2020 年の初めに、NetEase Interactive Entertainment の海外事業の成長と海外データ コンプライアンスの必要性に伴い、NetEase Interactive Entertainment のビッグデータ オフライン コンピューティング プラットフォームを海外に移行する作業を開始しました。初期段階では、クラウド ホスト ベア メタルと高性能 EBS ブロック ストレージのソリューションを採用しました。しかし、このソリューションは保管コストが高く、国内で自作したコンピュータ室の数十倍のコストがかかります。
そこで、パブリック クラウド上にプラットフォームを構築することにしましたが、このプラットフォームは、現在のビジネス シナリオにより適しており、過去のビジネスとの互換性が高いだけでなく、パブリック クラウドの EMR ホスティング ソリューションよりも経済的である必要があります。主にストレージ、コンピューティング、データの階層化されたライフサイクル管理の3つの側面からコスト最適化を実施しており、具体的な最適化計画については以下で詳しく紹介します。
最終的に、このプロジェクトは下流のデータ ビジネス部門と分析部門に完全な Hadoop 互換性を提供し、すべてのビジネス ロジックの転覆と再発明を回避しました。海外に進出するゲーム データ ビジネスのコストを大幅に節約し、ストレージ コストは以前の 50% でした。コストは最適化前のコストの 40%、コールド データのコストは最適化後のオンライン ストレージ コストの 33% になります。将来的に業務量の増加に伴い、コスト削減効果は10倍となり、海外進出後のデータ活用業務を強力にサポートします。
01.ビッグデータプラットフォーム海外クラウドソリューション設計
2020 年、私たちは海洋への緊急ミッションに乗り出しました。中国では、当社のビジネスは自社構築クラスターの形式で展開および運営されています。海外での迅速なオンライン化を実現するため、物理ノードで構築された統合ストレージとコンピューティング システムのセットを使用した、国内クラスターとまったく同じソリューションを緊急に立ち上げました。ベアメタルサーバー M5.metal を選択し、ストレージとして EBS gp3 を使用しました。

このソリューションの欠点は、コストが非常に高いことですが、利点は、すべての歴史的なビジネスと互換性があり、すべての歴史的なビジネスが迅速かつ即座に海外で実行できるようにする必要があるという非常に厄介な問題を解決できることです。当社の上流および下流のビジネスはシームレスに海外に移行でき、1 日あたり 300,000 件近くのジョブのスケジュールをサポートします。
しかし、コストは常に無視できない問題です。したがって、ソリューションを再選択して、より優れたパフォーマンスとより低いコストのソリューションを取得し、互換性を確保する必要があります。ビジネス要件とビッグ データ シナリオの特性に応じて、次の方向からソリューションを選択する方法を評価します。
- パフォーマンスのために時間と空間をトレードします。
- ビジネスシナリオに基づいた展開の最適化。
- ミドルウェアを追加して互換性の統合を実現します。
