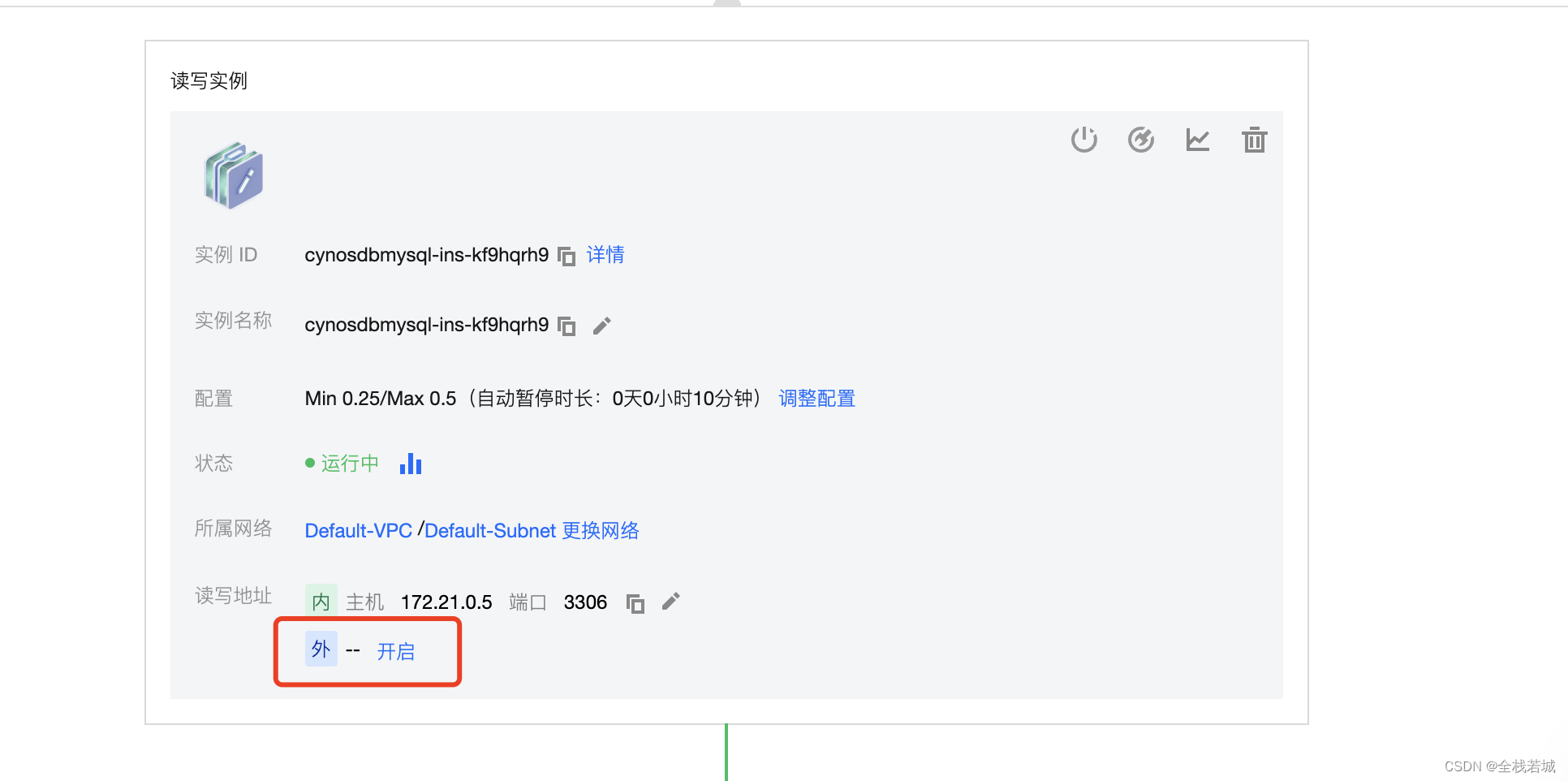
9. 作成と承認
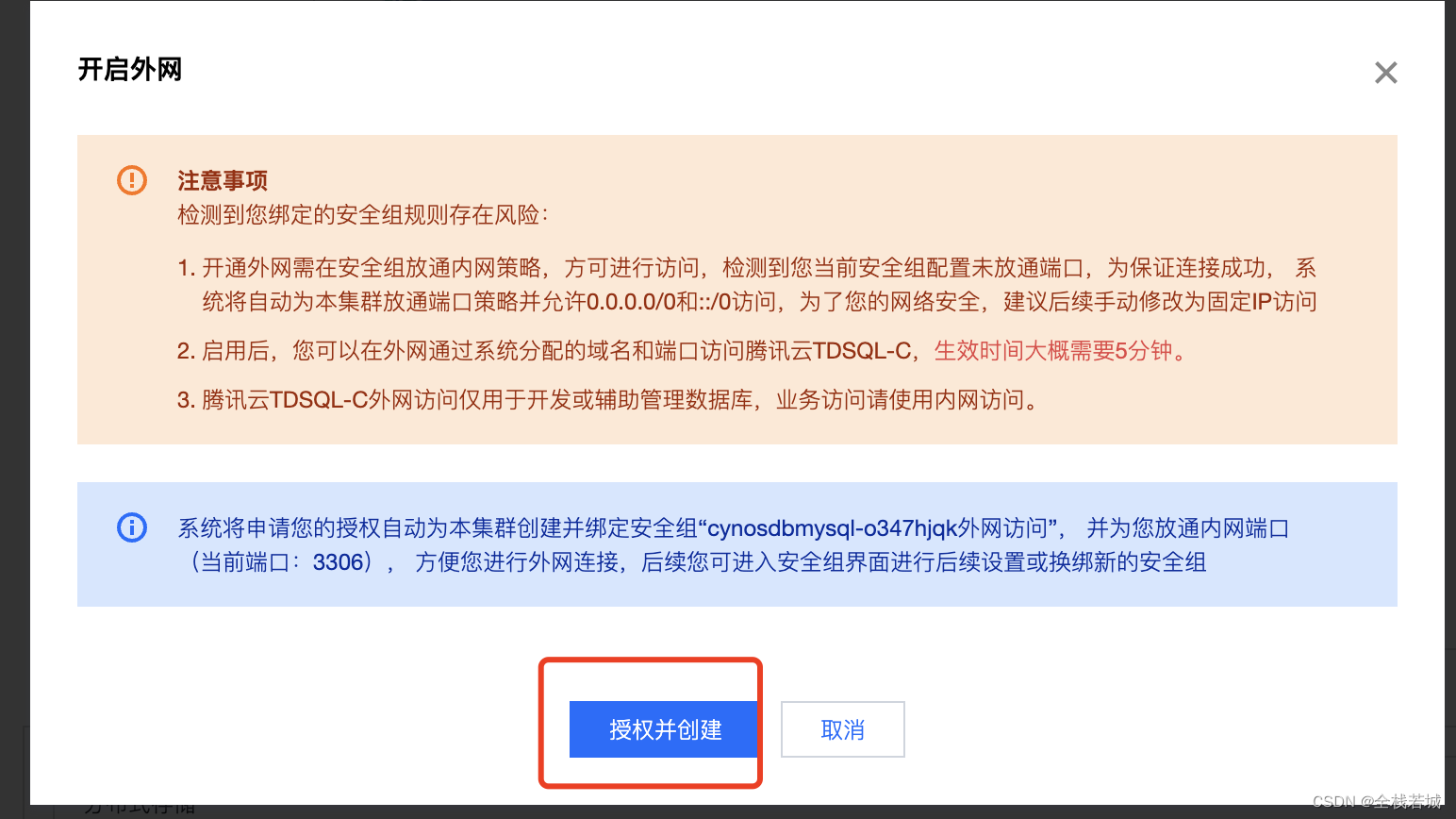
ここまでの準備作業は完了しましたが、実際、非常に簡単です。
データの準備
必要なデータは以下の通りです
- 単語の頻度
- 背景画像
- フォントファイル
ダウンロード アドレスは記事の最後にあります。必要に応じてダウンロードできます。
プロジェクトプロジェクトの作成
プロジェクトディレクトリは以下の通りです
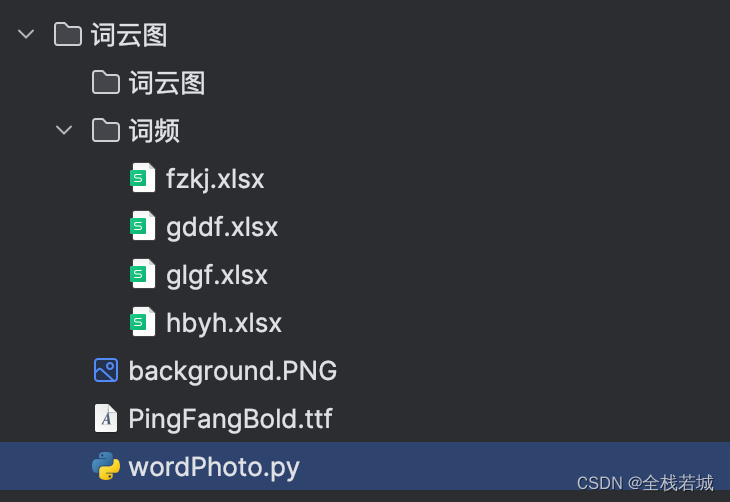
説明:
- ファイル内のワード クラウド マップ フォルダーは、生成された画像の保存パスとして使用されます。
background.pngワードクラウドマップの背景画像として- フォントファイルはワードクラウドマップのフォント表示です
- 単語頻度はデータのサポートです
wordPhoto.pyスクリプトファイルの場合
リンクTDSQL
図に示すように、データベースの読み取りおよび書き込みインスタンスを開いて、関連する構成を見つけます。
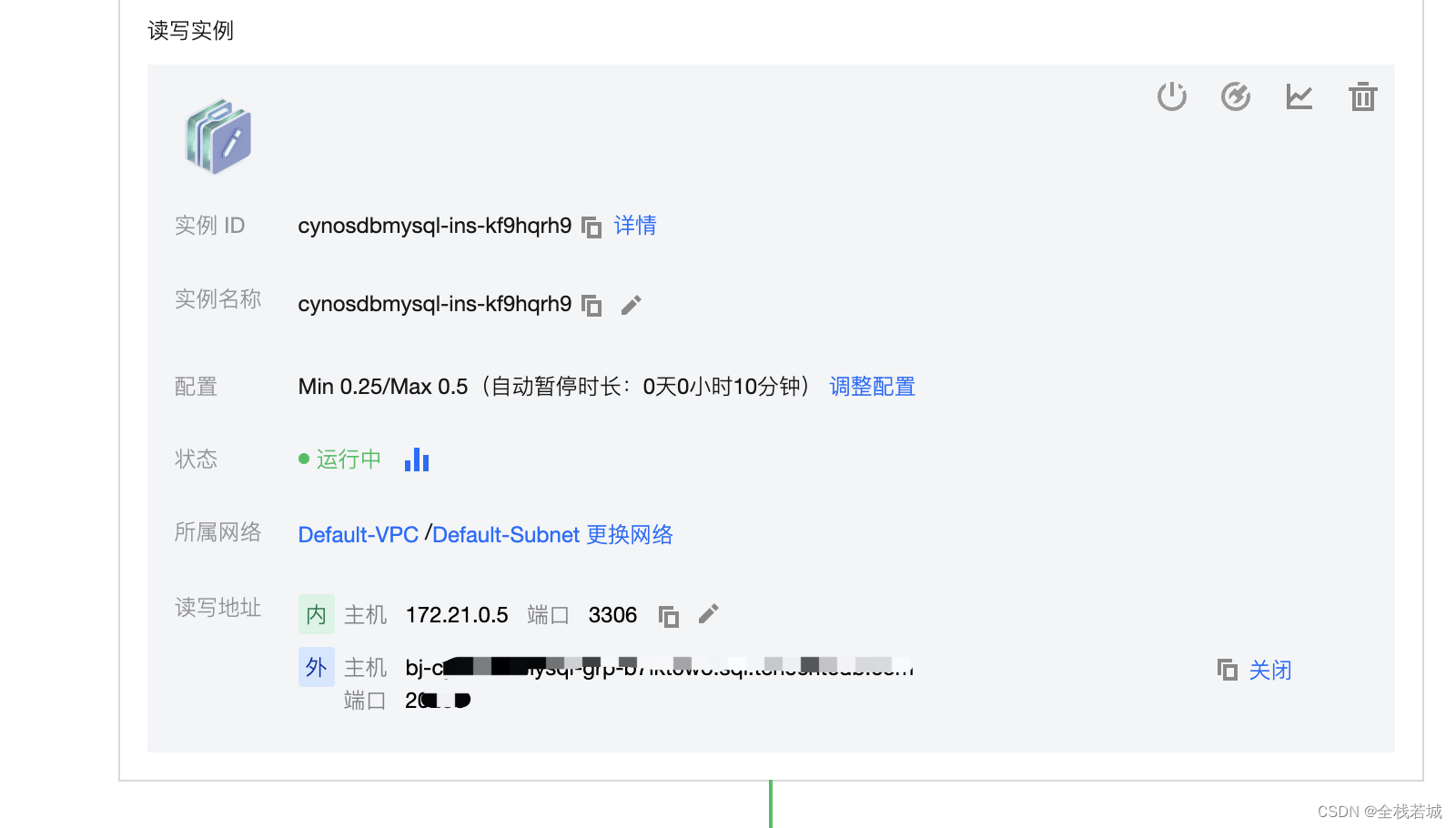
# MySQL数据库连接配置
db_config = {
'host': "XXXXXX", # 这里填写你自己申请的外部主机名
'port': xxxx, # 这里填写你自己申请的外部的端口
'user': "root", # 账户
'password': "", # 密码就是你自己创建实例时的密码
'database': 'tdsql', # 这里需要自己在自己创建的`tdsql`中创建数据库 ,
}
データベースを作成する
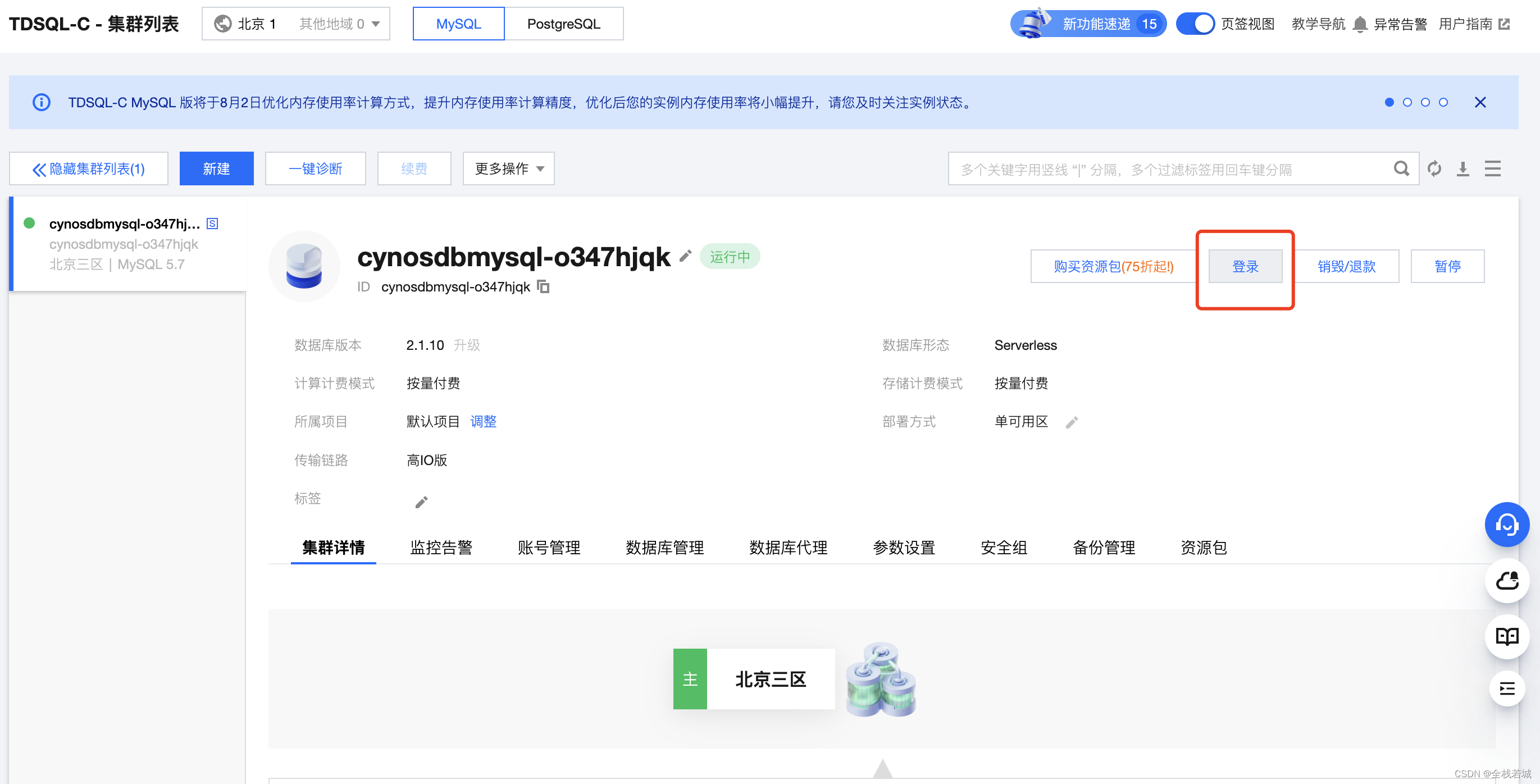
- 図に示すようにログインボタンをクリックして、作成したデータベースにログインします。
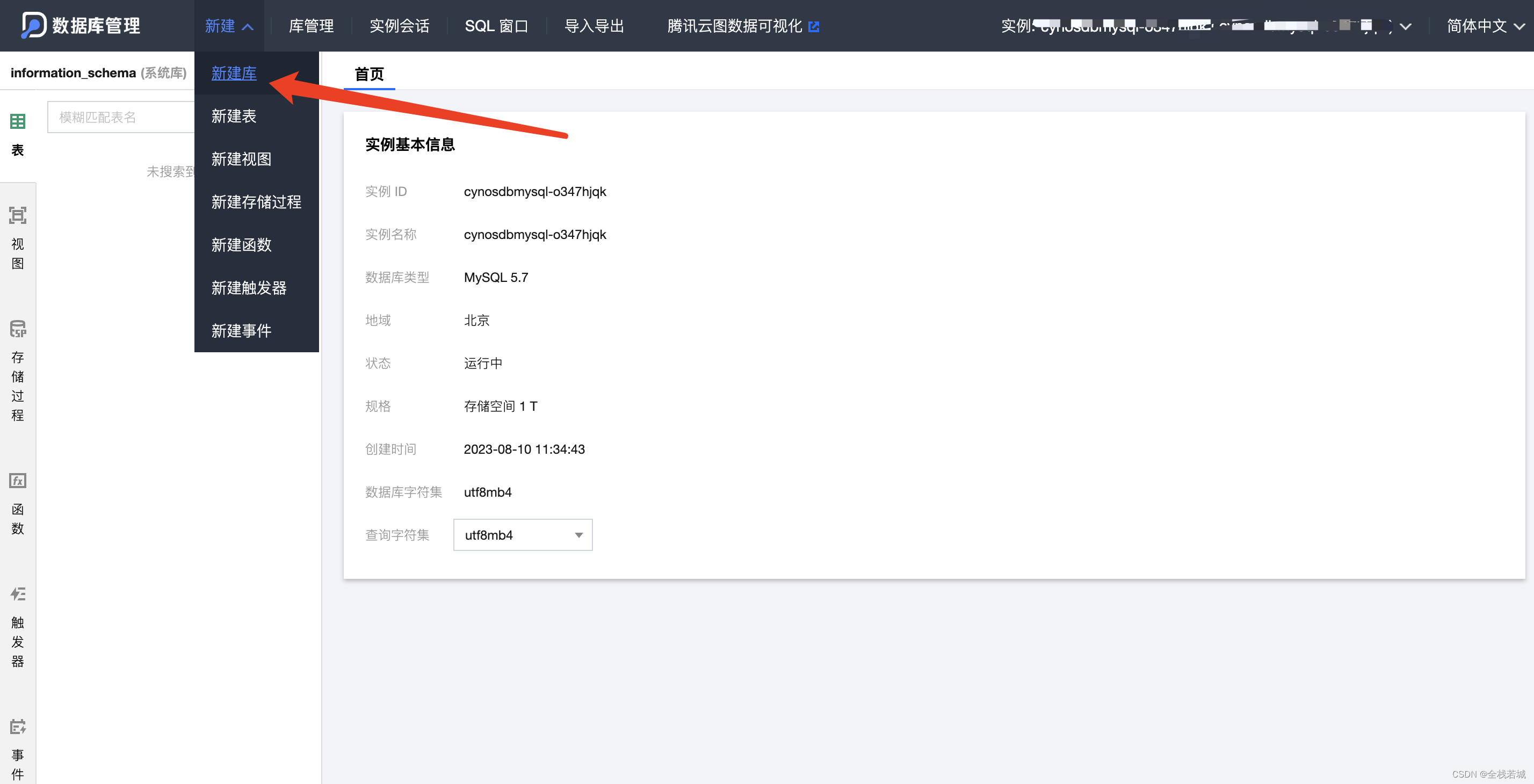
- データベースを入力してクリック
新建库
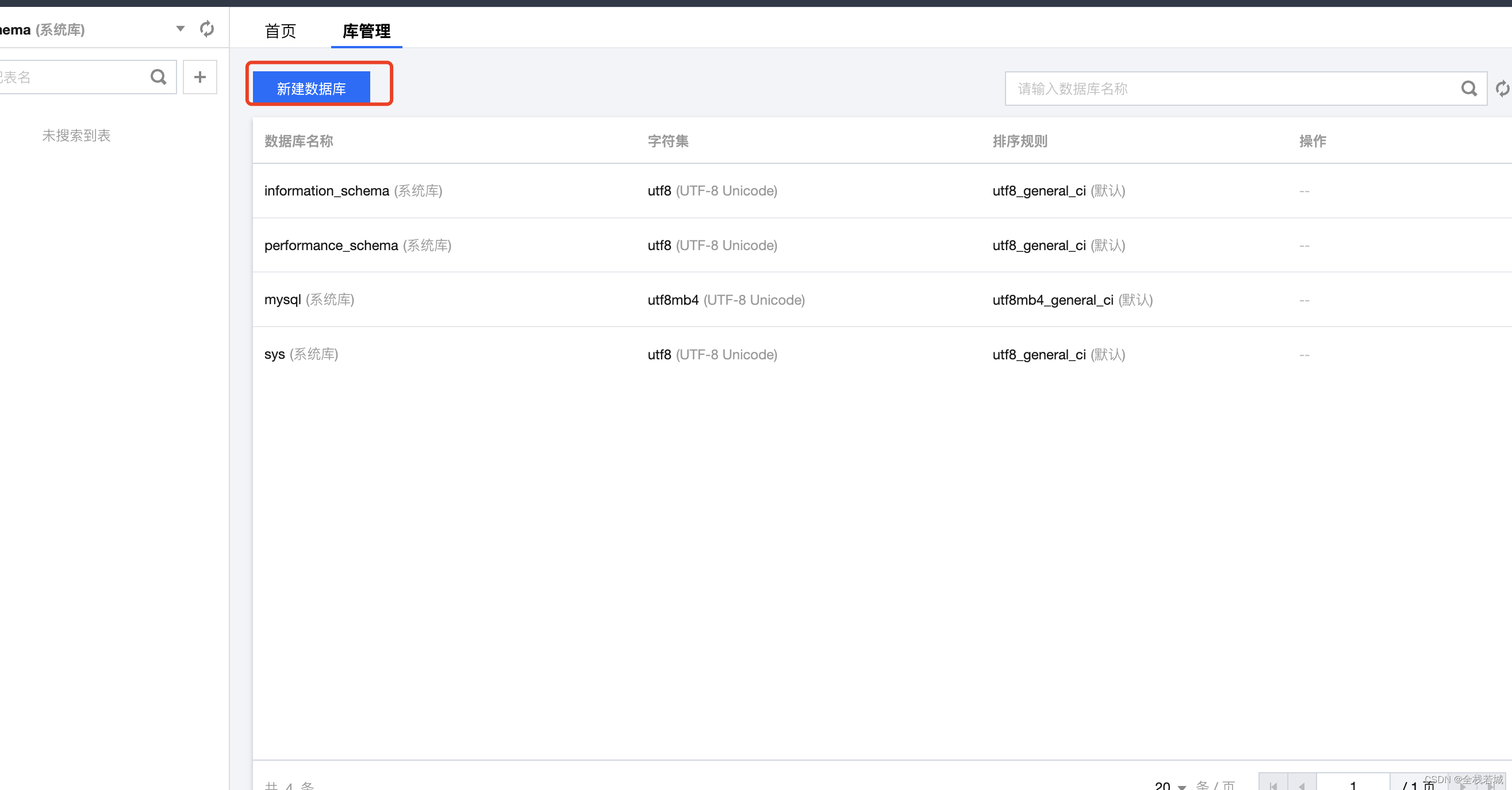
- をクリックする
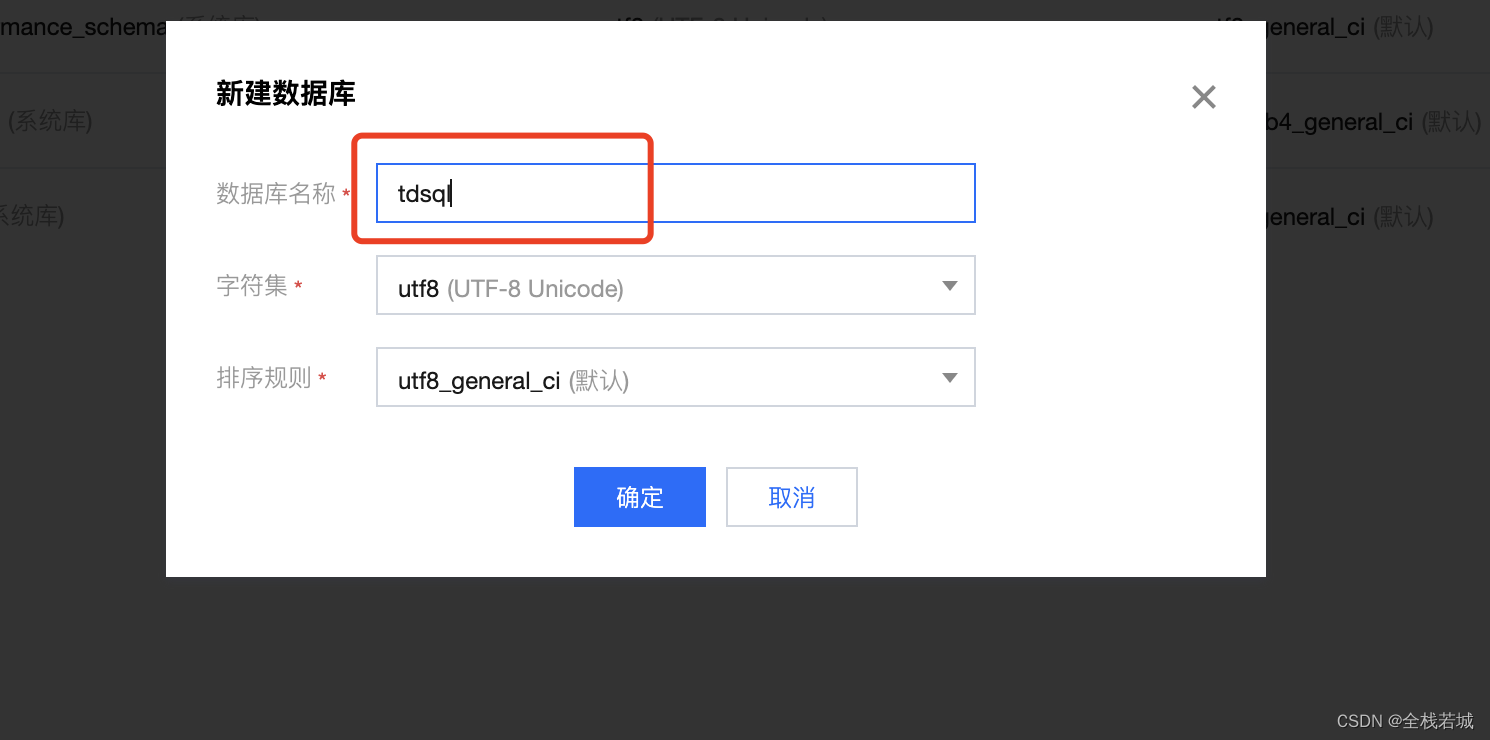
新建数据库と、ポップアップウィンドウが表示されます
- ポップアップ ウィンドウで、
数据库名称お気に入りのデータベース名を入力します。ここではtdsqlデータベース名として , を使用します。データベース名を入力した後、确定创建クリックします。
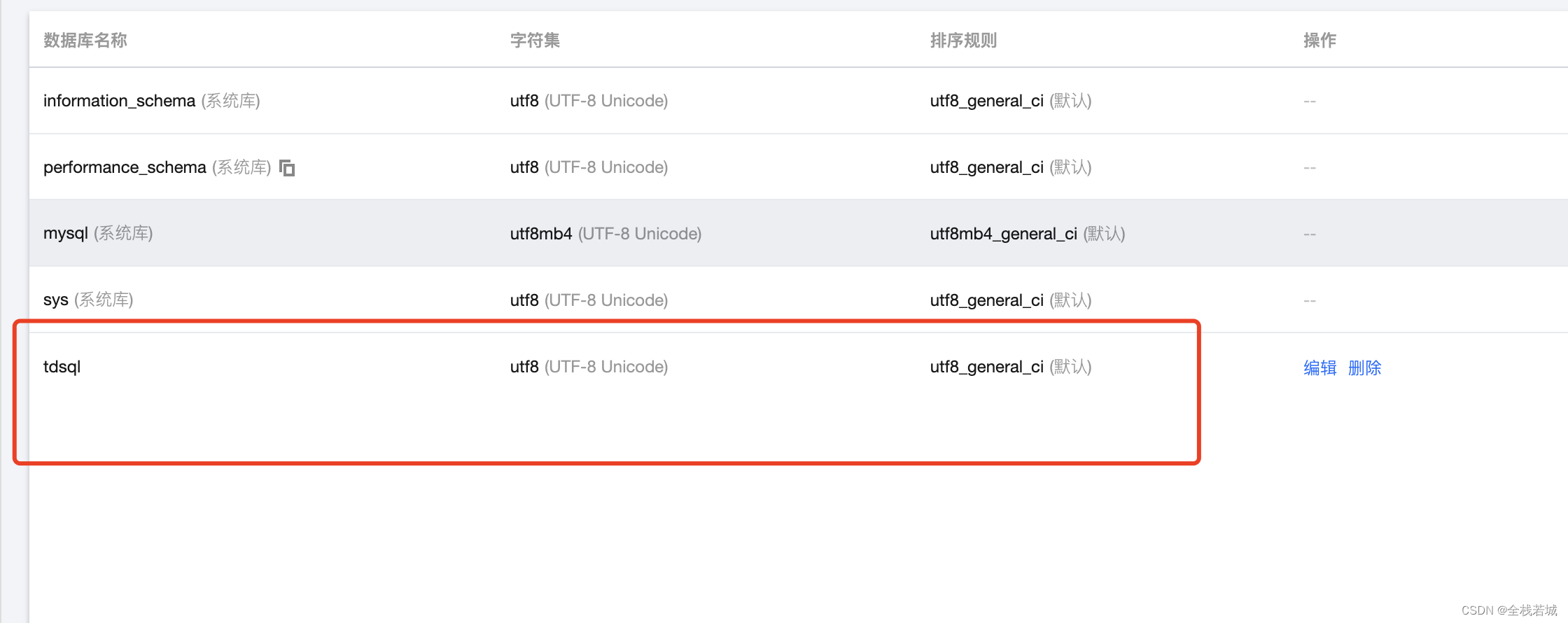
- 作成したデータベースの名前がリストに表示されたら、データベースが作成されたことを意味し、コードの記述を開始できます。
機能モジュール
Excelの単語頻度を読む
def excelTomysql():
path = '词频' # 文件所在文件夹
files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径
for file_path in files:
print(file_path)
filename = os.path.basename(file_path)
table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名
