前のセクションでは、データ プラットフォームのデータ品質を確保し、データを「正確」にする方法について説明しました。データセンターは「速い」「正確」に加えて「節約」も切り離せません。データの規模がますます大きくなるにつれて、コストはますます高くなり、コストが合理的に管理されなければ、データの応用価値を掘り出す前に企業の利益が消費されてしまいます。
緻密なコスト管理を実現できるかどうかが、データセンタープロジェクトの成否に関わってきます。
電子商取引ビジネスのデータ構築リソースの成長傾向 (CU= 1vcpu + 4G メモリ):
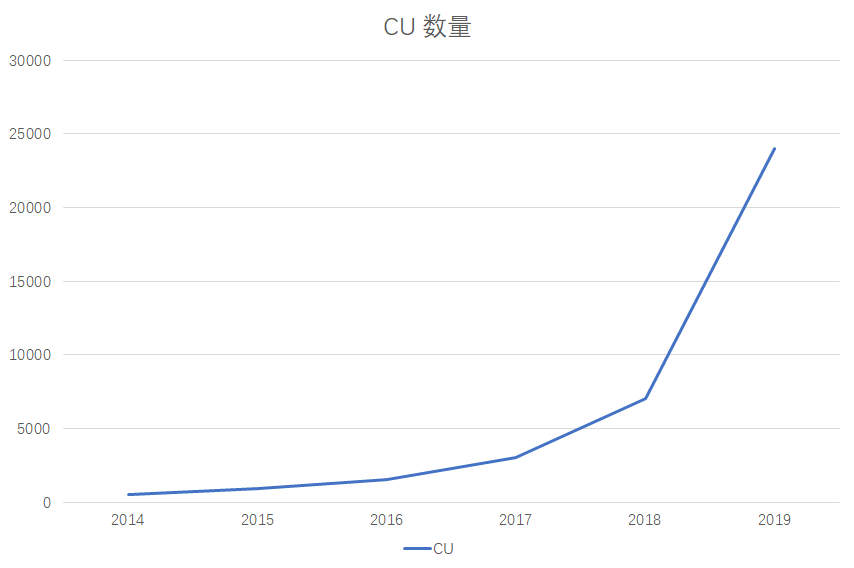
電子商取引プラットフォームのビッグデータリソース消費量は成長傾向にあり、2019年の年間リソース規模は25000CU、年間マシン予算は3500Wです。明らかに、スタートアップにとっては小さな出費ではありません。
ある日、データ チームの責任者である Li Haoliang は CEO からオフィスに呼び出されました。
- この3500Wは何の事業に使われるのでしょうか?
- どのようなコスト最適化策を講じており、その効果はどの程度ですか?
Li Wen は当惑しながら、こう考えました。チームのコストは、データ アプリケーションではなく、マシンに基づいて計算されます。データセンターでは、データ アプリケーション間の基盤となるデータが多重化されているため、各データ製品やレポートにどれだけの費用が費やされているか、そのようなデータがない場合はどうやって知ることができますか。
しかし、これらは CEO にとって非常に重要です。リソースには限りがあるため、戦略目標の主要なノードでリソースが確実に使用されるようにする必要があります。たとえば、今年の e コマース チームの中核となる KPI は、プラットフォーム上の 1 人の登録メンバーの消費を増やすことであり、上司の観点からは、次のような KPI 関連のビジネスにリソースが確実に投資されるようにする必要があります。データに基づいて登録メンバーのターゲットを絞ったマーケティングを行い、プラットフォーム上のメンバーの消費を増やします。
あなたのチームでも同様のことが起こったことがありますか? データ部門は企業のコストセンターであり、その価値を実証するには次のようにします。
- ビジネスをしっかりサポートし、ビジネス上の評価を得る
- コストを合理化し、会社のお金を節約します
