ニューラル ネットワークにおける意味論的および視覚的な整合性の不一致に対処する
公式アカウント:EDPJ
目次
0. 概要
画像分類タスクの場合、ニューラル ネットワークは主に視覚的なパターンに依存します。堅牢なネットワークでは、視覚的に類似したクラスが同様の方法で表現されることが期待されます。意味的に類似したクラスが視覚的に類似しない場合、および意味的に類似しないクラス間に視覚的な類似性が存在する場合について、次の質問を検討します。私たちは、意味的に類似したクラスを任意の (非視覚的) 意味関係とより適切に調整することを目的としたデータ拡張手法を提案します。拡散ベースの意味混合に関する最近の研究を活用して、2 つのクラスの意味混合を生成し、これらの混合を拡張データとしてトレーニング セットに追加します。私たちは、敵対的に摂動されたデータに対するモデルのパフォーマンスを評価することで、メソッドがセマンティック アライメントを高めるかどうかを評価します。敵対的であれば、クラスを同様に表現されたクラスに切り替えるのが容易になるはずです。結果は、私たちが提案したデータ拡張方法を使用すると、意味的に類似したクラスのアラインメントが増加することを示しています。
1 はじめに
画像分類という一般的なタスクでは、ニューラル ネットワークは画像内の視覚的パターンに依存する必要があります。意味論的な関係は視覚的な調整から生じることがよくありますが、視覚と意味論は常に関連しているわけではありません。たとえば、子供にとって安全な物体と危険な存在物を区別するように設計されたシステムでは、スプーンなどの無害な物体がナイフなどの危険な物体と視覚的に似ている可能性があり、この 2 つを混同すると有害な影響が生じる可能性があります。この例では、ニューラル ネットワークにおけるエラー重大度の概念を強調しています。分類モデルのほとんどのパフォーマンス測定ではすべてのエラーが同等に扱われますが、実際には一部のエラーは他のエラーよりも重大です。視覚的には似ているにもかかわらず、ナイフとスプーンをよく混同するため、有害な物体と安全な物体を区別するために使用されるシステムに対する高い不信感が生じます。この問題に対処するために、事前の意味論的な知識をトレーニング プロセスに組み込むデータ拡張方法を提案します。特に、純粋なデータ駆動型学習ではオブジェクトのセマンティクスに関する重要な情報が欠如しており、視覚的な情報だけではカテゴリの関係性を伝えることができない可能性があるため、意味的な整合性が視覚的な類似性と矛盾するケースに焦点を当てます。
このアプローチを使用して、視覚的な類似性がない場合でも、意味的に類似したオブジェクト間の整合性を高めることを目的としています。これを測定するために、クラスの表現が類似している場合、モデルがあるクラスを別のクラスと間違える可能性が高くなると考えて、摂動条件下でのエラー重大度の尺度を検討します。
この作品の貢献は次のとおりです。
- 拡散ベースの意味混合を使用して、意味的に類似したクラス間の整合性を高めるデータ拡張方法を提案します。
- 視覚的な類似性が意味的な類似性と一致しない場合にメソッドを評価するために、CIFAR100 に基づいた任意のクラス関係を持つデータセットを構築します。
- 敵対的摂動条件下でメソッドのエラー重大度を評価し、データ拡張により意味的に類似したクラス間の整合性が向上することがわかりました。
2.関連作品
これまでの研究では、階層型損失関数の導入や敵対的摂動を使用したクラスの調整など、意味論的な情報をトレーニングに組み込む方法が検討されていました。エラー重大度の概念は、モデルの堅牢性の代理尺度として、これらの研究の多くに登場します。これは、非常に類似していないクラス間のエラーは、意味的に類似したクラス間のエラーよりも悪いという考えです。Bertinetto (2020) らは、近年エラー重大度指標の改善が停滞しているため、この指標を再検討する必要があると主張しています。