# 使用pandas库读取Excel文件
data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名
columns = {
col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型
create_table(table_name, columns) # 创建表
save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名
print(filename + ' uploaded and saved to MySQL successfully')
コードの説明
- フォルダーのパスを「単語頻度」に設定し、そのパスを変数に割り当てます
path。 - 関数を使用して
os.listdir()、フォルダーの下にあるすべてのファイル名を取得し、フルパスを連結してリストに保存しますfiles。 - リスト内の各ファイル パスを
forループし、ファイル パスを出力するために使用します。files - 関数を使用して
os.path.basename()ファイル名を取得し、そのファイル名を変数に割り当てますfilename。 - 関数を使用して
os.path.splitext()ファイル名の拡張子を取得し、インデックス操作で拡張子部分を削除してテーブル名を取得し、変数 にテーブル名を代入しますtable_name。 pandasライブラリの機能を利用してread_excel()Excelファイルを読み込み、変数にデータを格納しますdata。読み取り中にopenpyxlエンジンが使用され、最初の行が列名とみなされます。- ディクショナリ内包表記を使用してディクショナリを生成します
columns。ディクショナリのキーはデータの列名で、値は "VARCHAR(255)" データ型です。 - および をパラメータとして
create_table()関数を呼び出して、対応するテーブルを作成します。table_namecolumns - および をパラメーターとして指定
save_to_mysql()して関数を呼び出し、ファイル名をテーブル名として使用してデータを MySQL データベースに保存します。datatable_name - ファイル名と「MySQL に正常にアップロードおよび保存されました」というプロンプト メッセージを出力します。
テーブルを作成する
def create_table(table_name, columns):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 组装创建表的 SQL 查询语句
query = f"CREATE TABLE IF NOT EXISTS {
table_name} ("
for col_name, col_type in columns.items():
query += f"{
col_name} {
col_type}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ")"
# 执行创建表的操作
cursor.execute(query)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
コードの説明