したがって、今日はお金の節約と、データ プラットフォームの洗練されたコスト管理について話すことに焦点が当てられています。
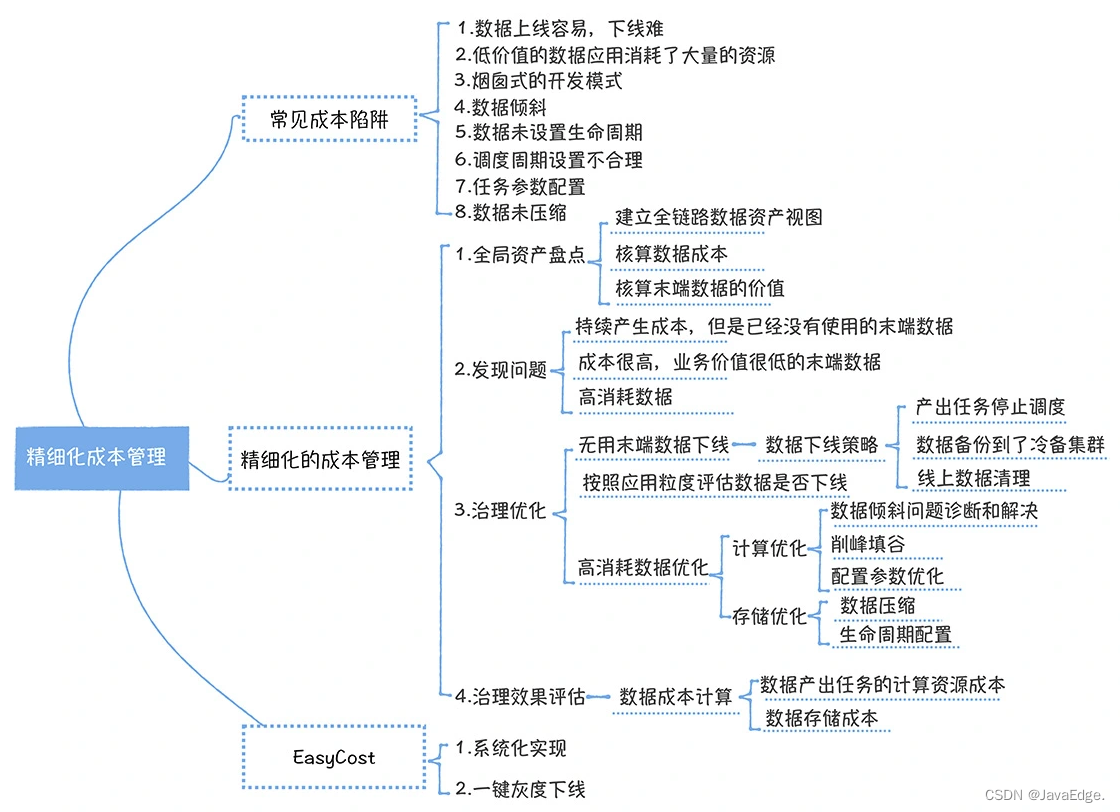
1 コストトラップ
初めてデータセンターを構築するときは、コスト管理の問題を無視して、新しいサービスへのアクセス、データ統合、データ価値のマイニングに重点を置く傾向があり、その結果、罠にはまり、コストが爆発的に増加します。したがって、落とし穴を深く理解し、日々の開発において落とし穴を回避するように努める必要があります。
以下に8つの罠を紹介します。
- 1~3は広く存在するが無視されやすい
- 4 ~ 8 はデータ開発のスキルを必要とするため、開発時に注意してください。
「それが何であるかを知るが、それよりも重要なのはなぜそうなるのかを知ること」によって、問題の本質を発見し、問題を解決する方法を深く理解することができます。
1.1 オンラインでデータを取得するのは簡単ですが、オフラインで取得するのは困難です
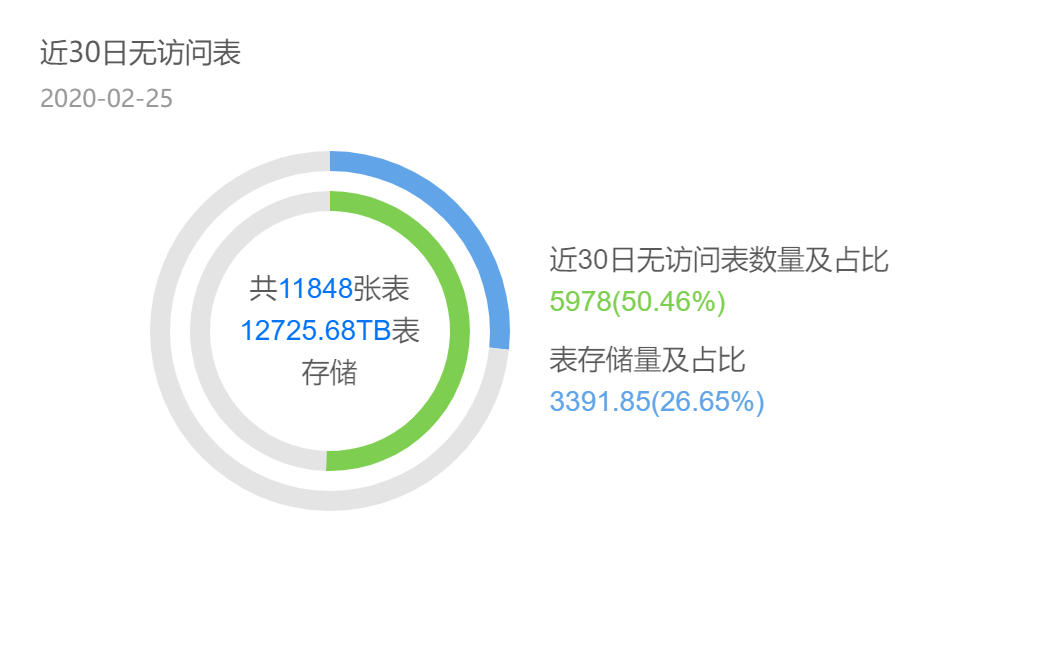
データセンター プロジェクトの場合、テーブル関連の使用統計。テーブルの半分は 30 日以内にアクセスされず、これらのテーブルがストレージの 26% を占めます。これらのテーブルの出力タスクを個別に取り出すと、ピーク時には5000コアのCPUコンピューティングリソースが消費され、サーバ換算で125台のサーバが必要となります(1台のサーバに割り当てられるCPU 40コアを基に計算) )、コストは年間500W近くになります。実際のところ、無駄なデータがたくさんあるのでしょうか?私はよく携帯電話のデータと写真を比較しますが、写真を撮ったり画像を生成したりし続けますが、それらを消去するのが面倒で、最終的には携帯電話のストレージが不足することがよくあります。
データの消去が間に合わず、データ開発も難航している。彼らはテーブルを知りません:
- 他のタスクが参照しているもの
- 他に問い合わせている人は誰ですか
当然、このテーブルのデータ処理はあえて止めず、オンラインでデータを取得するのは簡単ですが、オフラインでデータを取得するのは困難にします。
1.2 価値の低いデータ アプリケーションは大量のリソースを消費します
データは毎日アクセスされているように見えますが、データはどれだけの価値を生み出し、ROI はそれだけの価値があるのでしょうか?