特に興味深いのは、Bertinetto et al., 2020 での議論で、Bertinetto は意味上の近接性が視覚的な類似性を反映しないようにクラス関係をランダム化しています。この場合、検討した階層メソッドのパフォーマンスが低下するため、提案されたメソッドの成功には、階層内の関連クラスの視覚的な類似性が重要であることが示唆されます。Bertinetto 氏は、「アプリケーション固有の関係を強制するためにこのアプローチを使用したいと思うかもしれませんが、その有効性はデータの基本的な特性によって制限される可能性があります」と述べています。Abreu et al. (2022) の研究では、視覚的な関係が意味論的な関係をサポートしなくなったときに同様の動作が見出されました。私たちは、データ拡張手法で視覚的な類似性へのこの依存に対処することを目指しています。
さらに、拡散モデルを使用して合成トレーニング データを生成する以前の研究もありました。
- (Azizi et al., 2023) は拡散モデルを使用して、画像分類用の合成データを提供します。
- (He et al., 2022) は、テキストから画像への生成モデル GLIDE の合成データの使用を、ゼロショット設定と少数ショット設定の両方で、またモデルの事前トレーニングのためにも検討しました。彼らは、これらの設定では合成データが有益である可能性があることを発見し、データの多様性を高め、合成データによって生成されるデータ ノイズを低減するための戦略をさらに調査しました。
- 私たちのアプローチと同様に、(Trabucco et al., 2023) は拡散ベースのデータ拡張方法を提案しました。彼らは拡散モデルを使用して単一の画像を強化し、画像の高レベルの意味論的特性を多様化します (たとえば、トラックの前部の外観や背景の風景を変更するなど)。私たちの仕事は、特定のクラスのサンプルを多様化する代わりに、拡張を適用して画像の意味論的な混合を作成するという点で異なります。
私たちのアプローチでは、意味知識を統合する方法としてトレーニング サンプルの意味論的摂動を利用します。具体的には、トレーニング サンプルのセマンティック ミキシングを使用します。これは、2 つの異なる概念を混合して新しい概念を合成することを目的とした最近のタスクです。(Liew et al., 2022) は、事前トレーニングされたテキスト条件付き拡散モデルに基づいて概念を意味的に混合するための MagicMix と呼ばれる方法を提案しました。MagicMix は空間マスキングや再トレーニングを必要としないため、このメソッドで使用するのに十分な移植性を備えています。
評価では敵対的摂動を使用して、モデルがクラス表現をどのように調整するかについての洞察を提供します。(Szegedy et al., 2014) で紹介されているように、敵対的摂動は、画像に対するモデルの予測を変更する可能性がある小さな摂動です。(Madry et al.、2018) は、摂動に対する最適化されたビューを提供し、L2 有界投影勾配降下法 (PGD) 敵対的攻撃に対処できるようにします。
3. 方法
トレーニング中に「セマンティック混合」データを組み込むことで、トレーニング プロセスにセマンティックな知識を埋め込みます。具体的には、トレーニング データを使用して、意味的に類似した 2 つのクラスを混合した新しいトレーニング サンプルを生成するデータ拡張手法を提案します。効率性を高めるため、MagicMix パイプラインを使用してこのデータを事前生成します。トレーニング セット内の各画像に対して、そのスーパークラス内の他のクラスごとに新しい混合画像を生成します (図 1 を参照)。
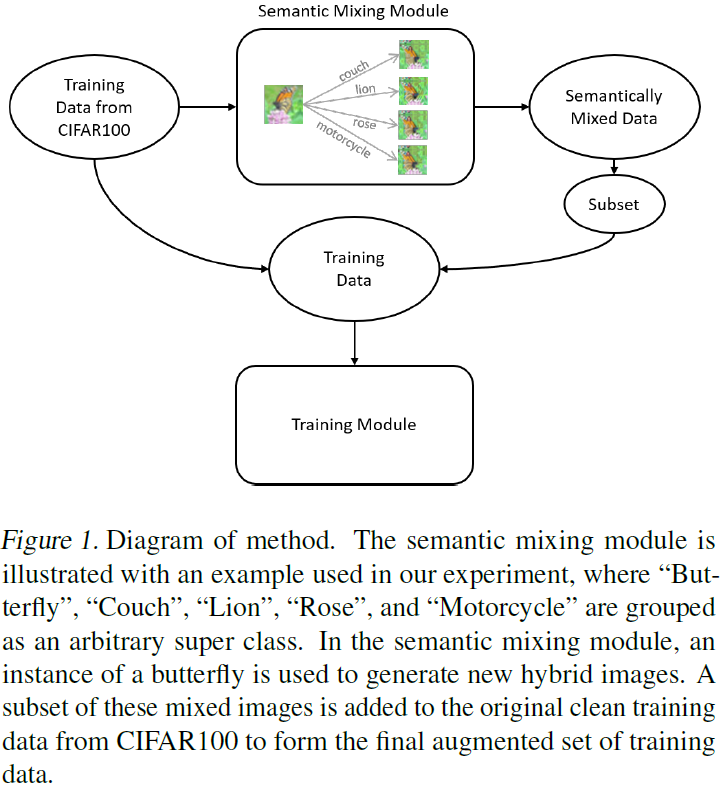