- クラウドリソースの特性を最大限に活かしてコストを最適化します。
クラウド上の Hadoop
一般に、Hadoop のクラウド移行には、EMR+EMRFS と Dataproc+GCS の 2 つのソリューションがあります。この 2 つのオプションは、海に出るときの通常の姿勢です。または、データ クエリ ソリューションとして BigQuery、Snowflake、Redshift などのクラウド ネイティブ プラットフォームを使用しますが、これらのソリューションは使用しませんでした。
なぜEMRが使われないのか
当社のすべてのビジネスは Hadoop に大きく依存しているため、現在使用している Hadoop バージョンはビジネス ニーズに応じてカスタマイズされた内部バージョンであり、さまざまな新バージョンの機能との下位互換性を実現しています。クラウド ネイティブな BigQuery などのソリューションに関しては、より大きな変化を伴う方向性であり、ビジネスにとってはさらに遠いものになります。
S3 ストレージを直接使用しない理由
-
データビジネスのセキュリティに対する需要が高いため、Amazon IAM (Identity and Access Management) ROLE が達成できる上限をはるかに超える複雑なビジネス権限の設計が行われています。
-
S3 のパフォーマンスには制限があり、バケット化やランダム ディレクトリなどの最適化手段が必要ですが、ビジネス利用には不透明です。S3 パーティションに適応するようにディレクトリ プレフィックスを調整したり、より多くのバケットを使用するには、既存の使用方法にビジネス上の調整が必要ですが、これは適応できません。現在のカタログデザイン。また、オブジェクトストレージによるファイルシステムのため、S3ディレクトリに対するlistやduなどの直接操作は、非常に大規模なファイルデータの場合は基本的に実行できませんが、大規模データのシナリオではこの操作が非常に多くなります。
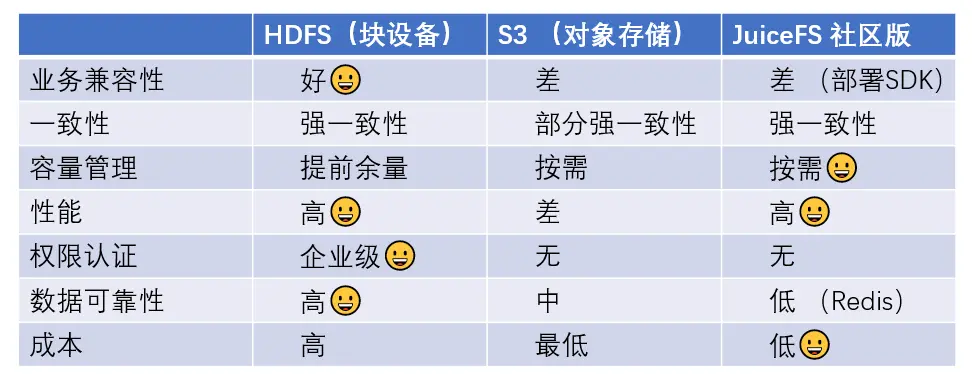
ストレージの選択: HDFS、オブジェクト ストレージ、JuiceFS
主に以下の観点からストレージコンポーネントを評価します。
ビジネスの互換性: 大量のストックビジネスを抱え、海外に進出する必要がある当社の状況では、互換性は非常に重要な考慮事項です。第二に、コストの削減と効率の向上には、保管コストの削減だけを指すのではなく、資源コストや人件費の考慮も含まれます。互換性の点では、JuiceFS Community Edition は Hadoop エコシステムと互換性がありますが、クライアント側に JuiceFS Hadoop SDK をデプロイする必要があります。
整合性: 当時、S3 について調査を実施しましたが、2020 年の第 1 四半期以前には強整合性が達成されておらず、現在すべてのプラットフォームで強整合性を実現できるわけではありません。
キャパシティ管理: 現在の自社構築クラスターの場合、重要な問題はリソースを予約する必要があることです。つまり、リソースを 100% 使用することは不可能であるため、オンデマンドでの使用は非常に費用対効果の高い方向です。