幅の広いテーブル (多くの列を含むテーブル。データ センターの下流のサマリー レイヤー データによく表示されます) に加えて、リンクを上流で処理するタスクがあり、この幅の広いテーブルの処理には 1 日あたり 6,000 元、1 回あたり 200 W のコストがかかります。その後、この広いテーブルを実際に使用しているのは毎日 1 人だけで、今も運営インターンであることが分かりました。明らかに、入力と出力の間には大きな不一致があります。
間接的に、データ部門は新しいデータ製品によってビジネスにもたらされる価値にはより注意を払いますが、既存の製品やレポートにまだ価値があるかどうかは無視され、最終的には価値の低いアプリケーションが依然として多くのリソースを消費することにつながります。
1.3 煙突開発モデル
研究開発の効率が低いだけでなく、データの繰り返し処理によりリソースが無駄になります。500T テーブル、このテーブルの処理、コンピューティング タスクは、ピーク時に 300 コアを消費する必要があります。これは、サーバー 7 台 (サーバーに割り当て可能な CPU 40 コアに基づいて計算) にストレージ ディスク コスト (サーバーに割り当てられる CPU 40 コアに基づいて計算) に相当します。 0.7 元/TB*日)、a 年間消費量は 40 W です。
また、このテーブルを再利用するたびに 40W を節約できます。したがって、モデルを再利用するとコストも節約できます。
4 番目に、データのスキューです。
データ スキューはタスクのパフォーマンスを低下させ、多くのリソースを無駄にします。
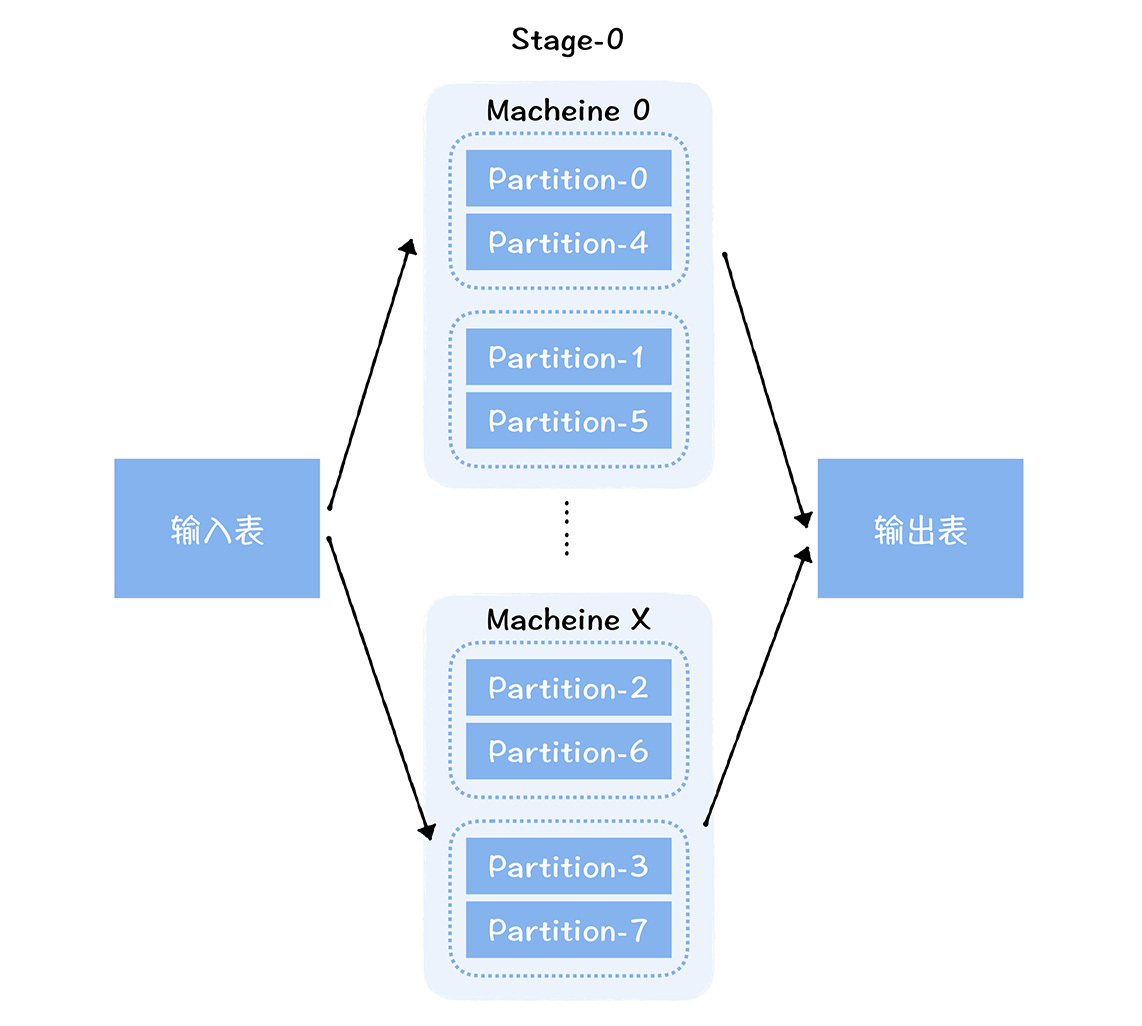
バレル効果について聞いたことがあるはずです。バレルにどれだけの水が入るかは、主に最も短いボードによって決まります。この効果は、分散並列コンピューティング フレームワークにも存在します。Spark コンピューティング エンジンでは、大量のデータを異なるパーティション (Partition) に分割し、異なるマシン上で実行されるタスクに割り当てて並列コンピューティングを実行することで、コンピューティング パワーの水平方向の拡張を実現します。
ただし、タスク全体の実行時間は、実際には最も長く実行されているタスクに依存します。各シャードのデータ量は異なる場合があるため、各タスクに必要なリソースも異なります。異なるタスクに異なるリソースを割り当てることはできないため、タスクの総リソース消費量 = max {1 つのタスクによって消費されるリソース} * タスクの数となります。このように、データ量が少ないタスクはより多くのリソースを消費し、リソースの無駄が発生します。
電子商取引のシナリオの例を見てみましょう。