トレーニング中に遭遇した特定のインスタンスに対してクラスの拡張イメージの確率を追加することで、トレーニング中に使用される拡張データの量が変化します。クリーンなトレーニング データに対する拡張データの比率が高いことを考慮すると、このアプローチにより、拡張データがクリーン データを完全に支配することを防ぐことができます。私たちの実験では、トレーニング中の任意のインスタンスに対して 25% の確率で拡張画像を追加することを「低拡張」と呼び、50% の確率で拡張画像を追加することを「高拡張」と呼びます。拡張イメージは、特定のインスタンスと同じ基本クラスを持つ事前生成イメージをランダムに選択することによって選択されます。拡張インスタンスには、50% が基本クラス、50% がターゲット クラスとしてラベル付けされます。
4. 実験
任意のクラス関係に位置合わせを追加することに焦点を当て、同じスーパークラス内のクラスの視覚的な類似性が最小限に抑えられ、異なるスーパークラス内のクラスの視覚的な類似性がマージされるようにデータセットを形成します。データセットとして、CIFAR100 から視覚的に異なる 5 つのスーパークラスを選択し、元の各スーパークラスから 1 つのクラスが新しいスーパークラスに含まれるようにクラスを再割り当てしました。スーパークラスのグループ化を表 1 に示します。2 つの間の混乱を避けるために、元のスーパークラス (花、家具、昆虫、捕食者、乗り物) を視覚的スーパークラスと呼び、新しいスーパークラス (A、B、C、D、E) を意味論的スーパークラスと呼びます。


MagicMix パイプラインの画像とテキストのブレンドを使用して、ブレンドされた画像を事前に生成しました。トレーニング セット内の画像ごとに、同じスーパークラス内の細かいクラスごとに 1 つずつ、4 つのブレンド画像を作成しました。トレーニング セット内の画像はベース イメージとして使用され、MagicMix モジュール内のプロンプトは同じスーパークラス内の洗練されたクラス名に設定されます。MagicMix モジュールを使用すると、ミックス係数を [0, 1] の範囲で設定して、ターゲット キューのミックス強度を定義できます。モデルに従って混合係数を変更します。低い混合強度には 0.50 の混合係数を使用し、高い混合強度には 0.75 の混合係数を使用します。サンプル画像を表 2 に示します。

エラー スーパークラスの精度メトリックを使用してメソッドを評価します。特に、モデルが視覚的に類似したクラスの同様の表現を持っている場合、スーパークラスの性的障害以外の、あるクラスから別のクラスへの敵対的インスタンスを見つけるのは簡単であるという考えに基づいて、深刻度が増加する敵対的インスタンスの指標を研究します。
敵対的攻撃は、(Madry et al.、2018) で提案されているように、L2 有界射影勾配降下敵対的攻撃を使用してモデル化されます。データ分布 D および損失関数 L に対して学習されたパラメーター θ を持つモデル f の場合、次を解くことにより、ラベル y を持つ特定のインスタンス x に対する敵対的摂動 δ を求めます。
![]()
ここで、ε は敵対者の L2 境界です。
比較したモデルは以下の通りです。
- 標準モデル: 追加の拡張データなしでトレーニングされたモデル
- 低拡張、低混合強度: 25% の追加拡張データと 0.5 の混合強度を使用してモデルをトレーニングします。
- 低拡張、高混合強度: 25% の追加拡張データと 0.75 の混合強度を使用してモデルをトレーニングします。
- 高拡張、低混合強度: 50% の追加拡張データと 0.5 の混合強度を使用してモデルをトレーニングします。
- 高い拡張性、高いミックスアップ強度: 50% の追加拡張データと 0.75 のミックスアップ強度を使用してモデルをトレーニングします。
5. 結果
このセクションでは、敵対的な摂動の重大度が増加するにつれてのエラー重大度の結果を示します。まず、私たちが提案する拡張手法を採用したモデルが、敵対的に摂動されたインスタンスのエラー重大度の点でより優れたパフォーマンスを発揮することを実証します。さらに、私たちの技術が視覚的に類似したクラスでのエラーを削減することを実証します。これらの結果は、私たちの方法が視覚的な類似性と矛盾する意味論的な一致を増やすのに役立つことを示唆しています。