パフォーマンス: HDFS に基づいており、国内の自社構築 HDFS のパフォーマンス レベルに達します。当社が中国の企業に提供する SLA は、単一クラスターで 40,000 QPS の条件下で、10 ミリ秒以内に p90 の RPC パフォーマンスを達成することです。しかし、S3 のようなものでは、そのようなパフォーマンスを達成するのは非常に困難です。
権限認証: 自作クラスタでは、認証と権限管理に Kerberos と Ranger を使用します。しかし、S3 は当時それをサポートしていませんでした。JuiceFS Community Edition もサポートされていません。
データの信頼性: HDFS は 3 つのレプリカを使用してデータの信頼性を確保します。当時、JuiceFS メタデータ エンジンはテスト時に Redis を使用していました。高可用性モードでは、マスター ノードが切り替わるとストレージがフリーズすることがわかりました。これは私たちにとって非常に受け入れがたいことです。そのため、各マシンに Redis メタデータ サービスを個別にデプロイする方法を採用しています。詳細は以下で展開します。
コスト: ブロック デバイスのようなソリューションは高価です。私たちの目標は S3 を使用することです。全員が S3 のみを使用する場合、コストは当然最も低くなります。JuiceFS を使用する場合、後者のアーキテクチャには特定の追加コストがかかるため、そのコストが最低ではない理由については後ほど説明します。
02. Hadoop海外マルチクラウド移行計画
ストレージ層でのストレージとコンピューティングの分離: Hadoop+JuiceFS+S3
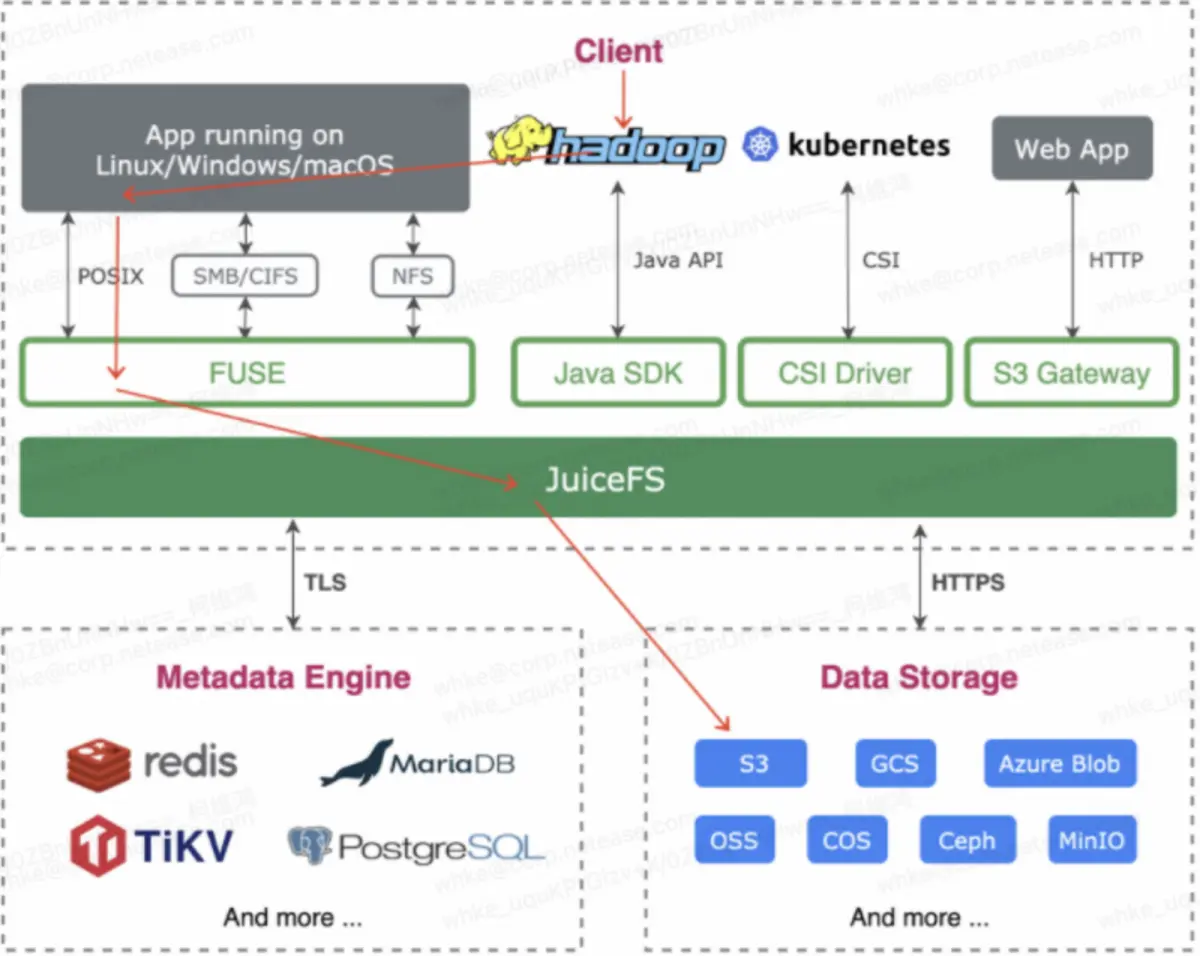
JuiceFSとHadoopを組み合わせることで、ビジネス互換性のコストを削減し、既存ビジネスの海外展開を迅速に実現できます。多くのユーザーが JuiceFS ソリューションを使用する場合、SDK と Hadoop オープン ソース バージョンを通じて実装します。ただし、このように権限認証の問題が発生し、JuiceFS Community Edition では Ranger と Kerberos の権限認証をサポートしていません。したがって、私たちは今でも Hadoop のフレームワーク全体を使用しています。メンテナンス費用が高そうに見えますが、中国では自社製のコンポーネント一式があり、メンテナンスが行われているため、費用はほとんどかかりません。以下の図に示すように、Fuse を使用して JuiceFS を Hadoop にマウントし、ストレージとして S3 を使用します。
EBS に基づいて独自に構築した単一クラスターのパフォーマンスを簡単に比較してみましょう。
- 40,000 QPS の場合、10 ミリ秒で p90 に達する可能性があります。
- 単一ノードは 30000 IOPS を維持できます。
初めてクラウドを使用したときは、HDD モード、特に st1 ストレージ タイプを使用しました。しかしすぐに、ノードの数が少ない場合、実際の IOPS は要件を満たしていないことがわかりました。したがって、すべての st1 ストレージ タイプを gp3 にアップグレードすることにしました。