加盟店の粒度に応じて各加盟店の取引金額をカウントする必要がある場合、このとき、加盟店ごとの注文フローテーブル上でグループごとに計算を行う必要があります。プラットフォーム上では、各加盟店の注文取引量は大きく異なり、取引量が多い注文もあれば、比較的少ない注文もあります。
Spark SQL を使用して計算プロセスを完了します。
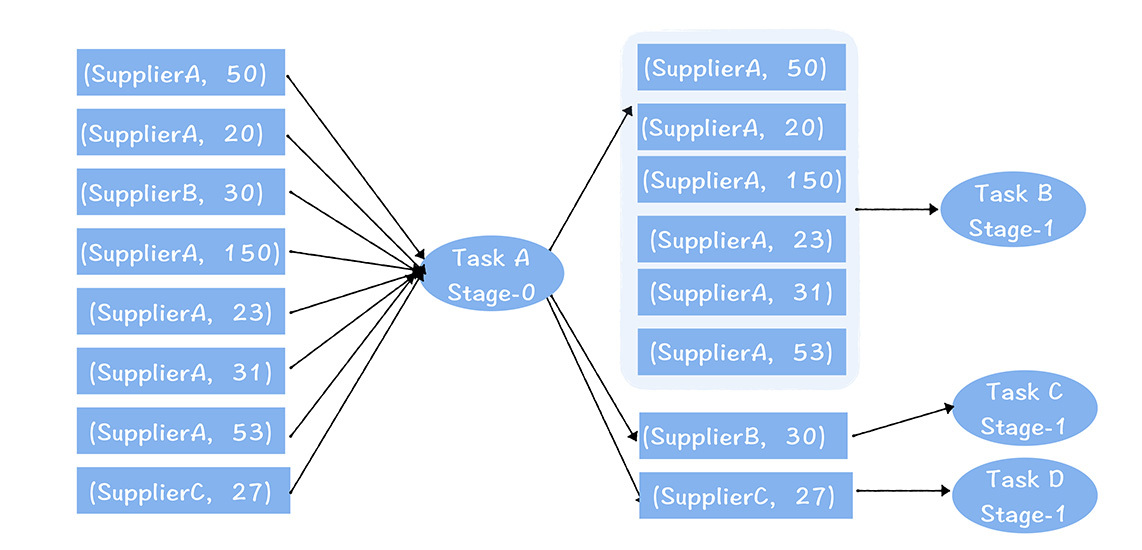
上図では、タスクAが左側のシャードのデータを読み込み、提供者ごとに集計し、次段のタスクB、C、Dに出力します。
集約後、タスク B、C、および D によって入力されるデータの量が大きく異なることがわかります。B は C および D よりも多くのデータを処理し、必然的により多くのメモリを消費します。単一の Executor が 16G を割り当てる必要があるとします。一方、B 、C、D で異なるメモリ サイズを設定することはできないため、C と D も 16G に設定されます。しかし実際には、C と D のデータ量からすると、4G だけで十分です。これにより、C タスクと D タスクに対するリソース割り当てが無駄になります。
第 5 に、データはライフサイクルを設定しません。
講義 06では、一般的な元データと詳細データは完全な履歴データを保持することを強調しました。アグリゲーション層、マーケットプレイス層、またはアプリケーション層では、ストレージコストを考慮してライフサイクルに従ってデータを管理し、通常はスナップショットまたはパーティションを数日間保持することが推奨されます。ライフサイクルを設定しないで大きなテーブルがあると、ストレージ リソースが無駄に消費されます。
第六に、スケジューリングサイクルが不合理である。
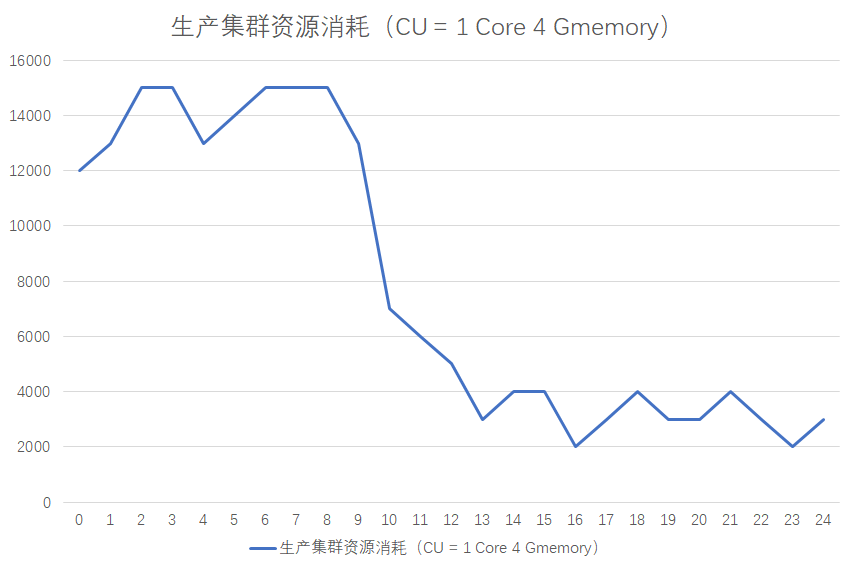
この図から、ビッグ データ タスクのリソース消費には明らかなピークと谷の影響があることがわかります。一般に、ピーク期間は午後 12 時から翌日の 9 時までで、谷期は 9 時からです午後から正午まで。
タスクには明らかなピークとボトムの影響がありますが、サーバー リソースには弾力性がないため、サーバーが谷期には比較的アイドル状態であり、ピーク期にはビジー状態になる状況が発生します。クラスター全体のリソース割り当ては、クラスター全体のリソース割り当ては、その期間中のタスクの消費量に依存します。最盛期。したがって、ピーク時に実行する必要のないタスクの一部をオフピーク時に実行するように移行すると、リソースの消費を節約することもできます。
7 番目に、タスクパラメータの設定。
タスクパラメータを不合理に設定すると、リソースが無駄になることがよくあります。たとえば、Spark では、エグゼキュータのメモリ設定が大きすぎ、CPU 設定が高すぎ、Spark で動的リソース割り当て戦略が有効になっていない場合、すでにタスクを実行した一部のエグゼキュータは解放できず、特にリソースを占有し続けます。データの偏りがある場合、リソースの無駄がより明らかになります。
