要約: この記事は元々、Grape City の技術チームによって CSDN に公開されたものです。転載元を明記してください:グレープシティ公式ウェブサイト、グレープシティは、開発者に力を与えるための専門的な開発ツール、ソリューション、サービスを開発者に提供します。
「できない」をデジタルトランスフォーメーションの障壁にしないでください
デジタル化のペースが加速するにつれ、ますます多くの企業がデータのプレゼンテーションとレポートに注力し始めています。元のデータの統合、クリーニング、二次処理はますます一般的になってきています。上記の機能を実現するために、企業は元のデータを処理するために多大な人的資源と物的リソースを費やす必要がありますが、ビジネスシナリオの急速な変化により、元のコードにハードコーディングされたデータ処理ロジックは大幅に逸脱します。実際のニーズ。これらを考慮すると、データ処理を自ら実現し、その処理結果を多次元で表示できるツールの実現が急務となっている。そこで今日は、Wyn ビジネス インテリジェンス ソフトウェアというソフトウェア ツールを皆さんにお勧めしたいと思います。
BI ソフトウェアとして、Wyn ビジネス インテリジェンス ソフトウェア自体は、さまざまな優れたビジュアル表示機能とセルフサービス BI 分析機能をサポートしており、基本的にほとんどの企業のデータ表示ニーズを満たすことができます。柔軟な埋め込み機能により、ユーザーは真に安心して置き換えることができます。そして、製品の開発に伴い、より強力で柔軟な表現も次々と導入され、より多くのユーザー シナリオに対応できるようになりました。今日は、数式を使用してすべてを実現する方法を確認するために、いくつかの一般的なユーザー シナリオを紹介します。リーダーが見たいデータをワンクリックで表示し、リーダーが満足する大画面を簡単に作成できます。
強力なデータ分析機能 - 式分析 (デモ付き)
式を紹介する前に、ソフトウェアのアプリケーション インターフェイスと基本的な使用方法を簡単に紹介します。(今回は、Wyn ビジネス インテリジェンス ソフトウェアのダッシュボード デザイナー レベルでの直接分析手法に焦点を当てています。すべての手法はダッシュボード上で直接追加できます)
分析式は、計算列とメジャーの 2 つのタイプをサポートします。
計算列: 元のテーブルに基づいて新しい列を追加することを指します。新しく追加された列は、使用される新しいフィールドに相当します。通常、プロセス計算の分析や新しいディメンション分析の作成に使用されますが、使用することもできます直接計算の場合。
測定値: 測定値は特定の集計操作を行う必要があります。バインドされた分類に基づいて設定した式が計算されるため、次元分析に基づいてさらに計算および分析され、生成される結果は次のとおりです。そのデータ自体が計算の結果であるため、数値フィールドで使用されます。
式インターフェイスの基本の概要:
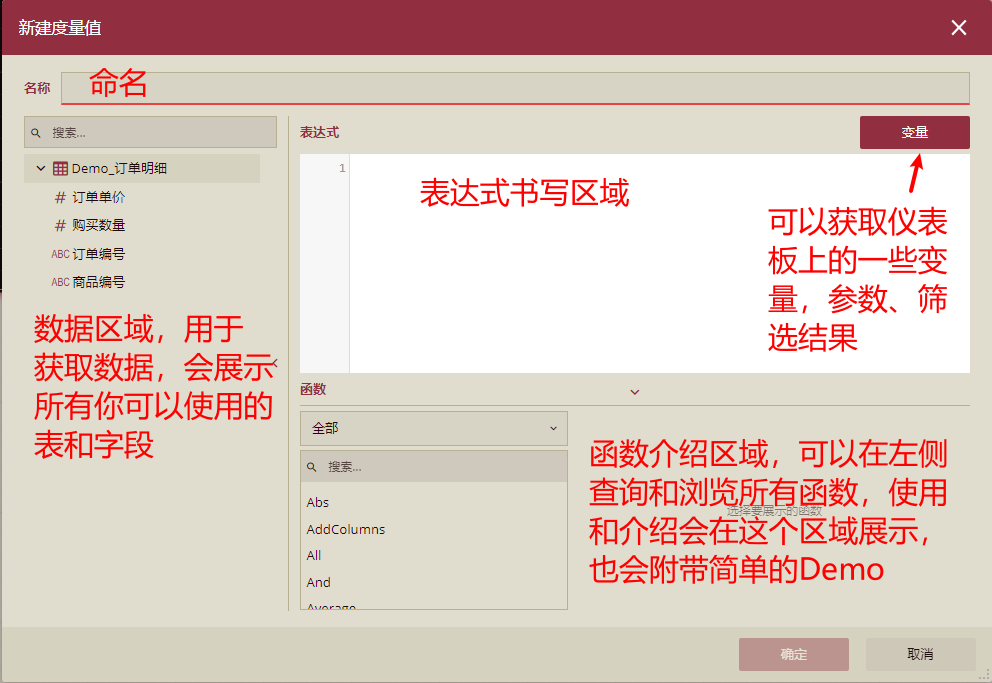
特に注意すべき点がいくつかあります。