各 gp3 はデフォルトで約 3000 IOPS を提供します。パフォーマンスを向上させるために、10 個の gp3 ストレージ ボリュームをマウントし、合計 30,000 IOPS のパフォーマンスを達成しました。この改善により、システムは IOPS 要件をより適切に満たせるようになり、ノード数が少ない場合でもパフォーマンスのボトルネックによる制限がなくなりました。gp3 の高いパフォーマンスと柔軟性により、IOPS 問題に対して理想的な選択肢となりました。
現在のノードあたりのデフォルトの帯域幅は 10Gb です。ただし、モデルごとに帯域幅も異なります。10Gb 帯域幅で 30000 IOPS の単一ノードのベンチマークを取得しました。私たちの目標は、S3 ストレージを統合できるようにすることです。つまり、高いパフォーマンスを維持しながらストレージのコストを考慮し、データは最終的に S3 に置かれることになります。
最も重要なことは、Hadoop アクセスと互換性があることです。つまり、すべての企業は変更を加える必要がなく、互換性の問題を解決するためにクラウドに直接アクセスできます。一部の歴史的なビジネスについては、一定のビジネス価値があるかもしれませんが、ビジネス変革とプラットフォームの互換性のコストを評価する必要があります。シナリオ ビジネスでは、すべての歴史的なビジネスを再構築するための人件費は、現時点ではプラットフォームの互換性のコストよりも高く、短時間で終わらせるのは不可能です。
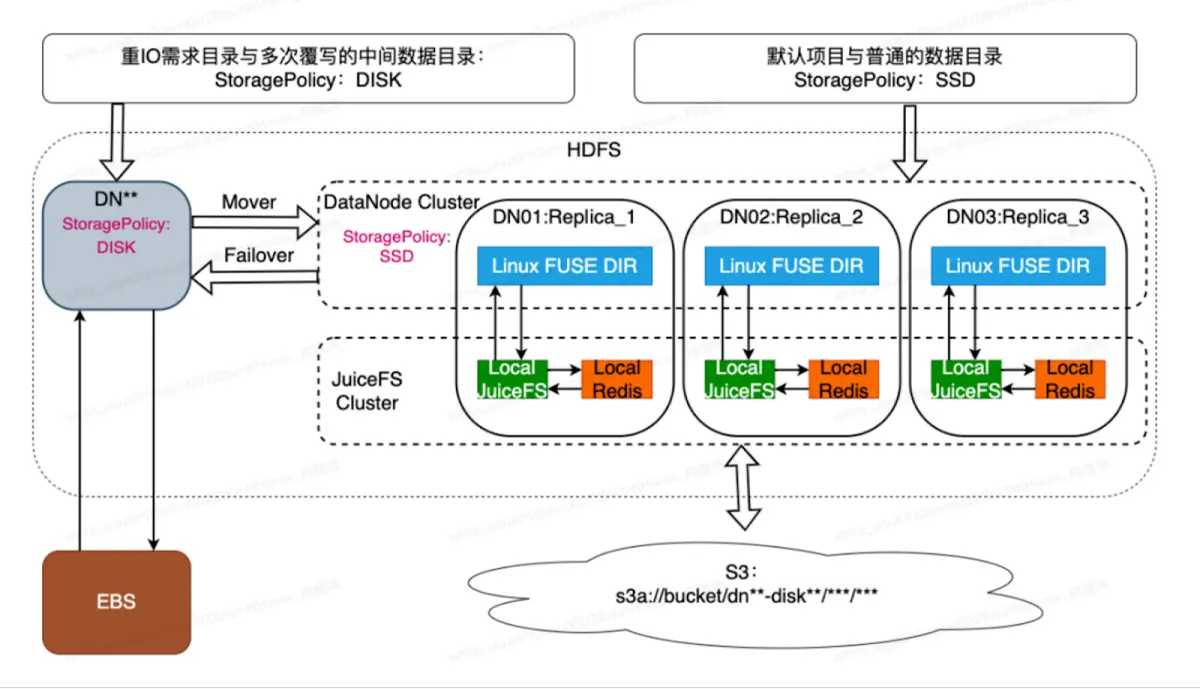
JuiceFS のマウント方法は公式 Web サイトと異なる場合があります。JuiceFS と Redis を各マシンにローカルにデプロイしました (以下の図を参照)。これは、JuiceFS のパフォーマンスを最大化し、ローカル メタデータの損失を最小限に抑えるために行われます。Redis クラスターと TiDB クラスターの使用を試みましたが、メタデータのパフォーマンスが数桁悪いことがわかりました。そこで、最初からローカル展開方式を採用することにしました。

もう 1 つの利点は、システムが DNO (データ ノード オブジェクト) に関連付けられていることです。各 DNO のファイル数、つまり単一ノードのファイル数を制御して、妥当なレベル内で安定させることができます。たとえば、当社の DNO には約 300 万から 800 万のメタデータ ファイルの上限があるため、1 つのメタデータ ノードは約 20 GB になります。このようにして、拡張にあまり注意を払う必要がなく、大規模な分散 Redis 要件を、単一ノード上の制御可能なメタデータを備えた Redis 要件に変換します。しかし、安定性にも問題があり、単一ノードに安定性の問題がある場合、損失のリスクに直面することになります。