第 8 に、データは圧縮されていません。
高可用性を実現するために、Hadoop の HDFS はデフォルトでデータのコピーを 3 つ保存するため、ビッグ データの物理ストレージの消費量は比較的多くなります。特に、元のデータ層と詳細データ層の一部の大きなテーブルの場合は、簡単に 500 T を超える可能性があり、物理ストレージに相当するのは 1.5P (コピーが 3 つであるため、実際の物理ストレージは 500 3)、約 16 台の物理サーバーが必要になります ( 1 台のサーバーに割り当てることができるストレージは12 8T に基づいて計算されます)。圧縮が有効になっていない場合、ストレージ リソースのコストが高くなります。
さらに、Hive または Spark の計算プロセス中に、中間結果も圧縮する必要があります。これにより、ネットワーク送信量が削減され、Shuffer (Hive または Spark の計算プロセス中に異なるノード間でデータを送信するプロセス) のパフォーマンスが向上します。スパーク)。
ご存知のとおり、私はあなたのために典型的なコストの罠を 8 つリストアップしました。それでは、先生、私はすでに採用されているのですが、どうすればよいでしょうか? 安心してください。洗練された原価管理を実行する方法を見てみましょう。
2 洗練された原価管理を実現するには?
コストガバナンスは、在庫全体、問題発見、ガバナンスの最適化、効果評価の4つのステップに従う必要があります。

2.1 世界の資産目録
データセンター内のすべてのデータの包括的なインベントリを実行し、メタデータセンターによって提供されるデータ系統に基づいてフルリンクのデータ資産ビューを確立します。
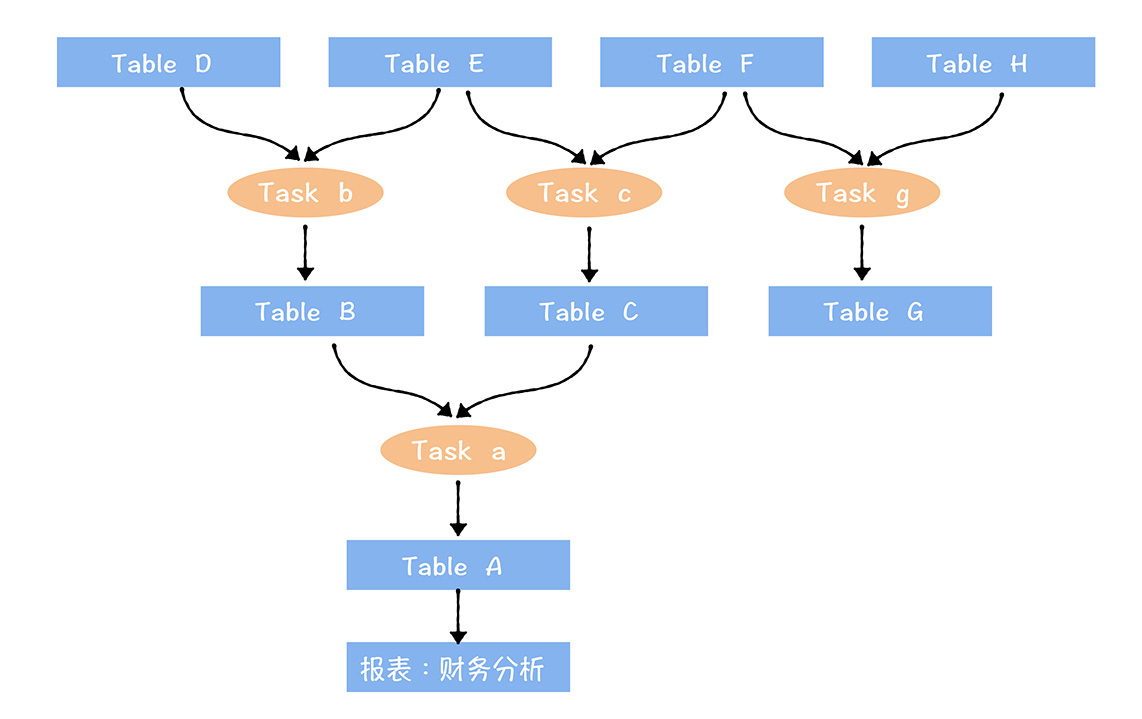
完全なリンク データ アセット ビュー:
- 下流端はデータ アプリケーションに接続されます (レポート: 財務分析)
- 上流の開始点は、データセンターに入ったばかりの生データです
- データはタスクを通じて接続されます
フルリンク データ資産ビューで端末データのコストと価値を計算します (端末データは、図のテーブル A やテーブル G など、処理リンクの最下流のテーブルです)。
なぜ最後から始めなければならないのですか?中間データの値を計算する際には、下流のテーブルの利用も考慮する必要があり、明確に計算することが難しいため、最終データから計算していきます。これはオフラインテーブルの順序とも一致しており、例えばデータの価値が低くコストが高い場合、オフラインデータは末尾のデータから開始されます。
データコストはどのように計算すればよいですか?