1) 式を書くとき、通常は難しい式を複数の式に分割できます。たとえば、(a+b)*c の場合、最初に a+b の計算結果を新しい計算列として使用でき、その後、この計算列が c を乗算する新しいフィールドとして再利用されるため、共有フィールドは次のようになります。抽出され、再利用性が向上します。
2) Filter や Calculate などのフィルタリング関数を合理的に使用すると、式の計算をある程度高速化できます。特定の値が不要になった場合は、if の過剰な使用が減り、これらのデータは直接フィルタリングされて除外されます。表現の速度を向上させます。
「//」を使用してコメントを書くことができ、同時にいくつかの式に独自のコメントを追加して、将来の閲覧や他の人による引き継ぎを容易にすることができます。
3) 使用の過程で、'' 単一引用符は「テーブル名」を記述するために使用され、[] 括弧は「フィールド名」を記述するために使用され、「" 二重引用符は「文字列」を表します。例: '売上詳細'[注文金額] は、売上詳細テーブルの注文金額フィールドを表します。複数のテーブルに重複するフィールド名がない場合は、[] を使用してテーブル名なしでフィールドを直接参照できます。(注:すべて英字です)
詳細についてはヘルプドキュメントの紹介(https://www.grapecity.com.cn/solutions/wyn/help/docs/wax)を参照してくださいので、ここでは詳しく説明しません。ダイレクトスタート式の紹介:
- 前年比-前四半期比
多くの分析シナリオでは、月次分析、四半期分析、年次分析のいずれであっても、前年比と前月比が欠如することは決してないと思います。誰もが、前の時間次元または同じ期間と比較した変化に注目します。これはリーダーにこそ見てほしい基本的なデータ比較方法でもあります。
前年比分析:
前年比とは、実際には今年の合計と前年の合計を計算し、同じ期間の成長率を計算します。
したがって、最初のステップは、昨年の合計を計算することです。
var basetable = SelectColumns(
'同比测试',
"年度", '同比测试'[下年度],
"订单金额",'同比测试'[订单金额])
return Calculate(
SumX(basetable,[订单金额]), Values([年度]))
上記の式では、まず一時テーブルが作成され、年と金額という 2 つの新しいフィールドが一時テーブルに追加されます。このうち、年は今年の翌年、つまり年+1となります。そして今年は、次の式でフィルター条件として使用するものです。
2 番目の式では、まず新しく作成したテーブルを使用して金額を合計し、次に「年」フィールド (値[年]) をフィルターします。実際の値を取得すると、関連付けに従ってフィルタリングされ、対応する前年比の値が取得され、前年比の計算で十分になるためです。詳細については、以下の図を参照してください。

Divide('前年比テスト'[今年の合計] - '前年比テスト'[昨年の合計], '前年比テスト'[昨年の合計])
最後のステップは前年比を計算することですが、この式は非常に簡単で、今年の合計から昨年の合計を引いて、さらに今年を引くと、それが成長率となります。
リング分析:
前年比ベースでは、チェーンレシオは実質的に同じです。前年比は昨年から取得され、四半期チェーンは前四半期または先月から取得されます。同じ四半期を例にとると、式は次のようになります。
var basetable = SelectColumns(
'同比测试',
"年度", '同比测试'[环比年度],
"季度", '同比测试'[环比季度],
"订单金额",'同比测试'[订单金额])
return Calculate(
SumX(basetable,[订单金额]), Values([年度]))
原則は同じで、まず一時テーブルを作成し、その一時テーブルの前年比および四半期比の計算を使用します。ここで前年対前年比の把握を参照することができますが、計算対象が上期3四半期の場合は当然何も処理する必要はなく、1つ加算するのが当然ですが、第 4 四半期、現時点では第 5 四半期がないため、年と一致させる必要があり、まず年に 1 を加えてから、四半期の第 1 四半期に戻ります。つまり、第 2 四半期の第 1 四半期に戻ります。年。それが完了したら、上記の方法に従って計算してフィルタリングし、フィルタリングを行うために年を渡します。
データの準備ができたら、プレゼンテーション リンクです。システムによって作成されたデータをページにドラッグ アンド ドロップするだけで、その効果を確認できます。

この時点で、前年比分析は完了です。
- 区間分析
ビジネス分析シナリオでは、全画面に売上データが表示され、さまざまな地域の売上高が区別なくランダムに配置されていることがよくあります。このとき、最終データに対して区間解析を行う必要があります。たとえば、どの地域の売上が 100w ~ 200w で、どの地域の売上が 200w ~ 300w であるかを知りたいとします。
このシナリオでは、どのように実装する必要がありますか? 一緒にアイデアを整理しましょう。
まず、さまざまな地域に応じて金額の合計を求めるかどうかは明らかです。次に、これらの地域をさまざまな売上レベルに応じて分割する必要があります。このようにして、データを複数の間隔に分割して分析できます。具体的な実装方法は以下の通りです。
var sales = SUMX('订单明细','订单明细'[购买数量]\*'订单明细'[订单单价])
var sales1 =
calculate(sales,Values('销售大区'[大区]))
var categories=
SWITCH(
TRUE,
sales1 \< 8000000, "小于800万",
sales1 \>= 8000000 && sales1 \< 12000000, "大于800万小于1200万",
sales1 \>= 12000000 , "大于1200万"
)
return categories
上記の最初のステップは金額の合計を求めることであり、求めた後、地域に応じてフィルターを実行する必要があります。このフィルタリングはデータ バインディング時に自動的に行われ、計算された量が目的の範囲に応じて分割されるため、新しいフィールド (計算列) が取得され、同時にデータが分割されます。次はデータ表示のリンクです。

- RFMモデル分析
RFM モデルは、上で説明した一般的なアプリケーションに加えて、販売指標の観点からも非常に重要な測定指標です。顧客価値の分析に使用できるため、アナリストはどの顧客がより重要であるかをより明確に知ることができます。