単一ノードのダウンタイムの問題を解決するために、DNO とバインドし、HDFS マルチコピー メカニズムを使用し、クラスター内に 2 つのコピー モード (トリプル コピーと EC (Erasurecoding) コピー) を使用しました。さまざまなモードで、レプリカ メカニズムを通じて高いデータ信頼性が実現されます。マルチコピー展開スキームでは、ノードに完全な障害が発生した場合でも、全体の動作とデータの信頼性に影響を与えることなく、ノードを直接削除できます。
実際には、JuiceFS と単一ノード Redis を使用しながら単一ノードをローカルにデプロイすることが、最高のパフォーマンスを得る方法です。HDFS および EBS ソリューションのパフォーマンスをベンチマークする必要があるためです。
HDFS ベースの分散水平拡張と JuiceFS キャッシュと読み書き戦略の最適化により、高性能 HDFS を実現しました。最適化部分は次のとおりです。
- JuiceFS を使用して gp3 ディレクトリを置き換え、小規模な gp3 ストレージを JuiceFS キャッシュ ディレクトリとして使用して、gp3 と一致する IOPS レベルを達成します。
- JuiceFS キャッシュ メカニズムの最適化、カスタマイズされた非同期削除、非同期マージ アップロード、S3 ディレクトリ TPS プリセット、その他の最適化により、S3 に陥る状況を軽減し、低コストのストレージ S3 が gp3 を置き換えます。
- HDFS クラスターに基づくノードの水平拡張の分散実装。
- Hadoop異種ストレージの特性を活かし、ビジネス特性に応じてIOを分解し、パフォーマンスとコストを最適化します。HDFS ストレージを「DISK」と「SSD」の 2 つの部分に分割しました。「SSD」ストレージタイプは、JuiceFSのEBSキャッシュとS3統合を使用したハイブリッドストレージに対応します。「DISK」ストレージ タイプは、DN の EBS に保存されたディレクトリに書き込むように構成されています。Stage ディレクトリなど、頻繁に上書きされるディレクトリでは、ストレージとして DISK を使用するようにこれらのディレクトリを設定します。EBS ストレージは頻繁な消去と書き込みに適しており、S3 と比較して追加の OP コストが少なく、これらのディレクトリの合計ストレージ要件を制御できるため、このシナリオでは EBS ストレージのごく一部を予約します。
コンピューティング層: スポットノードとオンデマンドノードの混合導入スキーム
まず、国内で自社構築した YARN クラスターをクラウドに移行すると、クラウド上のリソース特性に適応してコストの最適化を実現できません。したがって、YARN ベースのインテリジェントな動的スケーリング ソリューションとラベル スケジューリングを組み合わせ、スポット ノードとオンデマンド ノードの混合展開ソリューションを採用して、コンピューティング リソースの使用を最適化します。
- スケジューラ戦略をキャパシティ スケジューリングに調整します (CapacityScheduler)。
- オンデマンド ノード パーティションとスポット ノード パーティションを分割します。
- ステートフル ノードのパーティションをオンデマンド ノードに調整して、異なる状態のタスクが異なる領域で実行されるようにします。