上図の財務分析レポートのコストを計算します。このレポートの上流リンクには、a、b、c、3 つのタスク、A、B、C、D、E、F、6 つのテーブルが含まれます。
このレポートのコスト = 3 つのタスクの処理で消費されるコンピューティング リソースのコスト + 6 つのテーブルで消費されるストレージ リソースのコスト。
テーブルが複数の下流アプリケーションによって再利用される場合、テーブルのストレージ リソース コストと出力タスクのコストを複数のアプリケーション間で配分する必要があります。
値はどのように計算すればよいでしょうか?
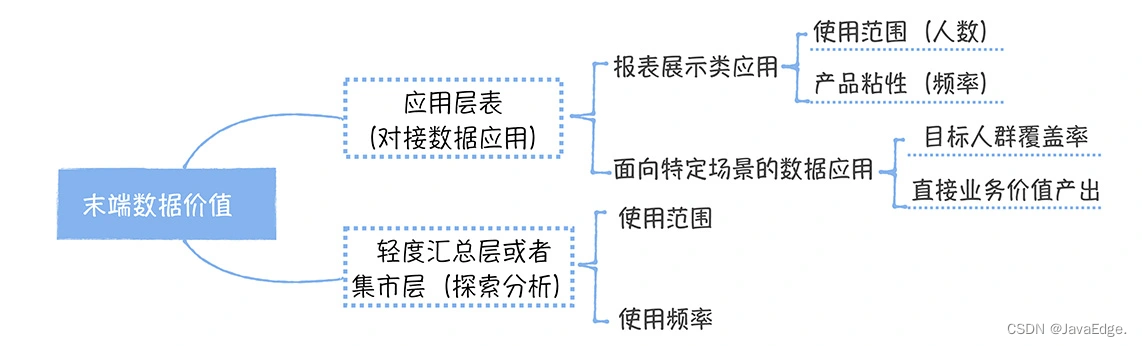
端末データがデータ レポートに接続されているアプリケーション層テーブルである場合、このデータの値は主にレポートの使用範囲と頻度によって決まります。
使用範囲を計算する際には、通常、週次の活動評価が使用され、さまざまな管理レベルの人々の重みも考慮する必要があり、上司の場合、その重みだけで一般従業員 1,000 人に相当する場合があります。したがって、管理レベルが高くなるほど経営上の意思決定に与える影響が大きくなり、自然価値も大きくなるということを考慮した設計となっております。使用頻度は通常、1 人のユーザーが毎週レポートを閲覧する回数で測定され、回数が多いほどレポートの価値が高くなります。
例えば、端末データのドッキングはデータレポートではなく、特定のシナリオ(主にサプライチェーン部門を対象とした前述のサプライチェーン分析および意思決定システムなど)向けのデータアプリケーションです。このような製品の価値を測定するには、対象となる母集団のカバー率と直接的なビジネス価値の出力が主に考慮されます。直接的なビジネス価値の成果とは何ですか? は、サプライ チェーンの意思決定システムにおいて、すべての発注書に対するシステムによって自動的に生成された発注書の割合です。
端末データは依然として市場レベルのテーブルである可能性があり、主にアナリストに探索的なクエリを提供するために使用されます。このタイプのテーブルの価値は、どのアナリストがそれを使用するか、およびどのくらいの頻度で使用されるかによって異なります。スコープ評価を使用する場合、アナリストはレベルによっても重み付けされます。
2.2 問題が見つかった
グローバル インベントリは、次の点に焦点を当てて、問題を発見するためのデータ サポートを提供します。
コストが発生し続けるが使用されなくなったサポート終了データ (通常、30 日以内に訪問がないことを指します)
使用されていないのにコストがかかっているテーブルは、先ほど述べたトラップ 1 に該当します。
データ アプリケーションの価値は非常に低いですが、コストが高くなります。これらのデータは、アップストリーム リンク上のすべての関連データに適用されます。
低価値の出力および高コストのデータ アプリケーションはトラップ 2 に該当します
ピーク時のデータ消費量が多い
高コストのデータ、落とし穴 4 ~ 8 に対応

落とし穴 3 については、実際にはセクション 6 モデル設計で対処します。
2.3 ガバナンスの最適化
これら 3 種類の問題に対して適切な戦略を立ててください。
最初のカテゴリは、テーブルのオフラインを処理することです。オフラインにするときは注意してください。オフラインになるデータの実行プロセス図を参照してください。

端末データが削除された後は、元の端末データの上流データが新しい端末データとなり、すべての端末データがオフライン戦略を満たさなくなるまで、問題の発見からガバナンスの最適化までを繰り返す必要もあります。
2 番目のタイプの問題については、アプリケーションの粒度に従ってアプリケーションがまだ必要かどうかを評価する必要があります。レポートの場合は、30 日以内にアクセスされなかったアプリケーションを自動的にオフラインにするポリシーに従い、最初にレポートを破棄し、次にレポートの上流のテーブルをオフラインにすることができます。テーブルが他のアプリケーションによって参照されている場合、オフラインにすることはできません。 。オフライン手順については、前のオフライン手順を参照してください。
3 番目のタイプの問題は、主に消費量の多いデータを対象としており、特に、出力データの消費量が多いタスクとデータ ストレージの消費量が多いタスクに分けられます。出力タスクの消費量が多い場合、最初に考慮すべきことは、データ スキューがあるかどうかです。どのように判断するか?実際、MR または Spark ログ内の Shuffer データの量によって判断できます。非常に大量のデータを含む特定のタスクがあり、他のタスクがほとんどない場合、データ スキューがあると判断できます。
図 Spark タスクのシャッファー レコード:

図 MR削減タスク記録:

データスキュー処理?