- R (Recency)、最新の消費間隔
- F(周波数)、消費周波数
- M(Money)、消費額
一般的に、直近の消費間隔が短く、消費頻度や消費量が多いほど、顧客価値は大きくなります。この原則に基づいて、対応する平均 R、F、M をそれぞれ計算し、顧客が平均より大きいか小さいかを比較する必要があります。平均より大きいものは当然価値が高くなります。
アイデアから始めて、最初に平均 R、F、M を計算します
R_Avg
CALCULATE(
AVERAGEX(
SUMMARIZECOLUMNS(
'Customer'[Name],
"rdayValues",
datediff(
'Sales'[Rday],
'Sales'[Rmax],
day
)
),
[rdayValues]
),
REMOVEFILTERS('Customer'[Name])
)
上記の datadiff は、顧客の最終消費日からビジネスの最新取引日までの日数を計算し、平均値を計算します。これは平均値であるため、フィルターも削除する必要があります。削除しないと、分類をバインドするときに自動的に分類されます。
F_Avg
CALCULATE(
AVERAGEX(
SUMMARIZECOLUMNS(
'Customer'[Name],
"fCount",
calculate(
DISTINCTCOUNTX('Sales','Sales'[Order Number])
)
),
[fCount]
),
REMOVEFILTERS('Customer'[Name])
)
ここでは実際に顧客消費の一意の数、つまり DISTINCTCOUNTX を要求し、前と同じようにすべての平均を計算してフィルタリングを削除しています。
M_Avg
CALCULATE(
AVERAGEX(
SUMMARIZECOLUMNS(
'Customer'[Name],
"mValues",
calculate(
'Sales'[M]
)
),
[mValues]
),
REMOVEFILTERS('Customer'[Name])
)
最後は消費量の平均値で、式中の[M]を集計した後はやはり平均と除去フィルターです。
上記は計算された平均値、つまり顧客の消費量を測定し、各顧客独自の値を計算するために使用される比較フィールドです。上記の式では、各エンドで RemoveFilters が使用されていることがわかります。フィルターを解除する機能です。その結果、Wyn の実際の計算はバインドした分類に基づいて行われることになります。つまり、値はバインドした分類によって異なるため、各顧客の実際の値の計算は非常に簡単になり、上記のすべてを削除します。式 AVEGAGEX 、removeFilters を削除します。つまり、平均化を削除し、フィルターを削除します。これは各顧客独自のデータです。
R:DATEDIFF( 'Sales'[Rday], 'Sales'[Rmax], Day )
F:DISTINCTCOUNTX('Sales','Sales'[Order Number])