- MySQL データベースとの接続を確立します。接続パラメータは
db_config変数を通じて提供されます。 - SQL文を実行するためのカーソルオブジェクトを作成します
cursor。 - SQL クエリ ステートメントをアセンブルしてテーブルを作成します。まず、SQL クエリ ステートメントにテーブル名を挿入します
table_name。次に、ディクショナリ内の各キーと値のペアをforループして、列名とデータ型をそれぞれ SQL クエリ ステートメントに追加します。columns - SQL クエリ ステートメントの末尾にある最後のコンマとスペースを削除します。
- 右括弧を追加して、SQL クエリ ステートメントの組み立てを完了します。
- カーソル オブジェクトを使用して
cursorテーブルを作成する操作を実行します。実行される SQL ステートメントは組み立てられたクエリ ステートメントです。 - トランザクションをコミットして、データベースへの変更を永続化します。
- カーソルとデータベース接続を閉じます。
このコードは、pymysqlモジュールを使用して MySQL データベース接続を確立し、SQL ステートメントを記述してテーブルを作成する操作を実行します。特定のデータベース接続パラメータはdb_config変数で提供され、columnsパラメータは前のコードによって生成されたディクショナリであり、テーブルの列名とデータ型が含まれます。
データを保存するtdsql
def save_to_mysql(data, table_name):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 将数据写入MySQL表中(假设数据只有一个Sheet)
for index, row in data.iterrows():
query = f"INSERT INTO {
table_name} ("
for col_name in data.columns:
query += f"{
col_name}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ") VALUES ("
values = tuple(row)
query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符
query += ")"
cursor.execute(query, values)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
コードの説明
- MySQL データベースとの接続を確立します。接続パラメータは
db_config変数を通じて提供されます。 - SQL文を実行するためのカーソルオブジェクトを作成します
cursor。 - データ内の行ごとに、
forループを使用して反復し、インデックスと行データを取得します。 - データを挿入するための SQL クエリ ステートメントを組み立てます。まず、SQL クエリ ステートメントにテーブル名を挿入します
table_name。次に、forデータの列名をループして列名を SQL クエリ ステートメントに追加します。 - SQL クエリ ステートメントの末尾にある最後のコンマとスペースを削除します。
- 右括弧を追加して、SQL クエリ ステートメントの組み立てを完了します。