- オンデマンド ノードを使用して収益をカバーします。
- リサイクル通知と GracefulStop、プリエンプティブ ノードがリサイクル前に事前にリサイクル通知を受信する場合、6. GracefulStop を呼び出してビジネスを停止し、ユーザーのジョブの直接的な失敗を回避します。
Spark+RSS は、ノードがリサイクルされるときに、データがもともと動的ノード上にあり、ジョブを再計算する必要がある可能性を減らします。
-
ビジネス ニーズに基づいて、いくつかの動的なインテリジェント スケーリング ソリューションを作成しました。ネイティブ ソリューションと比較して、クラウド ベンダーはビジネスのホット スポットを知ることが不可能であるため、ビジネスの状態に基づいた動的なスケーリングの方向性により多くの注意を払っています。
-
社内運用保守ツールSmarttoolの定期予測に基づいてインテリジェントなスケーリングを実現します。最初の 3 週間の履歴データを取得し、単純なフィッティングを実行して、Smarttool プリセット アルゴリズムを通じてフィッティング残差シーケンス resid と予測値 ymean を取得します。このツールを使用して、1 日の特定の時点でのリソース使用量がどのようになるかを予測し、動的スケーリングを実装します。
-
特定の時間の事前スケーリングなど、時間ルールに基づいてスケジュールされたスケーリング: 毎月 1 日の月次レポート生成時間、大規模なプロモーションなど、特定の時間に事前に設定された容量。
-
使用率に基づく動的なスケーリング。一定期間内に使用容量がしきい値の上限を超えるか、しきい値の下限を下回る場合、予期せぬ使用需要に対応するために自動拡張および縮小がトリガーされます。私たちのビジネスがクラウド上で安定していながらも比較的低コストのコンピューティング リソース ソリューションを確実に入手できるように努めてください。
ライフサイクル管理: ストレージ コストを最適化するためのデータ階層化
実際に、レプリカ メカニズムに基づいてデータの信頼性を確保するために JuiceFS と S3 を統合しました。3 コピーの EC であっても 1.5 コピーの EC であっても、追加のストレージ支出コストが発生しますが、ある程度のデータの人気を考慮し、データが一定のライフ サイクルを過ぎると、IO の需要はそれほど高くなくなる可能性があります。したがって、これらのデータを処理するために Alluxio+S3 の単一コピー レイヤーを導入しました。ただし、ディレクトリ構造が変更されていない場合、この層のパフォーマンスは実際には JuiceFS を使用する場合よりも大幅に低下することに注意してください。それにもかかわらず、コールド データ シナリオではこのようなパフォーマンスを依然として受け入れることができます。
そこで当社は、データガバナンス・組織階層化サービスを独自に開発し、データの非同期処理により異なるライフサイクルにおけるデータの管理とコストの最適化を実現しました。このサービスをデータ ライフサイクル管理ツール BTS と呼びます。