図 3 に示すように、データ拡張技術を使用したモデルは、標準モデルと比較して、摂動インスタンス エラーに関してスーパークラスの高い精度を実現します。高度なデータ増強、高混合強度モデルは、この指標に関して全体的に最高のパフォーマンスを発揮し、クリーンなデータを使用した標準モデルに近いパフォーマンスを示し、ゼロ以外のすべての摂動レベルで最高のパフォーマンスを達成します。クリーンなデータに対する標準モデルとデータ拡張モデルの同様のパフォーマンスに対処するために、CIFAR100 データセットの単純さにより、摂動レベルが低い困難な例 (例: 固有の特徴や誤解を招く特徴を持つもの) でのみモデルがエラーを引き起こすという仮説を立てます。摂動レベルが増加すると、モデルはより標準的な特徴を持つ例で間違いを犯し始める可能性があります。これは、データ拡張を使用したモデルのパフォーマンスの向上がより高い摂動データでのみ現れるという事実を説明します。
データ拡張技術を使用したモデルでは、同じビジュアル スーパークラス (例: 「花」) 内のクラス間のエラー率も低くなりました (図 3 を参照)。これは、モデルが、意味的には似ていない視覚的に類似したクラス間の相関が低いことを学習していることを示唆しています。

最後に、全体的なモデルの精度とセマンティック スーパークラスの精度を図 4 に示します。データ拡張技術を使用したモデルは、敵対的摂動のゼロ以外のすべてのレベルで両方のメトリクスを向上させ、高拡張、高混合強度モデルもクリーンでスーパークラスの精度を向上させます。データセットはそれほど難しいものではないため、データ拡張を使用した最高のパフォーマンスのモデルであっても、クリーンな精度とスーパークラスの精度の点ではわずかしか向上しません。摂動が増加してデータセットがより困難になると、MagicMix 歪みがクラスの特徴を同じセマンティック スーパークラスにグループ化するのに役立つため、私たちの方法はパフォーマンスを向上させます。最高レベルの摂動であっても、データ拡張を備えたモデルでは、ある程度の意味論的な整合性が維持されます。
6. 議論と結論
私たちの発見は、データ拡張を使用して任意の視覚的関係を持つクラス間の意味論的な整合性を高めるための有望な初期結果を提供します。より一般的には、この発見は、合成データがトレーニングに事前の知識を注入する可能性があることを示唆しています。今後の作業として、モデルがあいまいな画像や分類が難しい画像を認識する可能性が高い、より複雑なデータセットにこの方法を適用したいと考えています。さらに、このアプローチは、任意のクラス関係ではなくドメイン固有の知識を組み込む必要があるアプリケーションに拡張できます。
参考
Abreu N、Vaska N、Helus V. ニューラル ネットワークにおける意味論的および視覚的整合性の不一致への対処[J]。arXiv プレプリント arXiv:2306.01148、2023。
S. まとめ
S.1 主なアイデア
著者らは拡散ベースのデータ拡張を使用して、カテゴリと視覚的な関係の意味論的な整合性を高め、それによって摂動に対するモデルの堅牢性を向上させています。
S.2 セマンティックミキシング
拡散ベースのデータ拡張 MagicMix は画像に対してセマンティック ミキシングを実行します。そのプロセスを図 1 に示します。セマンティックミキシングの結果を図 2 に示します。列 4 (椅子からバス) を例にとると、意味混合の度合いが深まるにつれて (0% → 50% → 75%)、椅子の外観はますますバスに似てきます。
S.3メソッド
純粋なデータと意味論的な混合データを使用してモデルをトレーニングすることで、外乱が存在する場合でもモデルが正確な分類を実行できるようになります。つまり、モデルのロバスト性が向上します。