tuple(row)行データをタプル型に変換し、%s値のプレースホルダーに対応する数のプレースホルダーを動的に生成するために使用します。- 値のプレースホルダーが SQL クエリ ステートメントに追加されます。
- カーソル オブジェクトを使用して
cursor.execute()SQL クエリ ステートメントを実行し、クエリ ステートメント内のプレースホルダーを実際の行データに置き換えます。 - トランザクションをコミットして、データベースへの変更を永続化します。
- カーソルとデータベース接続を閉じます。
読み取りtdsqlデータ
def query_data():
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 查询所有表名
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
data = []
dic_list = []
table_name_list = []
for table in tables:
# for table in [tables[-1]]:
table_name = table[0]
table_name_list.append(table_name)
query = f"SELECT * FROM {
table_name}"
# # 执行查询并获取结果
cursor.execute(query)
result = cursor.fetchall()
if len(result) > 0:
columns = [desc[0] for desc in cursor.description]
table_data = [{
columns[i]: row[i] for i in range(len(columns))} for row in result]
data.extend(table_data)
dic = {
}
for i in data:
dic[i['word']] = float(i['count'])
dic_list.append(dic)
conn.commit()
cursor.close()
conn.close()
return dic_list, table_name_list
コードの説明
- MySQL データベースとの接続を確立します。接続パラメータは
db_config変数を通じて提供されます。 - SQL文を実行するためのカーソルオブジェクトを作成します
cursor。 cursor.execute()SQL クエリ ステートメントを実行してすべてのテーブル名を取得するために使用します"SHOW TABLES"。- クエリ結果を取得するために使用し
cursor.fetchall()、結果を変数に格納しますtables。 - クエリ結果を保存するための空のリスト
data、dic_list、table_name_list、 データ、ディクショナリ、およびテーブル名を作成します。 - テーブル名ごとに
table、forループを繰り返してテーブル名を取得し、それを に追加しますtable_name_list。 - テーブル内のすべてのデータをクエリする SQL ステートメントを作成し、
cursor.execute()クエリ ステートメントの実行に使用します。 - クエリ結果を取得するために使用し