BTS の設計は、ファイル データベース、メタデータ、監査ログ データに基づいており、テーブルとその熱の管理を通じてデータ ライフ サイクル管理を実現します。ユーザーは、上位レベルの DAYU Rulemanager を使用してルールをカスタマイズし、データの人気度を利用してルールを生成できます。これらのルールは、どのデータがコールドと見なされ、どのデータがホットと見なされるかを指定します。
これらのルールに従って、データの圧縮、マージ、変換、アーカイブ、削除などのさまざまなライフサイクル管理操作を実行し、それらをスケジューラーに配布して実行します。データ ライフサイクル管理ツール BTS は、次の機能を提供します。
- データの再編成、小さなファイルを大きなファイルにマージし、EC ストレージ効率とネームノードの圧力を最適化します。
- テーブル ストレージと圧縮方法の変換: テーブルをテキスト ストレージ形式から ORC または Parquet ストレージ形式に非同期的に変換し、圧縮方法を None または Snappy から ZSTD に変換します。これにより、ストレージとパフォーマンスの効率が向上します。BTS は、パーティションごとの非同期テーブル変換をサポートします。
- 異種データ移行。異なるアーキテクチャのストレージ間でデータを非同期に移行し、データ階層化のための組織的な機能を提供します。
ストレージ階層化アーキテクチャを次の 3 つの層に単純に分割します。
- 最高のパフォーマンスは、JuiceFS (ホット) 上の HDFS、3 コピーです。
- その後に、JuiceFS EC 上の HDFS のモード (ウォーム) 1.5 コピーが続きます。
- もう一度、S3 上の Alluxio のコピー (低頻度のコールド データ)。
- すべてのデータは消滅する前に、S3 上の Alluxio にアーカイブされ、単一コピーになります。

現在、データ ライフサイクル ガバナンスの影響は次のとおりです。
- 60% 冷、30% 温、10% 温。
- レプリカの平均数 (70% * 1 + 20% * 1.5 + 10% * 3) = 1.3 高いパフォーマンスを必要としないアーカイブの場合、データの約 70% を達成できます。EC レプリカを使用する場合はデータの約 20%、3 つのレプリカを使用する場合は約 10%。全体的なレプリカの数を制御し、平均約 1.3 のレプリカを維持しました。
03. 海外新アーキテクチャのオンライン効果:性能とコスト
テストでは、JuiceFS は大きなファイルの読み取りおよび書き込みに対してかなり高い帯域幅を達成することができました。特にマルチスレッド モデルでは、大きなファイルを読み取るための帯域幅は、クライアントのネットワーク カードの帯域幅制限に近くなります。
小さいファイルのシナリオでは、ランダム書き込みの IOPS パフォーマンスは (キャッシュとしての gp3 ディスクのおかげで) 優れていますが、ランダム読み取りの IOPS パフォーマンスは比較的低く、約 5 倍悪くなります。
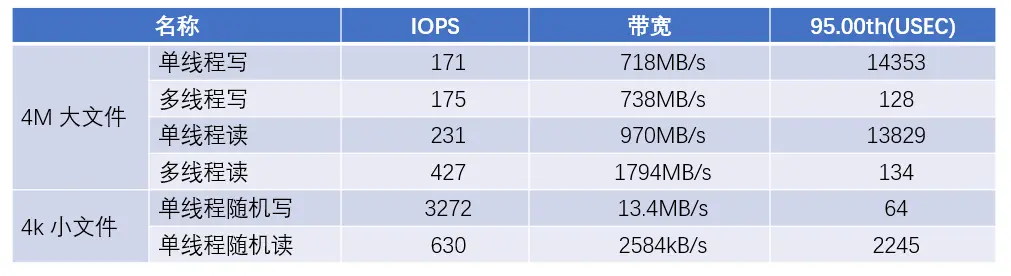