M:SUMX( 'Sales', 'Sales'[Quantity]\*'Sales'[Net Price] )
そして、それぞれの顧客が持つ価値を用いて平均値で判断し、顧客の価値が高いかどうかを判断します。このようにして、すべてのデータを区別できます。
R↑F↑M↑: 重要な顧客
R↑F↑M↓: 一般価値顧客
R↑F↓M↑: 重要な開発顧客
R↑F↓M↓: 一般開発のお客様
R↓F↑M↑: 顧客を維持することが重要
R↓F↑M↓: 通常、顧客を維持します
R↓F↓M↑: 顧客を維持することが重要
R↓F↓M↓: 通常、顧客を維持します
次に、その値を見つけるために、3 つの次元が実際には同じであるかどうかを確認します。
R:IF( 'Sales'[R]\<='Sales'[Ravg], "R_UP", "R_DOWN" )
F::IF( 'Sales'[F]\<='Sales'[Favg], "F_UP", "F_DOWN" )
M:IF( 'Sales'[M]\<='Sales'[Mavg], "M_UP", "M_DOWN" )
これまでに、顧客価値分析のためのデータモデルが形成されました。最終的な表示結果を見てみましょう。
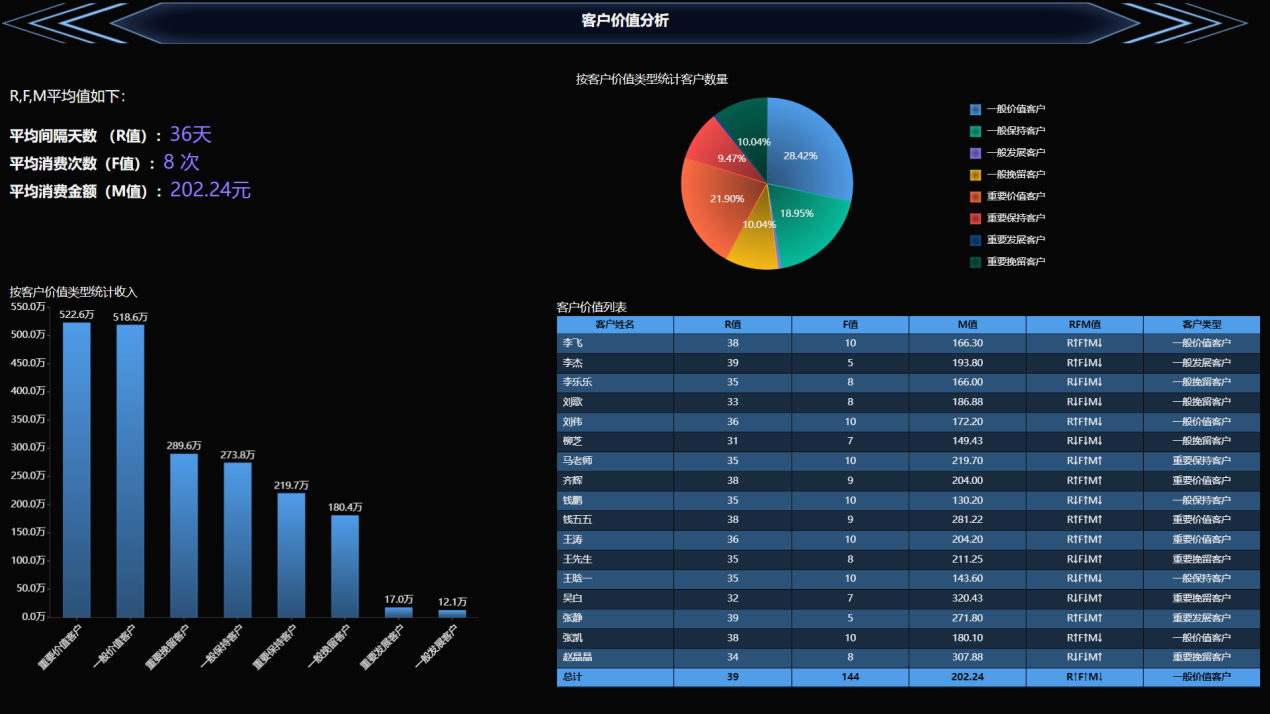
ここまで紹介してきましたが、皆さんも Wyn ビジネス インテリジェンス ソフトウェアの強力でクールなインターフェイスを見たことがあると思います。ここでは、時間、テキスト、数値などの複数のレベルからデータを分析できる、実際には数十の異なる式が含まれるいくつかのメソッドを簡単に紹介します。また、記事で言及されている式に加えて、Wyn ビジネス インテリジェンス ソフトウェアには、グラフ上に直接設定できる並べ替え、フィルタリング、ランキング、およびフィールドの書式設定機能も備わっています。ユーザーが完全な BI かんばんを簡単に作成できるようにします。
Wyn ビジネス インテリジェンス ソフトウェアは、BI 設計レベルでの式計算に加えて、式計算、グループ計算、データ取得レベルでの権限制御などの完全な機能も実行できます。B/Sアーキテクチャソフトウェアなので、お客様はサーバーにアクセスするだけで大画面のデザインや表示が可能です。
さらに、Wyn ビジネス インテリジェンス ソフトウェアは何百もの異なるインターフェイスを提供しており、ユーザーは既存のシステムや製品に安心して組み込むことができます。呼び出し元は、それを個別に表示したり、インターフェイスを個別に呼び出してプラットフォーム データを取得したりすることができます。また、情報漏洩を防ぐための完全な権限制御も備えています。同時に、シングルサインオンを統合し、システム内の既存の社内担当者をデータの整理と管理に利用することも可能です。とても素晴らしいソフトウェアなので、すぐに試してみないでください。
拡張リンク:
Spring Boot フレームワークでの Excel サーバー側のインポートとエクスポートの実装
Project Combat: オンライン見積調達システム (React +SpreadJS+Echarts)
SpreadJS と組み合わせた洗練されたフレームワークにより、純粋なフロントエンド Excel オンライン レポート デザインを実現