cursor.fetchall()、結果を変数に格納しますresult。 resultクエリ結果の長さが 0 より大きい 場合は、データがあることを意味し、次の操作を実行します。cursor.descriptionクエリ結果の列名のリストを取得し、列名を変数に格納するために使用しますcolumns。- リスト内包表記と辞書内包表記を使用して、クエリ結果の各行を辞書に変換し、その辞書を変数に格納します
table_data。 - がリスト
table_dataに追加されます。data
- の結果から辞書を作成し
data、その辞書を変数に格納しますdic。 - がリスト
dicに追加されます。dic_list - トランザクションをコミットして、データベースへの変更を永続化します。
- カーソルとデータベース接続を閉じます。
- 返品
dic_listとtable_name_list。
コード呼び出し
if __name__ == '__main__':
excelTomysql()
result_list, table_name_list = query_data()
for i in range(len(result_list)):
maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图
# 定义词云样式
wc = wordcloud.WordCloud(
font_path='PingFangBold.ttf', # 设置字体
mask=maskImage, # 设置背景图
max_words=800, # 最多显示词数
max_font_size=200) # 字号最大值
# 生成词云图
wc.generate_from_frequencies(result_list[i]) # 从字典生成词云
# 保存图片到指定文件夹
wc.to_file("词云图/{}.png".format(table_name_list[i]))
print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png'))
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
コードの説明
- 使用方法「background.PNG」という名前の背景画像を開いてNumPy配列に変換し、ワードクラウドの背景画像として
Image.open()変数に格納します。maskImage WordCloudオブジェクトを作成しwc、フォント パス、背景画像、表示される単語の最大数、最大フォント サイズなどのパラメータを設定します。wc.generate_from_frequencies()のresult_list[i]辞書データを使用してワード クラウド グラフを生成します。wc.to_file()生成されたワード クラウドを「word cloud/{}.png」という名前のファイルとして保存するために使用します。ここで{}、 は対応するテーブル名です。- 生成されたワード クラウド マップのファイル名を出力します。
plt.imshow()ワードクラウドを表示するために使用します。plt.axis('off')軸の表示をオフにするために使用します。plt.show()画像を表示するために使用します。
完全なコード
import pymysql
import pandas as pd