さまざまなシナリオに適用できるソリューションがいくつかあります。
- たとえば、いくつかの大きなテーブルが小さなテーブルに関連付けられている場合、キーの不均一な分散によりデータ スキューが発生するため、マップジョインを使用できます。
- より一般的な処理方法 (ホットスポット キーを個別に処理し、次に残りのキーを処理して、その結果を結合するなど)
データの偏りに加えて、タスクの構成パラメータも確認する必要があります。Spark 実行エンジンなど:
- 執行者の数が多すぎませんか?
- executor-coreとexecutor-memoryが多すぎて使用率が低いかどうか
一般に、executors-memorty は 4G ~ 8G に設定され、executor-cores は 2 ~ 4 に設定されます (使用率が最も高い構成項目が実践されています)。
また、そのタスクが本当にピーク時に実行する必要があるのかを検討する必要があり、クラスタの負荷状況に応じて、可能な限りオフピーク時にタスクを移行することで「ピークをカットし、ピークを埋める」ことができます。谷"。
上記の点は、出力タスクの消費量が多いことです。
ストレージ消費量が比較的大きいタスクの場合は、最初に圧縮するかどうかを検討します。特に元のデータ層と詳細データ層については、圧縮することをお勧めします。
圧縮方法

- 小さなファイルの圧縮には、分割に関係なく、gzip の方が適しています。
- 大容量ファイルの場合はlzo推奨、分割対応 圧縮効率の確保を前提に比較的安定した圧縮率を実現
有効期間が設定されているかどうかも考慮してください。
- ODS 生データ レイヤーと DWD 詳細データ レイヤー、永久保存戦略に適しています
- 一部の製品およびユーザーのディメンション テーブルでは、3 ~ 5 年の保存戦略が考慮される場合があります。
全体として、基礎となるテーブルは長期間保持されます。概要レイヤーより上のテーブル (概要レイヤーを含む) に重点を置く必要があり、一般に、データの重要性に応じて 7 日間および 1 か月の保存戦略を策定できます。
ガバナンス効果評価
ガバナンスの結果を定量化 - どれだけのお金が節約されたか
サーバーの数を直接測定した場合、ガバナンスの効果を正確に反映することはできません。ビジネスの成長の理由も考慮する必要があり、タスクとデータのコストも考慮する必要があるためです。
- オフラインになっているタスクとデータの数
- これらのタスクは 1 日にどれくらいのリソースを消費しますか
- データが占有するストレージ容量
これらのリソースを使用してコストを計算すると、どれだけのお金を節約できたかを計算できます。たとえば、最初のケースでは、タスク A は 3 時間実行され、実行プロセス中に合計 5,384,503 CPU* と 3,700,7892 GB * を消費します。1 CU (1 CPU、4g メモリ) のコストが 1,300 であると仮定します。年間元、1日あたり3.5元に相当します(計算式は1300/365)。
オフピーク時間の最適化では実際にリソースを節約できないため、最適化タスクであるかオフライン タスクであるかに関係なく、ピーク時間のみがカウントされます。
ピーク時間は 8 時間で、これは 1 秒あたり 0.00012153 のコストに相当します。その場合、タスクのコストは max{5384503*0.00012153, 37007892/4 * 0.00012153} = max{654, 1124} = 1124 となります。オフライン タスク後に 1124 元を節約し、テーブル A が占有するストレージ領域に GB あたりのコストを乗算すると、データ テーブル A がオフラインのときに節約されたコストを取得できます。