実際のビジネス測定における EBS ソリューションと JuiceFS+S3 ソリューションの比較 テストケースは本番環境のビジネス SQL です JuiceFS + S3 は基本的に EBS と大きな違いはなく、一部の SQL が異なることがわかりますさらに良いです。したがって、JuiceFS + S3 は EBS の全量を置き換えることができます。
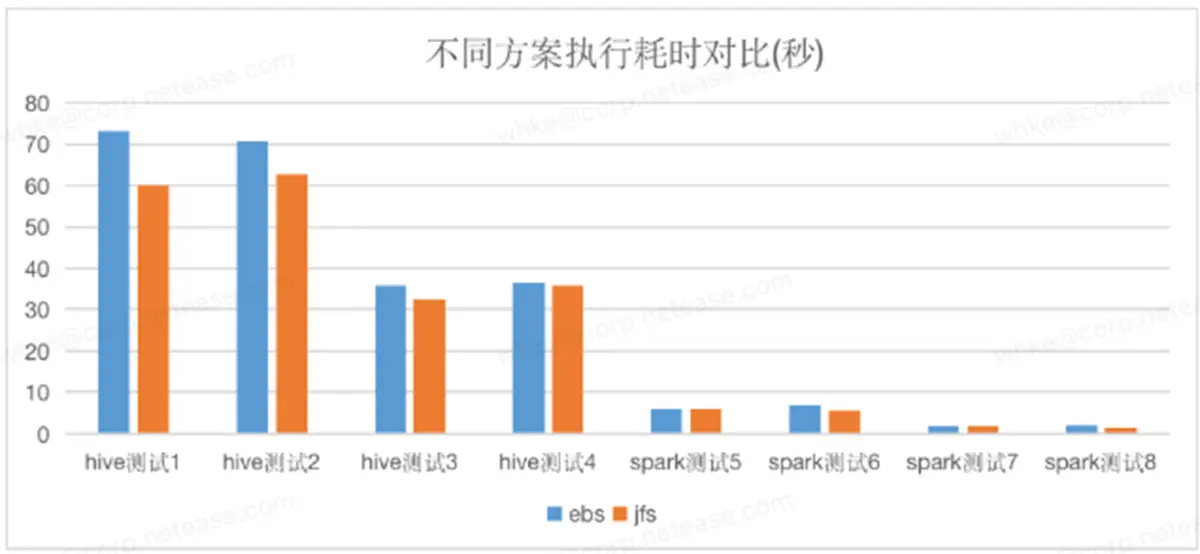
JuiceFS ベースの S3+EBS ハイブリッド階層型ストレージ コンピューティング分離ソリューションを使用して、元の EBS ソリューションを置き換えます。データ ガバナンスとデータ階層化により、元の Hadoop 3 コピー メカニズムは平均 1.3 コピーに削減され、複数コピーの 55% が節約されます。コスト、全体的なストレージ コストは 72.5% 減少しました。

インテリジェントな動的スケーリングにより、クラスター使用率の 85% とスポット インスタンスの 95% がオンデマンド ノードの置き換えに使用され、全体のコンピューティング コストは最適化前と比較して 80% 以上になります。
04. まとめと展望: クラウドネイティブに向けて
元の JuiceFS ソリューションと比較して、Hadoop+JuiceFS は追加のコピーを使用してストレージ パフォーマンスを最適化し、互換性と高可用性をサポートします。DN は、信頼性の観点から JuiceFS の反復最適化に依存して、コピーを 1 つだけ書き込みます。
EMR よりも優れたマルチクラウド互換ソリューションはさまざまなクラウドに実装されていますが、ハイブリッド マルチクラウドおよびクラウド ネイティブ ソリューションにはさらに多くの反復が必要です。
将来のクラウドネイティブなビッグデータシナリオの見通しに関して、現在採用しているソリューションは最終版ではなく、互換性とコストの問題を解決することを目的とした過渡的なソリューションです。今後は以下のような対応を予定しております。
- よりクラウドネイティブなソリューションへのビジネス移行を促進し、Hadoop 環境の分離を実現し、データ レイクとクラウド コンピューティングを密接に統合します。
- より高いレベルのハイブリッド マルチクラウド コンピューティングおよびハイブリッド ストレージ ソリューションを推進し、単なる互換性ではなく真の統合を可能にします。これにより、上位レベルのビジネスユニットにより多くの価値と柔軟性がもたらされます。
この内容が少しでもお役に立てれば幸いです。他にご質問がある場合は、JuiceFS コミュニティに参加して、皆様とコミュニケーションをとってください。
工業情報化省: 未登録のアプリにはネットワーク アクセス サービスを提供しない Go 1.21 が正式リリースRuan Yifeng が 「 TypeScript チュートリアル」をリリース Vim の父 Bram Moolenaar 氏が病気で死去 自社開発カーネルLinus が個人的にコードをレビュー, Bcachefs ファイル システムによって引き起こされた「内紛」を鎮めることを望んでいます. ByteDance はパブリック DNS サービスを開始しました. 素晴らしい, 今月 Linux カーネル メインラインにコミットしました