import os
import wordcloud
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
# MySQL数据库连接配置
db_config = {
'host': "XXXXXX", # 这里填写你自己申请的外部主机名
'port': xxxx, # 这里填写你自己申请的外部的端口
'user': "root", # 账户
'password': "", # 密码就是你自己创建实例时的密码
'database': 'tdsql', # 这里需要自己在自己创建的`tdsql`中创建数据库 ,
}
def create_table(table_name, columns):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 组装创建表的 SQL 查询语句
query = f"CREATE TABLE IF NOT EXISTS {
table_name} ("
for col_name, col_type in columns.items():
query += f"{
col_name} {
col_type}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ")"
# 执行创建表的操作
cursor.execute(query)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
def excelTomysql():
path = '词频' # 文件所在文件夹
files = [path + "/" + i for i in os.listdir(path)] # 获取文件夹下的文件名,并拼接完整路径
for file_path in files:
print(file_path)
filename = os.path.basename(file_path)
table_name = os.path.splitext(filename)[0] # 使用文件名作为表名,去除文件扩展名
# 使用pandas库读取Excel文件
data = pd.read_excel(file_path, engine="openpyxl", header=0) # 假设第一行是列名
columns = {
col: "VARCHAR(255)" for col in data.columns} # 动态生成列名和数据类型
create_table(table_name, columns) # 创建表
save_to_mysql(data, table_name) # 将数据保存到MySQL数据库中,并使用文件名作为表名
print(filename + ' uploaded and saved to MySQL successfully')
def save_to_mysql(data, table_name):
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 将数据写入MySQL表中(假设数据只有一个Sheet)
for index, row in data.iterrows():
query = f"INSERT INTO {
table_name} ("
for col_name in data.columns:
query += f"{