原価管理センター
コストガバナンスは一度きりの仕事ではなく、継続的に問題点を発見し、ガバナンスを最適化する根気強く取り組む必要がありますが、コストガバナンスの閾値を下げることが長期運用の仕組みを構築する前提となります。 NetEase のコスト ガバナンス プラットフォームである EasyCost を見てみましょう。
このシステムは、アクセス時間、アクセス頻度、関連アプリケーションに応じてオフライン戦略を設定できるデータ診断機能を提供し、ワンクリックのグレースケールオフラインをサポートし、管理の効率を大幅に向上させます。
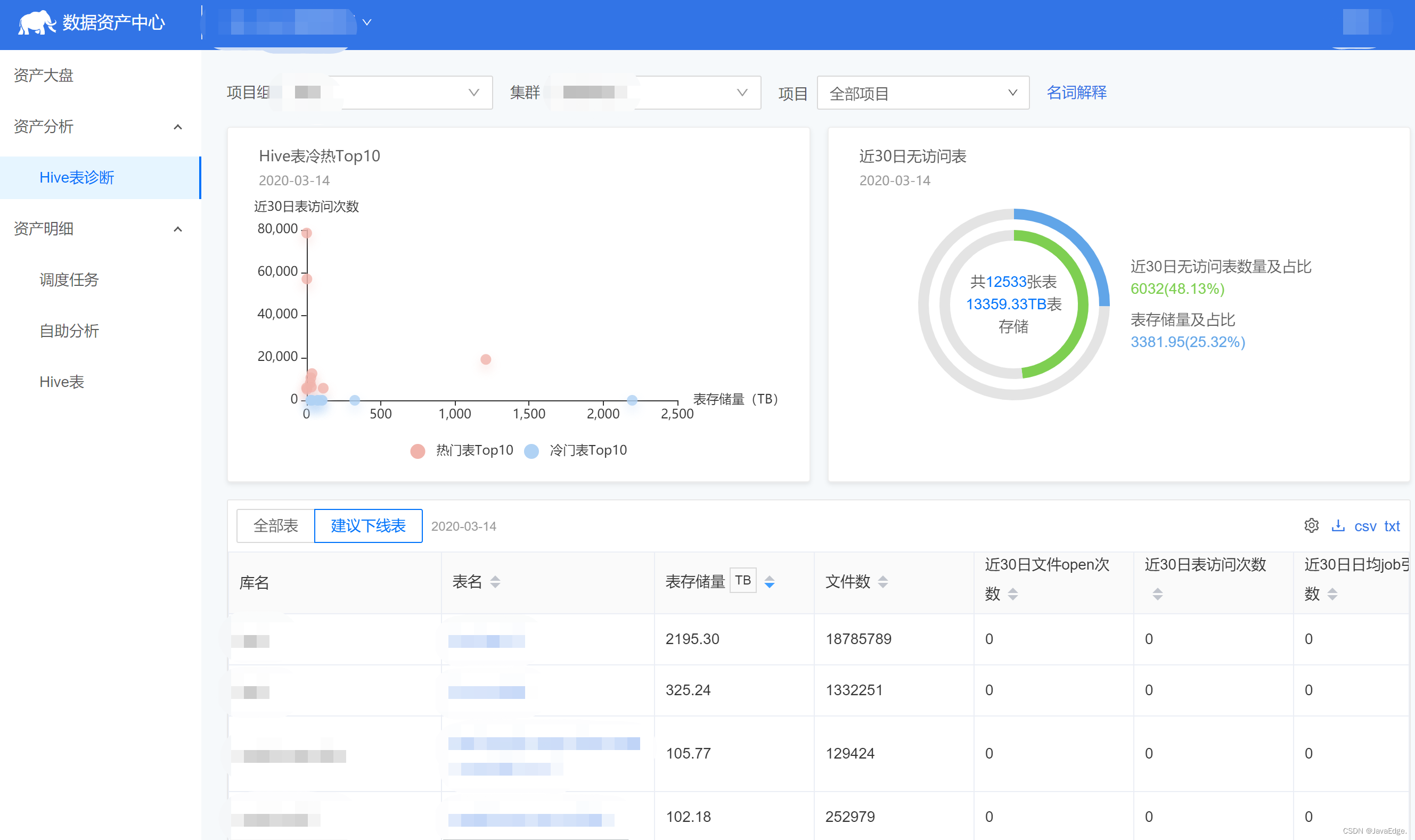
それを体系的にプロダクトに組み込むことができ、プロダクトを通じて管理効率を向上させ、ガバナンスメカニズムの長期的な実装を実現します。
要約する
データセンター経由:
- アセットセンターとしてビッグデータがもたらす配当を得ることができます
- また、コストの深淵に陥り、ビッグデータコストの猛烈な増加の代償を払うことになる可能性もあります
一般的なコストの罠から始めて、コストの無駄の考えられる原因を分析し、次に洗練されたコスト管理の方法を導入し、最後に次のことを強調します。
- 役に立たないデータのオフラインは、完全なリンク データ資産ビューの最後から開始し、層ごとに解明して、データ処理リンクの上流に進む必要があります。
- アプリケーション層テーブルの値はデータ アプリケーションの値によって測定される必要があり、値の出力が低いアプリケーションはアプリケーションの粒度でオフラインにする必要があります。
- 消費量の多いタスクを最適化するには、クラスターのピーク期間のタスクにのみ注意を払う必要があります。プロジェクト全体のリソース消費量は、ピーク期間のタスク消費量のみに依存します。もちろん、パブリック クラウドを使用している場合は、リソースに応じて、山と谷の間で差別化されたコスト決済を実装できます。また、低い期間にも注意を払う必要があります。
よくある質問
データセンターのバザール層には、数百のフィールドを持つ大きくて広いテーブルがいくつかあり、上流には数十のテーブルがある場合があり、このテーブルを計算するコストは非常に高くなります。このテーブルでは、フィールドのアクセス頻度が異なります。この広いテーブルを最適化するにはどうすればよいでしょうか?
垂直分割: フィールドのアクセス頻度に応じて広いテーブルを分割し、アクセス頻度の高いフィールドを個別にテーブルに分割し、アクセス頻度の低いフィールドを個別にテーブルに分割します。これにより、クエリ中にスキャンされるフィールドの数が減り、クエリの効率が向上します。
水平分割: 幅の広いテーブルを行ごとに分割し、各分割テーブルのフィールド数を許容範囲内で制御します。これにより、単一テーブルのフィールド数が削減され、クエリ効率が向上します。
インデックス作成: 幅の広いテーブル内でアクセス頻度が高いフィールドに対してインデックスを構築できるため、クエリを高速化できます。
キャッシュ メカニズム: クエリ頻度が高いデータの場合、キャッシュ メカニズムを使用してデータをメモリにキャッシュし、クエリ時間を短縮できます。
データ圧縮: 幅の広いテーブル内のコールド データの場合、データ圧縮テクノロジを使用してストレージ領域を削減し、クエリ効率を向上させることができます。
実際の状況に応じて適切な最適化方法を選択して、クエリ効率を向上させることができます。
この記事は、ブログ用のマルチポスト プラットフォームであるOpenWriteによって公開されています。