col_name}, "
query = query.rstrip(", ") # 去除最后一个逗号和空格
query += ") VALUES ("
values = tuple(row)
query += ("%s, " * len(values)).rstrip(", ") # 动态生成值的占位符
query += ")"
cursor.execute(query, values)
# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()
def query_data():
# 建立MySQL数据库连接
conn = pymysql.connect(**db_config)
cursor = conn.cursor()
# 查询所有表名
cursor.execute("SHOW TABLES")
tables = cursor.fetchall()
data = []
dic_list = []
table_name_list = []
for table in tables:
# for table in [tables[-1]]:
table_name = table[0]
table_name_list.append(table_name)
query = f"SELECT * FROM {
table_name}"
# # 执行查询并获取结果
cursor.execute(query)
result = cursor.fetchall()
if len(result) > 0:
columns = [desc[0] for desc in cursor.description]
table_data = [{
columns[i]: row[i] for i in range(len(columns))} for row in result]
data.extend(table_data)
dic = {
}
for i in data:
dic[i['word']] = float(i['count'])
dic_list.append(dic)
conn.commit()
cursor.close()
conn.close()
return dic_list, table_name_list
if __name__ == '__main__':
excelTomysql()
result_list, table_name_list = query_data()
for i in range(len(result_list)):
maskImage = np.array(Image.open('background.PNG')) # 定义词频背景图
# 定义词云样式
wc = wordcloud.WordCloud(
font_path='PingFangBold.ttf', # 设置字体
mask=maskImage, # 设置背景图
max_words=800, # 最多显示词数
max_font_size=200) # 字号最大值
# 生成词云图
wc.generate_from_frequencies(result_list[i]) # 从字典生成词云
# 保存图片到指定文件夹
wc.to_file("词云图/{}.png".format(table_name_list[i]))
print("生成的词云图【{}】已经保存成功!".format(table_name_list[i] + '.png'))
plt.imshow(wc) # 显示词云
plt.axis('off') # 关闭坐标轴
plt.show() # 显示图像
知らせ
コードを実行する前に関連パッケージをインポートしてください。
pip install pymysql
pip install pandas
pip install wordcloud
pip install numpy
pip install pillow
pip install matplotlib
コードを実行する
スクリーンショットを書き込む
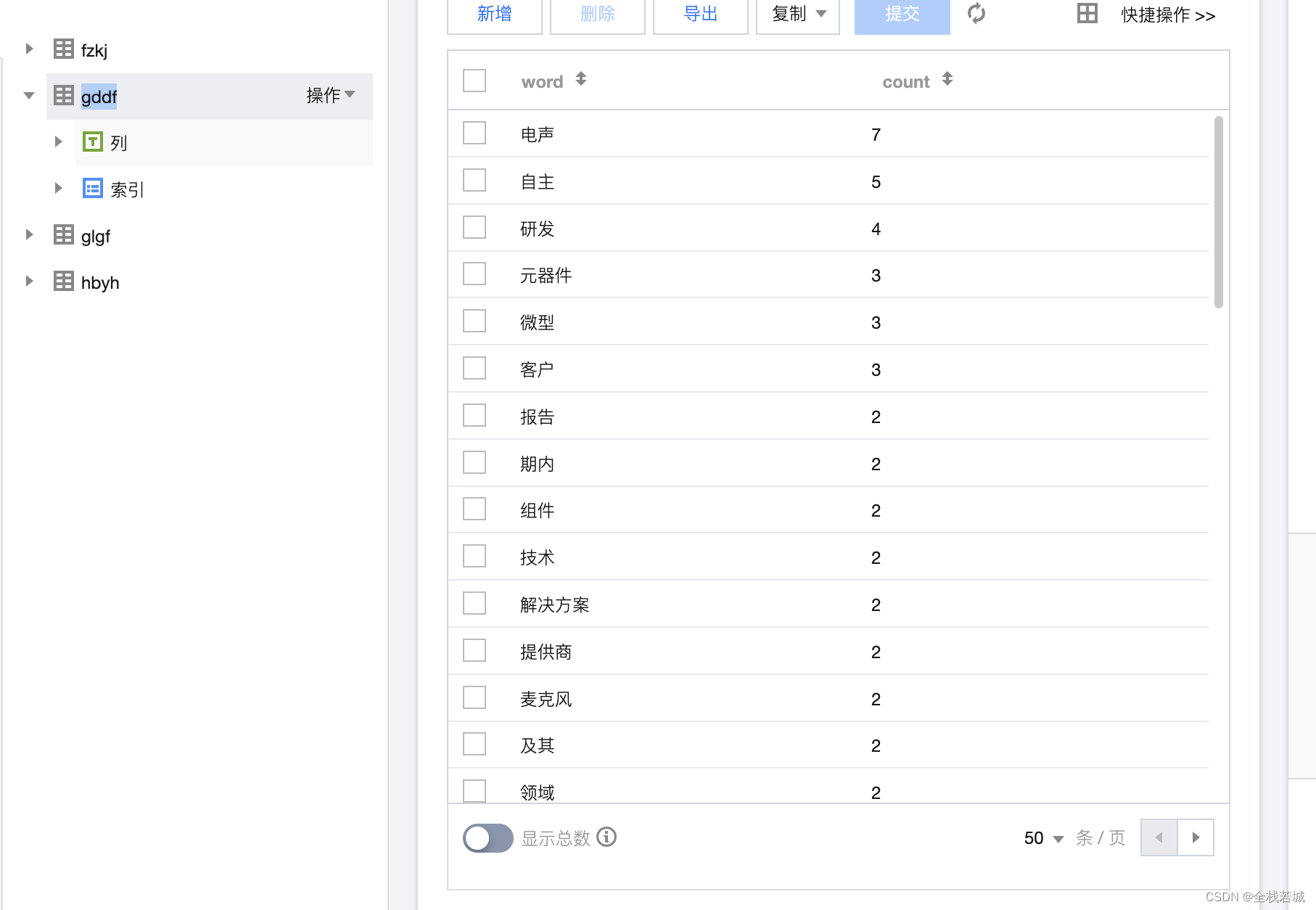
データベースデータのスクリーンショット
ワードクラウドを生成する

ワード クラウド マップをフォルダーに保存する

消去TDSQL
現在のビジネスでは無効な請求を防ぐためにデータベースを開き続ける必要がないため、データベースを削除すると、エクスペリエンスは完了しました。
図に示すように、破棄ボタンをクリックします。

インスタンスを破棄するためのポップアップ ウィンドウが表示されます。[OK] をクリックします。

ダウンロード
リソースは Baidu ディスクから取得されます。
リンク: https://pan.baidu.com/s/1hClOJI07HUuGBQ2SwZfWjw 抽出コード: 5mm9
– Baidu Netdisk スーパー メンバー v7 からの共有
要約する
使ってみる
TDSQLと、本当にシームレスなアクセスで、非常に滑らかだということがわかります。もちろん、いくつか欠点はありますが、改善されることを願っています。
アドバンテージ
- Tencent Cloud Database TDSQL の全体的な使用感とエクスペリエンスは非常に優れており、操作は比較的簡単で、シンプルな公式ドキュメントを使用して正常に構築できます。第 2 に、特に初心者にとって、コスト効率が非常に高いです。
- 従来のデータベースと比較して、TD-SQL Serverless の請求方法はより柔軟であり、実際に使用されたリソースに応じて請求方法が支払われるため、サーバーを長期間実行するコストがかかりません。同時に、アイドル状態のときに自動的にスリープすることもできるため、不必要なコストが削減されます。
欠点がある
- TD-SQL Serverless はリクエストが到着したときにのみリソースを割り当てて開始するため、最初のリクエストではある程度の遅延が発生する可能性があります。リアルタイム要件が高い一部のアプリケーション シナリオでは、遅延がユーザー エクスペリエンスに影響を与える可能性があります。
- 従来のデータベースと比較して、TD-SQL Serverless では構成および最適化のオプションが少なく、ユーザーによる基盤となるリソースの制御は限られています。これにより、特定の要件が満たされなくなる可能性があります。
- TD-SQL Serverless は需要に応じてコンピューティング リソースを自動的に拡張できますが、同時トラフィックが多いとコストが高くなる可能性があります。短期間に大量のリクエストが同時に発生した場合、追加料金が適用される場合があります。
これら 3 つの欠点は経験に基づく単なる推測であることに注意してください。間違いがあれば修正してください。